Command Palette
Search for a command to run...
PlanBench-XL:评估大语言模型工具使用智能体在大规模工具生态系统中的长程规划
PlanBench-XL:评估大语言模型工具使用智能体在大规模工具生态系统中的长程规划
摘要
LLM agents 日益在大型工具生态系统中运行,现实世界任务需要发现相关工具、推断隐式子目标,并在长周期内适应动态环境。然而,现有基准测试极少在检索受限的工具可见性条件下评估规划能力。为弥补这一空白,我们提出了 PlanBench-XL。这是一个包含 327 个零售任务、覆盖 1,665 个工具的交互式基准测试,旨在检验 agents 是否能够迭代检索可用工具,并通过调用这些工具揭示中间证据,从而为后续调用以达成最终目标提供依据。PlanBench-XL 进一步引入了一个可选的阻塞机制,该机制通过工具功能的缺失、失效或干扰来模拟现实世界的不确定性,迫使 agents 检测被中断的路径并在运行时进行动态调整。在十款主流 LLM 上的实验表明,大规模工具规划依然极具挑战:尽管 GPT-5.4 在无阻塞设置下达到了 51.90% 的准确率,但在最严重的阻塞条件下,其准确率骤降至 11.36%。进一步分析表明,当故障缺乏明确的错误提示,或恢复过程需要更长的替代工具调用路径时,agents 的脆弱性尤为突出。这些结果确立了 PlanBench-XL 作为诊断 agent 规划故障的测试平台,并凸显了在大型且不完美的工具环境中执行长周期任务时,对鲁棒自适应规划的迫切需求。
一句话总结
PlanBench-XL 通过引入可选的阻断机制来模拟现实世界的不确定性(如缺失、失败或干扰性函数),对 LLM 工具使用 agent 在 327 项零售任务和 1,665 个工具上的长周期规划能力进行评估。结果显示,GPT-5.4 在无阻断环境下的准确率为 51.90%,而在严重阻断条件下降至 11.36%,凸显了 agent 对静默故障及复杂恢复路径的脆弱性。
核心贡献
- 本文提出 PlanBench-XL,这是一个可扩展的基准测试框架,可自动生成覆盖 1,665 个工具的 327 项具象化零售任务,用于评估迭代式工具检索与中间证据发现。该框架通过提供构建多步工具使用轨迹的自动化流水线,解决了因检索受限导致的工具可见性问题。
- 动态交互环境通过可选的阻断机制模拟现实世界的不确定性,在运行过程中注入缺失、失败或干扰性的工具函数。该设计迫使 agent 检测中断的路径并实时调整规划策略。
- 对十款前沿语言模型的综合评估表明,海量工具规划依然具有挑战性,顶级模型在严重阻断条件下的准确率从 51.90% 下降至 11.36%。进一步分析显示,当故障缺乏明确错误信号或需要更长的替代工具使用路径才能恢复时,当前 agent 的表现尤为吃力。
