Command Palette
Search for a command to run...
S-Agent:空间工具使用激发空间智能推理
S-Agent:空间工具使用激发空间智能推理
摘要
现实世界的空间智能需要在连续且不断演化的三维世界中进行推理,然而现有的 VLMs 和工具增强型 agents 在很大程度上仍局限于从孤立视觉观察中进行静态、无状态的推理。我们提出 S-Agent,这是一种用于理解和推理连续多视角图像与视频的空间工具使用 agent 范式。通过将空间推理构建为时空证据累积而非孤立的帧级预测,S-Agent 将空间感知重塑为超越帧级识别的以场景为中心的理解。具体而言,S-Agent 将 VLM 视为决定所需证据的语义规划器,同时借助空间工具与专家的层级结构,在二维空间中锚定对象,将其转化为三维几何证据,并将这些证据聚合为高级空间知识(例如计数、测量、方向与相对位置)。此外,一种时间记忆机制(包括用于维持演化场景状态的场景记忆与用于累积推理上下文的 Agent 记忆)实现了跨帧与推理步骤的证据整合。在多视角与视频空间推理基准上的综合实验表明,S-Agent 以无需训练的方式持续提升了开源与闭源 VLMs 的性能。除推理时增强外,在 S-Agent 生成的空间轨迹数据集 S-300K 上进行监督微调(SFT)得到了 S-Agent-8B,这是一种紧凑的空间 agent,其性能显著超越同等规模的基线模型(例如 Qwen3-VL-8B),并与先进的闭源模型(例如 GPT-5.4 和 Gemini 3)表现相当。
一句话总结
S-AGENT 引入了一种空间工具使用范式,通过将空间推理视为时空证据累积,推动视觉-语言模型超越静态的帧级推理。该范式结合语义规划器、分层几何工具与双记忆机制,动态聚合跨帧数据,在多图与视频空间推理基准上实现了无需训练的性能提升。
