Command Palette
Search for a command to run...
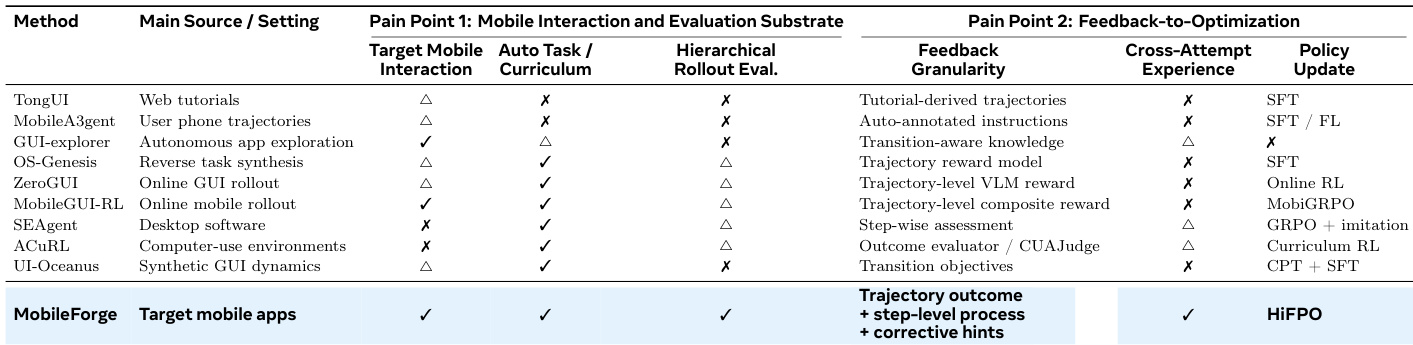
MobileForge:面向移动GUI Agents的无标注适配与基于分层反馈引导的策略优化
MobileForge:面向移动GUI Agents的无标注适配与基于分层反馈引导的策略优化
摘要
基于多模态大语言模型(MLLM)的移动GUI agents在UI理解和动作执行方面取得了显著进展,但将其适配到真实目标应用仍然成本高昂,因为移动应用数量庞大、更新频繁,且难以通过人工编写的任务、演示或奖励标签进行充分覆盖。现有的无标注GUI学习方法虽减少了人工监督,但缺乏连接目标应用探索、课程挖掘、rollout执行与反馈的统一基础框架;同时,策略优化往往依赖于孤立的rollout和粗粒度奖励,难以将其转化为可靠的改进信号。本文提出MobileForge,一种面向移动GUI agents的无标注适配系统。MobileForge包含MobileGym与分层反馈引导策略优化(HiFPO)两个模块。MobileGym将任务生成与rollout评估建立在真实的移动应用交互之上;HiFPO则将轨迹结果、步骤级过程反馈及纠正提示转化为基于提示上下文的步骤级GRPO更新。仅利用自动生成的无标注适配数据,MobileForge即可将Qwen3-VL-8B在AndroidWorld上的Pass@3指标提升至67.2%,该结果已接近采用封闭数据的GUI专用基础模型GUI-Owl-1.5-8B(69.0%)。