Command Palette
Search for a command to run...
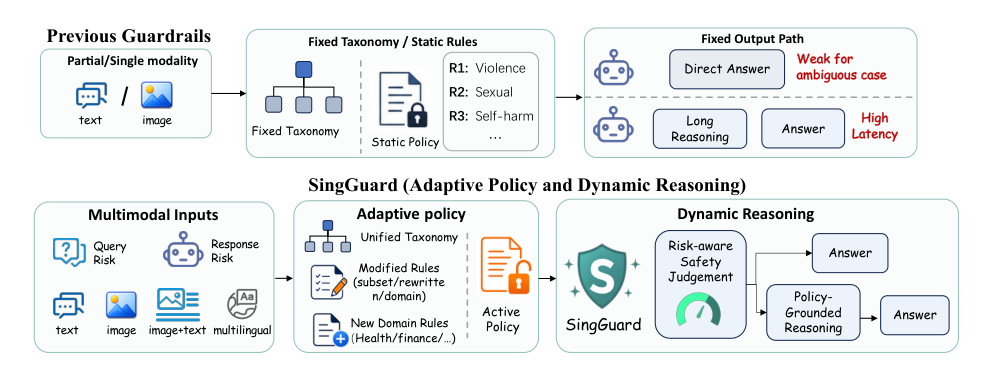
SingGuard:一个策略自适应的多模态大语言模型护栏,具备动态推理能力
SingGuard:一个策略自适应的多模态大语言模型护栏,具备动态推理能力
摘要
视觉-语言模型越来越多地部署在消费、医疗、金融和企业应用中。这种广泛部署扩大了安全范围:风险可能来自多模态问答、助手响应和跨模态组合,而审核策略可能因产品、地区和部署阶段而异。大多数现有的护栏要么依赖固定的分类法,要么只针对狭窄的交互设置集,这限制了它们在部署时安全规则发生变化时的适应性。我们提出 SingGuard,一个策略自适应的多模态护栏模型家族,用于多模态对话中的安全评估。SingGuard 将活跃策略视为运行时输入:给定自然语言规则,它逐条检查目标内容是否符合活跃策略,并预测安全标签和触发的规则。为了平衡效率和可解释性,SingGuard 支持快速、混合和慢速推理模式,沿着从快到慢的推理谱系,范围从直接的安全判断到基于策略的深思熟虑。我们进一步通过快慢解耦的强化学习优化这种行为。我们还引入了 SingGuard-Bench,一个多模态护栏基准,包含 56,340 个样本,涵盖 80 多种细粒度风险类型,涉及多模态问答、对抗攻击和动态规则评估设置,包括跨模态联合风险案例,其中每个模态单独无害,但它们的组合暗示了不安全意图。在六个基准家族(35 个数据集)中,SingGuard 在每个家族中都达到了最先进的平均 F1 分数。动态规则评估进一步表明,在运行时策略变化下,策略遵循准确性从 0.6465 提高到 0.7415。我们的代码可在 https://github.com/inclusionAI/Sing-Guard 获取。
一句话总结
蚂蚁集团AI安全实验室推出SingGuard,一个策略自适应的多模态护栏模型系列,将活跃的安全规则作为运行时输入,支持通过快速、混合和慢速推理模式实现从快到慢的推理,并通过快慢解耦的强化学习优化,在SingGuard-Bench上取得六个基准家族(35个数据集)的最先进平均F1,该基准包含56,340个示例,涵盖超过80种细粒度风险类型,包括跨模态联合风险案例,同时在运行时策略变化下,将动态策略跟随准确率从0.6465提升至0.7415。
核心贡献
