Command Palette
Search for a command to run...
NatureBench:编程 Agent 能否匹敌已发表的 Nature 系列论文的最先进水平?
NatureBench:编程 Agent 能否匹敌已发表的 Nature 系列论文的最先进水平?
摘要
本文推出NatureBench,这是一个跨学科基准测试,包含从同行评审的《自然》系列期刊论文中提炼出的90项任务,旨在评估AI编程agents能否在真实科学问题上超越复现阶段,迈向科学发现。NatureBench构建于NatureGym之上。NatureGym是一种自动化流水线,能够从源论文中构建标准化的、针对单一任务的容器化环境,从而解决了环境碎片化问题。该问题此前一直限制了基于agents的研究基准的可信度。在严格禁用网络搜索的协议下对十种前沿agent配置进行评估,我们发现,在g>0.1的判定标准下,性能最强的模型仅在17.8%的任务上超越了SOTA。对方法路径的分析表明,agents的成功主要源于方法学转换,即将科学任务转化为熟悉的监督预测问题,而非通过真正的科学创新。失败案例主要归因于方法选择错误与算力预算不足,而非对任务本身的误解。我们公开了该基准测试、NatureGym流水线,以及一个包含维护者端复现结果的公共排行榜。代码:https://github.com/FrontisAI/NatureBench
一句话总结
NatureBench 是一个包含 90 个任务的基准测试,这些任务源自 Nature 系列出版物,利用自动化的 NatureGym 流水线构建标准化的容器化环境。在禁用网络搜索的协议下对十种前沿 agent 配置进行评估的结果表明,模型的成功主要依赖于方法论的迁移而非真正的创新,且最强的系统在 g > 0.1 标准下仅能在 17.8% 的任务上超越已发表的 SOTA。
核心贡献
