Command Palette
Search for a command to run...
超越静态排行榜:用于评估 LLM Agents 的预测效度
超越静态排行榜:用于评估 LLM Agents 的预测效度
摘要
Agent基准正在快速发展,但没有任何单一基准能够涵盖部署所暴露出的超过四至五个维度。本文汇总了迄今为止针对某一基于MCP的工业agent基准所开展的最大规模协同深度研究:十四项并行实施研究,涵盖新资产类别(包括多模态视觉扩展)、替代编排方式、检索策略、推理模式、基础设施优化以及评估方法探测。将上述研究与七项先前的agent基准进行整合,我们认为,基于总分排名的排行榜系统性地未能充分界定已部署agent的评估。由总分得出的排名无法迁移至分布外场景;近期从公开赛制转为隐藏赛制的竞赛回顾为此类排名不稳定性提供了直接的实证证据。我们提出依据预测效度(即样本内排名与样本外排名之间的相关性)而非样本内均值对配置进行排序,并报告了一套十二层测量体系,该体系揭示了HELM及其agent时代后继者所未能涵盖的与部署相关的维度。该立场通过三个具有明确阈值的可证伪分布外标准得以操作化;现有证据部分支持该观点,但尚不足以充分证实。本文最后提出了一项预注册的试点设计方案,并从领域层面展望了下一代智能体基准应报告的内容。
一句话总结
本文未依赖静态的聚合评分,而是通过预测效度(即样本内与样本外排名的相关性)来评估 LLM agent 的性能,并通过一套十二层测量装置以及带有明确阈值的三个可证伪分布外(OOD)标准,将这一方法落地,以捕捉与部署相关的关键性能指标。
核心贡献
- 本文汇总了十四项基于 MCP 的工业 agent 基准测试的并行实施研究,以系统评估多种资产类别下不同的架构配置、检索策略与推理模式。
- 提出一种预测效度排名框架,以衡量样本内与样本外性能相关性的标准取代传统的聚合评分排行榜,从而解决分布偏移下的排名不稳定问题。
- 引入一套十二层测量装置,分离出以往基准测试中相互混淆的部署相关评估维度,并辅以跨基准排名相关性分析及公开到隐蔽竞赛的回顾验证。
引言
