Command Palette
Search for a command to run...
HydraHead:从头部级功能异质性到专用注意力混合
HydraHead:从头部级功能异质性到专用注意力混合
Zhentao Tan Wei Chen Jingyi Shen Yao Liu Xu Shen Yue Wu Jieping Ye
摘要
注意机制(Attention)的二次方复杂度(Quadratic Complexity)是长上下文处理的关键瓶颈,这也激发了对混合注意力设计的研究兴趣。大多数开源混合模型采用分层(layer-wise)策略。然而,先前的研究指出,将线性注意力(Linear Attention, LA)与全注意力(Full Attention, FA)相结合存在固有的困难,这表明注意力混合的设计空间仍有待深入探索。为了深入探究这一空间,我们进行了可解释性分析,观察到不同层之间表现出块级功能相似性,而同一层内的各个头部(Head)尽管共享输入特征,却展现出 distinct 的功能特异性。这种头部级别的异质性表明,头部维度为融合异构注意力信号提供了一个自然且 principled 的粒度。基于这一见解,我们提出了 HydraHead,一种沿头部轴(head axis)混合 FA 和 LA 的新型架构。HydraHead 包含两项关键创新:(1) 一种由可解释性驱动的头部选择策略,用于识别对检索至关重要的头部,并仅在这些头部中保留 FA;(2) 一个尺度归一化融合模块,用于调和 FA 和 LA 头部输出之间的分布差异。通过利用包含参数复用和蒸馏的三阶段迁移管道,我们以极少的训练开销实现了高性能的混合模型。在统一的训练设置下,HydraHead 在长上下文任务中优于其他混合设计,同时保持了强大的通用推理能力。借助由可解释性驱动的头部选择,它在 7:1 的 LA 到 FA 比例下,达到了与 3:1 分层混合模型相当的长上下文性能。关键在于,仅在 150 亿(15B)个 token 上训练,HydraHead 在 512K 上下文长度下的性能比基线模型提升了超过 69%,接近 Qwen3.5(一款原生上下文长度为 256K 的同规模领先模型)。这凸显了头部级混合化显著的可扩展潜力。
一句话总结
HydraHead 沿头轴混合全注意力与线性注意力,采用可解释性驱动的筛选策略为检索关键头保留全注意力,并通过尺度归一化融合模块协调输出分布。该方法以极小的训练开销实现了卓越的长上下文性能与强大的通用推理能力,在 7:1 的 LA-to-FA 比例下达到与 3:1 逐层混合架构相当的性能,并在 512K 上下文长度下带来超过 69% 的性能提升。
核心贡献
