Command Palette
Search for a command to run...
重新审视大语言模型 FP4 预训练中的收缩偏差:几何起源、系统性影响及 UFP4 方案
重新审视大语言模型 FP4 预训练中的收缩偏差:几何起源、系统性影响及 UFP4 方案
摘要
FP4(4位浮点数)训练有望大幅降低大语言模型(LLM)预训练阶段的内存与计算成本。然而,当前的 FP4 硬件路径与训练方案(recipe),包括 NVIDIA Blackwell/Rubin 级系统以及 AMD MI350 系列 GPU,仍主要基于 E2M1 数据格式。在本研究中,我们指出了这一选择的根本性局限:非均匀格式(如 E2M1) inherently 遭受“收缩偏差”(Shrinkage Bias)——这是一种由可表示值域箱(bins)几何不对称性引起的系统性负向舍入误差。我们表明,这种偏差在层间呈乘积式累积,并受到随机哈达玛变换(Random Hadamard Transform, RHT)的放大,从而为现有基于 E2M1 的 FP4 训练方案中观察到的训练不稳定性提供了统一的解释。相比之下,均匀网格格式(E1M2/INT4)规避了这种网格几何误差,并能更有效地将 RHT 带来的分桶利用率提升转化为更高的量化质量。基于这一发现,我们提出了 UFP4,一种均匀的 4 位训练方案,该方案对所有三种训练用的通用矩阵乘法(GEMMs)应用 RHT,同时仅对梯度 dY 限制使用随机舍入(stochastic rounding)。在 Dense 1.5B、MoE 7.9B 以及 MoE 124B 的长期预训练任务中,UFP4 均 consistently 实现了更低的相对于 BF16 的损失下降幅度(loss degradation),这一结论得到了缩放定律(scaling-law)分析和消融实验的支持。我们的研究结果表明,未来的加速器应将 E1M2/INT4 风格的均匀 4 位网格作为一级训练基元(training primitives),与 E2M1 并列支持。
一句话总结
蚂蚁集团研究者发现,基于E2M1的FP4训练中存在一种名为Shrinkage Bias的系统性负向舍入误差,该误差源于几何bin的不对称性。他们提出UFP4,一种使用E1M2/INT4网格的统一4-bit训练方案,将Random Hadamard Transform应用于所有三个训练GEMM,并将随机舍入限制在dY上,在Dense 1.5B、MoE 7.9B和MoE 124B预训练中实现了更低的BF16相对损失退化。
核心贡献
- 论文识别出Shrinkage Bias,一种由非均匀E2M1网格的几何不对称性引起的系统性负向舍入误差,并表明该误差在层间乘性累积,且会被Random Hadamard Transform放大,解释了现有基于E2M1的FP4方案中观察到的训练不稳定性。
- 提出UFP4,一种统一4-bit训练方案,将RHT应用于所有三个训练GEMM,将随机舍入限制在dY梯度路径,并使用E1M2/INT4风格均匀网格,将RHT带来的改善的bucket利用率转化为更高的量化质量。
