Command Palette
Search for a command to run...
EvoEmbedding:面向长上下文检索与智能体记忆的可进化表示
EvoEmbedding:面向长上下文检索与智能体记忆的可进化表示
Chang Nie Chaoyou Fu Junlan Feng Caifeng Shan
摘要
现有的嵌入模型本质上是静态的:它们孤立地对文本片段进行编码,忽略了其周围的上下文与时间顺序。本文提出了一种名为EvoEmbedding的新型嵌入模型,该模型能够生成用于检索的可演化表示。该模型专为长上下文场景量身定制,在此类场景中,信息具有动态性、序列性,且需要持续的状态跟踪。我们的设计十分简洁:EvoEmbedding在顺序处理输入的过程中维护一个持续更新的潜在记忆,并将其与原始内容结合,共同生成可演化的嵌入表示。因此,对于相同的查询,我们的模型能够根据不断演化的上下文自适应地调整其表示,以检索不同的目标,从而超越了静态语义搜索。为使模型具备此能力,我们构建了EvoTrain-180K数据集,这是一个用于潜在记忆与检索联合优化的多样化数据集。此外,我们引入了一个记忆队列以防止在循环编码过程中出现表示崩溃,并配合分段批处理技术来解决显著的长度差异问题,同时将训练速度提升了3.8倍。大量实验表明,我们的模型不仅在一系列长上下文检索基准测试中优于更大规模的专用模型(例如Qwen3-Embedding-8B和KaLM-Embedding-Gemma3-12B),而且在上下文长度达到其训练窗口10倍的下游任务(例如个性化)中也展现出良好的泛化能力。值得注意的是,EvoEmbedding能够无缝集成到agent工作流中以提升性能。例如,配备我们模型的简单RAG流水线超越了专用的agent记忆系统。项目页面:https://clare-nie.github.io/EvoEmbedding。
一句话总结
EvoEmbedding 通过顺序更新潜在记忆来生成可演化的表示,从而实现长上下文检索。在既定基准测试中,其表现优于更大的静态嵌入模型;能够泛化到上下文长度达到训练窗口十倍的下游任务;并能无缝增强 Agent RAG 管道。
核心贡献
- 本文提出了 EvoEmbedding,这是一种新颖的架构,通过维护持续更新的潜在记忆来生成上下文相关的可演化表示,以支持长上下文检索。通过引入记忆队列以防止表示坍缩,并结合片段批处理技术,该模型能够高效捕捉时间动态,同时将训练速度提升 3.8 倍。