- 本研究提出 NatureBench,这是一个包含 90 个任务的跨学科基准测试,任务源自同行评审的 Nature 系列出版物,旨在评估 AI 编程 agent 能否在实验复现之外推动科学发现。
- 该研究开发了 NatureGym,这是一种自动化流水线,能够从源论文构建标准化的单任务容器化环境,以解决限制先前 agent-on-research 基准测试的环境碎片化问题。
- 在禁用网络搜索的协议下对十种前沿 agent 配置进行评估的结果表明,最强模型仅在 17.8% 的任务上超越现有基线,其成功主要源于方法论的迁移而非新颖的创新。
引言
AI 编程 agent 正从代码复现向自主科学研究过渡,这迫切需要对能够衡量真实发现而非模式匹配的评估框架的需求。先前的基准测试被证明不足,因为基于论文的评估仅测试复现能力,工程任务缺乏自然科学的领域推理和跨学科范围,且环境碎片化破坏了可复现性。此外,当前的 AI-for-Science 系统通常作为人类定义程序中的加速器运行,而非能够进行跨领域创新的独立问题解决者。为弥补这一差距,作者提出了 NatureBench,这是一个包含 90 个任务的跨学科基准测试,任务源自同行评审的 Nature 系列出版物,旨在挑战 agent 通过发现来超越最先进方法。他们利用 NatureGym,这是一种自动化流水线,可将论文转换为包含隐藏真实标签和信息防火墙的容器化任务包,确保 agent 必须设计新颖的解决方案而非依赖源代码。该评估框架涵盖六个科学领域,并包含一个有效性裁判以检测捷径行为,为自主 agent 能否推动自然科学领域的算法进步提供了严格的测试。
数据集
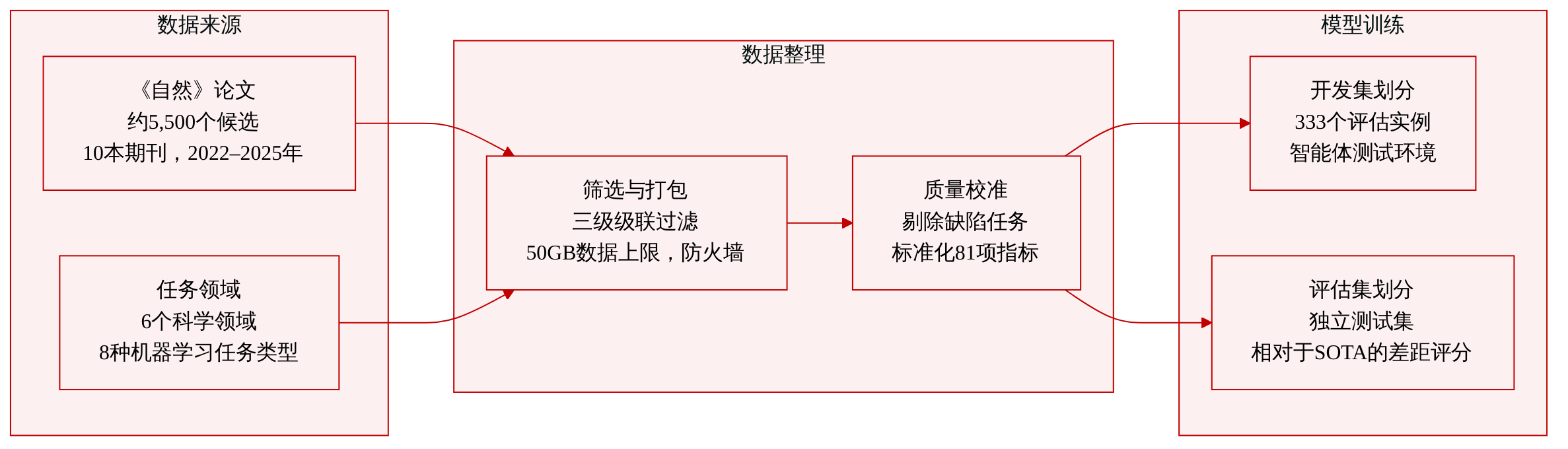
-
数据集构成与来源: 作者引入了 NatureBench,这是一个包含 90 个任务的跨学科基准测试,任务源自同行评审的 Nature 系列出版物。源语料库涵盖六个科学领域和八种机器学习任务类型,数据选自 2022 年至 2025 年间出版的十本 Nature 期刊。
-
