Command Palette
Search for a command to run...
MemGUI-Agent:一种具有主动上下文管理的端到端长程移动 GUI Agent
MemGUI-Agent:一种具有主动上下文管理的端到端长程移动 GUI Agent
Guangyi Liu Gao Wu Congxiao Liu Pengxiang Zhao Liang Liu Mading Li Qi Zhang Mengyan Wang Liang Guo Yong Liu
摘要
基于多模态大语言模型(MLLM)的移动GUI agents在短期任务上取得了显著进展,但在需要跨多个步骤与应用切换保留中间事实的长期任务中仍不可靠。我们将这一局限性归因于ReAct风格提示,该方法被动累积单步记录,从而导致提示词爆炸以及关键跨应用事实的稀释。为解决这一问题,我们提出了MemGUI-Agent,这是一种具备主动上下文管理能力的端到端长期移动GUI agent。MemGUI-Agent基于Context-as-Action(ConAct)构建,该机制将上下文管理视为由选择UI操作的同一策略所生成的第一类动作。与被动追加历史记录不同,ConAct维护三个结构化上下文字段:折叠的动作历史、折叠的UI状态以及最近的步骤记录,在保持上下文紧凑的同时保留关键的UI事实。为使主动上下文管理在不同模型规模下具备可学习性,我们构建了MemGUI-3K数据集。该数据集包含2,956条轨迹,并附有完整的ConAct标注,用于监督训练与离线分析。在MemGUI-3K上训练8B模型得到了MemGUI-8B-SFT,这是一个参数量为8B的MemGUI-Agent。该模型在MemGUI-Bench上取得了基于开放数据的8B模型最佳性能,并成功泛化至分布外(OOD)的MobileWorld基准测试。代码、数据及训练好的模型将于https://memgui-agent.github.io/开源发布。
一句话总结
MemGUI-Agent,一种端到端的长程移动GUI agent,通过将上下文操作视为策略动作并维护包含折叠动作历史、折叠UI状态和近期步骤记录的三个结构化字段,以“上下文即动作”(ConAct)的方式主动管理上下文,在MemGUI-Bench上取得了开源8B模型的最佳性能,并在MemGUI-3K数据集上训练后泛化至MobileWorld。
核心贡献