随着大型语言模型 agent 逐步转向工业资产运营等高风险部署环境,可靠的评估体系对保障运行安全与资源效率至关重要。现有基准测试难以适应这一转变,因其依赖的聚合评分将多轮产物复用、检索延迟与工具调用规范性等正交的部署维度相互混淆。此类单一指标排行榜表现出严重的排名不稳定性,无法预测系统在分布外任务上的表现,且过度依赖 LLM-as-judge 评分会在缺乏独立验证的情况下引入主观偏差与测量漂移。作者针对上述局限,提出将预测效度作为新的排名标准,优先考量样本内与样本外性能的相关性,而非单纯的样本内均值。通过整合七项成熟基准与十四项并行实施研究,作者构建了一套十二层测量装置以凸显部署关键维度,并制定三项可证伪标准,以严格检验分布偏移下的排名稳定性。
数据集

-
数据集构成与来源: 作者并未发布单一的训练语料库。取而代之的是,其整合了七项成熟基准与十四项并行实施研究,构建出综合评估框架。主要数据来源包括公开发布的 AssetOpsBench 数据集、NASA PCOE 锂离子电池循环数据,以及 ARE、Gaia2、MCP-Bench、TaskBench、MCP-Universe、SmartGridBench 和 PHMForge 等开源评估套件。所有材料均基于合成或公开可用的工业数据,不涉及人类受试者或敏感部署痕迹。
-
子集详情: 整合后的数据被划分为十二个正交测量层级。第一至第七层级整合了既往基准的指标,涵盖基础通过率、工具调用规范性、规划质量、能力维度、成本效率、故障模式与可复现性。第八至第十二层级源自面向部署的实施研究,涉及基础设施开销、多轮对话动态、推理适应性、知识增强以及独立于评判者的证据锚定。各层级均明确映射至特定源基准,例如利用 MCP-Bench 进行工具验证,以及使用 TaskBench 进行任务分解评分。
-
模型中的应用: 作者仅将该综合数据用于模型评估与排行榜构建,而非模型训练。通过聚合十二层级的指标来测量预测效度,并揭示当前评分实践与底层测量空间之间的差距。该框架旨在通过追踪成本-质量 Pareto 前沿位置、多轮运行方差以及评判者-人类一致率,防止对排行榜产生系统性过度信任。
-
处理与框架构建: 作者跳过了传统的裁剪与元数据构建流程。取而代之的是,通过明确指标边界(如无效通过率下限与依赖顺序正确性检查),将多样化的评估输出标准化为统一的层级化装置。在追踪延迟分解、步骤计数与上下文膨胀权衡等运行细节的同时,保留参考对抗扰动套件作为社区共享资产。十二个维度的正交性被视为一项工作假设,将在后续研究的实证测试中加以验证。
方法