- 本文提出 HydraHead,一种新型 Transformer 架构,沿头维度混合全注意力与线性注意力,以缓解长上下文处理的二次复杂度。通过可解释性驱动的筛选策略识别检索关键头并保留全注意力,其余所有头则通过线性注意力进行路由。
- 尺度归一化融合模块协调全注意力与线性注意力输出之间的分布差异,确保稳定的跨头表征学习。该架构通过利用参数复用与知识蒸馏的三阶段迁移流水线进行优化,在极小训练开销下实现高性能。
- 在统一的训练设置下评估,该模型在长上下文任务中优于现有混合设计,同时保持强大的通用推理能力。仅使用 15B tokens 训练,其在 512K 上下文长度下较基线提升超过 69%,并在 7:1 的线性注意力与全注意力比例下达到与 3:1 逐层混合架构相当的性能。
引言
向自主 LLM agent 的演进需要更长的上下文窗口,但标准全注意力因二次缩放计算成本过高。线性注意力虽提供高效的线性缩放,但常面临表达能力坍塌问题,限制了其执行精确长程检索的能力。先前的混合设计主要依赖逐层或逐 token 混合,但这些方法在训练稳定性、表征一致性或效率提升方面存在不足。本文通过引入 HydraHead 应对这些挑战,这是一种沿头维度混合注意力机制的细粒度架构。研究利用机械可解释性分离检索关键头以使用全注意力,同时将线性注意力分配给其余头。为协调差异化的输出分布,作者开发了尺度归一化融合模块与参数高效的三阶段训练流水线,最终在极小训练开销下实现最先进的长上下文性能与稳健的通用推理能力。
实验
评估基于 Qwen3-1.7B 主干网络,在长上下文检索与通用推理基准上进行,旨在将提出的 HydraHead 架构与逐层、逐 token 及其他替代的逐头基线进行对比。架构对比验证了逐头混合在平衡长上下文外推与复杂推理方面,天然优于粗粒度替代方案。结构与融合消融实验证实,结合特征归一化与静态缩放调制的可解释性引导头选择,能够确保训练稳定性并最大化分支协同效应。最后,训练优化与扩展实验展示了该方法稳健的泛化能力及其相对于现有混合设计的持续优势。
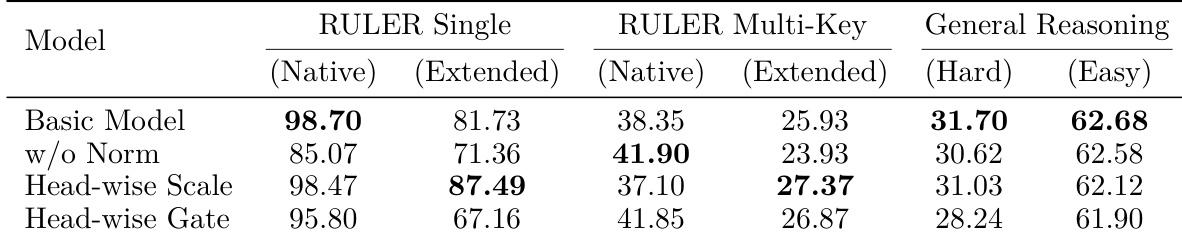
作者评估了结合全注意力与线性注意力头的特征融合策略,强调归一化在对齐异构特征分布中的关键作用。未经归一化的直接拼接会导致检索与推理基准上的性能显著下降。静态逐头缩放持续优于动态门控,尤其在长上下文外推场景中,确立了其作为更优融合机制的地位。未经归一化的直接拼接会严重削弱检索准确率与通用推理能力。与动态门控机制相比,静态逐头缩放为长上下文任务提供了更稳定的表征。动态门控仅在训练长度范围内提供局部收益,但在长度外推期间无法维持优势。