- MemGUI-Agent,一种端到端的移动GUI agent,通过上下文即动作(ConAct)的构建,用主动的上下文管理取代了被动的历史累积,其策略发出结构化动作以维护三个紧凑字段:折叠动作历史、折叠UI状态和近期步骤记录。
- MemGUI-3K提供了2,956条带有完整ConAct标注的轨迹,能够支持在不同模型规模下对主动上下文管理的监督训练与离线分析。
- 在MemGUI-3K上微调8B模型得到MemGUI-8B-SFT,该模型在MemGUI-Bench上取得了开源8B模型的最佳性能,并泛化至分布外基准MobileWorld。
引言
由多模态大语言模型(MLLM)驱动的移动GUI agent能可靠处理短任务,但在需要跨多步骤和应用切换记忆关键信息的长程工作流中表现不佳。以往的端到端agent通常采用被动上下文机制,如ReAct风格的思考-动作轨迹,这导致提示随每一步而膨胀,并稀释重要的跨应用UI细节,使其在扩展任务上容易出错。作者通过MemGUI-Agent解决了这一问题,这是一种将上下文管理视为一类首要动作的端到端agent。其上下文即动作(ConAct)策略联合决定执行哪个UI动作以及如何维护一个紧凑、结构化的上下文,保留折叠动作历史、折叠UI状态和近期步骤记录,使得关键的UI衍生事实得以被逐字保留。他们还构建了MemGUI-3K数据集,包含2,956条为主动上下文动作标注的轨迹,并用其训练一个8B模型,该模型在MemGUI-Bench基准上取得了开源最佳性能,并泛化至分布外的MobileWorld基准。
数据集
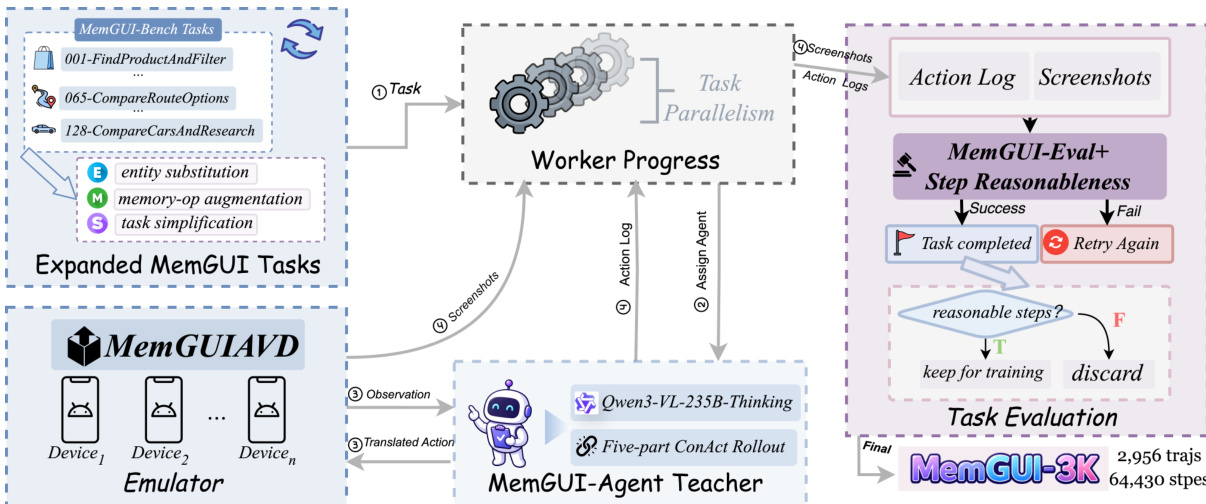
作者从MemGUI-Bench的128个长程种子任务出发构建MemGUI-3K数据集。他们通过三种策略扩充种子池:实体替换保留任务结构但更换实体;记忆操作增强增加了需要更新和删除动作的任务;任务简化将复杂任务分解为更短的单一目标变体。该扩充产生了一个包含7,303个任务的任务池,从中选出5,293个用于教师引导的轨迹执行。所有执行均使用Qwen3-VL-235B-Thinking教师模型在基于快照的Android环境中执行完整的5部分CoNACT协议,步骤预算为黄金步骤数的2.5倍再加一步。
关键数据集细节:
- 最终轨迹集包含2,956条成功轨迹,覆盖26个应用和7个类别,经MemGUI-Eval的渐进式审查管线的筛选(移除了一个异常轨迹和两条低频应用轨迹),然后按轨迹级别以90/10划分,并验证与MemGUI-Bench评估任务零重叠。