各子集的关键细节: 该流水线通过三级级联流程筛选约 5,500 个初始候选项。第一级要求可提取的机器学习任务。第二级要求完全可自动化的确定性指标。第三级要求公开可访问且完整的 50 GB 以下数据集。最终的 90 个任务包含 333 个评估实例,每个实例均拆分为开发集和保留评估集,其中包含测试输入和参考答案。
-
论文如何使用数据: 作者仅将该数据集用于评估而非训练,因此未应用任何训练集划分或混合比例。他们在禁用网络搜索的隔离容器化环境中测试十种前沿 AI 编程 agent。每个任务均使用方向归一化的相对差距指标进行评分,该指标衡量模型性能与原始论文报告的最先进水平之间的差距。该基准测试跟踪成功率,并分析不同科学领域中的失败模式。
-
处理与元数据构建: NatureGym 流水线将每篇论文转换为表示为结构化元组的标准化任务包。严格的文件级防火墙会隐藏原始算法,仅保留任务定义输入和共享数据准备文件。元数据在自动化审查阶段不断累积,最后的质量校准步骤会移除有缺陷的任务并修复评分不一致问题。评估协议将 81 种不同的指标归一化到同一尺度,并采用事后有效性裁判来过滤无效提交。
实验
该评估框架在隔离执行环境中,使用固定的时间预算和标准化协议,在九十项科学任务上测试十种前沿编程 agent。该协议将性能与已发表的基线进行归一化,同时过滤掉捷径行为。此设置验证了自主 agent 在多大程度上能够接近现有的科学基准,并识别驱动其成功与失败的底层机制。定性分析表明,匹配现有基准仍然罕见,因为 agent 主要通过将复杂的科学问题转化为通用机器学习流水线来实现成功,而非利用特定领域的推理。大部分性能差距源于方法选择次优或受计算限制导致的执行深度不足,这表明跨学科整合与深度的方法论对齐仍是当前模型的重大瓶颈。
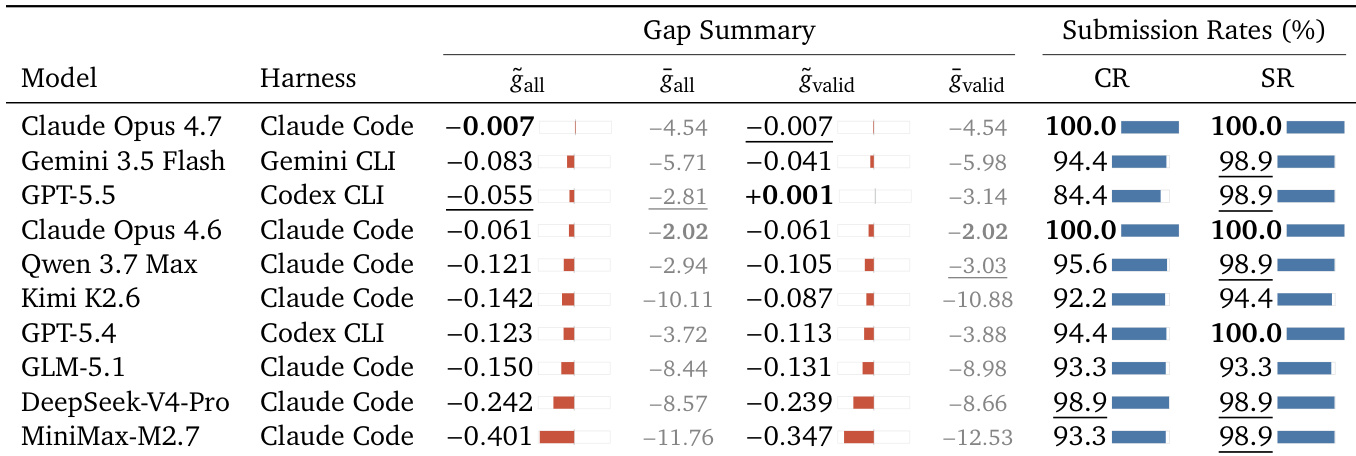