作者提出了 AssetOpsBench,这是一种综合评估框架,旨在评估 LLM agent 在工业运营中的预测效度。该框架未依赖单次测试基准,而是将基础 agent 沿六个独立维度进行扩展,以捕捉现实部署的多维特性。如下方框架图所示:
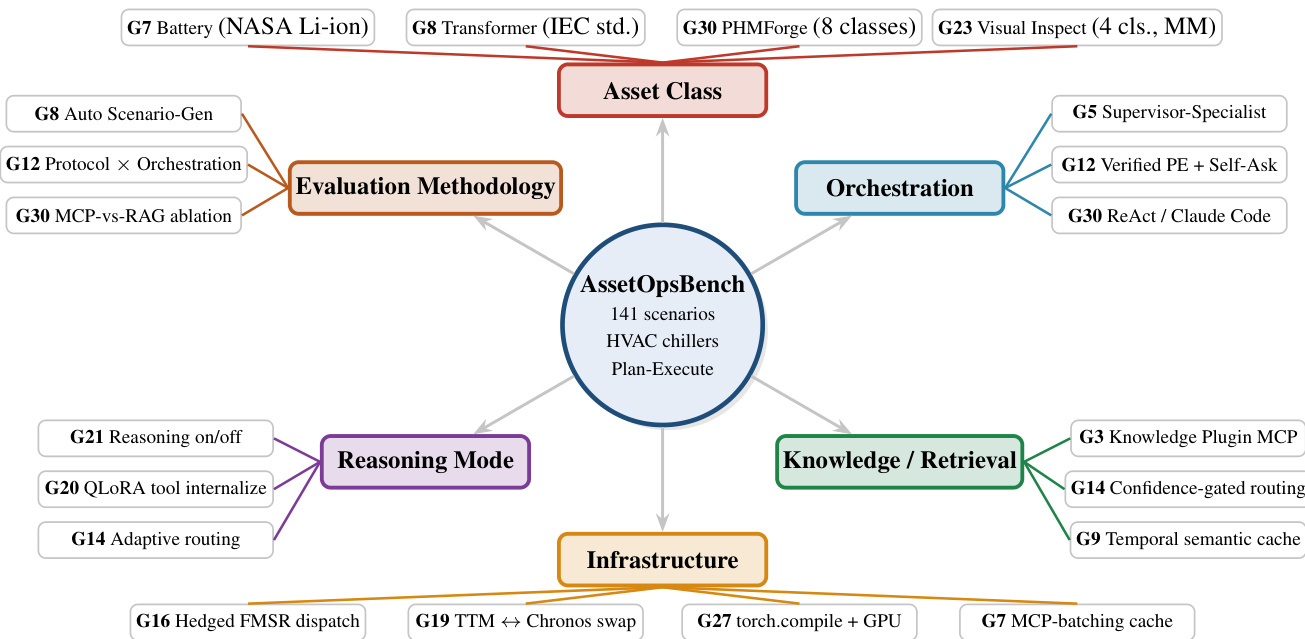
核心组件代表基础基准,包含 141 个聚焦于 HVAC 冷水机组的场景。框架由此延伸出六个操作化维度。资产类别(Asset Class) 维度测试跨不同设备类型(如电池、变压器与视觉检查任务)的泛化能力。评估方法(Evaluation Methodology) 探索不同的测试协议,涵盖自动化场景生成以及协议与编排机制的对比。编排(Orchestration) 维度考察 agent 架构,例如主管-专家协同设置或经验证的计划-执行循环。知识与检索(Knowledge and Retrieval) 研究知识插件、置信度门控路由与时序语义缓存等策略。推理模式(Reasoning Mode) 评估推理能力的影响,包括 QLoRA 内部化与自适应路由。最后,基础设施(Infrastructure) 解决系统级因素,如对冲调度、模型切换与持久化服务器模式,以降低延迟。
为在该框架内评估 agent,作者提出了一套严谨的方法论,基于分布外(OOD)偏移的三种操作化定义。第一项标准保留场景(Held-Out Scenarios) 采用分层随机划分,用于检验样本性能是否能预测整体总体的表现。第二项标准跨子集迁移(Cross-Subset Transfer) 通过将 agent 在 k−1 个子集上排名并在保留子集上进行测试来评估中等程度的偏移,从而构建跨资产类别的排名稳定性矩阵。第三项标准对抗扰动(Adversarial Perturbation) 施加最强烈的偏移,通过生成语义等价的改写文本、重命名标识符、偏移时间窗口以及注入干扰项来测试系统的鲁棒性。
评估方法的核心是预测效度得分(PV),这是一种复合指标,旨在根据 agent 的泛化可靠性而非单纯的样本内性能对其进行排名。该得分计算公式如下:
PV(c)=αYˉc−βσYc,OOD−γIQR(Yc)
在此公式中,Yˉc 代表样本内平均性能。项 σYc,OOD 捕捉跨 OOD 标准的排名位置标准差,对在不同 OOD 标准下性能波动显著的 agent 进行惩罚。项 IQR(Yc) 代表各场景得分的四分位距,对高方差进行惩罚。权重 α,β,γ 经过拟合,旨在最大化 PV 排名与基于 OOD 标准得出的排名之间的 Spearman 相关性。