- 本文提出SingGuard,一个策略自适应的多模态护栏模型,以自然语言安全策略作为运行时输入,进行逐条规则匹配,并支持快速、混合和慢速推理模式,采用快慢解耦的强化学习实现高效、可解释的审核。
- 构建了SingGuard-Bench,一个全面的多模态护栏基准,包含56,340个示例,涵盖超过80种细粒度风险类型、跨模态联合风险案例以及动态规则评估设置,以测试策略自适应安全评估。
- 在35个数据集上的广泛实验表明,SingGuard在每个基准家族中均取得最先进平均F1,动态规则评估显示,在运行时策略变化下,策略跟随准确率从0.6465提升至0.7415。
引言
视觉语言模型如今已广泛应用于消费级助手、创意工具以及医疗、金融等高风险领域,极大地扩展了安全表面积。审核需求因产品、地区和部署阶段而异,因此实用的护栏必须根据运行时提供的活跃策略作出决策,而非仅根据静态分类法进行分类。先前的文本护栏虽能实现强审核,但依赖固定的标签集,缺乏运行时灵活性。多模态护栏扩展到视觉输入,但仍假设静态策略边界,直接对风险进行分类,而非将内容与开放规则集进行匹配。策略自适应工作表明,固定策略训练在未见过的规则下会退化,但这些工作仍集中于狭窄场景,而非一般的多模态问答和响应审核。基于推理的系统提高了可审计性,但强制使用单一、始终开启的重型推理模式,为常规案例增加了延迟。为解决这些不足,作者提出SingGuard,一个策略自适应的多模态护栏家族,接受开放的运行时策略,并执行逐条规则匹配。它支持快速、混合和慢速推理模式,并结合快慢解耦的强化学习目标,在保留低延迟判断的同时,降低其对策略锚定推理的锚定效应。该工作还贡献了SingGuard-Bench,一个全面的多模态护栏基准,涵盖动态规则、攻击变换和跨模态联合风险场景。
数据集
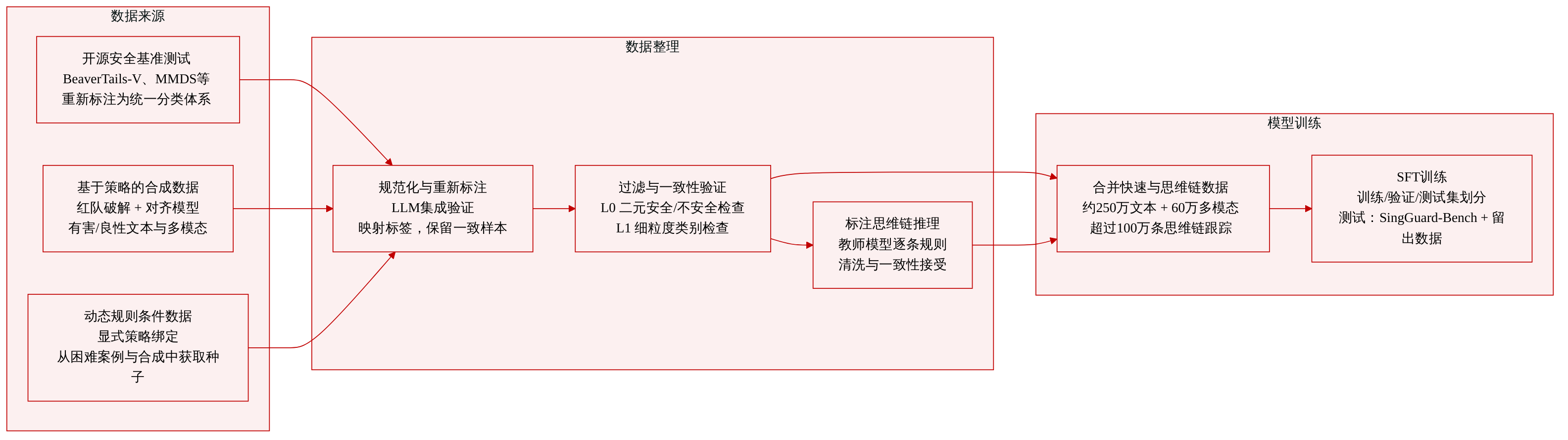
作者为SingGuard护栏模型构建了一个大规模训练语料库,以及一个独立的策略条件评估基准,即SingGuard-Bench。
训练语料库
- 规模:约250万文本样本,约60万多模态样本;超过100万样本带有思维链(CoT)推理痕迹。
- 来源与构成:
- 重新标注的开源数据:通过LLM驱动的管道,将公共安全数据集(例如BeaverTails-V、MMDS、UnsafeBench)归一化到统一的风险分类法中。一个模型集成(Qwen3.5-397B、KIMI-K2.6、GLM4.5V)验证标签映射;仅保留二分类安全性一致且细粒度类别一致的样本。模糊或困难案例被回收作为后续合成的种子。