引言
大型语言模型 agent 越来越依赖外部工具来解决企业系统和网络平台等现实环境中复杂且长周期的任务。由于上下文窗口限制了完整的工具可见性,agent 必须迭代检索并调用工具以获取中间信息,这使得自适应规划在实际部署中至关重要。然而,以往的基准测试通常假设工具集是固定且完全可见的,具备清晰的描述和明确的目标,很大程度上忽略了定义实际工具生态系统的检索噪声、缺失或失败的函数以及动态路径中断。为弥补这一差距,本文提出 PlanBench-XL,这是一个包含 327 项跨 1,665 个工具的多步零售任务的交互式基准测试,迫使 agent 在部分可见的环境中导航并从模拟的工具故障中恢复。通过对十款领先模型的评估,研究证明了当前 agent 在不可靠条件下进行海量工具规划时面临显著困难,从而为开发稳健、自适应的 agentic 系统建立了新的测试平台。
数据集
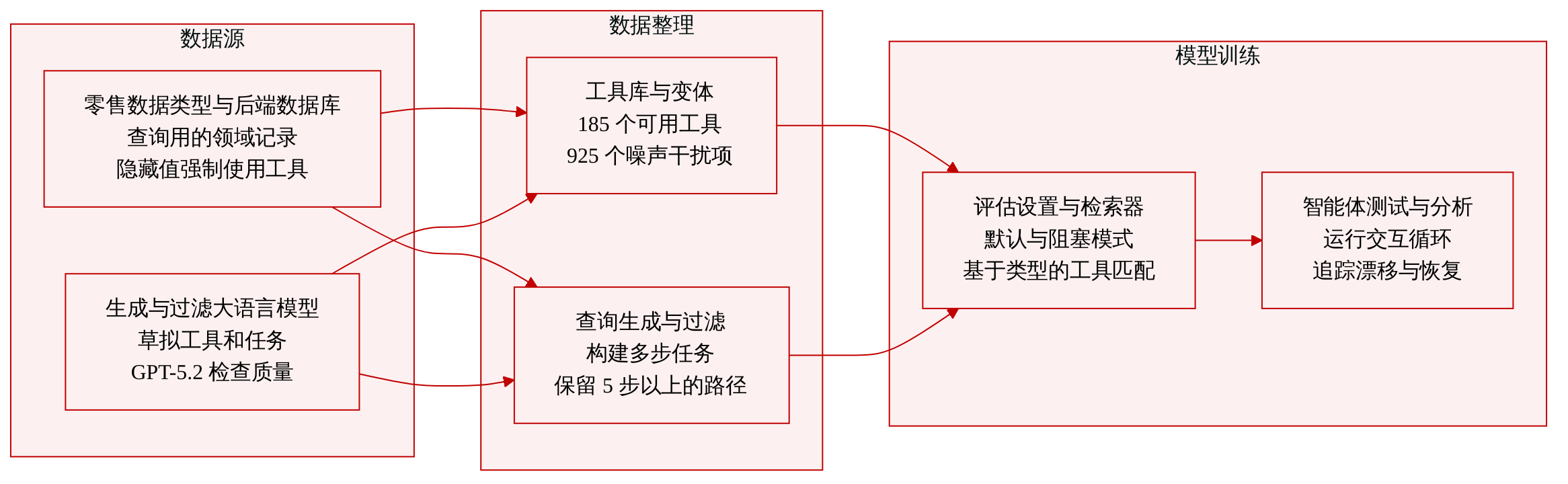
Dataset Composition and Sources
- 本文提出 PlanBench-XL,这是一个专注于零售领域的合成基准测试,旨在评估海量工具使用环境中的长周期规划与工具探索能力。
- 数据集采用由生成和过滤语言模型驱动的可扩展流水线构建,其中使用 GPT-5.2 执行过滤任务以确保质量控制。
- 该环境依赖于一组自定义的领域特定数据类型,用于表示不同的零售信息,并作为工具模式与后端记录的基础。
Key Details for Each Subset
- Executable Tools: 工具库包含 185 个工具,由输入和输出数据类型的组合对生成。输入模式包含 1 到 5 个数据类型,而输出模式严格包含 1 个数据类型。
- Noisy Tools: 本文在工具库中增加了 925 个噪声工具,为每个可执行工具创建五个变体以模拟真实的检索缺陷。这些变体涵盖已弃用、条件受限、过期、不可靠和非权威行为等类别。
- Queries: 任务通过指定初始和目标数据类型集、计算有效工具序列,并使用从后端数据库实例化的具体实体将任务转化为自然语言来生成。
- Filtering Rules: 对工具进行过滤以强制执行确定性依赖关系,确保信息访问需要实际执行工具,保持领域真实性,并保证非平凡的信息增益。仅当最短解决路径需要至少五次不同的工具调用且所有声明的输入均为解决所必需时,才保留该查询。
Data Usage and Processing
- Evaluation Modes: 基准测试支持带有检索噪声的默认模式以及用于破坏有效路径以评估 agent 恢复与重规划能力的阻断模式。