- 该研究推出了 EvoTrain-180K,这是一个多样化的数据集,专为在不同上下文长度下联合优化潜在记忆与检索而设计。该数据集使模型无需课程学习即可掌握动态上下文追踪与时间检索能力。
- 在十项长上下文检索基准测试上的广泛评估表明,该模型达到了最先进的准确率,以 11.1% 的优势超越 Qwen3-Embedding-8B。该架构可泛化至 128K 上下文,在零额外 memory token 开销的情况下增强 Agent RAG 管道,并将时间查询意图与粗略语义匹配解耦。
引言
检索增强生成(RAG)已成为赋予大语言模型长期记忆的关键技术,尤其适用于 AI Agent 处理动态的序列信息。传统的嵌入模型以静态方式运行,独立编码文本片段,这破坏了时间连续性,使其难以胜任需要连续状态追踪或共指消解的任务。为克服这些限制,研究团队提出了 EvoEmbedding。该框架通过维护持续更新的潜在记忆,在新输入到达时生成上下文感知的表示。研究团队利用专为训练设计的数据集与记忆队列来防止表示坍缩,使模型能够动态适应不断变化的上下文,同时规避传统管道修改带来的计算开销。
数据集

-
数据集构成与来源: 研究团队构建了 EvoTrain-180K,这是一个专为长上下文检索设计的大规模合成数据集。该集合融合了三种主要上下文类型:从 FineWeb 采样的顺序文本片段、由大语言模型生成的多轮角色对话,以及从网页和对话来源提取的记忆片段。
-
子集细节与过滤规则: 最终流水线产出 184,137 个高质量样本。为确保多样性,团队采用四十余种预定义问题模板,并利用不同规模的大语言模型生成从基础语义匹配到复杂推理的查询。由 Gemini-3.1-Pro-Preview 驱动的验证阶段会对正样本检索目标进行标注,严格过滤幻觉内容,并强制要求答案仅依赖所提供的上下文。
-
训练用途与处理: 完整数据集用于联合训练 EvoEmbedding 的记忆与检索能力。研究团队应用严格的长度限制以优化训练效率,将每个样本上限设定为 12,000 tokens 与 256 个片段。
-
其他处理步骤: 原始网页文档首先采用滑动窗口技术进行分块。自动化工作流随后通过定位相关片段的确切索引来构建检索元数据,并将其作为正样本目标。这一严格的合成与验证流程确保了模型能够实现强大的泛化能力,同时相比标准嵌入模型显著减少数据需求与训练上下文长度。