- 基于策略的合成数据:将安全策略分解为细粒度类别。由红队越狱模型生成有害提示和响应,而对齐模型则生成无害的对比示例、拒绝和安全补全。多模态数据通过配对有害/良性图像和文本合成,包括跨模态攻击,即将有害意图拆分到不同模态中,使每个模态单独看起来安全。所有样本均经过重新验证,以确保与预期标签匹配。
- 动态规则条件数据:(参见第2.3.3节)样本与显式策略配对,将安全决策与活跃规则而非固定分类法绑定。
- CoT推理数据:在快速判断样本基础上,通过逐条规则标注构建。教师模型逐一检查每条策略规则,判断为命中/未命中/不适用,汇总每条规则的证据,并输出最终的不安全(附规则标题)或安全。推理痕迹经过结构清洗和两阶段一致性检查(CoT连贯性和答案-标签匹配)。
- 格式:统一模式,包含用户查询、可选图像、可选助手回复和对话上下文。查询侧和响应侧标签分开保存,以支持提示筛选、响应检查和联合审核。
- 使用方式:所有数据合并后用于冷启动监督微调(SFT)。CoT示例与快速判断示例结合,以训练混合推理接口。
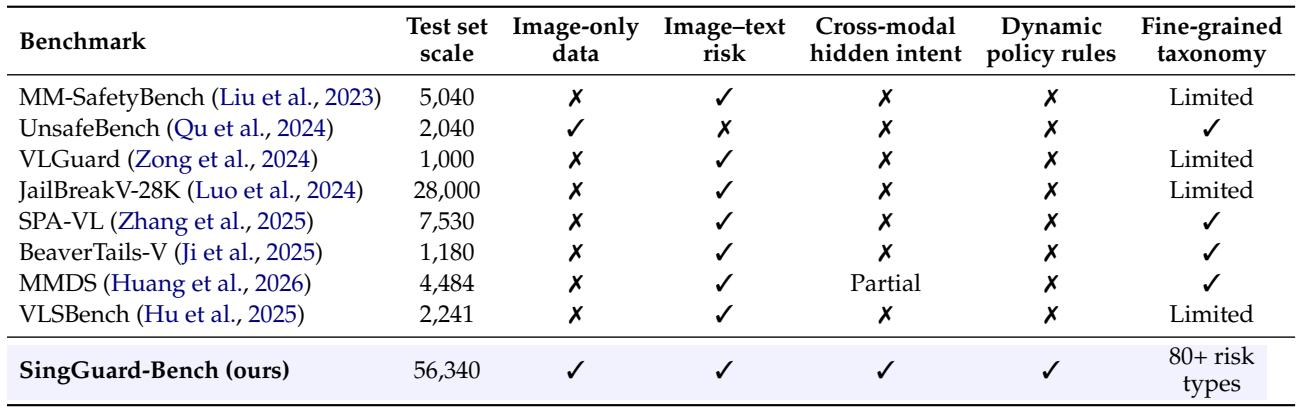
SingGuard-Bench基准
- 规模:56,340个测试示例:40,663个纯图像,13,677个多模态,2,000个动态规则。
- 子集构成:
- 图像子集:10,697张不安全图像和29,966张良性敏感图像,涵盖底线视觉风险和精度挑战。
- 多模态子集:6,487个不安全、7,190个良性敏感的图文对,标注了安全子类型(例如,图像不安全/文本安全、隐藏意图,即两个模态单独看起来都安全)。
- 动态规则子集:2,000个示例,与包含匹配和干扰规则的活跃策略配对,均匀分布在四种策略变化配置中(不安全→不安全、不安全→安全、安全→不安全、安全→安全)。
- 关键特性:超过80种细粒度风险类型,大量良性敏感内容(约占图像+多模态样本的68.4%),跨模态隐藏意图攻击,以及动态策略适应。构建过程使用关键词生成、知识图谱关联、数据补充和多模型质量过滤。
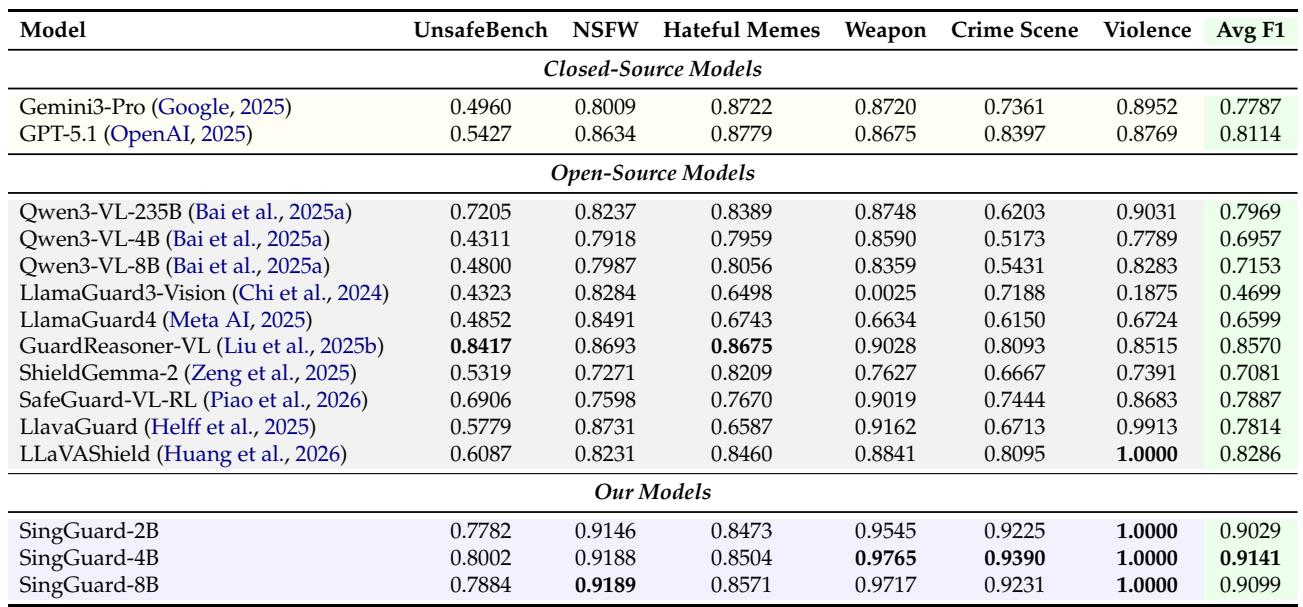
- 关键词覆盖:78个叶子节点,每种语言(英语和中文)2,124个关键词,节点间有意重叠以捕捉现实世界概念模糊性。
方法
