Command Palette
Search for a command to run...
Multi-LCB:将LiveCodeBench扩展至多种编程语言
Multi-LCB:将LiveCodeBench扩展至多种编程语言
Maria Ivanova Pavel Zadorozhny Rodion Levichev Ivan Petrov Adamenko Pavel Ivan Lopatin Alexey Kutalev Dmitrii Babaev
摘要
LiveCodeBench(LCB)近期已成为评估大语言模型(LLM)代码生成任务的广泛采用的基准测试。通过精心策划编程竞赛题目、持续向题库中补充新题目,并依据题目发布日期进行筛选,LCB 提供了污染感知评估,从而为代码生成能力提供了全面的评估视角。然而,LCB 目前仍局限于 Python 语言,使得一个关键问题悬而未决:大语言模型能否在现实软件工程所需的多样化编程语言中实现泛化。为此,我们提出 Multi-LCB,这是一个涵盖包括 Python 在内的十二种编程语言的基准测试,用于评估大语言模型。Multi-LCB 将 LCB 数据集中的 Python 任务转换为其他语言中的等效任务,同时完整保留了 LCB 的污染控制机制与评估协议。由于 Multi-LCB 与原始 LCB 格式完全兼容,它能够自动追踪 LCB 的后续更新,从而支持对跨语言代码生成能力的系统性评估,并检验模型在 Python 之外的其他语言中维持表现的能力。我们在 Multi-LCB 上对 24 款大语言模型的指令与推理能力进行了评估,研究结果揭示了 Python 过拟合、特定语言数据污染以及多语言性能存在显著差异等现象。研究结果确立了 Multi-LCB 作为多编程语言代码评估的严谨新基准,直接弥补了 LCB 的主要局限,并揭示了当前大语言模型能力中的关键短板。
一句话总结
Multi-LCB 将仅限 Python 的 LiveCodeBench 基准扩展至十二种编程语言,通过将任务转换为其他语言的等效版本并保留污染控制机制。对二十四个大语言模型的评估表明,模型在不同语言间存在显著的性能差异、特定语言的训练数据污染,以及 Python 过拟合的证据。
