Command Palette
Search for a command to run...
世界动作模型:综述
世界动作模型:综述
Qiuhong Shen Shihua Zhang Yue Liao Qi Li Zhenxiong Tan Shizun Wang Shuicheng Yan Xinchao Wang
摘要
世界动作模型(WAMs)是一类具身预测-动作模型,其使对未来的预测可供动作调用。近期的WAMs多对大型视频生成模型进行改造复用,而另一并行路线则依赖于语言或视觉-语言骨干网络,且不包含视频生成核心。这一快速扩张已模糊了广义世界模型、视频生成模型、动作接地视频世界模型、视觉-语言-动作策略以及WAMs之间的界限。本综述为该领域提供了统一的梳理与概述。本文首先厘清上述界限,随后通过两个互补的视角对现有工作进行系统组织。第一个视角关注各方法所需生成的内容,涵盖渲染的未来、隐空间未来以及无需视频生成的动作推理。第二个视角则从预测基底、骨干网络、动作耦合方式以及部署机制四个维度对各方法进行拆解分析。基于此分类框架,本文统一探讨了可交互性、因果性、持久性、物理合理性及泛化性等核心议题,并进一步综述了数据资源、评估方法与开放挑战。纵观上述维度,一种一致的设计范式逐渐显现:WAMs并非仅仅是附加了动作头的视频生成器,而是预测-动作方法,其设计选择需在表示丰富度与计算开销、内存占用、延迟及动作标签成本之间进行权衡。该领域正朝着生成更少的未来内容同时保留控制所需关键信息的方法演进。本综述的官方主页位于 https://world-action-models.github.io/。
一句话总结