- 在Dense 1.5B、MoE 7.9B和MoE 124B长程预训练中,UFP4相比强E2M1基线,始终实现更低的BF16相对损失退化,并得到缩放定律分析和消融研究的支持。
引言
作者研究了使用4-bit浮点格式训练大语言模型的技术,该技术有望显著降低内存和计算成本。当前硬件和训练方案主要依赖非均匀E2M1格式,但端到端FP4预训练仍不稳定,且相比更高精度基线存在精度损失。先前工作尝试通过Random Hadamard Transform (RHT) 和随机舍入等技术缓解这种不稳定性,但仍保留了有问题的E2M1数据格式。
作者发现了一个根本性局限:像E2M1这样的非均匀网格固有地存在Shrinkage Bias,即由其可表示bin的几何不对称性引起的系统性负向舍入误差。他们证明该偏差在神经网络层间乘性累积,导致信号衰减,并矛盾地被RHT放大,因为RHT将张量质量移入该格式最不对称的区域。作者的主要贡献是UFP4,一种用E1M2或INT4等统一4-bit格式替代E2M1网格的训练方案。该方法绕过了网格几何误差,使得RHT能够有效应用于所有关键矩阵乘法,同时将随机舍入限制在单个梯度张量上,从而在规模上实现了更优的训练稳定性和精度。
数据集
作者描述了用于构建低精度训练数据的量化格式和分块量化过程。
- 格式码本:考虑了两种4-bit浮点格式E2M1和E1M2,以及一种4-bit整数格式(INT4)。每种格式定义了一个具有固定可表示级别集合的归一化码本 G。
- 分块量化:张量被划分为连续块。对每个块,共享缩放因子 sB 由块内最大绝对值除以码本中最大幅度级别计算得出。然后每个元素通过舍入规则缩放并映射到码本级。
- 舍入规则:论文支持确定性的Round-To-Nearest-Even (RTNE) 和随机舍入 (SR),后者以与相邻级别间距离成比例的概率采样一个级别。RTNE被指出是近期低精度方案(如NVFP4方法)中广泛采用的选择。
- 模型中的使用:量化张量 QG(T) 在整个训练管线中使用;在算术表达式中,它表示反量化后的数值张量,确保低精度表示直接集成到前向和后向传递中。
方法
作者解决了量化训练张量的挑战,这些张量通常包含导致大多数码本级利用率不足的离群坐标。为缓解此问题,他们利用了Random Hadamard Transforms (RHT)。RHT在量化前应用一种保范旋转,将离群能量分散到所有坐标上。作者使用递归定义的Sylvester Hadamard矩阵:
H2n=21[HnHnHn−Hn],H1=[1],其中 Hn⊤Hn=In 对于 n=2k。RHT在Hadamard变换前额外应用一个随机符号矩阵 Sn=diag(ϵ1,…,ϵn),ϵi∈{−1,+1}。由于 Hn′=SnHn 是正交的,对共享GEMM维度应用相同变换可保留全精度结果:
Hn′=SnHn,Y=XW⊤=(XHn′)(WHn′)⊤.相应的低精度GEMM量化旋转后的操作数:
Y=QG(χHn′)QG(WHn′)⊤.虽然RHT减少了离群值主导,但其有效性严重依赖于底层量化网格。作者识别出主流E2M1格式的一个根本性问题,他们称之为Shrinkage Bias。该偏差源于非均匀网格中Round-to-Nearest-Even (RTNE) 舍入bin的几何不对称性。对于内部量化级别 qi,RTNE舍入bin具有左右宽度 ℓi 和 ri。如果bin内密度局部均匀,则条件期望误差为:
E[ρG(t)−t∣t∈Bi]=2ℓi−ri=42qi−qi−1−qi+1.一个满足 ri>ℓi 的不对称bin固有地产生负期望误差,导致幅度收缩。如下图所示,E2M1网格在间距转换点处表现出这些不对称bin,而像E1M2和INT4这样的均匀网格则保持对称bin(ℓi=ri),从而消除了这种几何偏差来源。
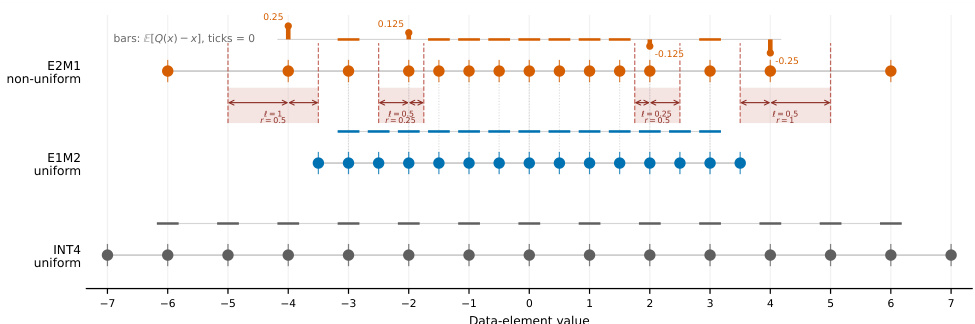
为解决此问题,作者提出UFP4,一种基于统一网格(E1M2/INT4)的4-bit训练方案。一旦RHT将张量从动态范围受限状态转变为局部分辨率受限状态,4-bit网格优先考虑局部幅度保持,而非极端动态范围。完整训练管线参见框架图。
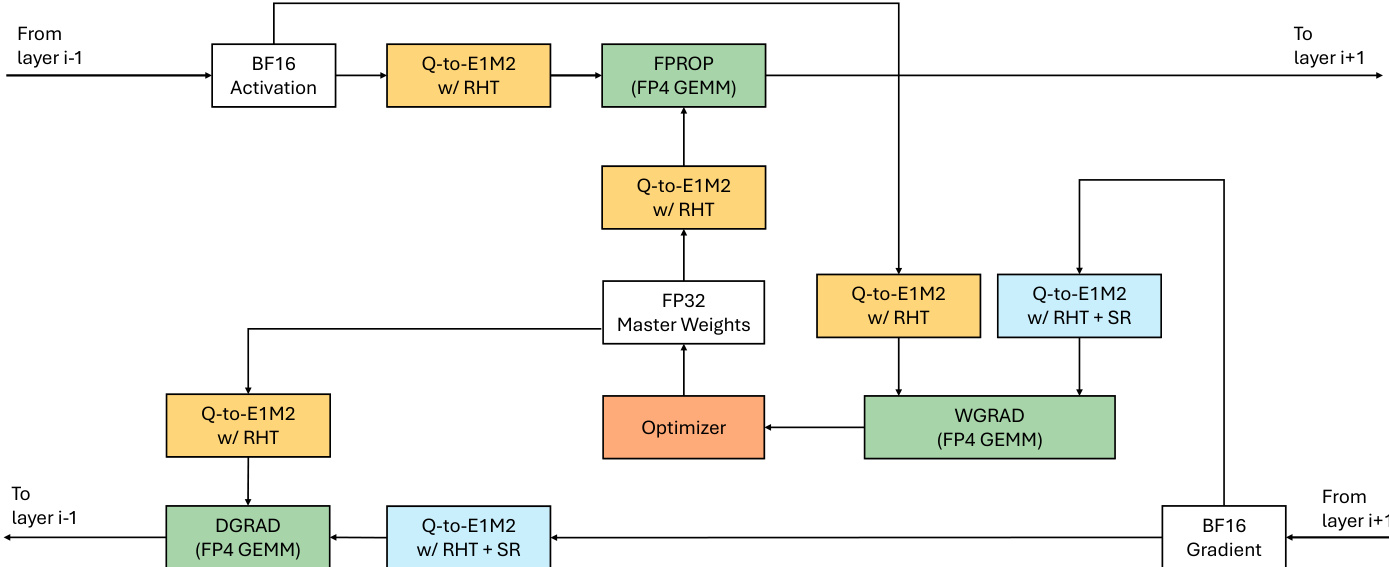
在UFP4方案中,对每个线性层GEMM,作者应用RHT并将操作数量化到均匀间隔网格。关键的是,虽然E2M1方案通常将RHT限制在权重梯度路径以避免复合几何误差,但UFP4的无偏特性允许他们安全地在所有三个GEMM上启用RHT:FPROP (fwd_y)、DGRAD (bwd_dx) 和 WGRAD (bwd(dw))。随机舍入 (SR) 应用于 dY 以保持梯度期望。缩放层次设计与此格式级解决方案正交,允许根据硬件效率选择单层、两层或块缩放。
实验
实验考察了FP4网格几何和Random Hadamard Transform (RHT) 范围如何在局部量化和端到端训练中相互作用。单张量和GEMM输出诊断显示,RHT在离群值密集的张量上逆转了首选格式排名,使旋转后的均匀E1M2网格性能优于E2M1。在多达124B参数的Dense和MoE模型长程预训练中,基于E1M2的UFP4方案相比E2M1参考,始终减少了BF16相对损失差距,且缩放定律验证确认此优势在模型规模上持续存在。消融研究揭示,完整RHT覆盖和输出梯度上的随机舍入均有助于增益,而范围受限的E2M1无法替代原生均匀网格支持,且内核基准测试表明将RHT融合到FP4量化中仅引入适度开销。
作者进行了一项消融研究,评估Random Hadamard Transform范围和随机舍入对FP4 E1M2训练的影响。结果表明,在所有GEMM输出上应用完整变换覆盖可获得最低的语言建模损失,且添加随机舍入进一步提升了性能。完整变换覆盖优于部分应用,证明在E1M2网格下旋转所有GEMM输出是有益的。当与完整变换覆盖结合时,随机舍入提供了额外的损失降低。UFP4方案相比范围受限或无随机舍入的配置,实现了最佳整体性能。
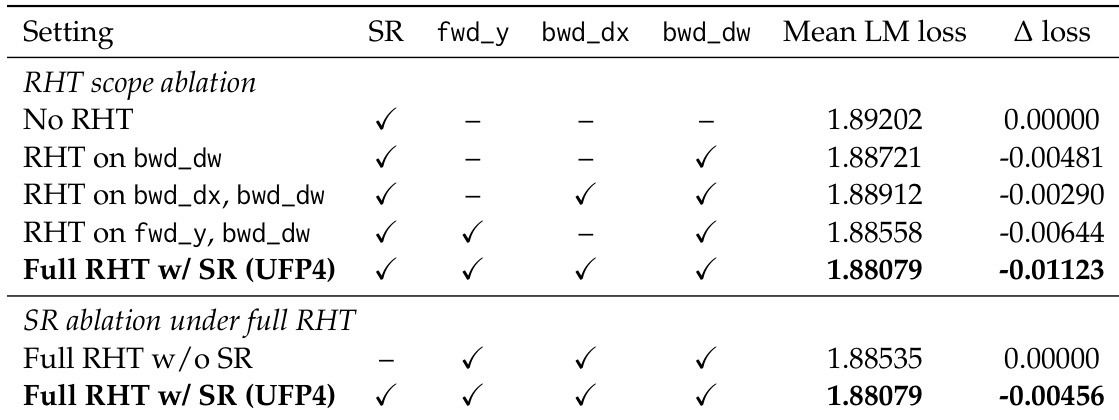
消融研究考察了Random Hadamard Transform的范围和随机舍入的使用如何影响FP4 E1M2训练。将变换应用于所有GEMM输出始终比部分覆盖产生更低的语言建模损失,确认了在此数据格式下完整旋转是有益的。在完整变换覆盖之上添加随机舍入进一步降低了损失,组合后的UFP4方案实现了最佳整体性能。