核心贡献
- Multi-LCB 通过将 Python 任务转换为等效实现,将 LiveCodeBench 基准扩展至十二种编程语言,同时保留了原有的发布日期过滤机制与实时评估协议。
- 该框架可自动追踪未来的 LiveCodeBench 更新,以实现持续的多语言评估,并支持对二十四个指令微调与推理导向的大语言模型进行评估。
- 实证评估揭示了 Python 过拟合、特定语言的数据污染以及显著的性能差异,证明 Python 熟练度无法可靠预测模型在其他编程环境中的能力。
引言
大语言模型已成为 AI 辅助编程与自动化软件开发的核心,这使得严格的评估基准对于追踪模型能力至关重要。尽管 LiveCodeBench 建立了感知数据污染的代码生成评估标准,但其仅针对 Python 进行评估。这一狭窄的评估范围掩盖了模型是否真正具备编程能力的泛化性,还是仅对单一语言产生过拟合,从而在评估真实软件工程工作流方面留下了关键空白。研究者为了解决这一局限,提出了 Multi-LCB。该扩展框架将 LiveCodeBench 的污染控制协议扩展至十二种编程语言。通过系统化地转换任务,同时保留持续更新与标准化执行流程,该框架实现了跨语言直接对比,并揭示了现代模型中显著的性能差异、特定语言的数据泄露以及广泛的 Python 过拟合现象。
数据集

数据集构成与来源
- 研究者引入了 Multi-LCB,这是 LiveCodeBench (LCB) 代码生成数据集的多语言扩展版本,旨在评估十二种语言下的编程能力。
- 该数据集整合了来自三大主流竞技编程平台的问题:LeetCode、AtCoder 与 Codeforces。
- 支持的编程语言包括 C++、C#、Python、Java、Rust、Go、TypeScript、JavaScript、Ruby、PHP、Kotlin 与 Scala。
- 语言选择优先考虑流行度、稳定的基础设施支持,以及在类型系统、内存管理模型与运行时环境方面的范式多样性。
各子集关键细节
- 平台格式: AtCoder 与 Codeforces 任务保留其原生的 STDIN/STDOUT 格式,而 LeetCode 任务原本采用需要特定函数签名的函数式格式,现已转换为统一的 STDIN/STDOUT 结构。