核心贡献
- S-AGENT 将空间感知重新定义为时空证据累积,而非孤立的帧级预测,其核心在于利用视觉-语言模型作为语义规划器。该框架调度分层空间工具,实现 2D 物体的定位、3D 几何线索的提取以及高层空间知识的综合。
- 由场景记忆(Scene Memory)与 Agent Memory 组成的双记忆架构,能够维持动态演变的场景状态,并在跨帧与工具迭代过程中累积中间推理轨迹。这种有状态设计明确地将碎片化的多视角观测数据连接起来,构建出具有时间基准的三维表示,以支持连续推理。
- 在 MMSI-Bench、ViewSpatial-Bench、ReVSI 和 VSI-SUPER 上的综合评估表明,该无需训练的框架能够持续提升开源与闭源视觉-语言模型的性能。在精心构建的空间指令数据集上对该架构进行微调后,模型在 MMSI-Bench 上的准确率提升了 10.5%,并在多个基准测试中达到了先进闭源模型的性能水平。
引言
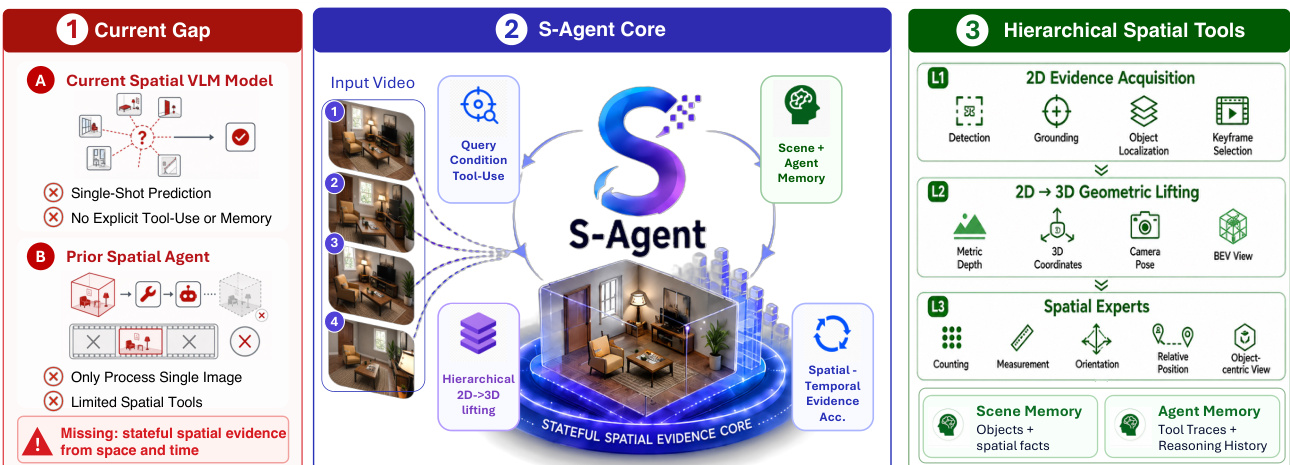
现实世界的空间智能要求模型能够导航动态的 3D 环境,这一能力对于具身智能机器人、自动驾驶及扩展现实应用至关重要。然而,当前的视觉-语言模型主要基于静态的 2D 语料库进行训练,难以弥合语义与几何之间的鸿沟,通常依赖有损表示,无法捕捉精确的空间关系。即便是近期引入工具增强的 Agent,仍受限于对孤立帧的静态、无状态推理,这阻碍了其对对象状态的持续保持以及跨视角、跨时间的视觉证据整合。为突破这些局限,本文提出 S-AGENT,一种将推理重新定义为连续时空证据累积的空间工具使用范式。该范式利用视觉-语言模型作为语义规划器,调度分层空间工具以实现 2D 物体定位、3D 几何重建及高层空间关系提取。在持续追踪场景状态演变与推理历史的雙记忆系统支持下,该架构实现了对视频与多视角数据的持久化、有状态理解。该框架持续提升了现有模型的零样本性能,并衍生出一种紧凑型微调变体,其能力可与领先的闭源系统相媲美。