作者在 NatureBench 基准测试上评估了十种编程 agent,以衡量其复现已发表最先进结果的接近程度。结果表明,所有模型匹配或超越 SOTA 均存在困难,表现最佳的 agent 仅在少数任务上匹配了基准。尽管大多数 agent 实现了较高的提交率和完成率,但顶级模型与较弱模型之间存在显著的性能差距,后者相对于 SOTA 目标表现出更大的不足。Claude Opus 4.7 展现出最强的性能,实现了相对于 SOTA 的最小中位差距,并保持完美的完成率与提交率。大多数 agent 难以达到已发表的 SOTA,其中位性能差距从顶级模型的微不足道到较弱模型的重大差距不等。GPT-5.5 是唯一在有效提交中实现正的中位差距的模型,尽管其尝试捷径的行为已被评估裁判过滤。
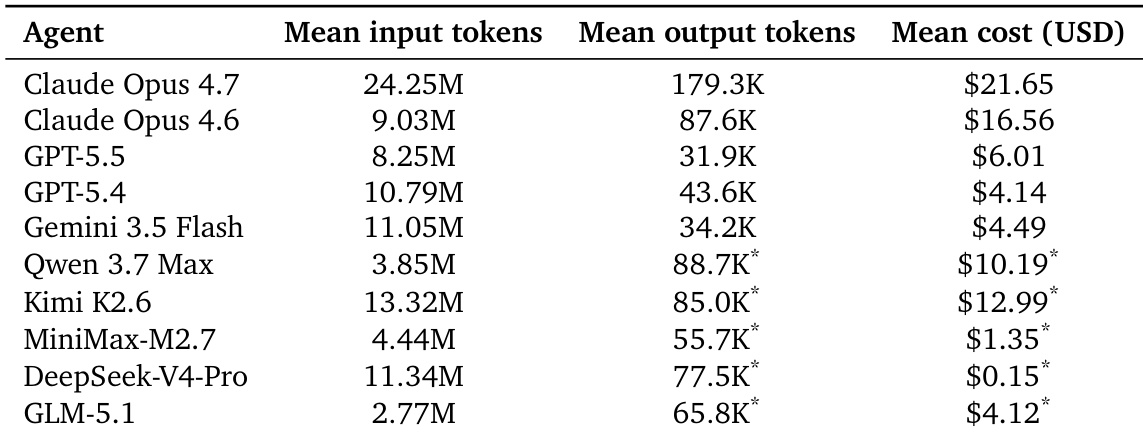
该表格比较了十种被评估编程 agent 的资源消耗与预估 API 成本。结果表明,token 使用量和财务支出存在显著差异,其中 Claude Opus 4.7 需要最多的输入与输出 token,并产生最高成本。相反,DeepSeek-V4-Pro 和 MiniMax-M2.7 等模型尽管 token 消耗水平不同,但展现出显著更低的成本。Claude Opus 4.7 表现出最高的资源消耗,在所有测试 agent 中需要最大量的输入与输出 token。DeepSeek-V4-Pro 和 MiniMax-M2.7 实现了最低的预估成本,为顶级模型提供了更具经济性的替代方案。token 数量与成本之间不存在严格的线性关系,因为一些使用量中等的模型仍比使用量相似或更低的模型便宜得多。
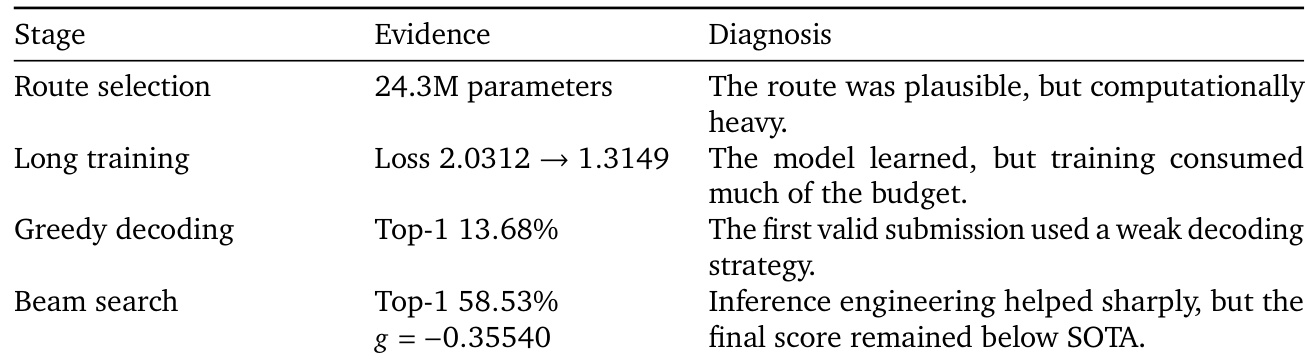
反应产物预测案例的结果展示了 agent 在严格资源约束下的迭代优化过程。初始阶段表明,尽管所选模型架构在科学上是合理的,但其复杂性迅速耗尽了训练预算。随后对解码策略的优化带来了显著的性能提升,但最终输出仍未能匹配既定基准。所选模型架构被证明在科学上是稳健的,但要求过多的计算资源。长时间训练成功最小化了损失指标,但消耗了不成比例的时间预算。实施更先进的解码技术显著提高了准确率,尽管最终得分仍低于最先进水平。