本综述厘清了世界动作模型(WAMs)与相关系统之间的边界,根据预测基底(predictive substrate)和动作耦合(action coupling)对现有方法进行分类,并识别出一种一致的设计模式:以计算、内存、延迟和动作标签成本换取表征丰富度。
核心贡献
- 本综述厘清了世界动作模型、视频生成模型、视觉-语言-动作策略以及更广泛的世界模型之间的概念边界,以建立统一的分析术语。
- 该框架引入双重视角,根据生成需求对现有方法进行分类,并系统性地从预测基底、骨干网络、动作耦合和部署模式四个维度对其进行分解。
- 该框架对交互性、因果性、持久性、物理合理性和泛化性等核心控制属性提供了统一分析,同时识别出一种一致的设计模式,即预测-动作方法以计算、内存、延迟和动作标签成本换取表征丰富度。
引言
具身智能正从反应式策略转向预测式系统,该系统在动作选择前预先感知环境动态。世界动作模型(WAMs)通过将未来模拟与实时控制相耦合来实现这一转变,使机器人能够在非结构化环境中对物理特性、接触条件和任务后果进行推理。然而,先前的方法存在架构碎片化和术语不一致的问题。反应式视觉-语言-动作模型缺乏明确的环境建模,而以视频为中心的世界模型往往优先考虑照片级真实感而非与动作相关的线索,导致计算量过大和延迟过高,进而破坏闭环控制。基于此背景,本文提供了一份全面的综述,形式化了 WAM 的定义,并通过两个互补的框架对快速增长的文献进行了整理。作者引入了基于生成目标的哲学层面分类法,以及追踪预测基底、骨干网络、动作耦合和部署模式的组件层面解剖结构。这种统一的结构实现了系统的模型对比,阐明了物理合理性和因果性等关键的具身要求,并指出了在平衡预测保真度与控制效率方面的关键开放挑战。
数据集
