Command Palette
Search for a command to run...
BrainG3N:一种用于可控3D脑部MRI生成的双用途分词器
BrainG3N:一种用于可控3D脑部MRI生成的双用途分词器
Max Van Puyvelde Ibrahim Gulluk Wim Van Criekinge Olivier Gevaert
摘要
三维(3D)脑部磁共振成像(MRI)在临床神经病学与神经肿瘤学中占据核心地位,生成式模型在此可扩充代表性不足的队列,模拟疾病发展轨迹,并支持隐私保护的数据共享。潜在扩散(Latent diffusion)已成为影像数据建模的首选方案,但其对分词器提出了两项相互竞争的要求:编码器嵌入必须保留下游任务所依赖的临床信息,而解码器必须重建解剖结构高度保真的体积数据。现有的重建驱动型分词器在实现第二项要求的同时,牺牲了第一项要求。为解决这一问题,我们引入了一种基于全容积掩码自编码器(MAE)的分词器,用于3D脑部MRI的潜在扩散,并解耦了编码器与解码器:冻结的3D MAE编码器生成富含临床信息的嵌入表示,而专用的CNN解码器则通过对这些嵌入进行线性投影来重建体素。我们在涵盖四种模态、十种疾病类别以及200余个采集站点的18个公共队列的35,309个体积数据上对编码器进行预训练,并在两种应用场景下验证了其双重效用。首先,在包含23个任务的线性探测基准测试中,该编码器在23项任务中的21项上表现优于或持平于当前最先进(SOTA)模型(即BrainIAC、BrainSegFounder和MedicalNet)。其次,基于这些富含临床信息的嵌入表示训练的条件扩散Transformer(DiT)支持跨六个变量的条件生成以及患者特定的纵向预测。综上所述,这些结果确立了一个统一的3D脑部MRI嵌入空间,该空间能够同时满足下游临床任务与可控生成的需求。
一句话总结
BrainG3N 是一种用于可控三维脑 MRI 生成的双用途 tokenizer。它将一个能产生有临床意义嵌入的冻结三维掩码自编码器(MAE)编码器,与一个专用 CNN 解码器解耦,从而重建解剖学上保真的体积。在来自 18 个公开队列、涵盖四种模态、十种疾病类别及超过 200 个采集站点的 35,309 个体积上对编码器进行预训练后,它在 23 项线性探针任务中的 21 项上超越或达到当前最优模型的水平。
核心贡献
- 一种用于三维脑 MRI 的全体积 MAE-CNN tokenizer,将冻结的三维 MAE 编码器与专用 CNN 解码器解耦,在从嵌入的线性投影重建体素的同时,产生有临床意义的嵌入。
- 在涵盖四种模态和十种疾病类别的 35,309 个体积上进行预训练后,该冻结 MAE 编码器在 23 项线性探针任务中的 21 项上超越或达到已发表的三维脑 MRI 基础模型,这些任务包括 IDH1 突变、APOE 基因型和认知评分。
- 在冻结嵌入上训练的条件流匹配扩散 Transformer 实现了可控的三维脑 MRI 生成。在无分类器引导下,真实数据线性探针能恢复所请求的条件,且纵向年龄进展以 0.72 的皮尔逊相关系数被捕捉。
引言