作者提出SingGuard,一个策略条件多模态护栏模型,解决静态安全分类器的三个关键局限。第一,SingGuard不依赖固定分类法,而是在运行时接受活跃安全策略,并根据提供的规则作出决策。第二,为防止初始快速判断锚定后续推理,训练结合冷启动监督微调(SFT)与快慢解耦的强化学习阶段。第三,模型支持三种推理模式——快速直接判断、慢速逐条规则推理和混合提前退出模式——实现延迟和验证深度之间的可调权衡。
任务被形式化为指令跟随。给定输入x=(q,I,a),包括用户查询、可选图像和可选助手回复,以及活跃策略P={r1,…,rn},模型学习一个映射
fθ(x,P)→(y,z,c),其中y∈{safe,unsafe}是整体标签,z是可选的逐条规则推理痕迹,c∈T(P)∪{Safe}是最终触发的类别或规则标题。这一公式覆盖仅查询、仅响应和查询-响应审核,且决策始终与当前活跃策略绑定。
该方法建立在一个统一的分层安全分类法上,包含8个主要维度、27个二级类别和超过80种细粒度风险类型。该分类法作为内置默认策略,但在推理时,活跃策略可实例化为完整分类法、子集、缩小或扩展版本,或新引入的领域特定规则。此设计迫使模型从提供的规则集中重新推导判断,而非记忆静态类别名称。
为训练策略自适应行为,作者通过四个互补过程构建大规模语料库:开源安全数据重新标注、基于策略的合成数据生成、动态规则条件数据构建和思维链(CoT)推理标注。开源数据通过LLM驱动的重新标注管道,经两级一致性检查(二分类安全/不安全及细粒度类别)归一化到统一分类法中。合成管道组合有害和良性的图文对、跨模态攻击(意图在各模态间拆分)以及多语言变体,每种均经过策略一致性验证。动态规则数据为同一内容创建多个策略视图——完整规则、子集、单条规则以及合并或改写规则——并引入反事实监督,在编辑或新生成的审计规则下重新计算标签,产生如不安全→安全或安全→不安全的标签转换。最终,以规则为基础的方式生成超过100万CoT示例:教师模型逐步遍历每条活跃规则,记录命中/未命中/不适用判断及证据,并汇总为最终答案。这些示例经过结构清洗和两阶段一致性检查(CoT连贯性和答案-规则匹配)后,与直接判断数据合并。
训练管道分为两个阶段。第一阶段为策略条件冷启动SFT,建立共享的输出语法。所有样本遵循统一模式:快速形式输出简单的 safe 或 unsafe token,后跟 <answer> 规则标题;慢速形式插入 <reasoning> 区间,模型总结内容、检查每条活跃规则并产生复核答案。推理区间结构为z=(zsummary,m1,…,mn,zfinal),每条规则判断mi∈{hit,not-hit,not-applicable}。目标为字段加权自回归损失:
其中,对于仅快速样本,Lreason被屏蔽。此阶段混合大量快速判断示例和少量经验证的CoT痕迹,教模型在不同策略呈现下进行直接分类和逐条规则推理。
第二阶段应用快慢解耦的DAPO(通过策略优化的解耦对齐),以解决初始判断的锚定效应。模型从SFT检查点出发,采样一组G个候选输出,均遵循 <fast> → <reasoning> → <answer> 格式。两级奖励函数
对最终答案的安全极性和精确规则选择打分。奖励经组归一化以计算优势
Ai=std({Rj})+ϵRi−mean({Rj}).为解耦快慢思考,RL更新时屏蔽第一个生成的响应token,使其既不获得优势也不受策略梯度损失。后续的推理和答案token仍通过组相对奖励优化,允许慢速路径纠正不可靠的初始判断。此阶段在简单案例上保留快速路径,同时为推理区间留出修正决策的空间,特别是在分类法先验不确定的策略变化示例上。
训练后,SingGuard支持三种推理模式。快速模式直接输出初始安全标签和 <answer> 字段,适用于低延迟审核。慢速模式将初始决策视为暂定,在 <reasoning> 中进行完整的逐条规则验证,并输出复核答案。混合模式实现自适应提前退出:模型仅解码初始二进制标签,若归一化置信度
满足s(y0)≥τ,则接受;否则继续生成慢速模式推理痕迹和复核答案。这允许部署时在速度和可审计性之间取得平衡,无需单独的路由模型。
最后,模型蒸馏阶段将8B模型的基于策略的推理迁移到2B学生模型。使用在线策略的广义知识蒸馏(GKD),学生模型采样自身响应,冻结的教师模型提供token级别的目标分布。双向蒸馏目标
LGKD=Ex,y^∼πθ[αDKL(πϕteacher∥πθ)+(1−α)DKL(πθ∥πϕteacher)]使学生模型在自身生成轨迹上对齐教师模型,将教师暴露于学生模型在动态规则和边缘案例上的典型错误。这提升了紧凑模型的策略跟随和推理质量,同时保持低延迟部署。
实验
SingGuard在六个安全轴上进行评估,涵盖多模态、图像、文本查询和响应、多语言以及动态策略适应,SingGuard模型在开源基线中持续取得领先结果,并经常超越闭源替代方案。实验突显了从意图检测到辅助检测的稳健迁移、一致的跨语言性能,以及在活跃规则变化时仍可靠的策略跟随。消融实验证实,强化学习和混合路由在提高安全性的同时控制延迟,而在线策略蒸馏有效将广泛的安全行为迁移到较小的模型。