作者还通过提议的排行榜设计,规定了结构化报告这些结果的方法。该设计强制要求声明配置列,以便将性能归因于特定的架构选择(如推理模式或检索策略)。此外,建议采用分层展示方式,以 PV 排名总表为起点,随后辅以成本-Pareto 图与下钻面板,以揭示部署相关维度。这确保了排行榜不会因传输或编排方法的差异而产生混淆,从而更准确地反映 agent 在生产环境中的实际能力。
实验
该评估设置综合了十四项独立实施研究的结果,这些研究采用受控消融实验与跨模型对比,以检验排名稳定性、推理模式、知识增强策略与评估方法。定性结果表明,扩展推理能力可提升输出清晰度,但会引入延迟且未能均匀提高任务正确率;而知识检索方法则展现出明显的精度-速度权衡,需要部署感知的报告机制。额外实验表明,LLM-as-judge 评分需借助外部锚点以确保可靠性,且系统性能主要受限于底层硬件规格与编排机制瓶颈,而非模型原始能力。这些趋同的发现共同验证了构建多维评估框架的必要性,该框架需能够捕捉架构权衡、评判独立性以及部署特定约束。
作者展示了十四项基于 MCP 的工业 agent 实施研究的结果,并按其针对的具体扩展维度进行分组。结果揭示了趋同的架构敏感性,表明性能提升幅度显著取决于干预目标(知识检索、编排或基础设施)。这些研究共同指出,当前基线模型常在协议开销与缓存机制上存在效率瓶颈,评估指标必须将这些底层结构因素纳入考量。agent 驱动的知识检索方法在准确率上显著优于标准的检索增强生成,尽管需要更多的计算资源。优化编排与基础设施组件(例如通过改进缓存或调度策略)可大幅降低延迟与执行时间。启用扩展推理能力能够提升输出清晰度并减少幻觉,但会伴随处理时间增加的成本。
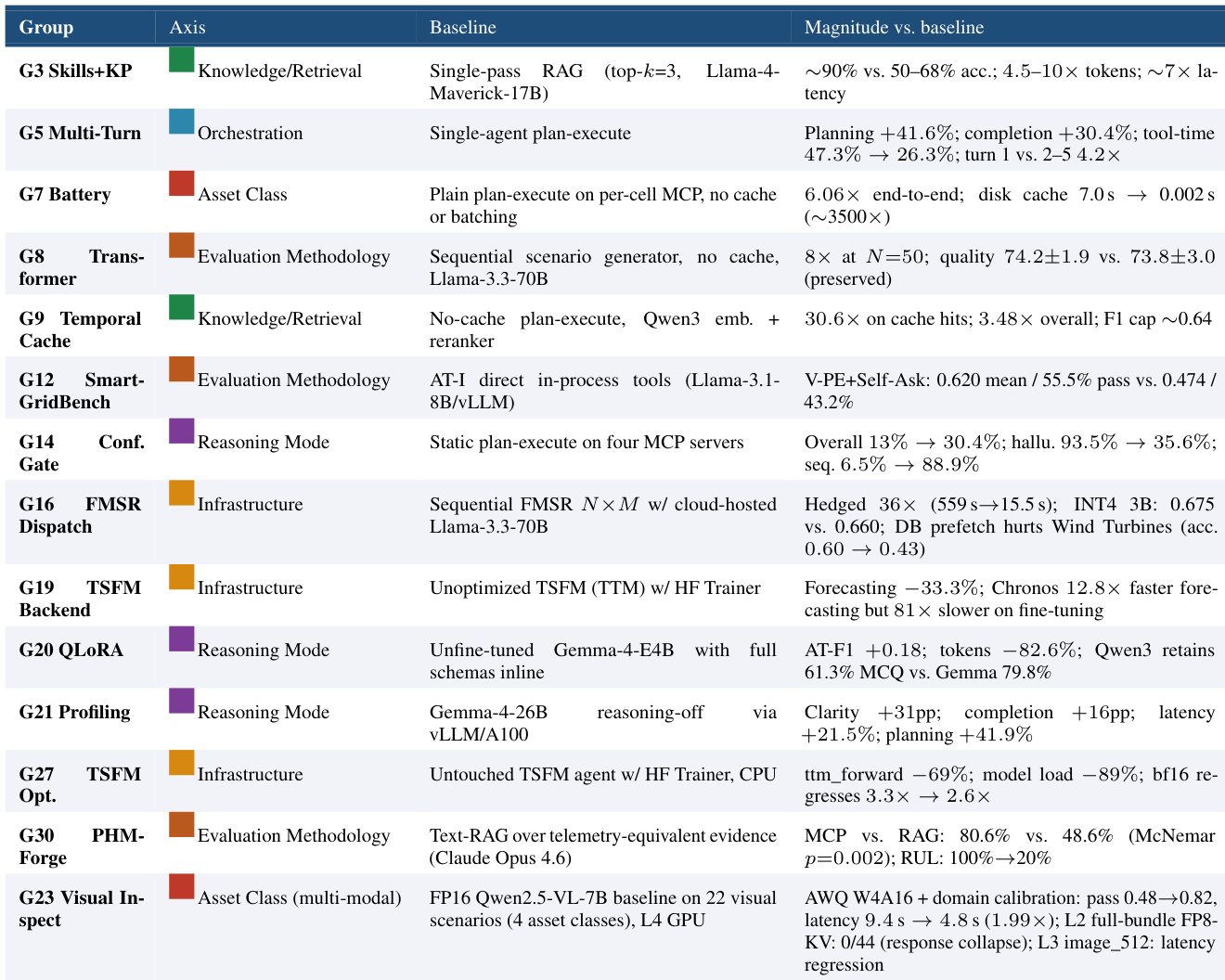
基于十四项基于 MCP 的工业 agent 实施研究,实验验证了不同架构扩展如何影响系统性能、效率与输出质量。研究结果表明,性能增益高度依赖于目标干预措施,知识检索方法在付出更高计算成本的前提下实现了更优的准确率。与此同时,优化编排与基础设施组件可大幅降低延迟,而扩展推理能力在增加处理时间的同时提升了输出清晰度并最小化幻觉。综合来看,这些结果凸显了基线模型在协议开销与缓存方面持续存在的效率问题,进一步强调了评估框架必须将底层结构因素纳入考量的必要性。