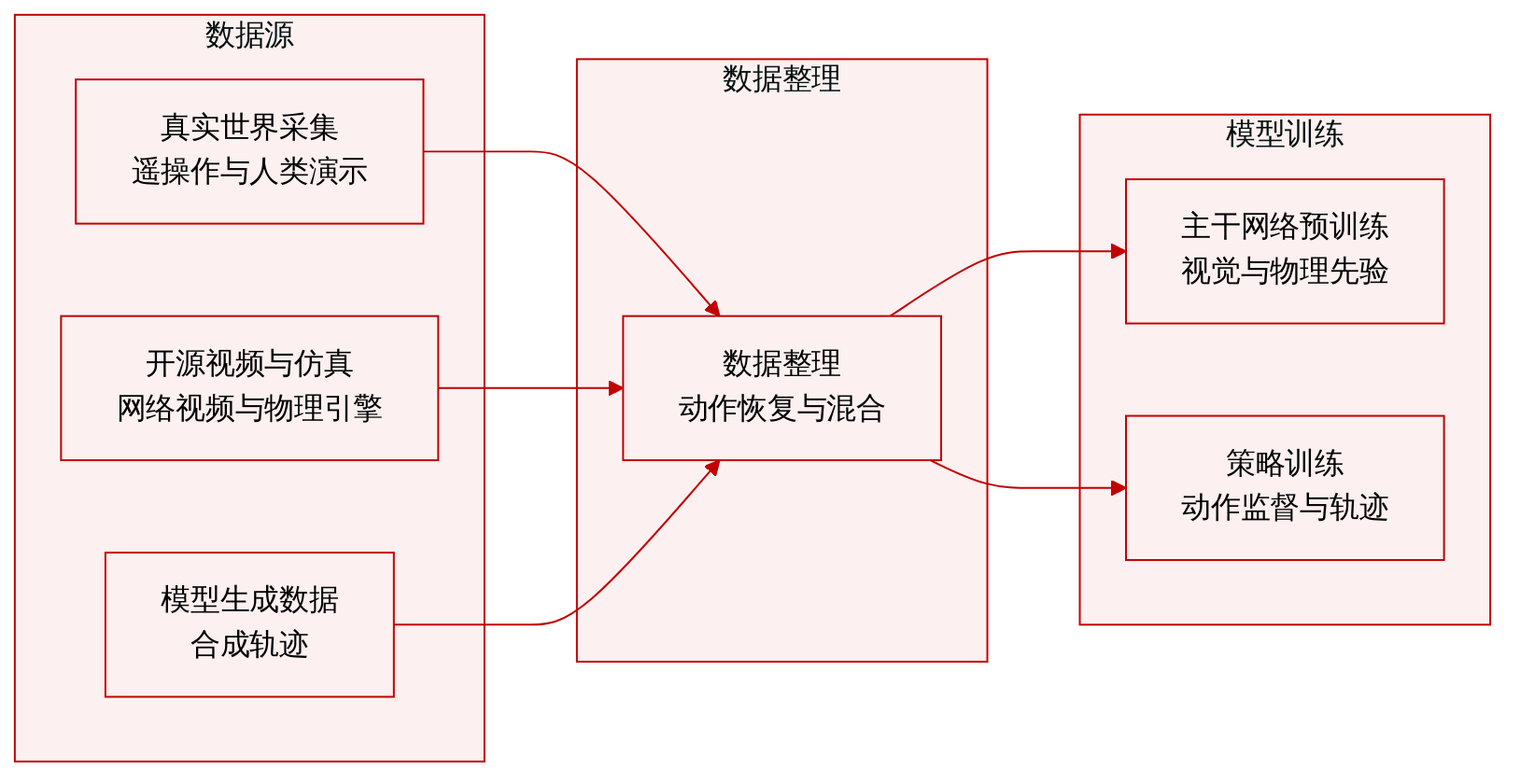
• 数据集构成与来源:作者根据规模、动作标签质量与具身对齐之间的权衡,将训练语料库划分为五个主要类别。这些类别涵盖机器人遥操作录制数据、便携式人类演示数据、互联网规模的自我中心视角与教学视频、基于物理与数字孪生的仿真数据,以及由模型自身生成的合成数据。
• 子集详情:Open X-Embodiment 和 RoboNet 等机器人遥操作数据集提供高标签保真度的精确动作指令,但需要大量操作员与机器人时间。来自 EgoVerse 和 EgoDex 等平台的便携式人类演示通过可穿戴设备或手机采集提高了数据收集吞吐量,但引入了具身差距。包含 Ego4D、EPIC-KITCHENS 和 EgoScale 在内的互联网视频数据集提供了海量的视觉变化与操作模式,但缺乏显式的动作通道。ManiSkill、LIBERO 和 RoboCasa 等仿真环境以较低边际成本提供精确标签与受控课程,但存在仿真到现实的差距。由扩散模型或视频生成器产生的合成轨迹弥合了仿真与现实数据之间的鸿沟,同时继承了视觉真实感与生成器的故障模式。
• 训练用途与混合策略:作者混合这些来源以平衡视觉先验、可信的动作标签、数据规模与可控覆盖率。互联网视频主要用于预训练视频骨干网络,或训练恢复控制代理的反向动力学与潜在动作模型。遥操作数据提供真实动作监督,而仿真与合成轨迹则填补了物理采集成本高昂的数据空白。论文指出,特定部署模式下的最优混合比例仍是一个未解决的研究问题,且访问限制使得对部分大规模来源的独立验证受到限制。