实验
评估涵盖检索与生成任务中的十项多样化基准测试,将 EvoEmbedding 与标准稠密检索器、专用 Agent 记忆系统以及高级优化策略进行对比。结果验证了该模型在长上下文方面的强大可扩展性与泛化能力,表明简洁的 RAG 管道能够持续优于复杂的记忆架构,同时消除不必要的 token 开销。附加分析确认了该方法的即插即用兼容性,以及通过在潜在空间中清晰结构化历史上下文来捕捉时间语义的独特能力。最后,消融实验与效率研究确立核心潜在记忆机制对表示质量不可或缺,尽管编码时间略有增加,但仍显著降低了峰值 GPU 显存占用。
研究团队在多样化的检索与生成基准测试中对 EvoEmbedding 与多种基线模型进行了对比评估。结果表明,EvoEmbedding-4B 变体在整个任务套件中实现了最高的综合性能,超越了 KaLM-Embedding-Gemma3 与 Qwen3-Embedding-8B 等更大规模的模型。尽管特定基线模型在细分的长上下文场景中表现优异,但 EvoEmbedding 在整个评估中展现出更优的泛化能力与一致性。EvoEmbedding-4B 在所有测试基准中均取得最佳综合表现,在召回率与排序指标上大幅领先规模显著更大的基线模型。EvoEmbedding 的较小变体(如 2B 模型)展现出强劲竞争力,在 QASPER 与 PeerQA 等特定数据集上频繁超越规模大得多的模型。尽管 KaLM-Embedding-Gemma3 在 LongMemEval 等特定长上下文基准中领先,EvoEmbedding 在综合总分上仍保持显著优势。
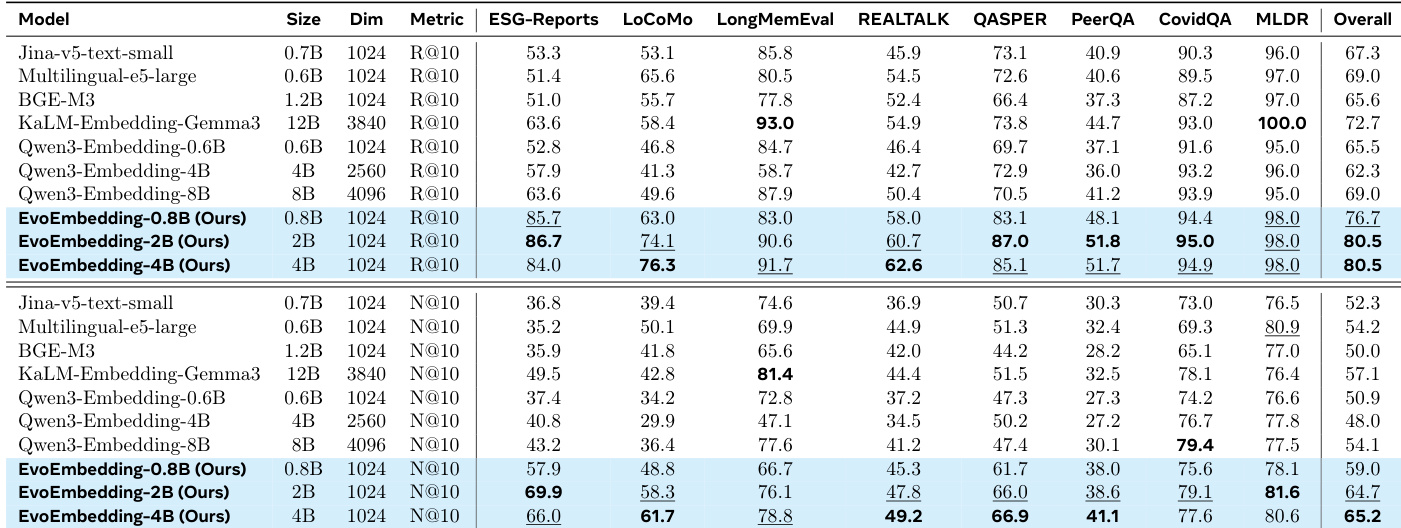
消融研究证实,潜在记忆机制是模型成功的基础,而特定的批处理策略对训练效率至关重要。移除记忆队列或记忆损失会导致灾难性的性能崩溃,尤其在长上下文基准测试中,并显著增加训练时间。相比之下,省略片段批处理会大幅拖慢训练速度,仅对准确率产生轻微影响;而移除长度加权则会导致整体性能出现适度下滑。移除记忆队列或损失会在对话与长上下文基准测试中引发严重的性能退化。片段批处理对计算效率至关重要,因为其移除会大幅增加训练时间,仅带来准确率的微小下降。长度加权提供了有益的正则化效果,缺失该机制会导致模型整体性能出现明显下滑。