- Backend Construction: 后端数据库使用非平凡值进行实例化以强制触发工具调用,因为输出无法仅凭常识或查询文本推断得出。
- Ground Truth: 通过逆向搜索算法推导过程级真实标签,以识别能将初始数据类型转换为目标数据类型的最小包含工具集及合法执行顺序。
- Retrieval Strategy: 工具通过自定义检索器暴露,该检索器支持双向探索,基于数据类型结构而非表层文本描述将查询与工具进行匹配。
Metadata and Additional Processing
- Internal Metadata: 数据集包含跟踪输入和输出数据类型的元数据,用于依赖验证、进度调用标注及评估诊断。
- Agent-Schema: 提供给模型的信息包括函数名称、描述、参数和严格性约束,数据类型标注被隐藏为内部元数据以防止直接进行图结构还原。
- Naming Convention: 工具名称遵循基于别名的模板,并带有可选的版本后缀,以模拟现实世界的不一致性并避免简单的名称匹配。
- Failure Annotations: 轨迹被标注以根据工具调用是否产生有用的中间证据,将故障分类为无进展、不可恢复漂移、弱恢复和格式错误。
实验
PlanBench-XL 基准测试在海量工具生态系统中评估前沿与开源 LLM 的长周期自适应规划能力,采用基线评估、检索时阻断、强制探索及路径长度变化来验证核心能力、对损坏工具的鲁棒性、自适应恢复潜力及复杂度容忍度。结果表明,尽管广泛探索与精确执行能显著推动任务成功,但当前模型在工具静默损坏或恢复路径延长时始终难以适应,增加测试时算力仅带来边际收益。定性分析显示,性能瓶颈主要源于轨迹漂移与工具选择缺陷,而非检索限制,凸显了 agent 必须可靠检测不可靠反馈并在部分可观测条件下动态重规划的需求。
评估结果显示,前沿模型与较小规模的开源变体之间存在显著的性能差距,较大架构在任务完成度与执行精度方面始终表现出优势。尽管对可用工具数据类型的广泛探索通常与更高的成功率相关,但过度的检索活动并不能保证有效进展,因为部分模型会在无信息的搜索上浪费交互轮次。此外,保持基础的工具使用可靠性依然至关重要,成功最小化无效调用并过滤不受信任输入的模型能够实现显著更高的整体准确率。较大规模的模型变体在任务完成准确率和执行质量上始终优于较小变体。过多的检索轮次和较高的搜索到调用比例并不必然转化为成功的任务完成或高效的探索。最小化结构无效的工具调用并拒绝不受信任的输入与更高的整体任务成功率密切相关。
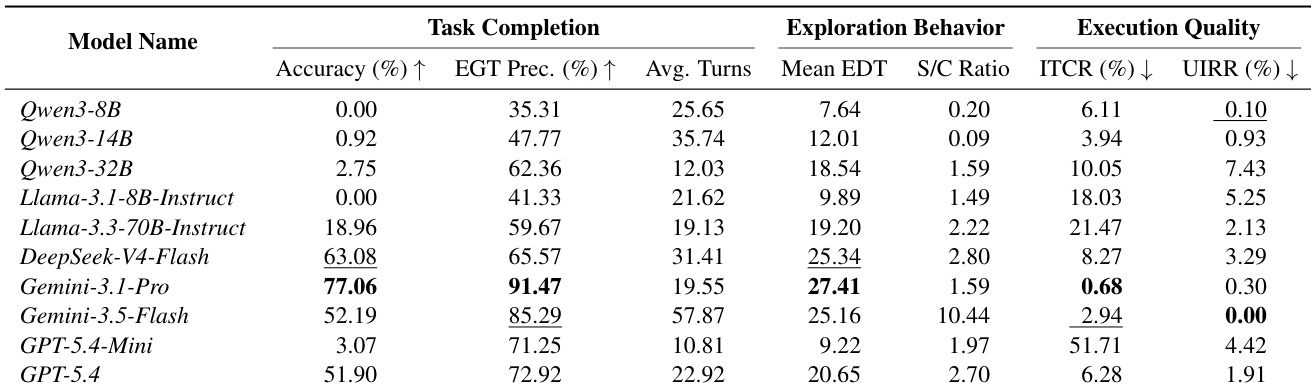
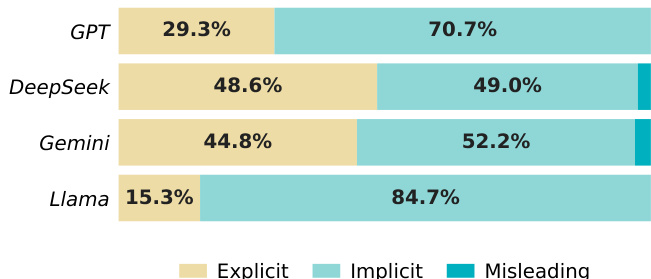