数据集

- 数据集构成与来源: 研究团队构建 S-300K 数据集,从 SenseNova-SI-800K 中获取初始提示词,并筛选出能够挑战较弱学生模型且自然需要工具调用的查询。
- 关键子集详情与过滤规则: 最终语料库包含 300K 条轨迹。研究团队通过 Qwen3-VL-8B 的多次运行来评估样本难度,并优先保留不确定性高或不稳定的案例。在导出阶段,仅保留执行有效且最终答案正确的轨迹,同时应用针对答案类型的特定标准,例如选择题的精确选项匹配、数值题的平均相对准确率以及文本回复的归一化匹配。工具调用被刻意排除在硬性过滤规则之外。
- 数据处理与分解: 研究团队未将多次运行结果视为单一示例,而是将每条保留的轨迹分解为三种独立的监督格式。他们生成用于空间推理的端到端最终答案序列,用于在部分上下文中教授迭代工具使用决策的回合级序列,以及用于优化工具使用策略的专家级序列。所有原始的 agent 轨迹均被独立保留以供分析。
- 模型使用与训练策略: 该多粒度数据集被专门用于对 Qwen3-VL-8B 进行监督微调。通过将分解后的轨迹输入训练循环,紧凑的学生模型得以学习如何请求证据、解读工具观测结果,并在推理步骤中累积空间知识,最终生成 S-AGENT-8B 模型。
方法