- 每一步都被标注为合理或不合理。仅合理步骤(占总步骤75.7%,平均每条轨迹21.8步)作为监督微调样本。
- 由此产生的步骤级SFT集合包含64,430个样本(57,951训练,6,479测试)。每个样本将用户消息(base64编码的截图加结构化上下文:折叠动作历史、折叠UI状态、近期步骤记录和查询)与5部分CoNACT格式的黄金助手回复(思考、折叠、工具调用、UI观察、动作意图)配对。
- 轨迹平均28.8步,中位数25;记忆动作出现在65.1%的轨迹中;23.8%的折叠是跨度级摘要,平均包含6.25步,88.7%的轨迹包含至少一个跨度级折叠。
论文如何使用数据:
- 作者使用ms-swift框架通过LoRA在步骤级SFT样本上微调Qwen3-VL-8B-Instruct,得到MemGUI-8B-SFT。
- 未采用数据集混合或配比,训练仅依赖MemGUI-3K的SFT样本。
处理与元数据细节:
- 提供全分辨率截图,无裁剪;图像以base64字符串嵌入用户消息。
- 结构化上下文(折叠历史、折叠UI状态、近期步骤记录)由教师在轨迹执行中的CoNACT动作构建,为模型提供丰富的长程上下文监督。
- 数据集以两种互补格式发布:轨迹级格式保留完整执行、评估元数据和步骤级标注;步骤级SFT格式兼容ms-swift。
方法
作者提出了MemGUI-Agent,一种端到端的移动GUI agent,利用ConAct(上下文即动作)将上下文管理变为动作策略的一等部分。该agent不将上下文视为模型控制之外的被动日志,而是联合决定执行哪个UI或记忆动作、折叠哪些历史、以及如何描述当前交互,从而将上下文维护转化为策略级行为。
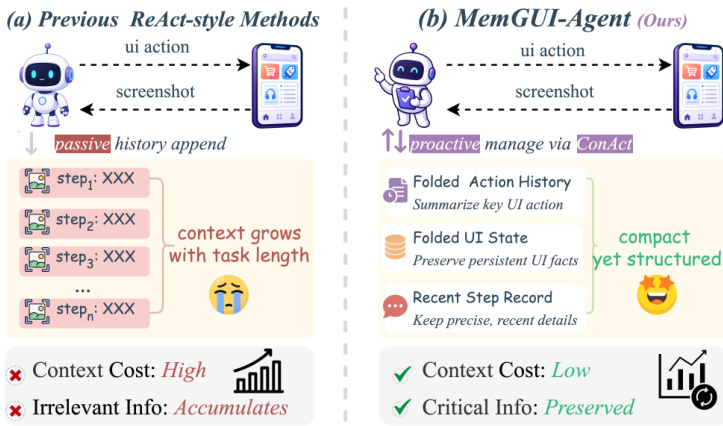
如下图所示,以往ReAct风格的方法被动追加历史,导致上下文成本随任务长度增长,无关信息不断累积。相比之下,MemGUI-Agent通过ConAct主动管理上下文,维护一个紧凑而结构化的状态,包括折叠动作历史、折叠UI状态和近期步骤记录,在保持关键信息的同时将上下文成本控制在较低水平。
作者将移动GUI自动化形式化为一个具备结构化工作上下文的序列决策问题。给定任务目标G和截图It,agent观察状态:
St=(G,Ht,Mt,Lt),其中Ht、Mt和Lt分别表示折叠动作历史、折叠UI状态和近期步骤记录,存储压缩的轨迹摘要、持久的UI派生事实和最新步骤细节。
在每一步,MLLM策略发出一个联合ConAct决策:
yt=(τt,ϕt,at,ot,ιt)∼πθ(⋅∣It,St),其中τt是推理,ϕt是折叠指令,at是UI或记忆动作,ot是UI观察,ιt是动作意图。与追加不断增长的任务进度字符串的ReAct风格提示不同,ConAct将上下文划分为三个字段,并通过模型发出的上下文动作进行更新。
参见框架图中单步执行流程。模型输出一个5部分结构化输出。<tool_call>字段每步执行扩展动作空间中的恰好一个动作:
这里,Aui包含如点击、输入、滑动、等待和终止的UI动作。记忆动作更新Mt。
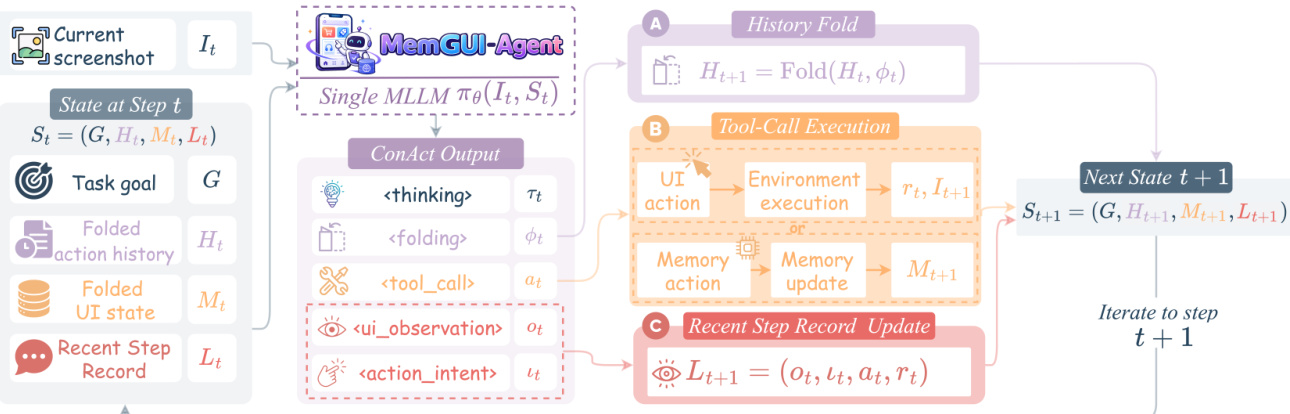
从第2步开始,agent发出一个强制的<folding>块。形式上,折叠指令为ϕt=([st,t],zt),其中[st,t]是要压缩的历史跨度,zt是生成的摘要。步骤级蒸馏对应st=t,将最新一步保持为一条紧凑记录;跨度级抽象则使用st<t,将完成的子任务总结为一条可复用的记录。折叠历史按如下方式更新:
这将不受控制的结论累积替换为模型控制的折叠,将上下文的增长从线性累积推向亚线性增长。
每个记忆项是一个结构化三元组m=(id,d,c),其中id是唯一标识符,d是简短描述,c是要保留的完整内容。设Amem={a+,a∘,a−}表示记忆添加、记忆更新和记忆删除。记忆动作诱发:
Mt+1=⎩⎨⎧Add(Mt,m),Update(Mt,id,c),Delete(Mt,id),Mt,at=a+,at=a∘,at=a−,at∈Aui.记忆写入存储完整的任务相关信息,而非引用或有损摘要。当价格、代码、联系信息或复制的文本需要在屏幕变化、长时间延迟和应用切换中保存时,这一点至关重要。
这两个自描述字段使每一步都能被未来的上下文动作重复使用。<ui_observation>提供基于屏幕的描述,包含确切的可见文本、数字、名称和与任务相关的UI事实。<action_intent>说明当前工具调用旨在完成什么。结合执行的动作和工具结果,它们形成:
此记录为写入Mt的记忆和未来折叠进Ht的内容提供了可靠内容。
在第t步,MLLM πθ接收(It,St)并发出yt=(τt,ϕt,at,ot,ιt)。环境/工具结果为:
(rt,It+1)={Env(It,at),(ok,It),at∈Aui,at∈Amem,其中UI动作改变屏幕,记忆动作仅更新结构化上下文。结合方程式,完整的状态转移为:
St+1=T(St,yt,rt)=(G,Ht+1,Mt+1,Lt+1).下一状态St+1被送入第t+1步。由于折叠、记忆和动作意图由同一个多模态策略在一次前向传播中预测,压缩和记忆继承agent的任务级推理,而非委托给单独的总结器、检索器或记忆agent。