• 处理与评估流程:所提供的文本未明确说明具体的裁剪策略或详细的元数据构建流程。处理过程主要聚焦于动作恢复技术,例如将人类演示跨机器人具身进行重定向、从无标签视频中提取伪动作,以及直接在神经轨迹上训练最终策略。作者采用两阶段协议评估生成的模型,将轻量级视觉保真度指标与在明确计算、内存和延迟约束下的选择性闭环成功测试相结合。
方法
作者提出了一个世界动作模型的统一框架,从根本上将预测的未来观测与动作生成相联系。与直接将当前上下文映射到动作的标准视觉-语言-动作模型,或预测未来状态但不一定指导控制的传统世界模型不同,世界动作模型确保预测的未来观测主动塑造、评估或训练动作路径。核心契约被形式化为对未来预测窗口和未来动作的条件联合分布,以观测历史、过去动作和任务指令为条件,表示为 pΘ(st+1:t+H,at:t+H−1∣c)。该公式确立了操作边界,其中任何预测的未来都必须直接参与后续动作的生成、评估、验证或训练。如下图所示:

为了梳理该领域多样化的实现方式,作者根据推理过程中未来预测器与动作模块的交汇点,将现有模型划分为三种互斥的设计哲学。参考框架图:
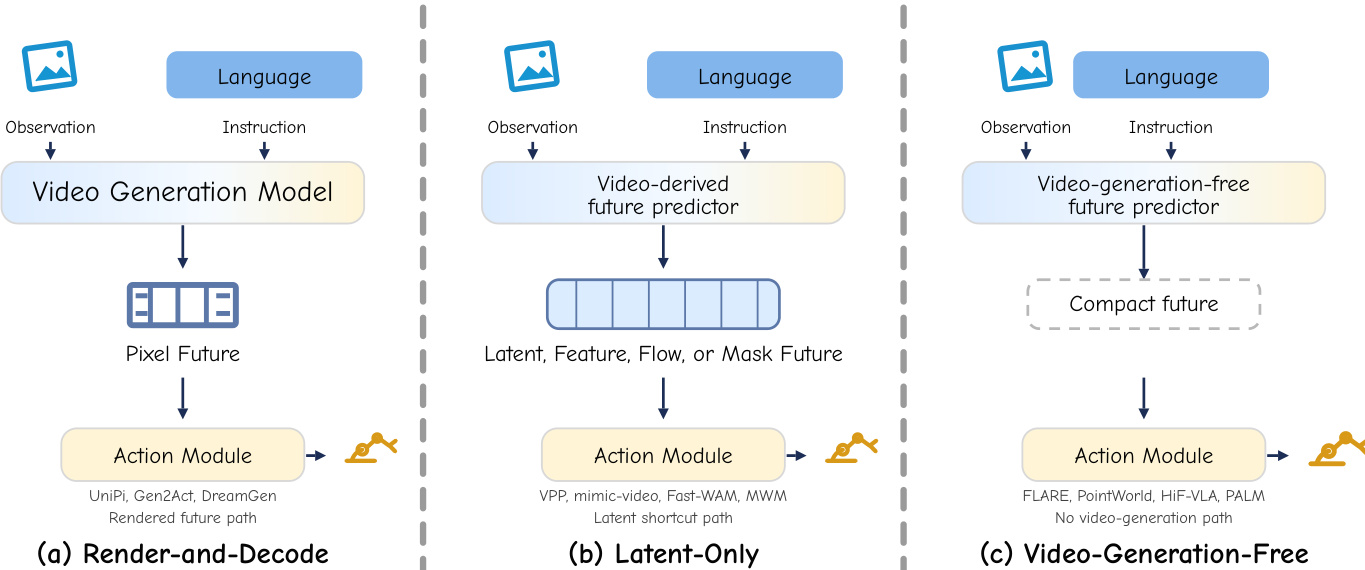 第一种哲学让视频生成骨干网络一直运行至像素输出,随后再解码动作。这保留了完整的视觉先验,但会带来高延迟。第二种哲学保留了视频衍生的动态先验,但在中间潜在变量、去噪特征或流场与掩码等结构化字段处拦截推理路径,绕过像素解码以降低计算成本。第三种哲学完全移除了视频生成骨干网络。取而代之的是,它在紧凑的表征空间中利用预测监督,例如大语言模型或视觉-语言模型的嵌入空间、联合嵌入预测编码器或非视频扩散骨干网络,并将轻量级动作专家附加到这些紧凑的未来表示上。