本文提出 S-AGENT,一种专为处理连续多视角图像与视频的空间推理而设计的空间工具使用 Agent 框架。该系统未将空间推理视为基于孤立视觉输入的单次预测,而是将其构建为时空证据累积的过程。该架构利用大型视觉-语言模型(VLM)作为语义规划器,通过专用工具主动获取分层空间证据,同时维护场景记忆与 Agent Memory 以支持有状态推理。如框架概览所示,该系统通过显式建模时空维度下的有状态空间证据,突破了单次预测与有限工具调用的局限,有效解决了当前空间 VLM 的不足。
核心推理过程是迭代进行的。在每一个推理步骤 t,VLM 规划器接收问题 q 与视觉观测序列 F。它维护两种记忆状态:用于已定位空间证据的场景记忆状态 St,以及用于推理历史的 Agent Memory 状态 Ht。规划器基于问题、观测结果与当前记忆状态生成证据请求 rt:
rt=πθ(q,F,St,Ht)
层级 k 的空间工具或专家执行该请求,生成观测结果 ot:
ot=T(k)(rt,F,St)
该观测结果被分解为可复用的场景证据 et 与过程上下文 ct,进而更新记忆模块:
St+1=Merge(St,et),Ht+1=Append(Ht,ct)
该交互的详细流程,包括规划器、分层证据级别与持久化记忆结构,如下图所示。
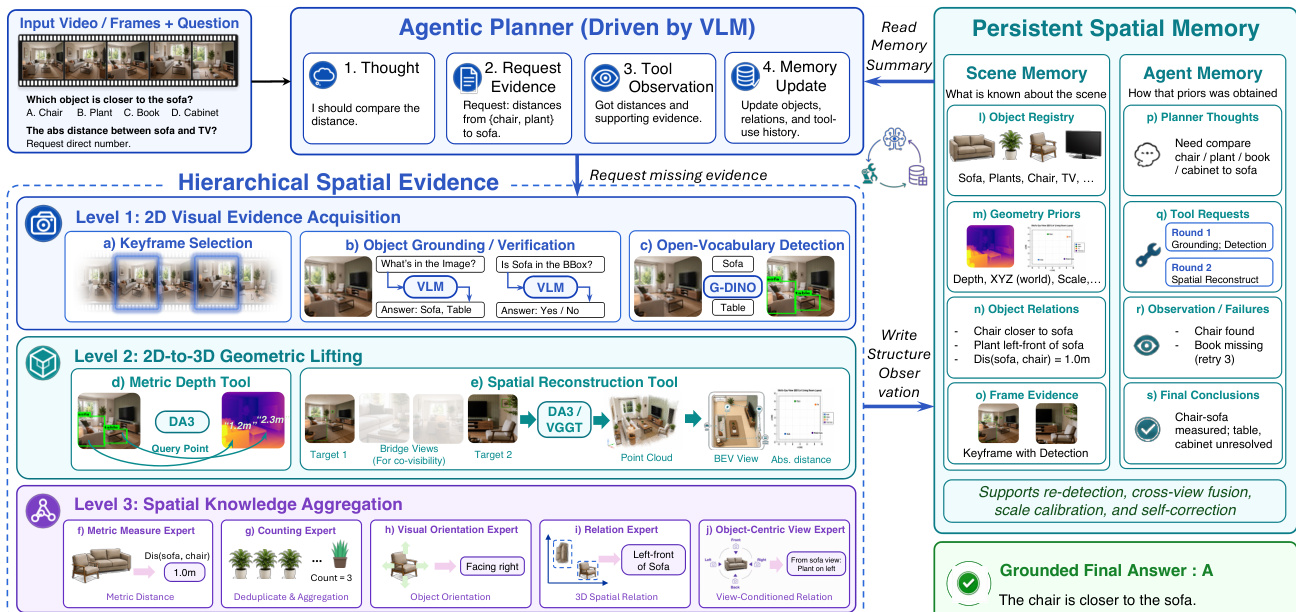
S-AGENT 通过三级层级结构获取证据,将原始 2D 观测转化为显式空间知识。第一级涉及 2D 视觉证据获取,系统在此阶段选择信息量丰富的帧,定位所指实体,并利用开放词汇检测器确定候选区域。第二级执行 2D 到 3D 的几何提升,利用工具恢复场景级 3D 信息,如深度结构、度量坐标与相机位姿。这使得 agent 能够在共享的空间上下文中对比碎片化的 2D 观测。第三级利用专门用于计数、相对方向与度量测量的专家聚合空间知识。该过程的迭代特性在推理轨迹中清晰可见,规划器会根据工具反馈在各轮次中动态调整策略,例如在初步尝试失败时从直接定位切换至目标检测。