为训练学生模型,作者利用教师模型和专门的评估管线。如下图所示,训练过程始于扩展的MemGUI任务。MemGUI-Agent教师(Qwen3-VL-235B-Thinking)在MemGUI-AVD模拟器上执行五部分ConAct轨迹。监控工作进程,截图和动作日志馈送至MemGUI-Eval+并进行步骤合理性分析。评估器将每一步标注为合理或不合理。仅标注为合理的步骤被转换为SFT样本,形成最终的MemGUI-3K数据集。
实验
评估采用两个长程移动GUI基准,MemGUI-Bench和MobileWorld,以评估跨多步、跨应用任务的任务成功率和记忆保持力。使用235B模型的零样本ConAct取得了新的最优性能,超越了复杂的agentic框架;而在MemGUI-3K数据集上微调的8B模型取得了开源8B最佳性能,并迁移至分布外环境,增益集中在最困难的任务上。消融研究证实,ConAct的三个组件(历史折叠、UI记忆动作和自描述步骤输出)是互补的,每个组件都解决了一种不同的失败模式;错误分析表明,完整系统主要减少了过程和输出幻觉,证明主动上下文管理有效防止了长程信息丢失,而非依赖于更强的推理或领域知识。
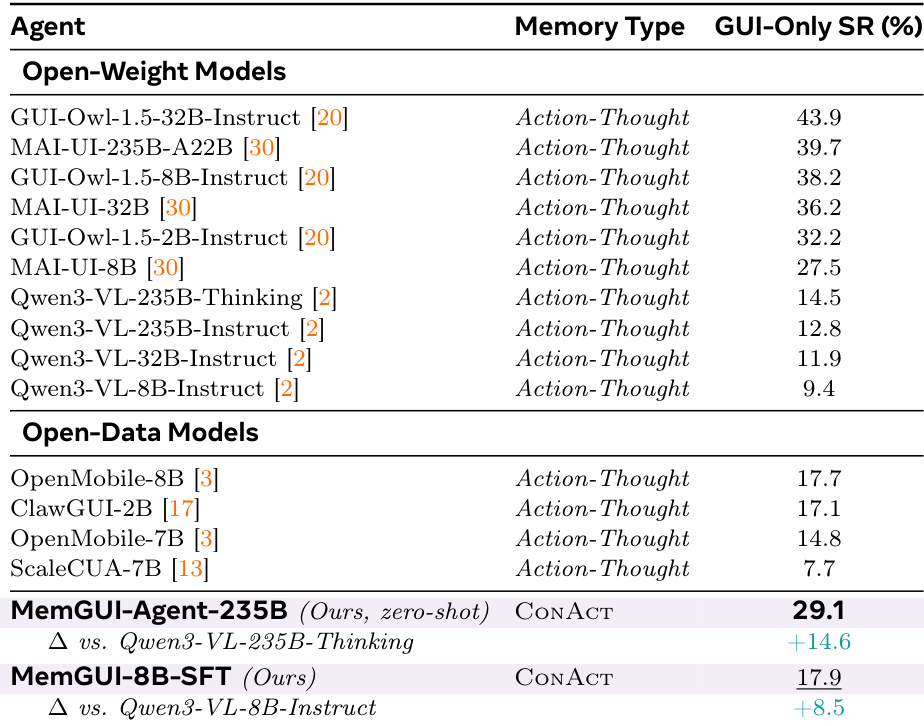
作者在MobileWorld GUI-Only基准上评估其MemGUI-Agent模型,将ConAct记忆类型与使用Action-Thought的基线进行比较。零样本MemGUI-Agent-235B在开源模型中取得了最高成功率,大幅优于其Qwen3-VL骨干。同样,微调的MemGUI-8B-SFT模型在开源8B模型中名列前茅,相较于其基础模型有显著提升,并表明学到的上下文管理技能能有效迁移至新环境。使用ConAct的MemGUI-Agent-235B在开源模型中取得了最高成功率,大幅超越其Qwen3-VL骨干。MemGUI-8B-SFT在开源8B模型中位居最佳之列,相较于基础模型提升显著。在不同模型规模上,ConAct记忆类型相较Action-Thought基线持续提升性能。