- 过滤规则: 数据集沿用了 LCB 的污染控制机制,根据竞赛发布日期相对于模型训练时间窗口的关系来过滤任务。
- 质量约束: 为保证严格的输入/输出评分,排除了允许多个有效答案或需要显式构建数据结构的问题。
- I/O 结构: 转换后的任务按输入与输出的维度进行分类,包括标量值、一维数组与二维数组。
- 范围限制: 该基准基于 2025 年流行度排名覆盖 12 种语言,并因运行时或生态系统限制排除了 Swift 或 Haskell 等其他语言。
使用与处理流程
- 仅限评估: 研究者仅将 Multi-LCB 作为评估资源使用。未在数据集上训练任何模型,也不存在训练集划分或混合比例。
- 提示策略: 基准测试采用零样本提示策略。提示词包含定义目标语言专长的系统消息、包含自然语言描述及明确 STDIN/STDOUT 规范与示例用例的用户消息,以及代码块占位符。
- 转换流程: 专用流程将 LeetCode 函数式任务转换为统一的 STDIN/STDOUT 格式。此过程包括适配问题提示词,并将所有测试用例(含隐藏测试)进行转换,从而支持跨所有语言的统一评估框架。
- 评估协议: 生成的代码将在目标语言中进行编译或执行,并使用 Pass@1 指标进行评估。
元数据与处理细节
- 元数据构建: 每个任务均保留来自 LCB 的元数据,包括用于污染追踪的竞赛发布日期、平台来源与难度等级。
- 格式化规则: 转换过程中,列表格式化为空格分隔的值。二维数组采用首行指示行数、后续每行空格分隔数值的结构。
- 语言无关性: 转换流程确保任务保持语言无关性,无需针对特定语言重写核心问题逻辑。
- 验证: 对样本任务的手动检查确认了不存在由语言依赖特性导致的不一致问题。
方法
研究者提出了 Multi-LCB,这是一个综合性的评估框架,旨在跨十二种不同的编程语言评估大语言模型。该方法扩展了原始的 LiveCodeBench (LCB),以解决仅限 Python 评估的局限性,从而实现模型在不同语言处理相同问题时的能力直接对比。该系统依赖模块化流程,将从提示词构建到代码执行的问题解决过程标准化。