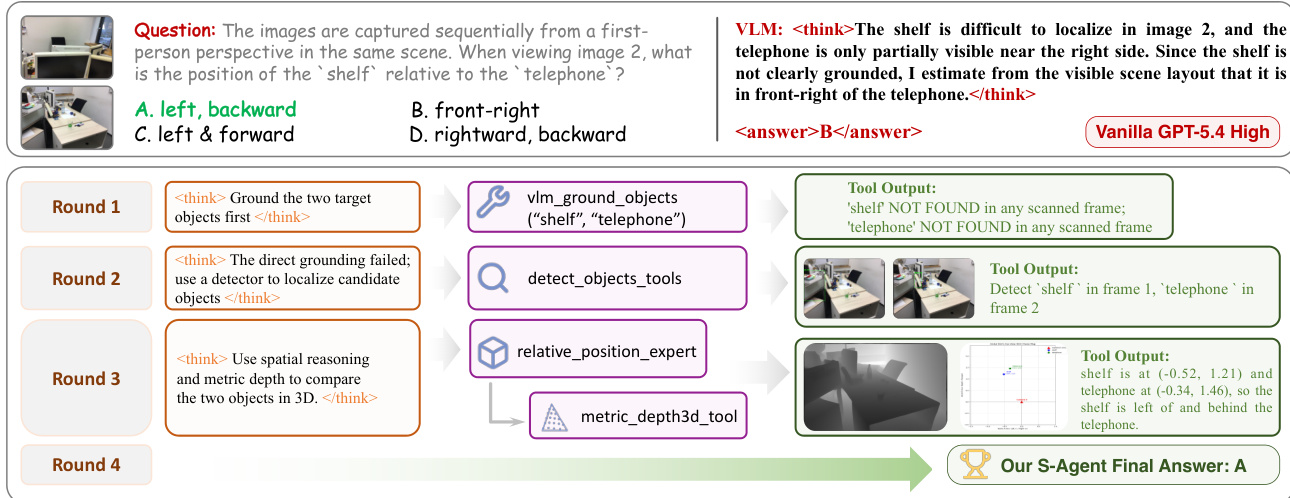
该框架维护两种互补的记忆模块以支持有状态推理。Scene Memory 通过将重复观测绑定至持久化的场景实体,并累积其视觉与几何属性,来整合可复用的场景证据。此举有效防止了证据冗余,并稳定了跨视角与跨帧的对象身份。Agent Memory 则保留推理轨迹,记录中间思维过程、工具调用及失败信息。此类程序上下文使规划器能够识别缺失证据并避免冗余操作。系统执行复杂空间任务的能力通过绝对距离测量与物体尺寸估计等示例得以验证,在此过程中,agent 选择关键帧、估算初始度量值、定位目标,并执行 3D 测量以得出最终答案。

实验
在涵盖多图、视频及视角感知任务的四项空间推理基准上的评估表明,实验验证了 S-AGENT 在零样本与知识蒸馏训练模式下,系统性地定位视觉证据并整合跨视角信息的能力。零样本评估证明,该框架通过动态调用专用工具与记忆模块重建度量空间布局,持续超越强大的闭源与专用基线模型。消融研究证实,结构化的证据层级与专家辅助的 3D 解释对于过滤噪声几何数据至关重要,而定性分析则揭示,这种基于工具的方法成功解决了通常导致标准视觉-语言模型失败的遮挡与模糊线索问题。最终,轨迹蒸馏实验确认,这些高级推理能力可有效迁移至紧凑型模型,为空间理解确立了稳健且可扩展的范式。
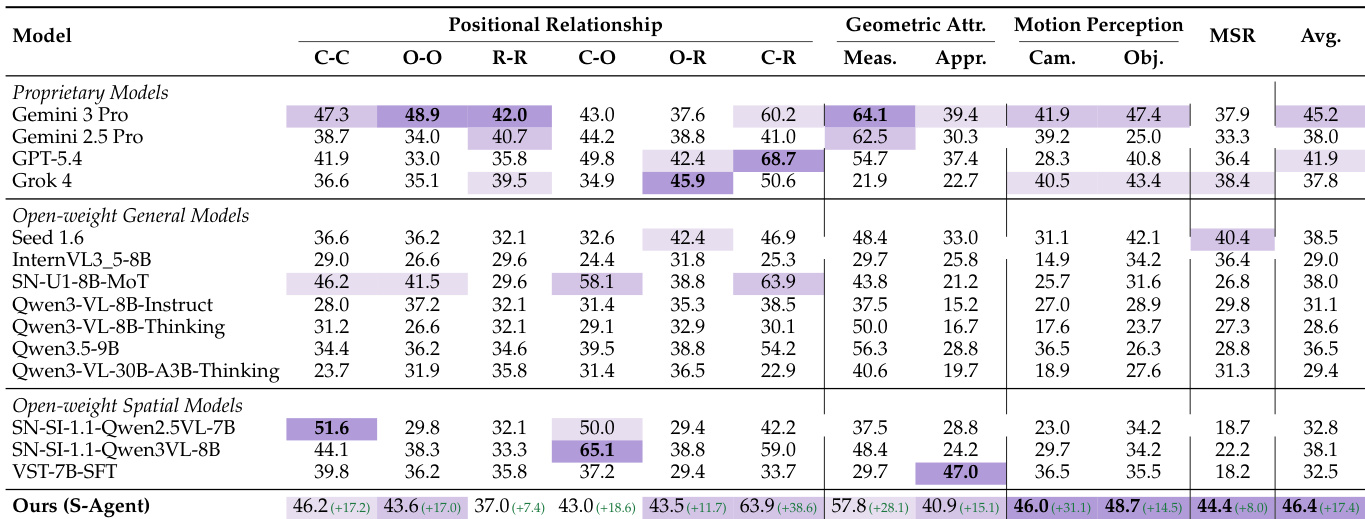
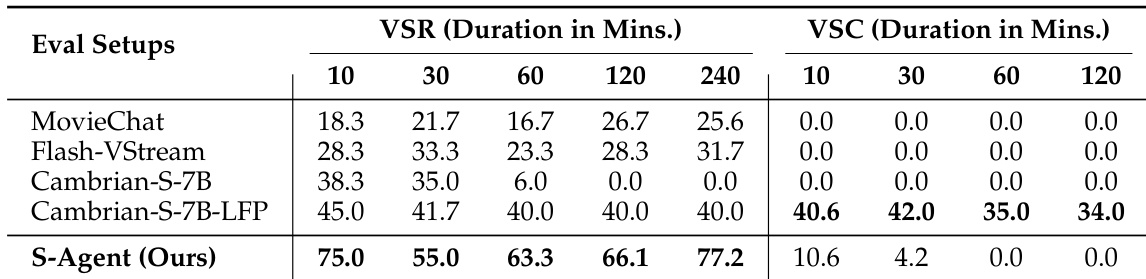