作者将混合模型的训练结构化为三个渐进阶段,以优化收敛过程并适应不同的序列长度。通过调整批量大小与学习率调度等超参数,稳定不同注意力机制间的优化动态。该配置使模型能够有效迁移知识,并在最终阶段适应长上下文依赖。训练流水线在初始阶段采用余弦学习率调度器以确保稳定收敛,随后切换为恒定速率。最终阶段显著增加上下文长度,以精炼模型处理扩展序列的能力。第二个训练阶段消耗了总 token 预算的最大份额,凸显了中间知识迁移的重要性。

作者将 HydraHead 与标准全注意力模型及其他混合架构进行对比,以评估长上下文检索能力。结果表明,全注意力模型在较短序列上表现优异,但随着上下文长度增加,性能显著下降。相比之下,提出的混合方法在扩展长度上保持高准确率,有效平衡了外推能力与多键检索性能。在其他混合模型性能显著衰退的扩展上下文长度下,HydraHead 仍能维持高检索准确率。该混合方法在长上下文外推与多键检索任务的稳健性能之间取得了平衡。与提出的混合架构相比,标准全注意力模型在最长上下文长度下面临严重的性能挑战。
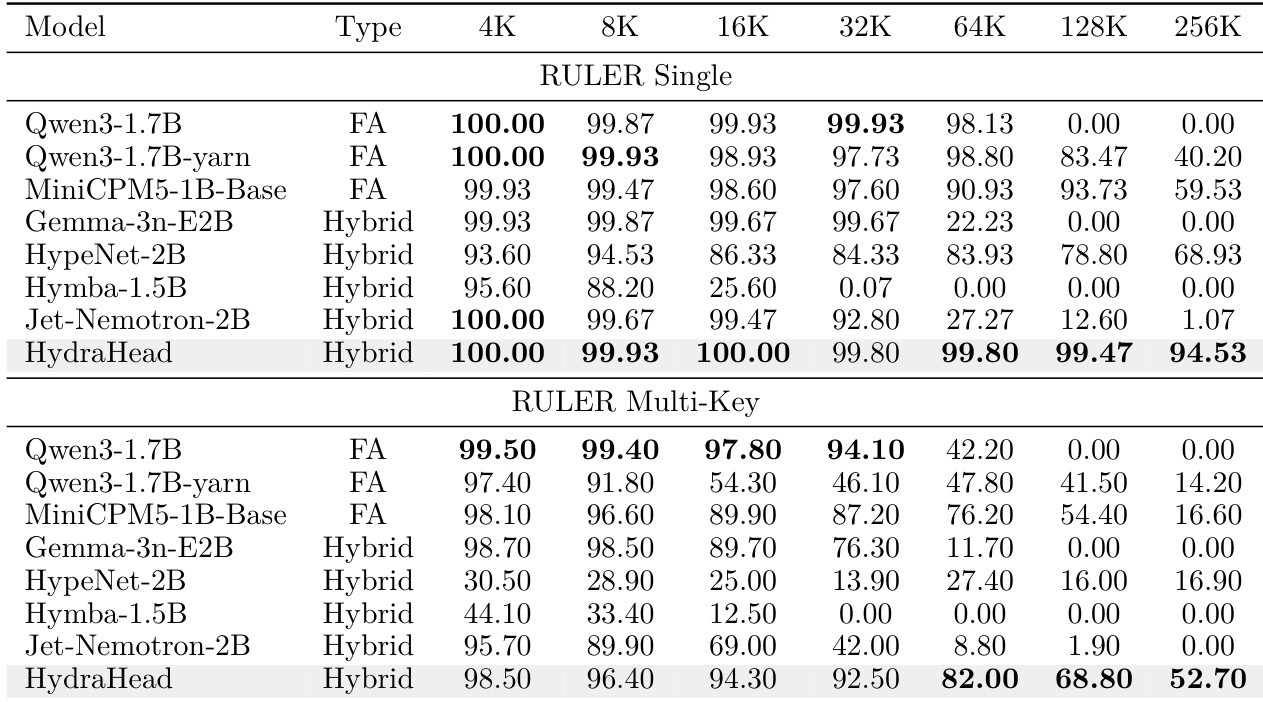
对比表明,采用可解释性引导选择且线性注意力比例更高的逐头混合架构,实现了与传统逐层混合方法相当的长上下文检索性能。尽管全注意力头的计算预算显著稀疏,该方法仍在挑战性与标准基准上大幅提升了通用推理能力。该逐头混合架构在比逐层基线高得多的效率比下,仍保持稳健的扩展上下文检索性能。与均匀的逐层替换相比,可解释性引导的头分配在复杂通用推理任务中带来显著改进。所提架构成功平衡了计算效率与具有挑战性推理基准上的卓越性能,且未牺牲长上下文能力。

作者在三阶段训练中优化流水线,以平衡知识迁移与长上下文适应。在初始阶段扩大数据量与批量大小以稳定优化过程,同时保留最终阶段使用显著更长的上下文长度进行微调。该配置在各项评估基准上带来一致的性能提升,尤其在具有挑战性的长上下文与推理任务中。训练策略从较短上下文与衰减学习率开始,逐步过渡到以恒定学习率聚焦扩展上下文长度的最终阶段。早期阶段增加数据规模与批量大小增强了知识迁移,并稳定了异构注意力分支间的优化过程。最终训练阶段采用显著更大的序列长度,以更好地适应长上下文依赖。

作者评估了一种混合注意力架构,该架构通过三阶段渐进训练流水线整合全注意力与线性注意力头,旨在稳定优化过程并适应扩展序列长度。初步实验验证了特征融合策略,证明合理的归一化与静态逐头缩放对于维持稳定表征以及在长上下文外推期间超越动态门控至关重要。与标准全注意力及逐层混合基线的对比评估表明,所提出的可解释性引导逐头方法成功平衡了计算效率与稳健的多键检索能力,并显著增强了复杂推理能力。最终,本研究证实结构化混合与渐进式训练能有效解决长上下文扩展性与通用推理性能之间的固有权衡问题。