参见下方框架示意图:
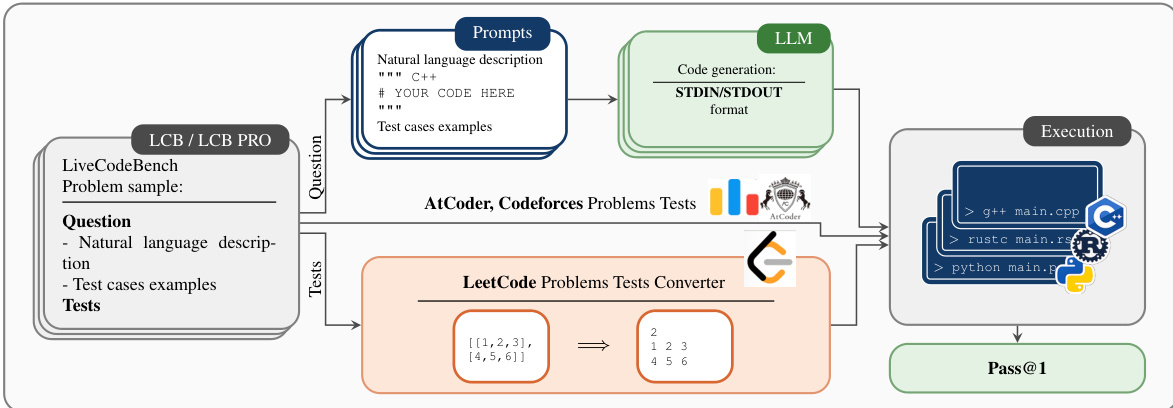
流程始于从 LCB 或 LCB PRO 获取的问题样本,这些样本包含自然语言描述与测试用例示例。研究者利用标准化提示词模板对这些输入进行格式化。对于非 Python 设置,代码块头部会进行调整(例如 """cpp 或 """java),而提示词结构的其余部分与 Python 基线保持一致。这确保了大语言模型接收指令的一致性。随后,大语言模型的任务是生成符合 STDIN/STDOUT 格式的代码,以实现标准化的输入输出处理。
该架构中的一个关键模块是“LeetCode 问题测试转换器”。由于许多编程基准(如 LeetCode)将测试用例作为结构化数据(如列表或数组)而非纯文本提供,该转换器将其转换为适用于标准输入流的格式。例如,[[1,2,3], [4,5,6]] 这类输入会被转换为文本表示形式,其中维度与元素分行打印。该模块还促进了与 AtCoder 和 Codeforces 等其他平台测试用例的兼容性。
最后,生成的代码与转换后的测试用例将被传递至执行环境。该框架支持多样化的执行模型,分为编译型语言(C++、Rust、Go、Java、C#、Scala、Kotlin)、解释型语言(Python、Ruby、PHP)与跨编译语言(TypeScript 至 JavaScript)。系统针对测试用例执行代码,并计算 Pass@1 指标以评估正确性。该端到端流程支持对广泛编程语言中的代码生成模型进行严格且感知数据污染的评估。
实验
该评估采用完全自动化的零样本流程,在十二种编程语言下对二十四个大语言模型进行评估。通过针对隐藏测试集的安全执行,验证了模型的跨语言泛化能力、基准保真度与污染控制机制。定性分析揭示了持续存在的针对 Python 的性能偏向,表明单一语言能力并非衡量真实多语言编程能力的可靠代理指标。时间校验与错误细分确认,发布日期过滤能有效将真实泛化能力与预训练暴露隔离开来,同时将算法正确性确立为主要瓶颈,并揭示了编译型语言固有的可预测语法与运行时挑战。最终,研究结果表明,稳健的多语言代码生成仍是重要前沿领域,其发展严重受限于训练数据分布、特定语言的执行开销以及日益增长的问题复杂度。
