Command Palette
Search for a command to run...
无限OCR工作:欢迎一次性长期解析的时代
无限OCR工作:欢迎一次性长期解析的时代
Baoding Zhou Jingyun Wang Xiaolin Wei Jianwei Niu Hui Lin Zhenyu Li Zhiwei Xu Xiaojun Wan
摘要
近期,以 DeepSeek OCR 为代表的端到端 OCR 模型再次将 OCR 技术推向了风口浪尖。业界普遍观点认为,采用大语言模型(LLM)作为解码器,能够利用语言先验分布,从而提升 OCR 性能。然而,其劣势同样明显:随着输出序列的延长,累积的 KV cache 会导致内存消耗急剧增加,并逐渐降低生成速度。这与人类在长程抄写任务中表现出的高效性形成了鲜明对比。在本技术报告中,我们提出了 Unlimited OCR,这是一种旨在模拟人类解析工作记忆的模型。以 DeepSeek OCR 为基线,我们将解码器中的所有注意力层替换为我们提出的参考滑动窗口注意力机制(Reference Sliding Window Attention, R-SWA)。该机制在保持整个解码过程中 KV cache 大小恒定的同时,显著降低了注意力计算成本。通过将 DeepSeek OCR 编码器的高压缩率与我们恒定的 KV cache 设计相结合,Unlimited OCR 能够在标准最大长度为 32K 的条件下,单次前向传播即可转录数十页的文档。更为重要的是,R-SWA 是一种通用的解析注意力机制——除了 OCR 任务外,它同样适用于自动语音识别(ASR)、翻译等任务。代码和模型权重已在 http://github.com/baidu/Unlimited-OCR 上公开。
一句话总结
百度研究者提出 Unlimited OCR,该模型通过将 DeepSeek OCR 基线中的所有解码器注意力层替换为参考滑动窗口注意力(Reference Sliding Window Attention, R-SWA),模拟人类解析工作记忆,在解码过程中保持恒定的 KV 缓存,从而在标准 32K 最大长度下实现数十页文档的高效一次性转录,避免了典型 LLM 基 OCR 系统的内存和速度退化。
核心贡献
- Unlimited OCR 被提出作为一种端到端模型,将所有解码器注意力层替换为参考滑动窗口注意力(R-SWA),在解码过程中保持恒定的 KV 缓存,以消除长序列生成的内存和速度退化。