第一种哲学让视频生成骨干网络一直运行至像素输出,随后再解码动作。这保留了完整的视觉先验,但会带来高延迟。第二种哲学保留了视频衍生的动态先验,但在中间潜在变量、去噪特征或流场与掩码等结构化字段处拦截推理路径,绕过像素解码以降低计算成本。第三种哲学完全移除了视频生成骨干网络。取而代之的是,它在紧凑的表征空间中利用预测监督,例如大语言模型或视觉-语言模型的嵌入空间、联合嵌入预测编码器或非视频扩散骨干网络,并将轻量级动作专家附加到这些紧凑的未来表示上。
基于这些设计哲学,作者将任意世界动作模型分解为四个可分离但相互作用的的设计轴。如下图所示:
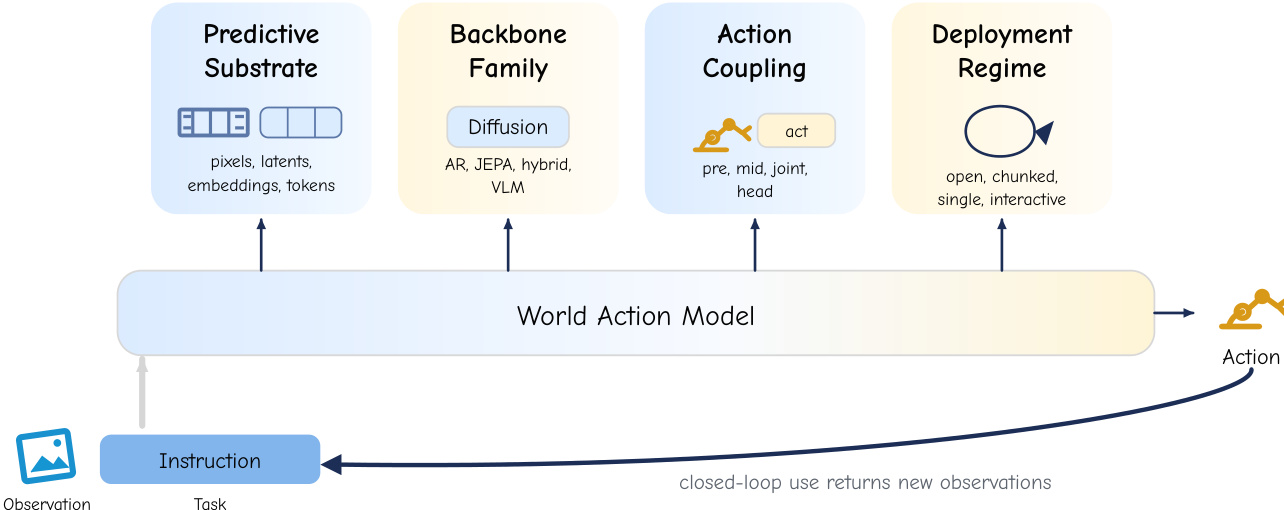 第一个轴是预测基底,它定义了未来变量的表征空间。第二个轴是架构骨干,它决定了预测的生成方式,包括迭代去噪网络、自回归解码器、联合嵌入预测器、混合架构或大语言与视觉-语言模型。第三个轴是动作耦合,它规定了联合分布的因子化方式,并决定动作如何进入或离开预测循环。第四个轴是部署模式,它控制相对于控制循环的调用频率与预测视距,涵盖从开环轨迹生成到分块闭环控制、单步执行以及交互式仿真器操作。
第一个轴是预测基底,它定义了未来变量的表征空间。第二个轴是架构骨干,它决定了预测的生成方式,包括迭代去噪网络、自回归解码器、联合嵌入预测器、混合架构或大语言与视觉-语言模型。第三个轴是动作耦合,它规定了联合分布的因子化方式,并决定动作如何进入或离开预测循环。第四个轴是部署模式,它控制相对于控制循环的调用频率与预测视距,涵盖从开环轨迹生成到分块闭环控制、单步执行以及交互式仿真器操作。
聚焦于预测基底,作者将未来表征分为四个不同的类别。参考下图:
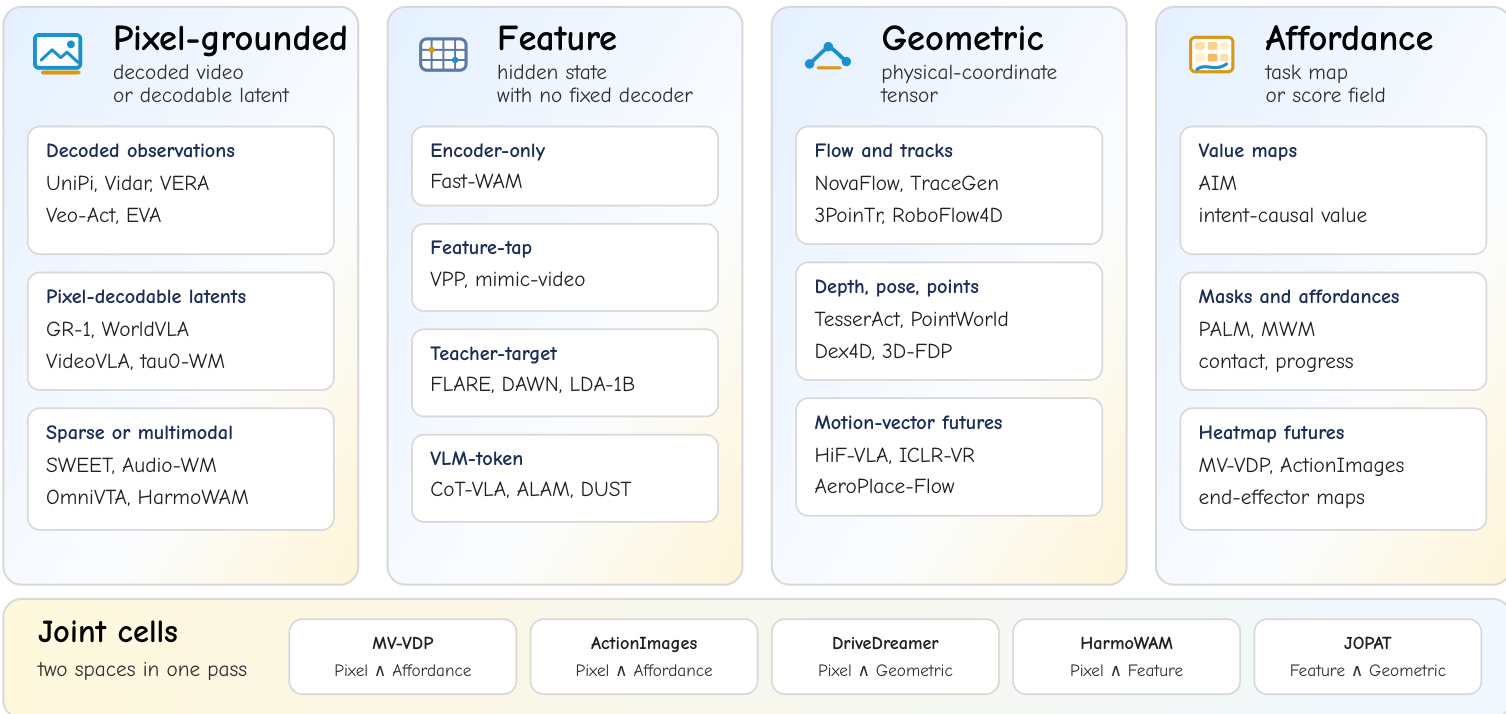 像素级基底暴露解码后的观测或映射回视频的解码器绑定潜在变量,保留了外观与运动先验。特征基底表示学习到的隐藏状态、教师嵌入或 token 块,没有固定的观测解码器,以直接视觉可解释性换取紧凑性与语义不变性。几何基底暴露物理坐标张量,如光流、点轨迹、深度、位姿或运动矢量,将未来压缩至运动而非纹理。功能基底暴露与任务相关的标签或评分图,包括价值图、接触概率场、语义掩码或末端执行器热力图,直接将预测的未来与控制目标对齐。
像素级基底暴露解码后的观测或映射回视频的解码器绑定潜在变量,保留了外观与运动先验。特征基底表示学习到的隐藏状态、教师嵌入或 token 块,没有固定的观测解码器,以直接视觉可解释性换取紧凑性与语义不变性。几何基底暴露物理坐标张量,如光流、点轨迹、深度、位姿或运动矢量,将未来压缩至运动而非纹理。功能基底暴露与任务相关的标签或评分图,包括价值图、接触概率场、语义掩码或末端执行器热力图,直接将预测的未来与控制目标对齐。
最后,动作耦合轴定义了将预测性世界模型转化为可执行策略的结构化决策。如下图所示:
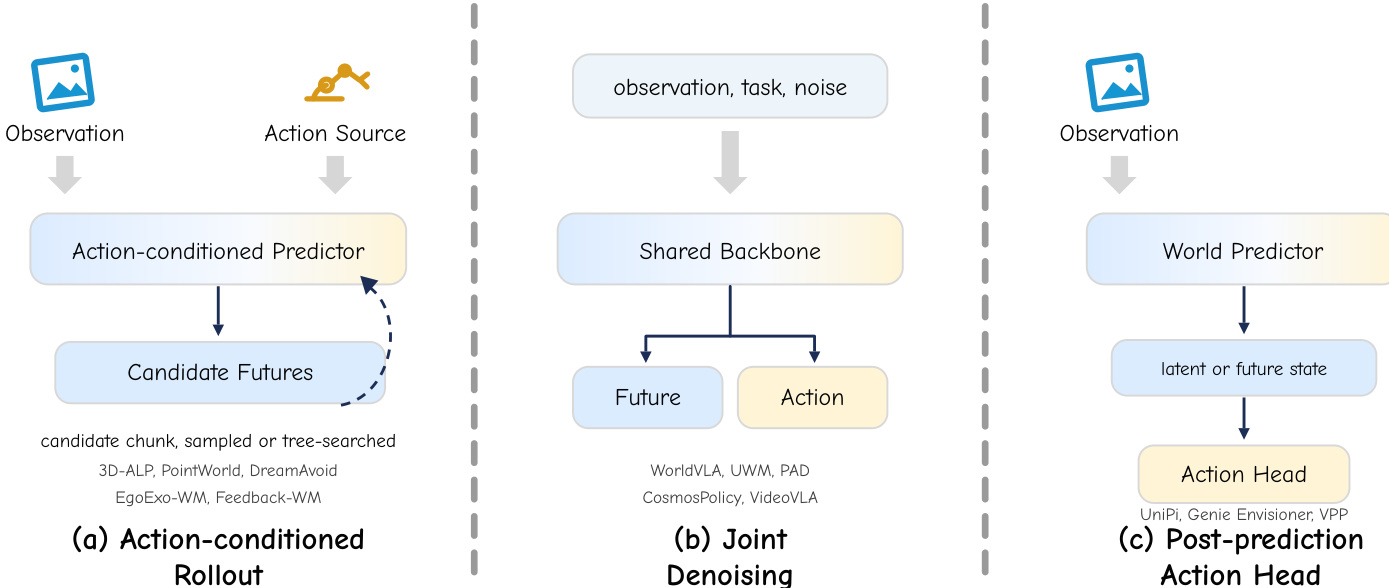 第一种架构是动作条件轨迹生成,其中外部规划器或策略提供候选动作,动作条件世界模型预测其后果。该架构可在分块级别或逐步模式下运行。第二种架构是联合生成,其中共享骨干网络上的单一生成过程同时生成基底与动作分块,通过耦合损失强制相互一致性。第三种架构是预测后动作头,其中基底生成器首先预测未来,较小的独立动作专家从该预测中解码控制信号。这种因子化允许预训练预测器保持固定,同时动作头适应特定的具身设备或控制接口。