结果显示,S-AGENT 模型在 MMSI-Bench 上取得了最高的总体平均分,领先于主流闭源模型与开源权重基线。该系统在动态空间推理方面展现出卓越能力,在运动感知与多步推理类别中斩获最高分。此外,其在特定相机-区域位置关系任务中位居榜首,同时在几何属性评估中保持稳健表现。S-AGENT 的总体平均分位居第一,超越了 Gemini 3 Pro 与 GPT-5.4 等闭源模型。该模型在运动感知与多步推理类别中表现突出,在相机-区域位置关系任务中夺得第一,并在几何测量任务中保持强劲竞争力。
研究团队在 ReVSI 基准上对 S-AGENT 进行评估,以检验其在数值与选择题任务中的空间推理能力。S-AGENT 在开源通用模型与空间专用模型中取得了最高的平均性能。它在需要跨帧整合证据的选择题任务中表现尤为突出,特别是在相对方向与路径规划方面。S-AGENT 在该基准上超越了所有开源通用与空间专用基线模型。该模型在相对方向与路径规划类别中取得最高分。S-AGENT 的平均分总体排名第二,仅次于最强的闭源模型。
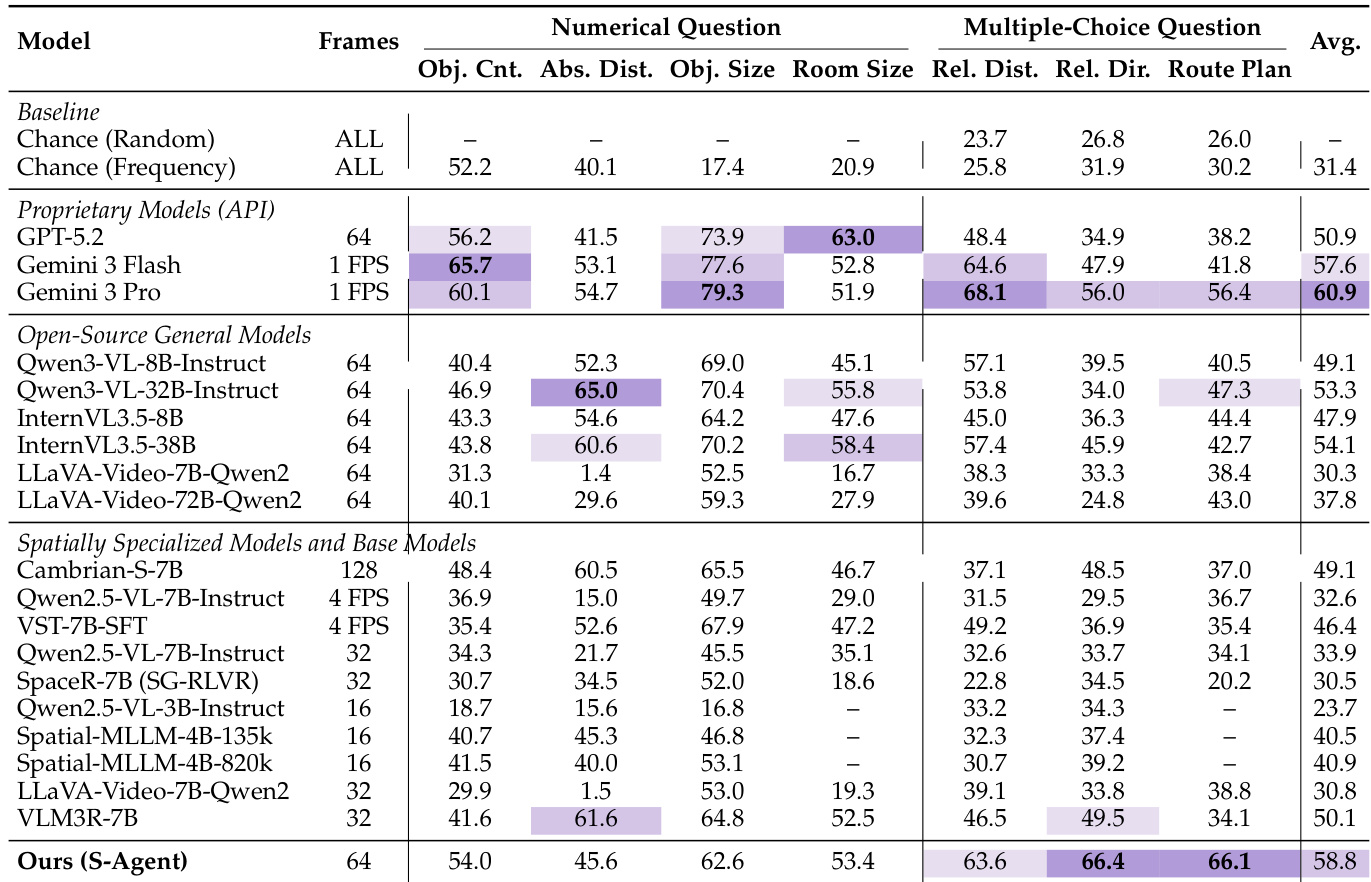
研究团队在 ViewSpatial-Bench 基准上评估 S-AGENT,并将其与闭源及开源权重模型进行对比。结果表明,S-AGENT 取得了最高的平均性能,显著优于 GPT-5.4 等领先闭源模型。该模型在相机中心与人物中心的空间推理任务中均展现出优越能力。S-AGENT 在 ViewSpatial-Bench 上取得最高平均分,超越闭源基线。该模型在相机视角物体朝向与人物视角相对方向任务中表现强劲。S-AGENT 在极具挑战性的人物视角场景模拟相对方向任务上实现了显著提升。
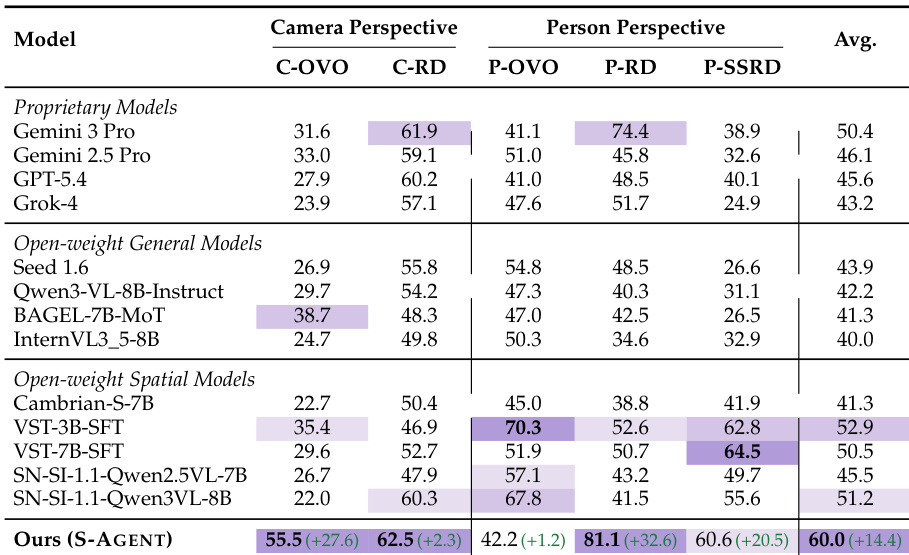