- R-SWA 是一种受人类工作记忆启发的通用解析注意力机制,模型通过仅将必要的历史信息传递到固定窗口而非保留完整上下文,学习了一种软遗忘行为。
- 将所有解码器自注意力替换为因果 R-SWA 可实现无损的 OCR 解析性能,能够在单次 32K token 前向传递中转录数十页文档,并且该方法适用于其他长时程基于参考的任务,如 ASR 和翻译。
引言
近期使用大型语言模型解码器的端到端 OCR 模型带来了显著的精度提升,但它们存在一个关键瓶颈:随着输出序列变长,累积的键值缓存消耗更多内存并减慢生成速度。这与人类工作记忆形成对比,后者在长时间复制任务中保持恒定的认知负荷,而无需查阅全部历史。先前方法通过循环处理页面并每次重置内存来处理多页文档,这割裂了任务而非原生解决。
作者引入 Unlimited OCR,将解码器的标准注意力替换为参考滑动窗口注意力(R-SWA)。在此设计中,每个生成的 token 关注所有参考 token(视觉和提示 token),同时仅关注前序输出 token 的一个小滑动窗口。这使得解码过程中键值缓存大小保持恒定,并避免了标准滑动窗口注意力中出现的视觉特征逐渐模糊。通过将这种恒定缓存解码器与高压缩图像编码器结合,模型能够在标准 32K 上下文长度下,单次前向传递转录数十页文档,同时相比基线提升通用 OCR 精度。
数据集
以下是基于所提供文本的简明数据集描述。
数据集构成与来源
- 作者构建了一个约 200 万文档 OCR 样本的专用数据集,用于训练 Unlimited OCR 模型。
- 数据按 9:1 比例划分为单页和多页文档。
- 构建了一个独立的内部基准用于长时程评估,来源为按页数分组的小说、文档和论文。
各子集的关键细节
- 单页数据: 来源为 PDF 文档。作者使用 Paddle OCR 进行标注,提取块坐标和内容以生成端到端检测与解析的真值。
- 多页数据: 该子集完全为合成数据。作者通过拼接单页文档生成了约 200,000 个样本。每个样本包含 2 至 50 页,使用
<page>token 作为分隔符。 - 内部基准: 该测试集按文档长度组织,包含 2、5、10、20 和 40+ 页的书籍类别。每个类别包含不少于十本书籍。
模型中的数据使用
- 构建的数据集用于训练 Unlimited OCR 模型。
- 作者将所有训练数据打包为固定长度 32,000 token 的序列。
处理与元数据细节
- 坐标归一化: 对于单页数据,每个检测元素的坐标被归一化到 0–1000 的范围。