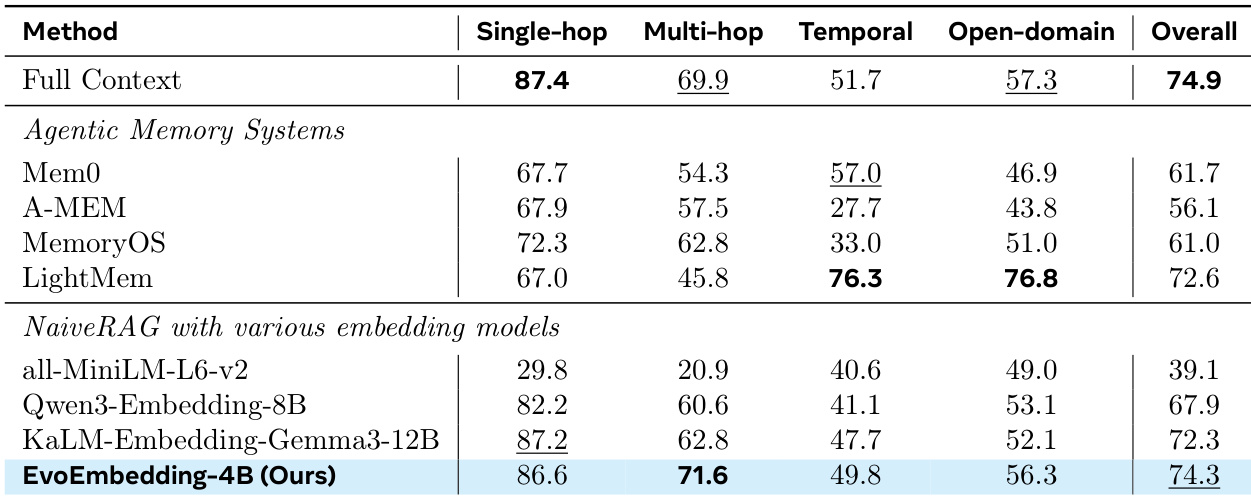
在所有评估模型中,EvoEmbedding-4B 实现了最高的综合性能(77.6),超越了 LightMem(70.2)等 Agent 记忆系统以及 KaLM-Embedding-Gemma3-12B(72.8)等标准嵌入基线。该模型在多个维度上展现出卓越能力,尤其在时间推理、多会话对话与知识保留方面表现突出,同时在用户与助手追踪方面保持强劲性能。EvoEmbedding-4B 取得 77.6 的最高综合得分,优于表现最佳的 Agent 记忆系统(LightMem,70.2)与最强的嵌入基线(KaLM-Embedding-Gemma3-12B,72.8)。该模型在特定子任务中表现优异,在时间推理(63.2)、多会话对话(71.4)与知识(84.6)指标上均位列所有列出模型之首。EvoEmbedding-4B 在用户追踪(98.6)与助手追踪(100.0)上达到近乎完美的表现,甚至超越 Full Context 基线。
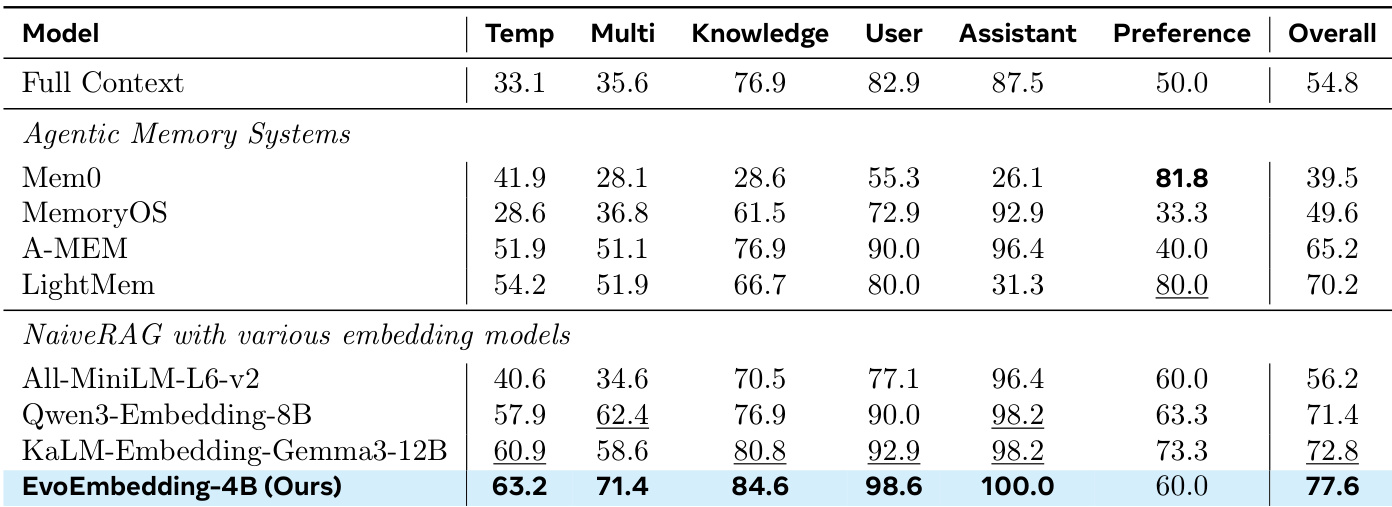
研究团队将 EvoEmbedding 与静态嵌入基线进行对比,以评估编码效率与检索性能之间的权衡。结果表明,尽管 EvoEmbedding 因顺序处理导致上下文编码时间较长,但相比更大规模的模型,其实现了最佳准确率并显著降低了峰值 GPU 显存占用。EvoEmbedding 取得了最高的检索准确率,超越了规模更大的基线模型。该方法所需的峰值 GPU 显存显著低于竞争性静态嵌入方案。该模型以编码速度换取性能,展现出最长的上下文编码时间,但交付了最佳结果。
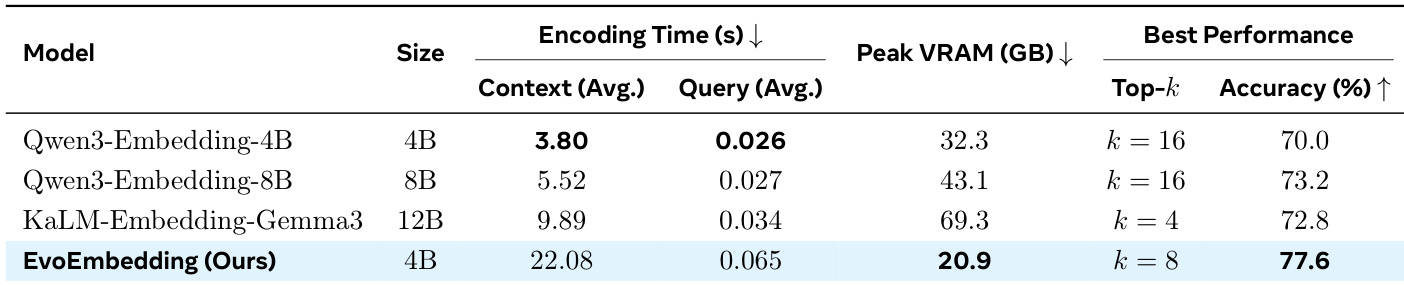
在多样化的检索与长上下文基准测试中,与标准嵌入基线及 Agent 记忆系统相比,主实验验证了 EvoEmbedding 在顺序编码开销下仍具备卓越的准确率与泛化能力。专项效率评估确认,该模型在实现顶级检索性能的同时,相比更大规模的静态方案显著降低了峰值 GPU 显存需求。此外,消融研究证实潜在记忆机制对长上下文保留不可或缺,而特定的批处理策略对维持训练效率至关重要。综合来看,这些结果表明 EvoEmbedding 有效平衡了计算约束与强大的多会话对话及知识追踪能力。