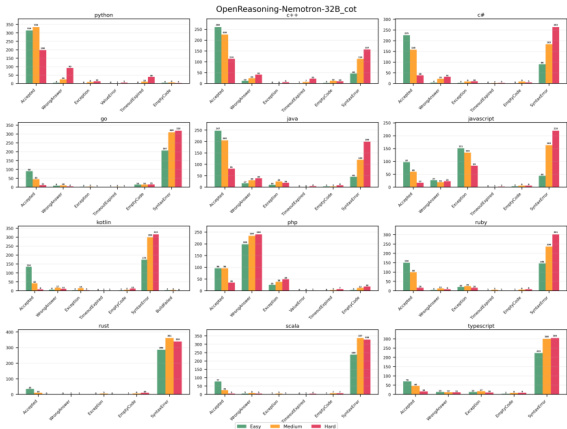
实验在 12 种编程语言下对 OpenReasoning-Nemotron-32B 模型进行评估,按任务难度与错误类型分析性能。结果显示,随着问题复杂度从简单递增至困难,成功率持续下降,困难任务最具挑战性。错误分析揭示了特定语言的模式,例如 C++ 的编译错误率较高,Java 的运行时错误较多,而 Python 始终保持最高性能与最低错误率。随着任务难度增加,模型性能显著下降,困难问题表现出最大的性能差距。答案错误在大多数语言中占主导地位,但 C++ 和 Rust 等编译型语言也表现出显著的编译错误率。与其他语言相比,Python 展现出更优的能力,拥有最高的成功率以及极少的运行时或语法错误。
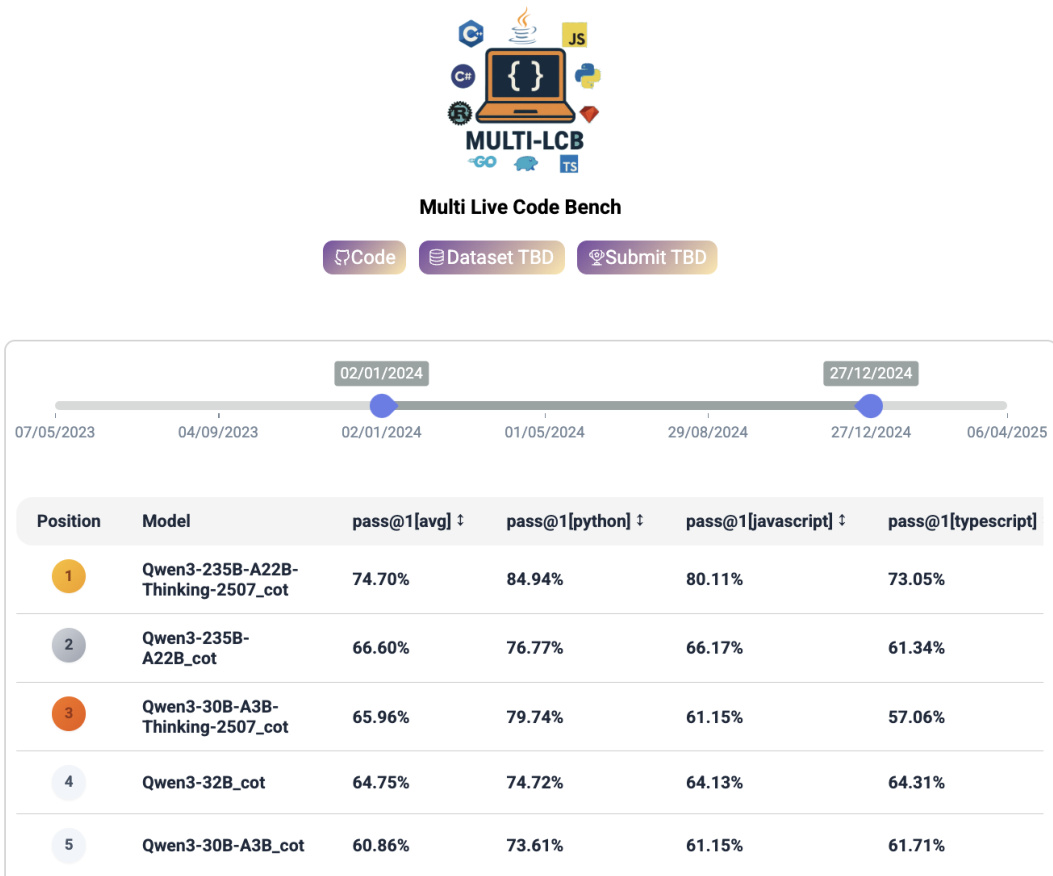
研究者在 Multi-LCB 基准上评估了一系列大语言模型,以评估其在多种编程语言下的代码生成能力。结果表明,推理增强型模型(尤其是规模最大的 Qwen3 变体)取得了最高的整体性能。评估揭示了一个持续存在的趋势:模型在 Python 任务上的得分显著高于 JavaScript 和 TypeScript,凸显了当前能力中的特定语言偏向。推理增强型模型在排行榜中占据主导,表现最佳的变体在所有评估语言中均展现出优越能力。Python 与其他语言之间存在持续的性能差距,因为模型在 Python 任务上实现了更高的成功率。高效模型架构展现出强劲的竞争力,尽管参数量少于领先模型,仍稳居较高排名。
研究者采用零样本提示策略,在多种编程语言下评估了一套多样化大语言模型。结果表明,Python 仍是当前模型最擅长的语言,而 Scala 和 Kotlin 等编译型语言则呈现出显著更高的难度。表现顶尖的推理增强型模型确立了强劲的技术前沿,但大多数评估系统在多样化的语言生态中仍难以实现稳健的正确性。Python 在几乎所有模型中始终取得最高分,而 Scala 和 Kotlin 等语言则表现最低。推理增强型模型显著优于非推理对应模型,尤其在复杂编译型语言中表现突出。Python 的优异表现无法可靠预测在其他编程语言中的成功,凸显了跨语言泛化能力的不足。