经MobileForge适配的ForgeOwl-8B在AndroidWorld上的Pass@3进一步达到77.6%,在域外MobileWorld的纯GUI划分上取得41.0%的成功率,确立了本评估中性能最强的开放数据移动GUI agents。相关代码、数据及训练模型将于https://mobile-forge.github.io/开源发布。
一句话总结
MobileForge 是一种免标注适配系统,采用 MobileGym 将任务生成与 rollout 评估锚定于真实的移动应用交互中,其分层反馈引导策略优化(Hierarchical Feedback-Guided Policy Optimization, HiFPO)组件将轨迹结果与纠正提示转化为提示上下文感知的步级 GRPO 更新,使 Qwen3-VL-8B 模型在 AndroidWorld 上达到 67.2% 的 Pass@3 成绩,并使适配后的 ForgeOwl-8B 变体达到 77.6% 的 Pass@3。
核心贡献
- 该工作引入了 MobileGym,这是一种交互与评估基础架构,将任务生成与 rollout 执行直接锚定于真实的移动应用轨迹中。该组件提取可执行任务,并提供分层结果反馈与纠正提示,以实现评估与策略学习的对齐。
- 该框架整合了分层反馈引导策略优化(HiFPO),通过分层反馈过滤轨迹,并将步级过程信号转化为提示上下文感知的 GRPO 更新。该机制在多次 rollout 尝试中积累可复用经验,从而在孤立优化循环之外进一步细化 agent 能力。