作者在长程移动GUI基准上评估其提出的MemGUI-Agent,该agent使用上下文即动作范式,与现有agentic框架和端到端模型相比。结果显示,其agent的零样本版本取得了最优性能,超越了基于闭源骨干的强agentic框架。此外,用其数据集微调较小模型带来了显著提升,尤其在更困难的任务上,证明了上下文管理技能的有效迁移。零样本MemGUI-Agent在所有任务难度级别上均优于现有agentic框架和端到端模型。微调一个8B模型能显著提升其性能,在中等和困难任务上相比基础模型提升最大。所提出的上下文管理方法在不同任务复杂度下持续提升了信息保持率。
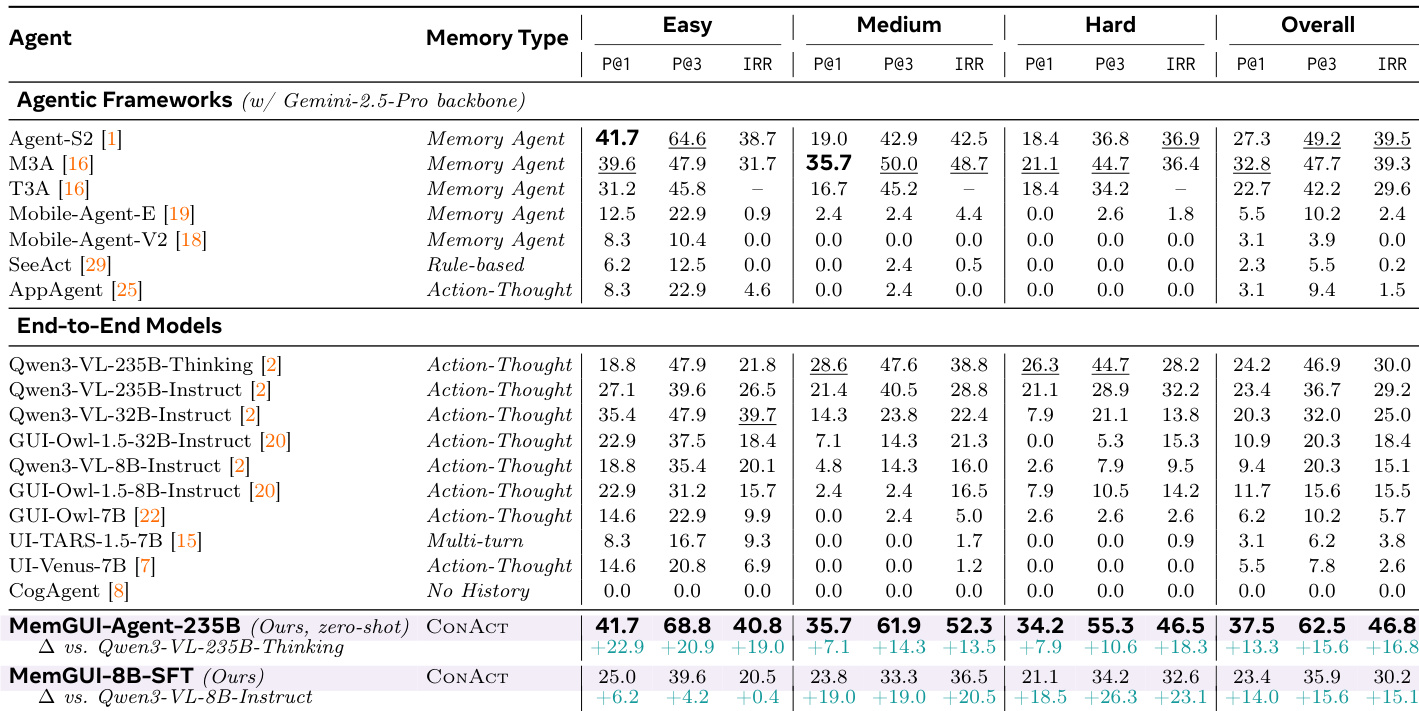
作者进行消融研究以评估三个上下文管理组件的单独贡献:UI记忆动作、历史折叠和自描述步骤输出。结果表明,虽然每个组件均较基线独立改善,但单独使用任一组件都不足以达到最佳性能。结合所有三种机制能获得最高的成功率和记忆保持率,证明折叠、记忆保存和基于屏幕的自描述是互补的。UI记忆动作对记忆相关指标的提升最大。历史折叠提升了初始成功率,但若无记忆动作则难以在多轮尝试中保持性能。完整模型在成功率和记忆保持率指标上均显著优于所有单组件变体。
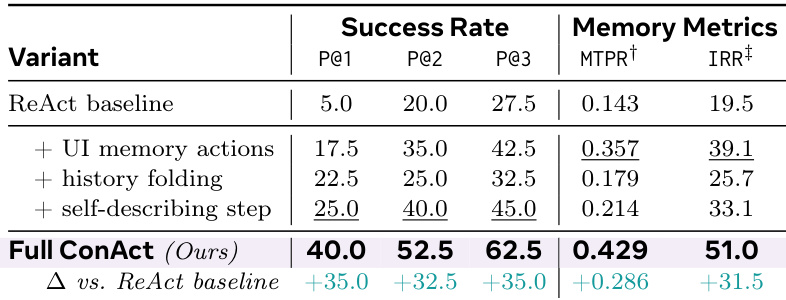
作者通过分析评估轨迹中的步骤分布,将所有步骤的统计信息与合理步骤子集进行比较。结果显示,合理步骤子集的均值和中位数低于全量集,表明过滤过程有效减少了平均轨迹长度。合理步骤子集相较于全量步骤集具有更低的均值和中位数。过滤合理步骤得到了更紧凑的轨迹长度分布。
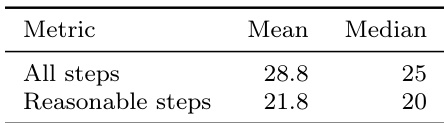
作者进行步骤级离线评估,以隔离动作执行、记忆管理、上下文折叠和格式化等子技能。结果显示,微调的8B模型相较于基础模型显著提升了记忆触发和深度折叠能力,同时达到接近完美的格式合规性。微调的8B agent取得了最高的记忆触发得分,甚至超越了更大的零样本模型。在数据集上进行监督微调后,深度折叠比率和跨度准确率显著提高。模型维持了极高的格式合规性,确认在所有评估步骤上都能可靠生成结构化输出。
作者在移动GUI基准上使用上下文即动作记忆范式对MemGUI-Agent进行了评估,表明ConAct记忆类型始终优于Action-Thought基线,零样本和微调版本在开源模型中取得了领先结果。消融研究证实,UI记忆动作、历史折叠和自描述步骤输出是互补的,其组合带来了最高的成功率和记忆保持率。微调8B模型显著提升了记忆触发、深度折叠和格式合规性,甚至超越了更大的零样本配置;同时,将轨迹过滤为合理步骤可降低平均长度。上下文管理技能能有效迁移至新环境,在更困难的长程任务上尤为有益。