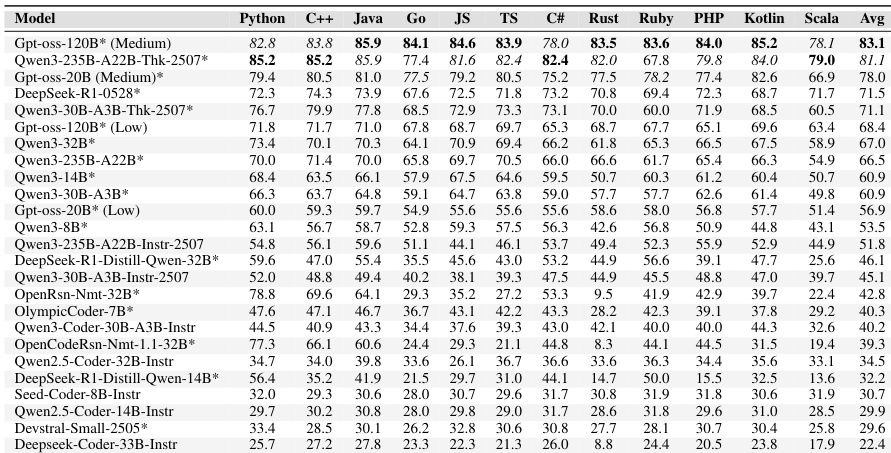
实验在多种编程语言下评估了一系列大语言模型,以检验代码生成能力。结果表明,推理增强型模型(尤其是规模最大的 Qwen3 变体)取得了最高的整体性能。呈现出一致的模式:Python 得分显著高于其他语言,而 Scala 在大多数模型中成功率最低。推理增强型模型一贯优于同等规模的指令微调变体。Python 在绝大多数模型中取得最高通过率,而 Scala 表现最低。规模最大的评估模型相较于较小或能力较弱的对应模型,确立了明显的性能优势。
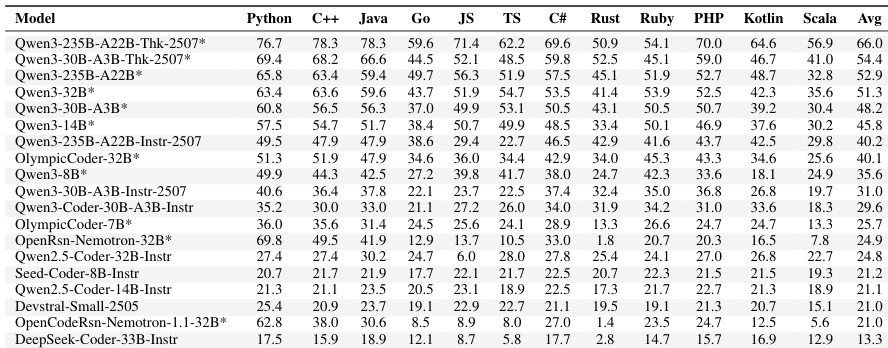
评估表明,与标准指令微调变体相比,推理增强型模型在多种编程语言中始终取得更高的 Pass@1 分数。性能因语言差异显著,TypeScript 和 Go 等解释型语言通常比 Rust 和 Scala 等编译型语言产生更高的成功率。此外,平台特定的挑战显而易见,模型在面试风格问题上的表现通常优于竞技编程任务。推理增强型模型在所有评估语言中均显著优于标准对应模型。与 Rust 和 Scala 等编译型语言相比,TypeScript 和 Go 等解释型语言显示出更高的整体成功率。模型在 LeetCode 风格问题上通常比在 AtCoder 等竞技编程平台上取得更高的 Pass@1 分数。
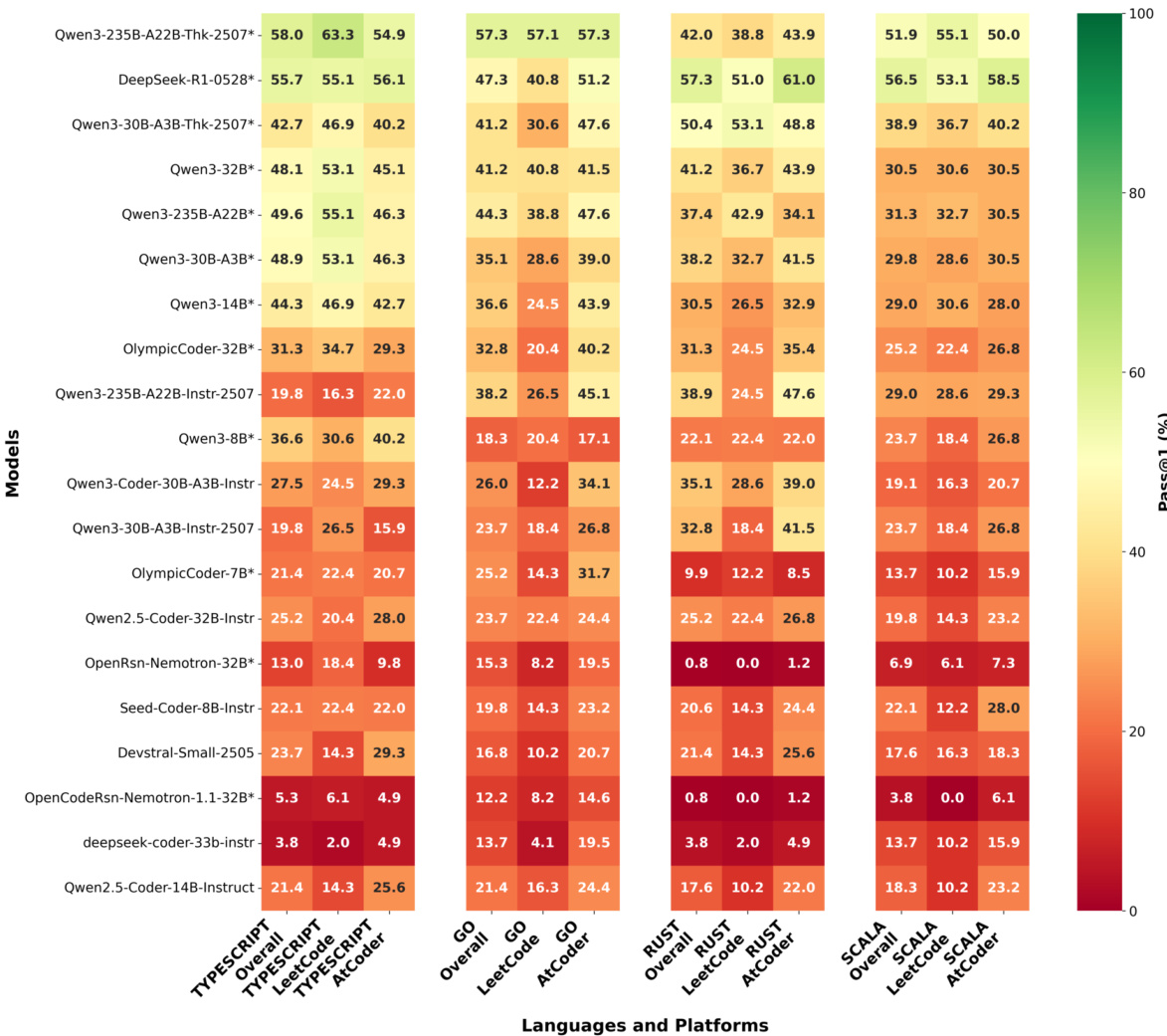
多项实验在多种编程语言下评估了多样化大语言模型,以检验代码生成能力,并验证推理增强、任务复杂度与语言范式的影响。定性分析表明,推理增强型架构一贯优于标准指令微调变体,且更大规模的模型在面对日益困难的问题时展现出更优的鲁棒性。性能呈现出明显的特定语言偏向,Python 和 TypeScript 等解释型语言的成功率显著高于编译型替代方案,且在单一语言上的优异表现无法可靠预测跨语言泛化能力。此外,错误模式凸显了不同生态系统的独特挑战:编译型语言主要受困于语法与编译问题,而模型在标准面试风格任务上的表现一贯优于严格的竞技编程基准。