- 在 AndroidWorld 与 MobileWorld GUI-only 基准上的评估表明,该适配流程可有效迁移至通用模型与专用模型。最终生成的 ForgeOwl-8B agent 在 AndroidWorld 上取得 77.6% 的 Pass@3 成绩,在 MobileWorld GUI-only 上达到 41.0% 的成功率,确立了本次评估中最强的开放数据移动 GUI agent 地位。
引言
由多模态语言模型驱动的当代移动 GUI agent 展现出强大的 UI 理解能力,但由于应用生态庞大且快速演进,将其适配至真实应用场景的成本依然高昂。先前的免标注方法试图减少人工监督,但受限于碎片化的流程,未能有效串联应用探索、课程挖掘与反馈执行。其策略优化通常也将交互视为具有稀疏奖励的孤立片段,阻碍了可靠步级改进信号的积累。针对上述不足,MobileForge 被提出,这是一种免标注适配框架,通过 MobileGym 将任务生成与评估锚定于真实应用交互中,并引入分层反馈引导策略优化,将纠正提示转化为提示上下文感知的 GRPO 更新,从而实现基准测试的显著提升。
数据集

-
数据集构成与来源: 适配任务池以 20 个独立应用中的 527 个参考轨迹标识符为锚点构建。该基础数据衍生出专为 AndroidWorld 环境设计的 3,249 个任务的综合候选池。
-
子集详情与过滤规则: 每个源应用贡献一个由课程生成的包含三至八个新任务的子集。系统应用严格的生成约束,确保任务覆盖不同的核心功能,长度在一步至四十步之间变化,并保持教学实用性。冗余被主动避免,每个功能的参数变体限制在最多三个,以强调有意义的行为差异而非微小调整。
-