- 元数据构建: 单页数据的真值通过将归一化坐标与每个块的相应文本内容拼接构建。
方法
作者提出 Unlimited OCR,一种专为长时程解析设计的统一端到端架构。如下图所示,该模型具有一个高压缩编码器,并配有一个混合专家(Mixture-of-Experts, MoE)LLM 解码器。
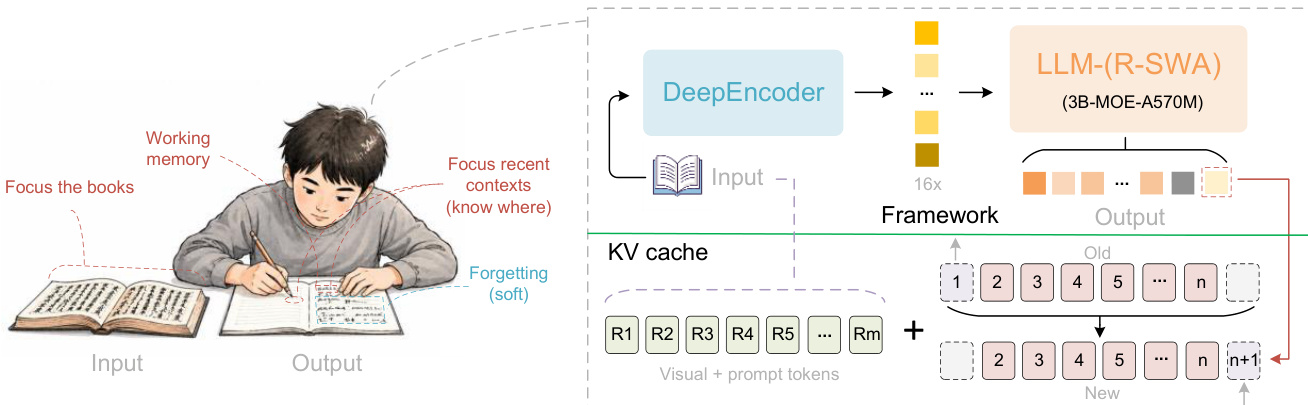
该框架采用 DeepSeek OCR 作为基线,包含 DeepEncoder 和一个总参数 3B、激活参数 500M 的 MoE-LLM 解码器。DeepEncoder 提供了卓越的视觉 token 压缩能力,大幅减少了预填充阶段的 KV 缓存占用,同时保留了稳健的光学文本特征提取。与原始基线的一个关键区别是,将普通多头注意力(Multi-Head Attention, MHA)替换为提出的 R-SWA 机制。这使得通过用宽度为 n 的固定容量输出 KV 缓冲区扩充原始参考 KV 缓存 m,实现长时程解析。
DeepEncoder 级联 SAM-ViT 与 CLIP-ViT,并在桥接处应用 16× token 压缩。前半部分完全依赖窗口注意力处理原始图像 token,而全局注意力仅保留用于压缩后的 token。这种设计在编码高分辨率图像时保持较低的激活值,从而节省 GPU 内存。该编码器原生支持多种分辨率模式,包括用于多页输入的 Base 模型和用于动态分辨率单页输入的 Gundam 模式。例如,它可以将 1024×1024 的 PDF 图像压缩至仅 256 token。这种高压缩比至关重要,因为视觉 token 不会随输出进行状态转换;它们被编码一次并在整个解析过程中保持静态。
解码器直接影响推理成本,具体涉及 LLM 激活值和 KV 缓存大小。为解决前者,作者采用了 MoE 架构,在推理期间将激活值保持在仅 500M。为解决后者,即 KV 缓存通常随解码上下文持续增长的问题,模型实现了 R-SWA。
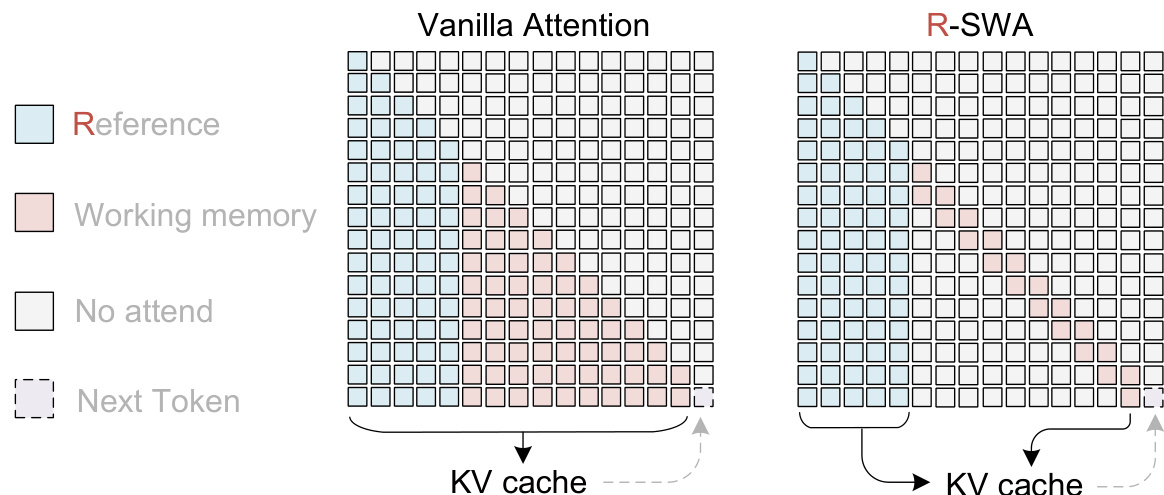
如上对比所示,与 KV 缓存无限增长的普通注意力不同,R-SWA 将 KV 缓存实现为一个容量为 m+n 的队列。每次生成新 token 时,队列中第 (m+1) 个 token 对应的 KV 将被驱逐。这确保了计算成本和内存使用在生成过程中不会逐步增加,模仿了人类在抄写书籍时关注近期上下文同时保留参考信息的过程。