研究团队针对 S-AGENT 的空间证据层级与记忆模块开展了消融实验。结果表明,尽管基础 2D 证据较基线模型带来了适度提升,但原始 3D 证据因噪声干扰效果较差。相比之下,使用第三级 3D 专家能显著提升性能,而同时整合场景与 Agent Memory 模块则取得了最佳总体效果。相较于原始 3D 证据,利用第三级 3D 专家显著提升了性能,凸显了专家解释的价值。整合场景与 Agent Memory 模块取得了最佳总体效果,优于单独使用任一模块。基础 2D 证据较基线带来适度提升,而未经专家过滤的原始 3D 数据收益有限。
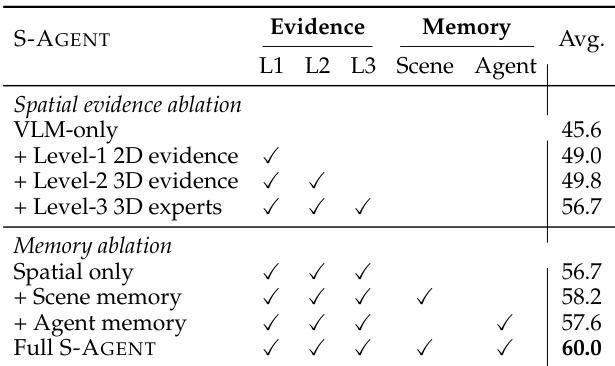
研究团队在涵盖不同视频时长(从短片段到长序列)的视频空间推理与变化检测任务上评估了所提出的 S-Agent 模型。结果表明,S-Agent 在所有测试时长下均保持稳健且优异的性能,显著优于在长视频上失效的 Cambrian-S-7B 等基线模型。此外,S-Agent 是唯一能在较短时长变化检测任务中取得非零成绩的模型,凸显了其处理复杂时序变化的卓越能力。S-Agent 在长视频序列中维持高准确率,而竞争模型则出现严重性能衰退或完全失败。该方法在所有视频长度上均显著优于 Cambrian-S-7B 等空间专用基线。S-Agent 是唯一在较短时长视频空间变化任务中取得非零分数的模型,展现了其独特的时序推理能力。
S-AGENT 模型在多项空间推理基准、证据层级与记忆模块的消融实验,以及基于视频的时间推理任务中接受了评估。在这些多样化的评估中,该系统持续超越闭源与开源权重基线,在动态空间推理、视角感知场景理解及跨帧证据整合方面展现出卓越能力。消融结果表明,专家过滤后的 3D 证据与结合场景及 Agent Memory 的模块是达到峰值性能的关键,而原始 3D 数据会引入有害噪声。此外,该模型在变化的视频时长下维持稳健的准确率,并独自在短时时序变化检测中取得成功,凸显了其处理复杂空间与时序动态的优越能力。