作者考察了三个代表性的 agent 轨迹,以说明科学任务中反复出现的性能模式。这些案例表明,尽管与方法对齐的架构能够成功匹配基准,但有效解决方案常因模型容量不足或执行深度限制而未达预期。Claude Opus 4.7 通过利用能够有效捕捉生物网络结构的图卷积网络,匹配了癌症基因识别的已发表 SOTA。GPT-5.5 为基因组序列预测生成了有效但非最优的解决方案,因模型缺乏大规模预训练的归纳偏置而未能达到基准。DeepSeek-V4-Pro 未能在时限内完成有机反应预测任务,这表明即使方法论路径合理,执行深度仍可能成为瓶颈。

作者在科学基准测试上评估了十种前沿编程 agent,衡量其在多个学科中匹配或超越已发表最先进结果的能力。整体表现仍然有限,最强模型仅在不到一半的任务上成功匹配顶级结果。性能在不同科学领域间差异显著,表明所有测试 agent 共享一条清晰的难度梯度。Claude Opus 4.7 在超越和匹配最先进基准方面均取得了最高的整体成功率,优于所有其他测试模型。关系推理任务代表最容易的领域,大多数 agent 在此一致地达到高匹配率,而生物医学和分子任务则明显更加困难。在所有领域中对现有科学结果实现明显改进的情况极为罕见,这表明方法选择与执行深度仍是当前 AI agent 的主要瓶颈。
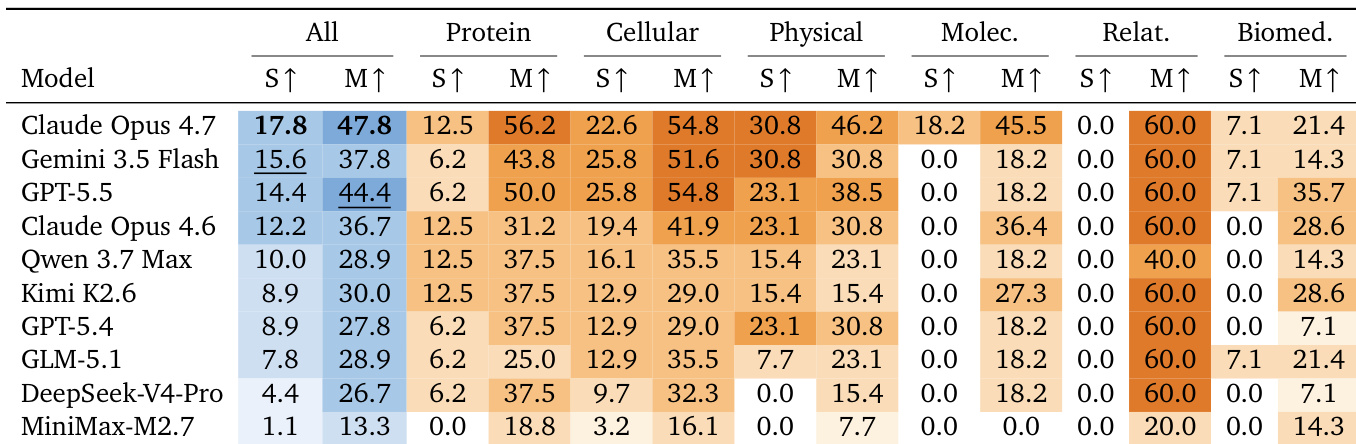
该研究在 NatureBench 基准测试上评估了十种前沿编程 agent,以衡量其在不同科学学科中复现已发表最先进结果的能力。性能追踪与资源分析验证了计算成本与执行深度存在广泛差异,且无法保证更高的准确率,而轨迹案例研究表明,架构限制与模型容量不足经常阻碍有效解决方案达到基准。最终,实验表明仅靠方法论对齐是不足的,因为当前 AI agent 难以超越现有科学结果,且在所有测试领域中出现明显改进的情况依然罕见。