从 DeepSeek OCR 检查点开始,作者在 8×16 A800 GPU 上,以全局批次大小 256 和最大序列长度 32K 继续训练 Unlimited OCR 4000 步,并对所有数据使用随机打包。训练期间,DeepEncoder 因已充分优化而被冻结,仅训练 LLM 参数。作者使用 AdamW 优化器和余弦退火调度器,初始学习率为 1e-4。为支持 32K 训练,采用了 DeepEP,并将专家并行度设为 4。整个训练流程基于 Megatron-LM 框架构建。对于推理,R-SWA 的 KV 缓存管理在 Transformers 库中实现,并在 SGLang 推理引擎中提供了相应支持和优化,使模型能够在恒定的每秒 token 数和 GPU 内存使用下运行。
实验
通过在少量 PDF 特定数据上继续训练 DeepSeek OCR,Unlimited OCR 将标准解码器注意力替换为循环滑动窗口注意力(R-SWA),在 OmniDocBench 上实现了端到端的最先进性能,同时推理速度提升超过 12%。跨九种文档类型的子类别评估确认了一致的增益且无妥协,即使在报纸和杂志等复杂布局上也是如此。R-SWA 设计通过保持 KV 缓存固定来实现长时程解析,使模型能够以稳定的延迟和良好的编辑距离分数处理数十页文档。效率分析显示,随着输出长度增长,Unlimited OCR 的速度优势扩大,在 6,000 token 时相比标准注意力领先 35%,尽管未来工作旨在克服预填充长度限制并将该方法扩展到 ASR 和翻译等任务。
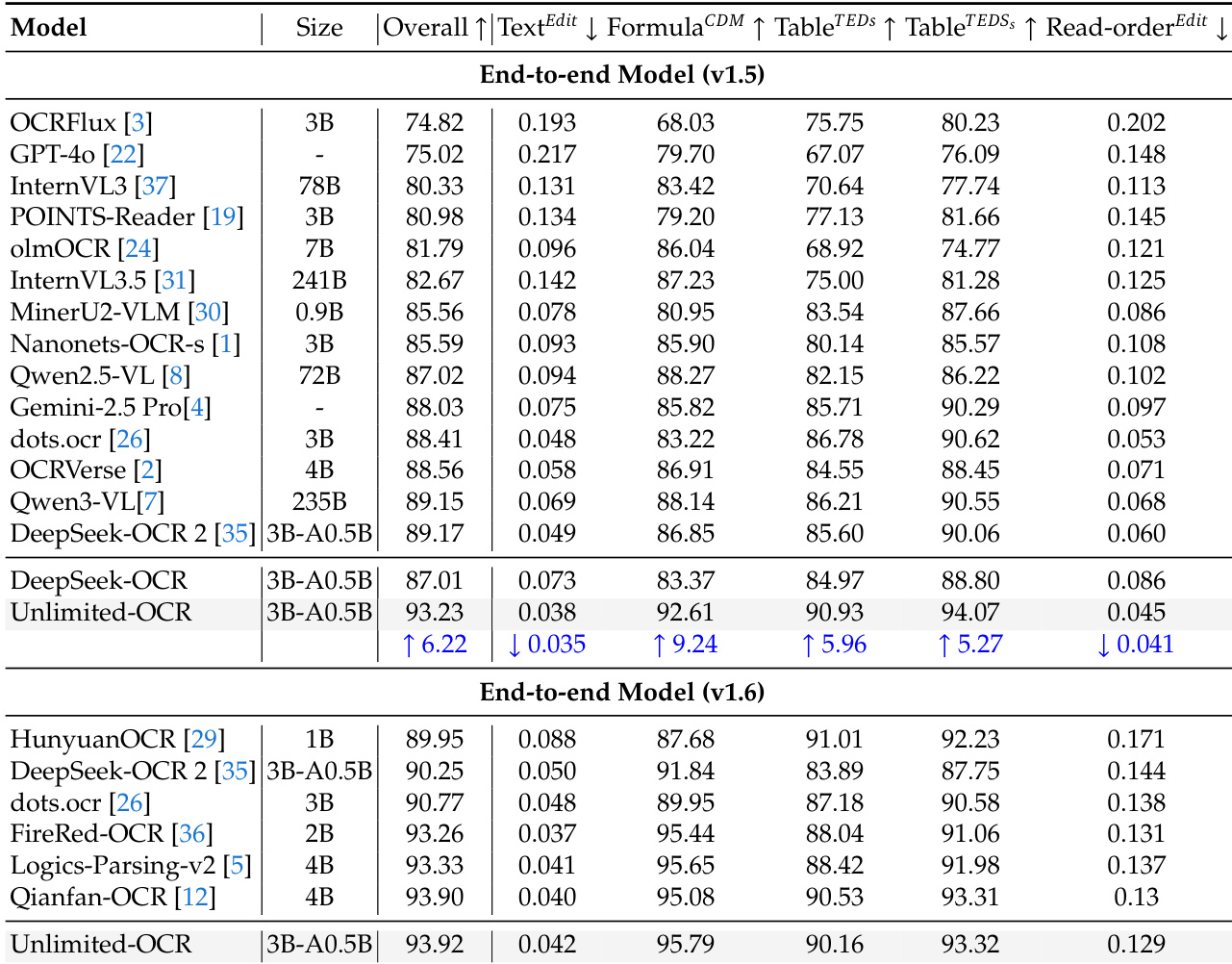
作者证明,Unlimited OCR 通过将标准注意力替换为 R-SWA,在 OmniDocBench 基准上实现了端到端的最先进性能。结果显示,与 DeepSeek OCR 等先前模型相比,在所有评估指标上(包括文本编辑距离、公式识别和表格结构)均取得了一致且显著的改进。Unlimited OCR 在 OmniDocBench v1.5 和 v1.6 数据集上,在整体指标和特定子任务方面均优于所有比较模型。该模型在文本编辑距离和表格识别分数上相比其基线 DeepSeek OCR 取得了显著提升。该方法在多种文档类型上实现了一致的改进,且未影响推理效率。