对阻断替代调用的分析显示,模型主要与显式和隐式故障交互,同时很大程度上避免使用语义误导性的工具。架构差异导致故障偏好不同,部分模型严重倾向于静默故障,而其他模型在显式和隐式错误类型之间表现出更均衡的分布。这种分布凸显了 agent 在处理看似可执行但细微的故障时,相较于明显的语义不匹配所面临的显著挑战。模型始终避免使用语义误导性的工具,证明了初始工具过滤的有效性。Llama 和 GPT 表现出强烈倾向于调用隐式故障而非显式故障的倾向。DeepSeek 和 Gemini 则对显式和隐式故障类型的依赖更为均衡。
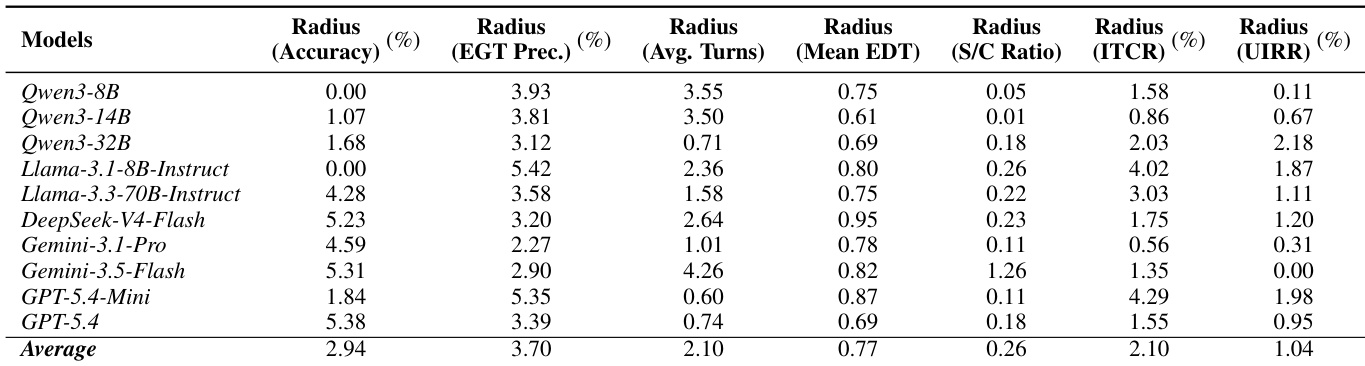
本文通过计算多个模型与评估指标下的置信区间来评估基准测试的统计可靠性。报告的不确定性范围相对于模型间观察到的性能差距始终较为狭窄,表明主要发现具有稳定性,并非由随机采样变异驱动。在所有测试模型和指标类别中,统计不确定性均保持在极低水平。狭窄的置信区间证实,观察到的性能差异反映了真实的能力变化,而非采样噪声。鲁棒性分析表明,该基准测试在重复评估条件下能够产生一致的结果。
本文在单步工具检索任务上评估了一个较小的开源模型,以验证基准测试结果并非主要受限于检索器的覆盖范围。该模型在定位和执行正确工具方面展现出强大能力,高度契合理想的交互模式。高执行精度与无无效调用的表现表明,检索系统与运行时协议能够可靠地为简单查询提供有效工具。高准确率与精度反映了可靠的任务完成与相关执行。检索系统频繁包含真实标签工具,支持有效的单步规划。交互长度高度契合理想轨迹,未出现结构或过程调用故障。

本文提出一个综合评估框架,同时涵盖工具使用规划的多项关键维度,包括检索、子目标推理、探索及不可靠工具处理。与仅关注孤立能力的以往基准测试不同,该框架整合了所有关键特性,以全面评估 agent 在大规模工具生态系统中的表现。现有基准测试通常仅评估有限的工具使用能力子集,使得双向探索与不可靠工具处理等关键领域基本未经测试。所提出的框架独特地覆盖了全部七个评估维度,从而能够更完整地评估 agent 的适应性与鲁棒性。这一综合设计凸显了当前评估套件中的显著空白,后者往往忽视长周期规划与工具可靠性之间的相互作用。

该评估采用综合框架,全面衡量多维度的工具使用能力,包括检索、推理、探索与不可靠工具处理。实验验证了较大规模的前沿模型在执行精度方面始终优于较小变体,同时表明过度的搜索活动会阻碍效率,且最小化无效调用与过滤不受信任输入是成功的关键。故障模式分析显示,agent 能有效避免语义误导性的工具,但在处理细微的隐式故障时面临困难,架构差异对错误偏好具有重大影响。额外的可靠性与检索测试证实,观察到的性能差距反映了真实的能力差异,而非采样噪声或系统限制。