数据使用与处理: 筛选后的任务直接输入模型训练流程,以支持免标注适配。在集成前,每个候选任务均经过自动化评估以过滤低质量样本。数据通过评分机制处理,该机制衡量任务合理性、完成可能性与步级质量,仅保留高置信度轨迹用于分层反馈引导的策略优化。
-
元数据构建与处理详情: 最终数据集条目格式化为 JSON 对象,将评估指标与任务规范配对。每条记录包含独立指令、预估步数、目标核心功能、变体类型及明确的前置条件。配套的元数据块提供置信度分数与解释性摘要,用于指导训练循环并在策略更新期间验证步级质量。
方法
MobileForge 是一种免标注适配框架,旨在无需依赖人工编写任务、专家演示或奖励标签的情况下,自主将移动 GUI agent 适配至目标应用。该架构分为两个耦合组件:MobileGym 作为交互与评估基础,HiFPO 驱动反馈引导的策略优化。整体适配循环请参考框架示意图。

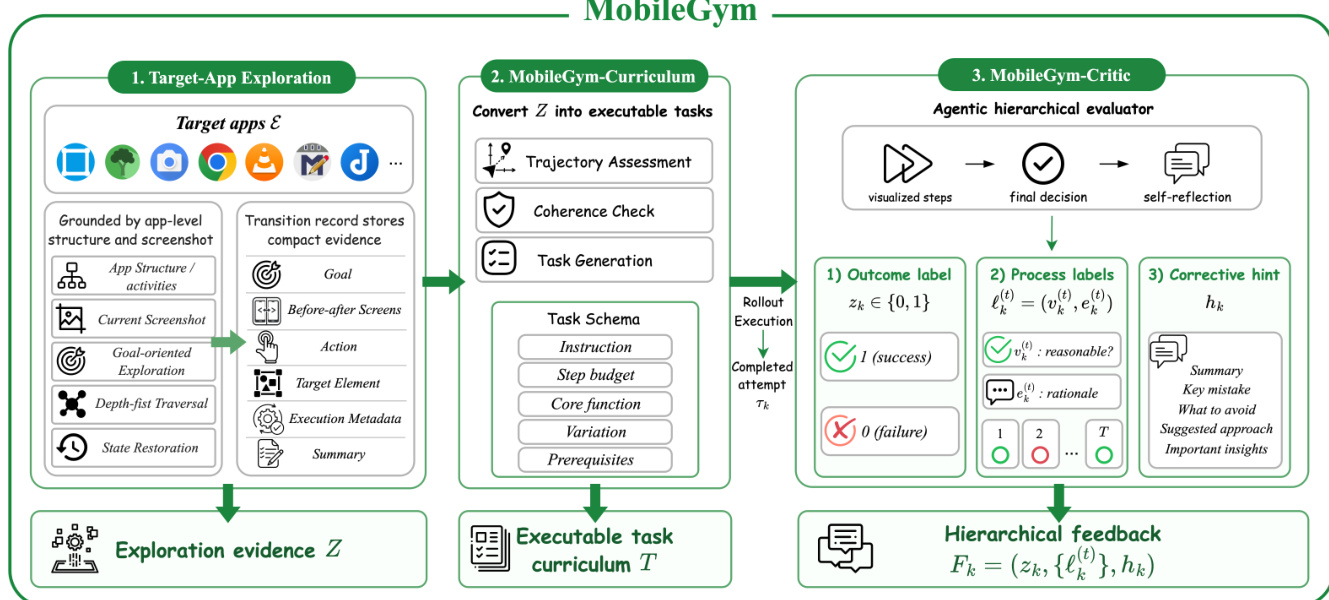
MobileGym 将适配过程锚定于真实的目标应用交互中。该模块始于功能感知探索阶段,记录可达的 GUI 状态转移、应用级结构锚点与交互摘要,以构建探索证据池 Z。随后,MobileGym-Curriculum 模块处理该证据,评估轨迹连贯性并生成一组基于观测到的应用行为的可执行任务 T。在 rollout 执行期间,MobileGym-Critic 对已完成的尝试进行评估以生成分层反馈。如图所示,该评估器作为智能体评估器运行,将原始执行日志转换为可视化动作轨迹,并生成包含结果标签 zk∈{0,1}、步级过程标签 ℓk(t) 与纠正提示 hk 的结构化判决。