作者通过测量不同输出长度下的每秒 token 数,比较了 Unlimited OCR 和 DeepSeek OCR 的推理效率。结果表明,虽然两个模型在较短输出长度时性能相似,但 DeepSeek OCR 的效率随序列长度增加而下降,而 Unlimited OCR 保持了一致且更高的速度。随着输出长度增加,Unlimited OCR 保持稳定的推理速度,而 DeepSeek OCR 则呈现稳步下降。在较长输出序列下,由于 R-SWA 机制,Unlimited OCR 相比基线模型展现出显著的速度优势。Unlimited OCR 恒定的生成速度使其特别适用于长时程 OCR 任务。

作者通过测试模型在页数递增的文档上的表现,评估其长时程解析能力。结果显示,即使对于非常长的文档,模型也能保持高输出多样性和低错误率,验证了循环滑动窗口注意力机制的有效性。作者指出,极端长度下的微小错误是由于图像分辨率限制而非模型丢失上下文。模型在 2 到 20 页的文档中持续保持高多样性分数和低编辑距离。对于超过 40 页的文档,性能仍保持令人满意的水平,表明模型在长序列中不会迷失方向。稳定的指标证实滑动窗口注意力方法有效支持了连续解析而无显著退化。

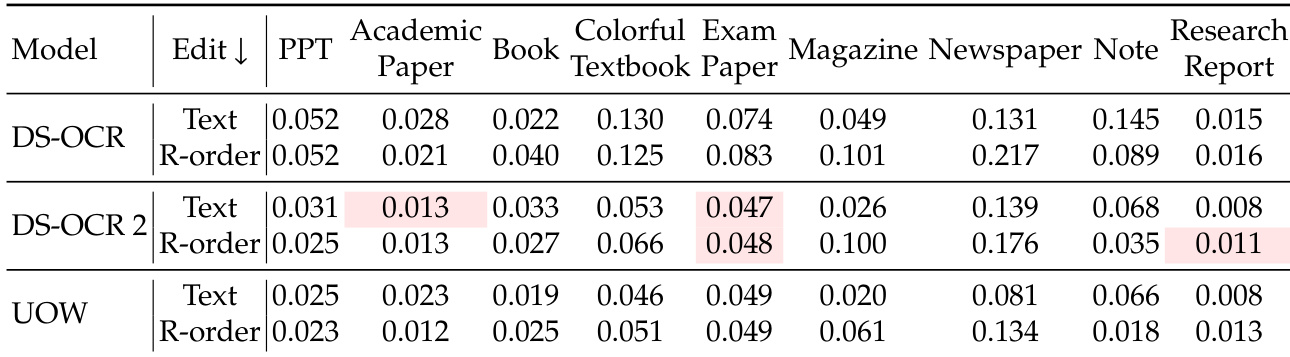
作者展示了 Unlimited OCR 与 DeepSeek OCR 和 DeepSeek OCR 2 在九种文档类型上的子类别比较。结果显示,Unlimited OCR 在所有指标和文档类别上均相比原始 DeepSeek OCR 取得了一致的改进。此外,该模型在大多数情况下优于 DeepSeek OCR 2,在报纸和笔记等复杂布局上展现出特别的优势。Unlimited OCR 在每种指标和文档类型上均相比 DeepSeek OCR 显示出清晰且一致的增益。该模型在九种类别中的七种上,在文本编辑距离和阅读顺序分数方面均超越了 DeepSeek OCR 2。对于报纸和笔记等复杂布局文档,性能依然强劲,相比基线模型有显著改进。
评估在 OmniDocBench 上将 Unlimited OCR 与先前模型进行基准对比,其中将标准注意力替换为循环滑动窗口注意力在文本、公式和表格结构指标上带来了一致增益,且未牺牲速度。推理效率实验显示,虽然两个模型在短输出时性能相似,但随着序列长度增长,Unlimited OCR 保持稳定的生成速度,而基线模型则出现退化。对多页文档的长时程解析测试证实,该方法即使在超过 40 页时也能保持高输出多样性和低错误率,任何微小错误归因于图像分辨率而非上下文丢失。按文档类型的细分进一步揭示,Unlimited OCR 在所有类别上均优于 DeepSeek OCR,并在大多数类别上超越 DeepSeek OCR 2,在报纸和笔记等复杂布局上表现尤为突出。