第一种架构是动作条件轨迹生成,其中外部规划器或策略提供候选动作,动作条件世界模型预测其后果。该架构可在分块级别或逐步模式下运行。第二种架构是联合生成,其中共享骨干网络上的单一生成过程同时生成基底与动作分块,通过耦合损失强制相互一致性。第三种架构是预测后动作头,其中基底生成器首先预测未来,较小的独立动作专家从该预测中解码控制信号。这种因子化允许预训练预测器保持固定,同时动作头适应特定的具身设备或控制接口。
实验
第一个实验比较了分块级别与逐步的动作条件轨迹生成策略,验证了并行候选评分与连续轨迹中点适应分别能够在世界模型中实现鲁棒的反事实控制。第二个实验评估了当前的基准测试协议,揭示了孤立的成功率指标或平均性能分数经常掩盖关键的权衡关系与特定任务的故障模式。最终,研究结果表明,可靠的评估需要集成的报告框架,以联合量化准确性、延迟、规划视距与计算约束。
作者将 FLARE 介绍为一种世界动作模型,其特征为联合嵌入骨干网络与基于特征的教师基底。该系统利用预测后动作头进行动作耦合,并采用分块部署策略。该配置将 FLARE 置于分块级别子模式家族中,动作在此以并行分块而非逐步方式处理。FLARE 基于分块部署策略运行,与用于并行候选评估的分块级别子模式家族保持一致。该模型采用联合嵌入骨干网络与预测后动作头将动作与预测相耦合。分块方法允许对动作候选进行并行评估,但限制了预测窗口内的反应式控制。

FLARE 的评估在并行候选评估框架中检验了其分块部署策略,验证了联合嵌入骨干网络与基于特征的教师基底在架构上的整合。通过引入用于动作耦合的预测后动作头,该系统成功将动作处理从顺序步骤转变为并行评估分块。该设计产生了明确的定性权衡,在提升并行效率的同时,本质上限制了活跃预测窗口内的反应式控制。