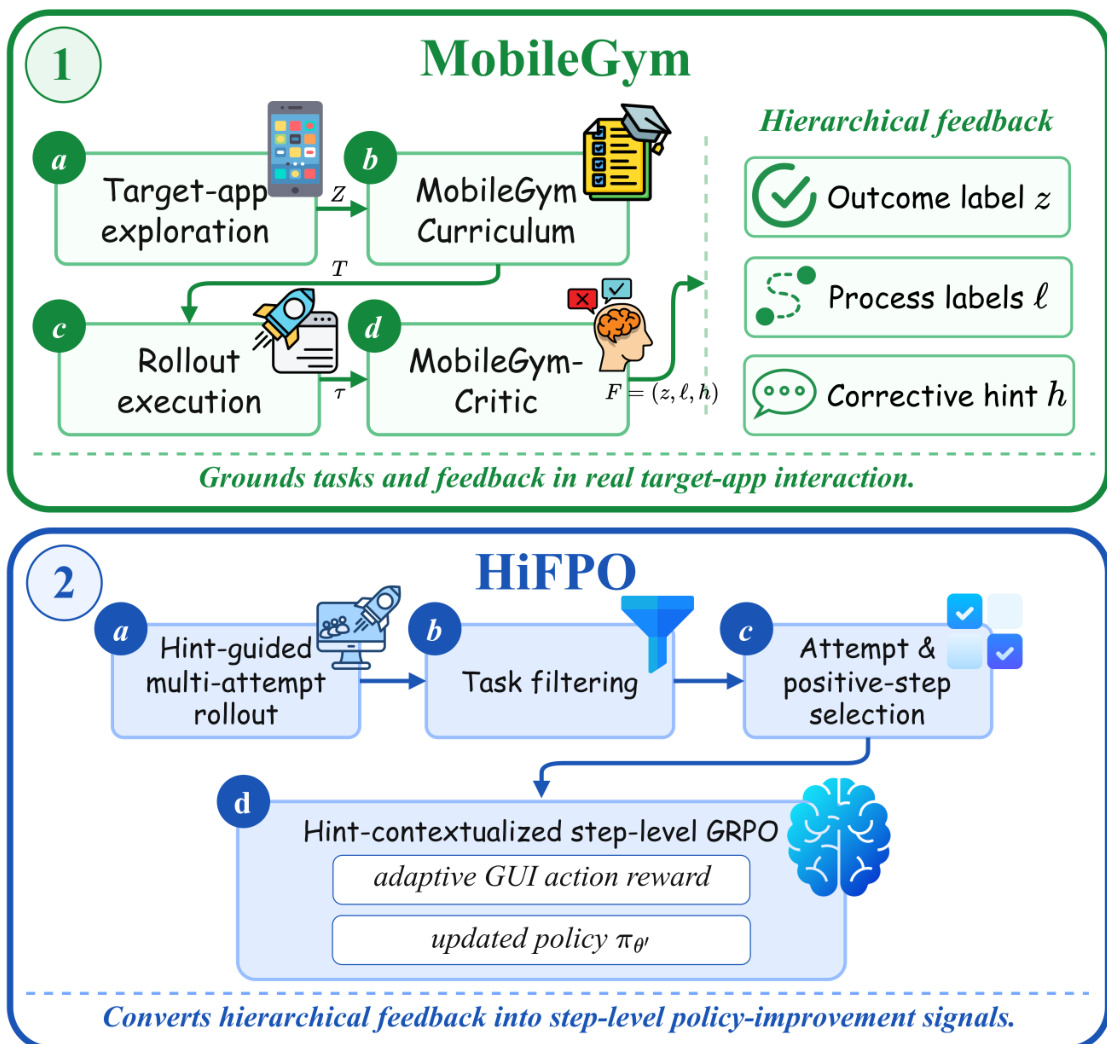
HiFPO 利用该分层反馈,通过多次尝试 rollout 协议驱动策略更新。对于课程中的每个任务,系统以串行方式执行 K 次尝试。在每次尝试 k 之前,框架聚合先前尝试的纠正提示以构建提示上下文 η<k=Aggregate(h1,…,hk−1)。策略随后基于该累积上下文生成新的 rollout 尝试。系统过滤掉成功率为 1 的已掌握任务,仅保留部分解决或失败的任务以进行进一步优化。
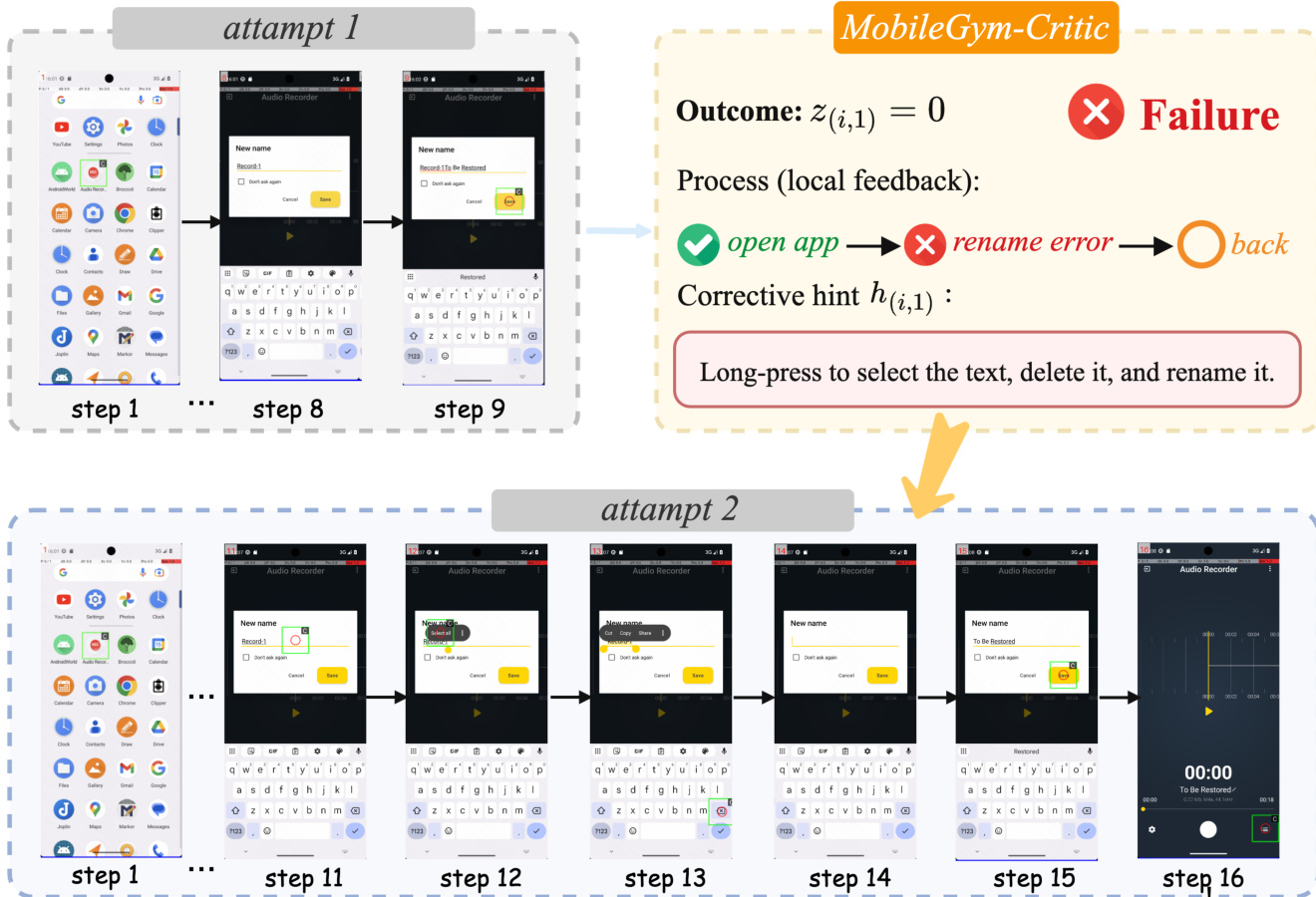
为将长周期轨迹转化为密集监督信号,HiFPO 执行双反馈过滤。它通过优先选择包含最高比例合理局部步骤的成功 rollout,或选择表现最佳的失败尝试,为每个保留的任务挑选信息量最大的尝试。从选定的尝试中,仅提取局部合理的步骤以构建步级训练集 D。纠正提示会在下一次 rollout 尝试前附加至任务指令,使 agent 能够从历史错误中学习。此提示引导的细化过程示例如图所示。
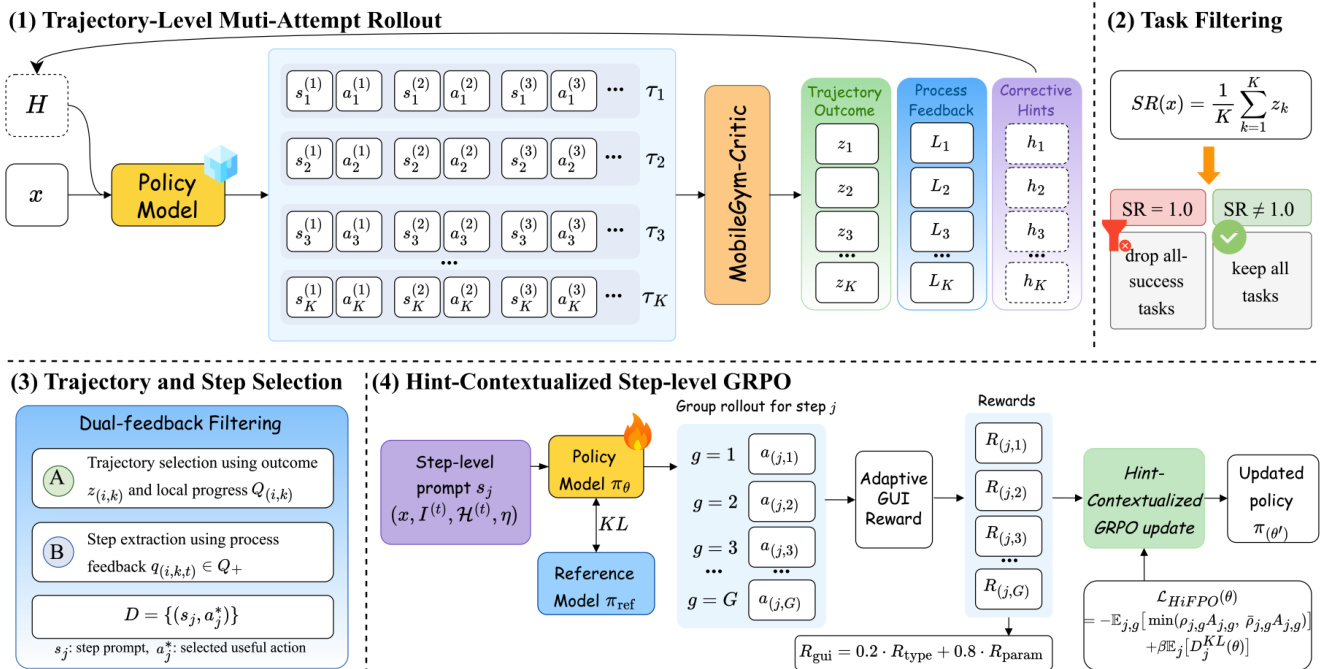
最终训练阶段采用提示上下文感知的步级 GRPO 算法。对于每个选定步骤,决策状态会附加纠正提示上下文并渲染为提示 s~j。策略从旧策略中采样一组 G 个候选响应。每个响应被解析为结构化的 GUI 动作,并使用自适应 GUI 动作奖励进行评分,该奖励将动作类型正确性与参数精度分离计算。响应奖励计算方式为 Rj,g=λtyperj,gtype+λargrj,garg。响应组内的奖励经过归一化以计算相对优势 Aj,g=(Rj,g−μj)/(σj+ϵstd)。随后策略通过带 KL 正则化的截断 GRPO 目标函数进行更新:
LHiFPO(θ)=−Ej,g[min(ρj,gAj,g,ρˉj,gAj,g)]+βEj[DjKL(θ)],其中 ρj,g 与 ρˉj,g 分别代表重要性比率及其截断版本。该设计确保策略优化严格依赖于反馈感知状态,从而在不依赖外部奖励模型的情况下实现稳健的步级信用分配。
实验
该评估在域内 AndroidWorld 基准与域外 MobileWorld 划分上检验免标注适配效果,使用两个 8B 规模的基础 agent,性能在 200 至 900 个生成任务间进行扩展。主要实验表明,所提出的适配框架成功在域内将通用模型与专用 GUI agent 对齐,同时实现了有意义的跨域泛化。消融研究验证了多次尝试纠正提示、提示上下文感知 GRPO 优化、保留困难或部分解决任务的战略过滤,以及基于轨迹的课程设计均为有效学习所必需。定性分析证实,这些组件共同增强了 agent 在复杂 UI 序列中维持任务意图的能力并提升核心交互技能,尽管在长周期多步与跨应用工作流中仍存在局限性。
MobileForge 被提出以解决移动交互与反馈挑战,该框架通过在跨尝试经验循环中运用自动生成课程、分层 rollout 评估与纠正提示实现目标。结果表明,该免标注适配显著增强了通用模型与 GUI 专用 agent 的性能,使通用模型在域内基准上逼近专用系统的表现,同时展现出向域外环境的迁移能力。