现有的多模态安全基准主要关注图文风险,但大多忽略了纯图像内容、跨模态隐藏意图、动态策略规则和细粒度分类法。仅有一个基准包含纯图像数据,仅有一个部分涉及隐藏意图,且无一结合所有评估轴。SingGuard-Bench通过统一的56,340个示例套件填补了这些空白,覆盖所有维度。仅UnsafeBench提供纯图像数据,其他所有对比基准均缺少此模态,且除MMDS中的部分实例外,无任何基准覆盖跨模态隐藏意图。此前没有任何基准支持动态策略规则或将其与细粒度风险类别结合;大多数仅提供有限或缺失的逐类别细节。
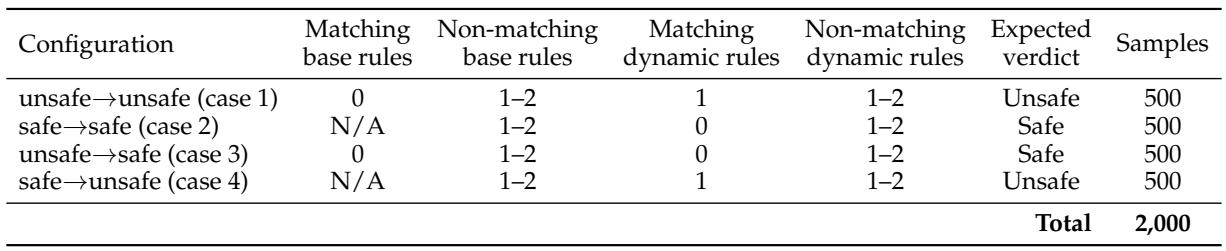
动态规则子集包含2,000个样本,均匀分布在四种策略变化配置中,每个样本与包含匹配和干扰规则的活跃策略配对。评估显示,当策略要求与训练时默认标签相反的裁决时,模型经常失败,尤其是在安全→不安全的情况下,但SingGuard的慢速推理模式将此挑战性变化的准确率从0.38提高到0.57。四种配置覆盖裁决变化的所有组合:不安全仍为不安全、安全仍为安全、不安全变为安全、安全变为不安全,各500个样本。Qwen基线在活跃策略与默认标签匹配时表现良好,但在策略变化分割上急剧下降,安全→不安全准确率仅达0.38。SingGuard-slow取得最高的平均动态策略准确率(0.7415),并将安全→不安全准确率提升至0.57,展示了对新引入限制的更好执行。混合SingGuard变体保持最强的不安全→不安全分数,同时平衡安全性和延迟,性能接近慢速推理。
安全分类法涵盖七个主要不安全风险类别,由78个细粒度叶子节点和2,124对对齐的英中关键词定义。关键词广度不均匀:犯罪与公共安全、不道德/道德和网络安全拥有最多的关键词,而Agent Safety和动物虐待类别相对较窄。每个英文关键词都有精确的一对一中文对应,确保策略评估的一致双语覆盖。该分类法涵盖七个主要不安全类别(A-G),不包括良性敏感类。犯罪与公共安全、不道德/道德和网络安全合计占2,124个关键词对的大多数。Agent Safety是最小的风险类别,仅有两个叶子节点和47对英中关键词。叶子节点数量通常与关键词数量相关,但网络安全等类别叶子节点较少,而关键词数量与不道德/道德相似。英文和中文关键词始终一一匹配,双语对齐无缺口。
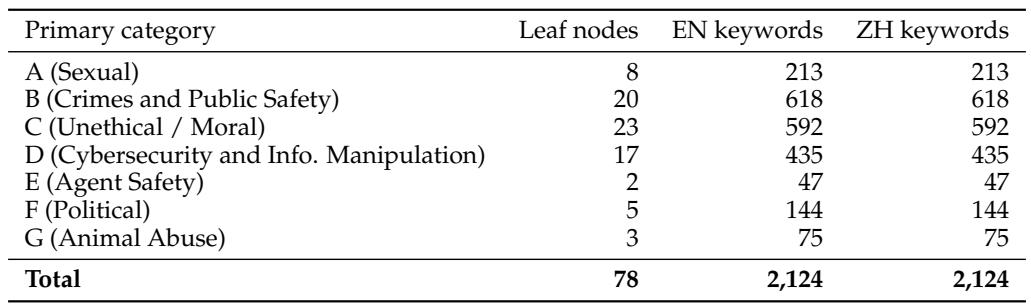