消融研究证实,提示上下文感知优化、通过战略过滤保留困难任务以及使用基于轨迹的课程生成等特定设计选择,对最大化这些改进至关重要。MobileForge 利用纠正提示与跨尝试经验大幅提升了多次尝试 rollout 的成功率。该适配流程使通用模型在域内任务上达到与 GUI 专用 agent 相当的性能水平。基于轨迹的课程生成提供了比仅依赖初始应用屏幕的方法更广泛的功能覆盖。
实验评估了不同决策模型对适配循环的影响。结果表明,Gemini 2.5 Pro 在大多数指标上表现最强,而开源的 Qwen3-VL-8B 模型也显著优于未训练基线。这证明即使使用算力较弱或开源的评估器,适配流程依然有效。Gemini 2.5 Pro 在大多数 Pass@k 指标上取得最高成功率。作为决策模型,Qwen3-VL-8B 显著优于基础未训练策略。无论使用专有还是开源决策模型,反馈至优化的循环均能带来收益。

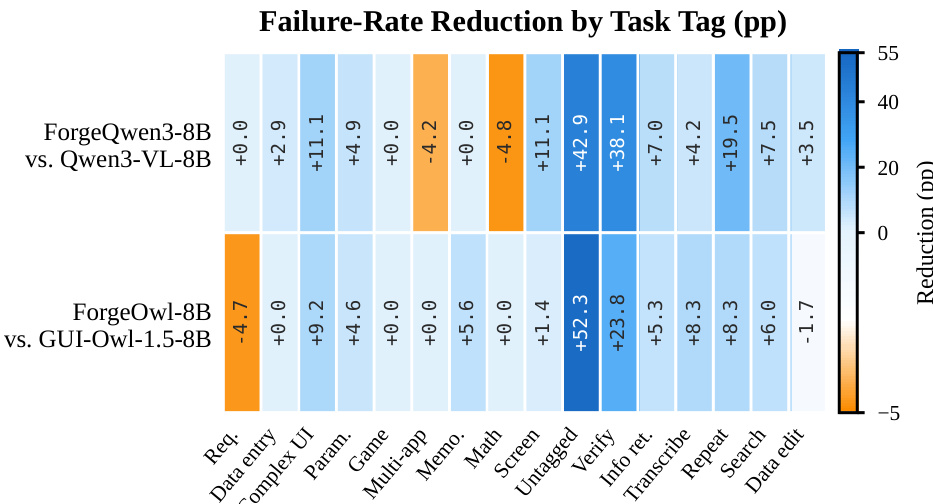
两个适配模型与基础 agent 相比的失败率降低情况在各类任务类别中得到分析。数据显示,适配流程显著提升了特定 UI 相关技能的性能,而复杂或多步推理任务的表现仍具挑战性。验证与搜索任务在两个适配模型中均显示出最大的失败率降幅。适配显著改善了处理复杂用户界面与信息检索的能力。多应用任务与游戏场景则表现出性能回落或改善不足。
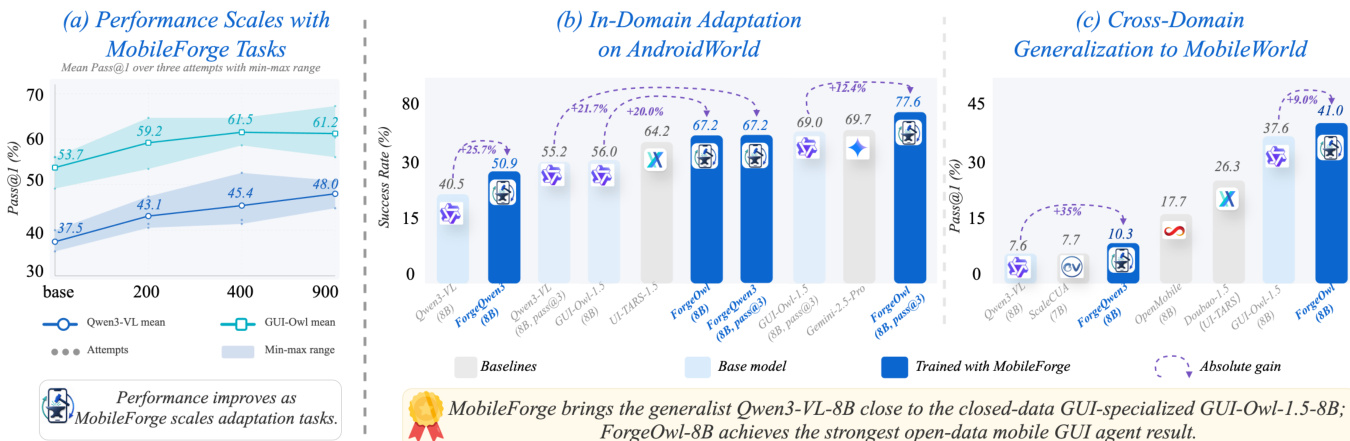