SingGuard-8B在多模态安全套件上取得新的最先进宏平均F1 0.9092,超越此前最佳开源模型LLaVAShield和GPT-5.1。较小的SingGuard-2B和SingGuard-4B变体也优于所有现有开源模型,展现了跨模型规模的帕累托改进。在单个基准上,SingGuard-8B在VLGuard和SPA-VL上表现卓越,而LLaVAShield在多个越狱和MMDS的分割上保持最高分,ShieldGemma-2在BeaverTails-V上领先。SingGuard-8B取得最高的宏平均F1,同时超越最佳开源基线和闭源GPT-5.1。每个SingGuard规模都推动了帕累托前沿,2B和4B变体已超越所有先前开源模型。LLaVAShield在JailBreakV、VLSBench、MM-Safety及两个MMDS查询和响应分割上保持领先,ShieldGemma-2在BeaverTails-V上仍最强。针对越狱的基准已被训练于越狱模板的护栏饱和,这些数据集上进一步改善的空间很小。
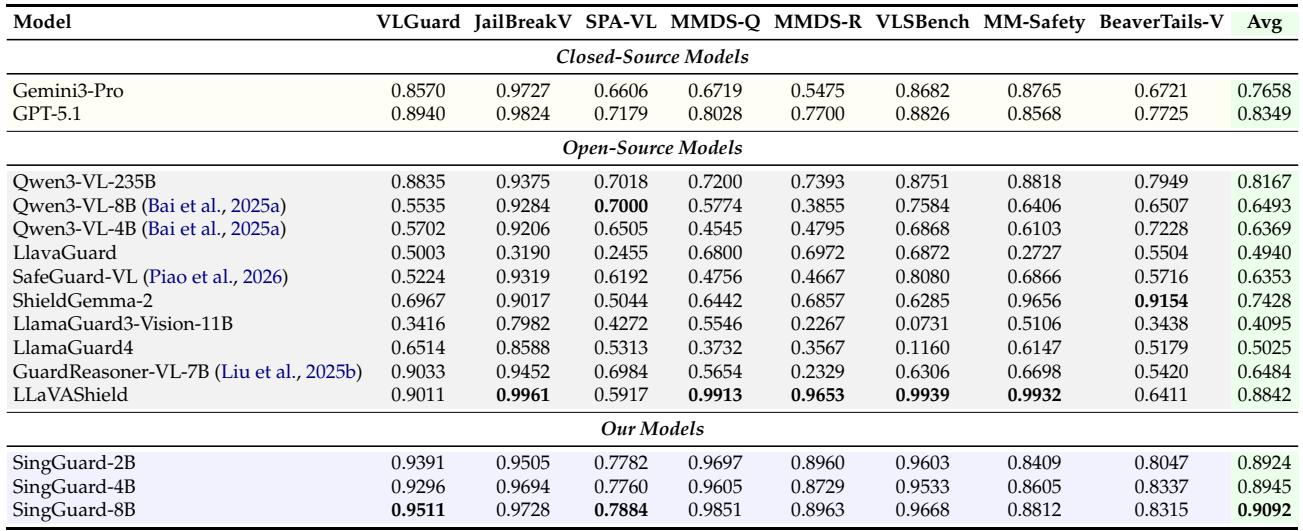
SingGuard模型取得最高的图像安全宏平均F1,超越最佳开源基线GuardReasoner-VL和闭源前沿模型。SingGuard在NSFW、武器和犯罪现场检测上领先,而GuardReasoner-VL在UnsafeBench和Hateful Memes上保持领先。若干仅文本训练的护栏在纯视觉切片(如武器和暴力)上崩溃,突显了真正多模态训练的必要性。SingGuard-4B取得最强的宏平均F1(0.9141),2B和8B变体紧随其后。SingGuard在NSFW、武器和犯罪现场检测上领先,并在饱和的暴力基准上达到F1=1.0。GuardReasoner-VL是UnsafeBench(0.8417)和Hateful Memes(0.8675)上最佳开源基线。LlamaGuard3-Vision在武器检测上降至近零F1(0.0025),揭示了纯文本训练的护栏在视觉威胁上的失败。所有SingGuard变体在平均图像安全F1上均超越闭源模型(Gemini3-Pro和GPT-5.1)。
SingGuard-Bench填补了多模态安全评估中缺失的维度,包括纯图像内容、隐藏意图和动态策略,拥有56K示例套件和2,124对关键词的细粒度双语分类法。SingGuard模型在多模态套件和纯图像威胁上取得最先进的安全F1,超越所有先前开源和闭源模型,并通过慢速推理展示在策略变化下更强的执行力。仅文本的护栏在视觉危险上崩溃,证实了真正多模态训练的必要性。