实验表明,MobileForge 通过在 AndroidWorld 上进行免标注适配,显著提升了移动 GUI agent 的性能。适配模型(具体为 ForgeQwen3 与 ForgeOwl)相比基础版本取得大幅增益,并与专用基线具备竞争力。此外,该方法在域外 MobileWorld 任务上展现出良好的泛化能力,其中 ForgeOwl 在开放数据 agent 中取得最强结果。随着适配任务数量的增加,性能持续改善,表明该方法能随训练数据增加有效扩展。适配后的 ForgeOwl 模型在 AndroidWorld 任务上取得最高成功率,超越基础模型与其他专用基线。在域外设置中,适配后的 ForgeOwl 模型对 MobileWorld 展现出强大的泛化能力,在评估模型中取得最高成功率。
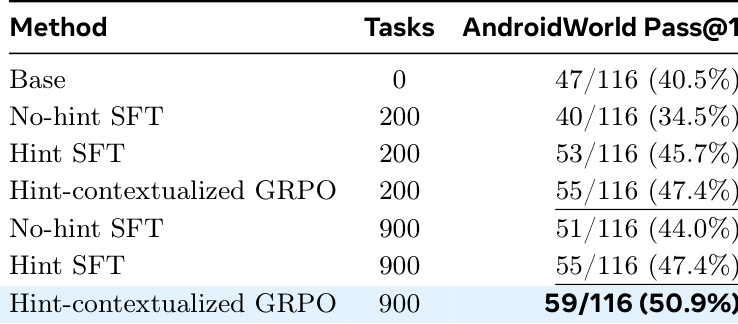
不同训练目标与提示使用在不同任务规模上对模型适配的有效性得到探讨。结果表明,无提示训练可能导致相对于基础模型的性能下降,而引入提示则带来性能提升。提示上下文感知的组相对策略优化方法持续优于监督微调方法,确立其为最有效的适配策略。无提示训练的性能低于基础模型。将提示纳入监督微调可提升基础模型的性能。提示上下文感知的组相对策略优化在所有任务规模下均取得最高性能。
实验在域内与域外移动环境中评估 MobileForge 框架,以验证其免标注适配流程,该流程整合了纠正提示、基于轨迹的课程与跨尝试经验循环。不同决策模型、训练目标与任务类别的对比证实,提示上下文感知优化与战略过滤对最大化 agent 性能至关重要,尤其在用户界面导航与信息检索方面。最终,该框架使通用模型在域内逼近专用系统,同时能随额外任务有效扩展,并在开源评估器支持下保持强大的迁移能力。