三维脑 MRI 支撑着神经病学和神经肿瘤学的临床决策,然而为数据增强、患者特定的数字孪生或隐私保护共享等任务直接生成全分辨率体积在计算上是不可行的。现有潜扩散模型使用仅基于重建训练的自动编码器压缩影像,这使潜空间偏向于体素级别的保真度,而丢弃了条件合成或下游分析所需的具有临床意义的语义信息。作者通过一种双用途 tokenizer 解决这一问题:一个在来自 18 个队列的 35,309 个脑 MRI 体积上预训练的冻结掩码自编码器(MAE)产生的嵌入,既能强烈预测临床表型,又作为条件扩散 Transformer 的特征空间。配合用于忠实体素重建的专用卷积解码器,该冻结编码器在 23 项线性探针基准的 21 项中匹配或超越了三个已发布的三维脑 MRI 基础模型,且扩散模型实现了跨六个临床变量的可控生成和患者特定的纵向预测,弥合了大规模三维医学影像中诊断内容与生成保真度之间的鸿沟。
数据集
作者通过聚合来自全球 18 个公开队列、超过 200 个采集站点的 17,399 名独立受试者的 35,309 个预处理脑 MRI 体积构建数据集。它涵盖四种模态(T1、T2、FLAIR、T1c)和 5 至 98 岁的年龄范围,其中 6,576 名受试者拥有纵向影像。
各组成部分的关键细节:
- 诊断子集及数量:健康对照(HC)15,274,轻度认知障碍(MCI)5,808,胶质母细胞瘤(GBM)4,028,帕金森病(PD)3,381,儿科混合 2,130,阿尔茨海默病(AD)1,458,自闭症谱系障碍(ASD)1,061,非 GBM 胶质瘤 396,精神分裂症(SCZ)328,注意缺陷多动障碍(ADHD)247。按设计,健康受试者占 43%,为探针和生成建模提供了大量空分布。
- 临床元数据:扫描年龄(90% 覆盖)、性别(90%)、诊断(96%)、CDR(34%,集中于 AD/MCI)、MMSE(41%,AD/MCI)、MoCA(18%)、APOE 基因型(41%)、肿瘤分级(肿瘤队列的 8%)、IDH1(7%)、MGMT(6%)和采集站点(78%)。
预处理和裁剪策略:
- 对所有体积应用统一流水线:N4 偏置场校正、HD-BET 颅骨剥离、仿射配准至 SRI24 模板(240×240×155 体素,1 mm 各向同性,LPS 方向)。在多模态设置中,T2、FLAIR 和 T1c 通过 T1 变换进行共配准,以防止跨模态对齐漂移。
- 插值产生的负体素被裁剪至零。此阶段不进行强度归一化。
- 模型输入时,体积被中心裁剪或填充至 160×192×160。训练数据加载器在运行中对每个体积进行 z 分数标准化。
本文如何使用数据:
- 整个语料库用作生成模型的训练材料和探针基准。大量的健康对照存在(43%)有助于将疾病信号与正常变异分离的探针任务,并确保生成模型学习到充分的空分布。数据集卡片未描述显式的训练/验证/测试划分;所有体积均用于自监督预训练和下游评估。
方法
作者引入了一种完全基于三维掩码自编码器(MAE)的 tokenizer,用于三维脑 MRI 潜扩散。核心设计将编码器和解码器解耦,以满足两个相互竞争的需求:在编码器嵌入中保留临床信息,并实现解剖学上保真的体积重建。这通过 tokenizer 的两阶段训练实现,随后训练条件扩散模型。
如下图所示:
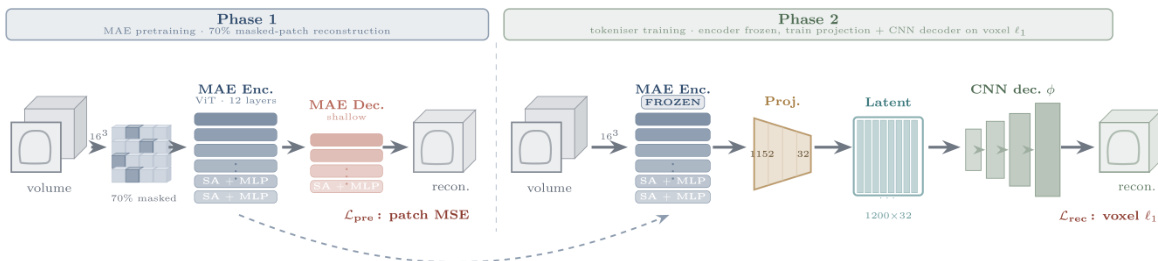
在第一阶段,作者在大量体积数据集上进行 MAE 预训练。架构采用具有 12 层的视觉 Transformer(ViT)作为 MAE 编码器,以及一个浅层解码器。输入体积被划分为 163 的块,其中 70% 的块被遮蔽。模型通过块级别的均方误差(MSE)损失 Lpre 训练来重建被遮蔽的块。
在第二阶段,tokenizer 训练在冻结 MAE 编码器的情况下进行。一个线性投影层将编码器嵌入映射到维度为 1200×32 的潜空间。然后,一个专门的卷积神经网络(CNN)解码器 ϕ 被训练从此潜表示重建体素。重建使用体素 ℓ1 损失 Lrec 进行优化。
为支持跨多个变量的条件生成和患者特定的纵向预测,作者在冻结编码器产生的具有临床信息的嵌入上训练了一个条件扩散 Transformer(DiT)。
参考框架图:
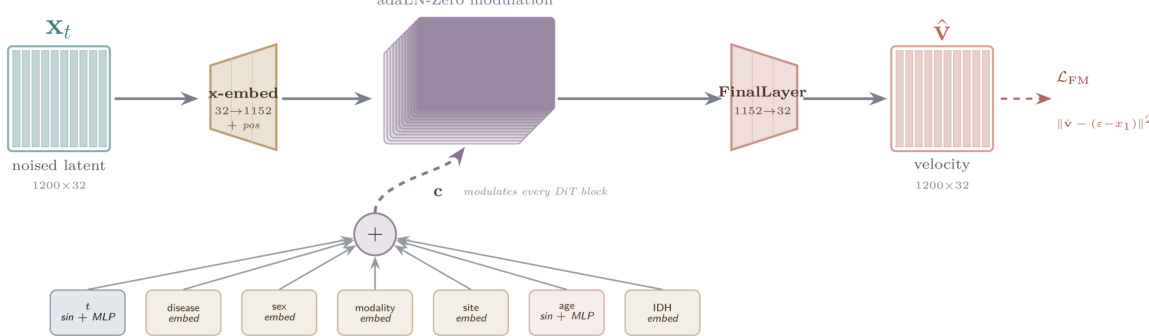
DiT 架构以大小为 1200×32 的加噪潜表示作为输入。该输入通过一个嵌入层将 32 维映射到 1152 维,并添加位置编码。DiT 的核心由受 adaLN-Zero 调制的块组成。条件信号 c 由多个变量组合而成:时间步 t(经 sin+MLP 处理)、疾病嵌入、性别嵌入、模态嵌入、站点嵌入、年龄(经 sin+MLP 处理)以及 IDH 嵌入。这些嵌入被求和形成条件向量,用于调制每个 DiT 块。最后,一个 FinalLayer 将 1152 维映射回 32 维以预测速度 v^。模型使用流匹配损失 LFM=∥v−(ϵ−x1)∥2 进行训练。
实验
评估首先在肿瘤队列上验证了低维投影能保留临床信息,并且冻结的 MAE-CNN tokenizer 在临床探针上超越了 CNN-VAE 基线,同时支持可扩展性。随后在大规模编码器上的冻结线性探针在大多数临床和人口统计学任务中优于已发表的大脑 MRI 基础模型。使用相同的嵌入,条件扩散模型展示了沿疾病、性别、年龄、模态和肿瘤突变轴的可控生成,具有良好的保真度且无记忆化,而纵向变体则预测了患者特定的解剖变化,这些变化定位于脑室和脑沟。
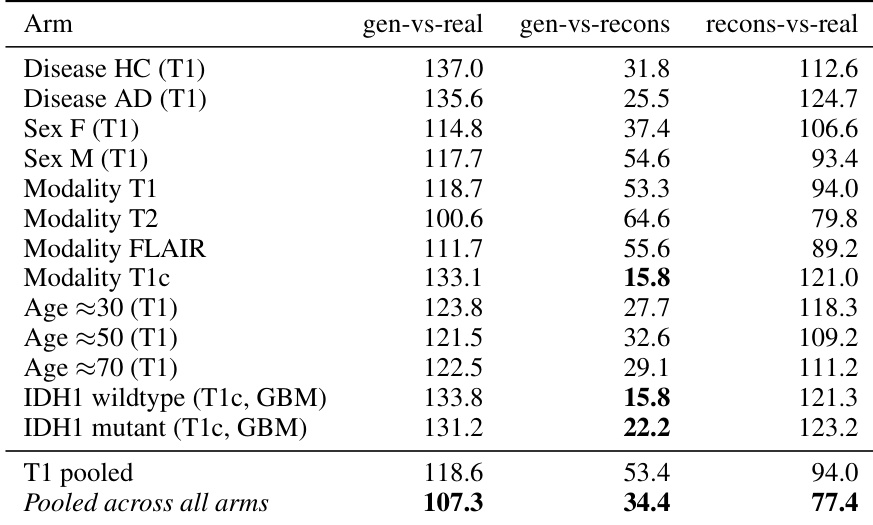
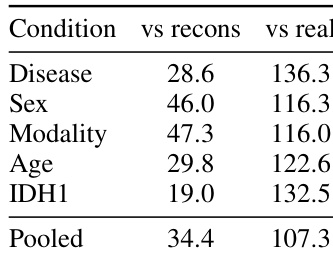
作者使用各种条件臂下的 3D-FID 评估生成保真度,将误差分解为生成器到真实、生成器到重建以及重建到真实的组成部分。结果表明,生成器紧密匹配 tokenizer 的潜分布,生成器到重建的池化 FID 显著低于 tokenizer 自身对真实体积的重建下限。这表明生成样本与真实体积之间的主要差距源于 tokenizer 对高频细节的压缩,而非生成器本身的限制。生成器与 tokenizer 的潜分布高度一致,其相对于重建的 FID 远低于 tokenizer 相对于真实体积的重建下限。在不同条件臂(包括疾病状态、性别、模态、年龄和突变状态)下,生成保真度保持一致。某些特定条件臂,如特定模态和突变状态,显示出特别低的生成器到重建 FID,表明与 tokenizer 潜空间高度对齐。
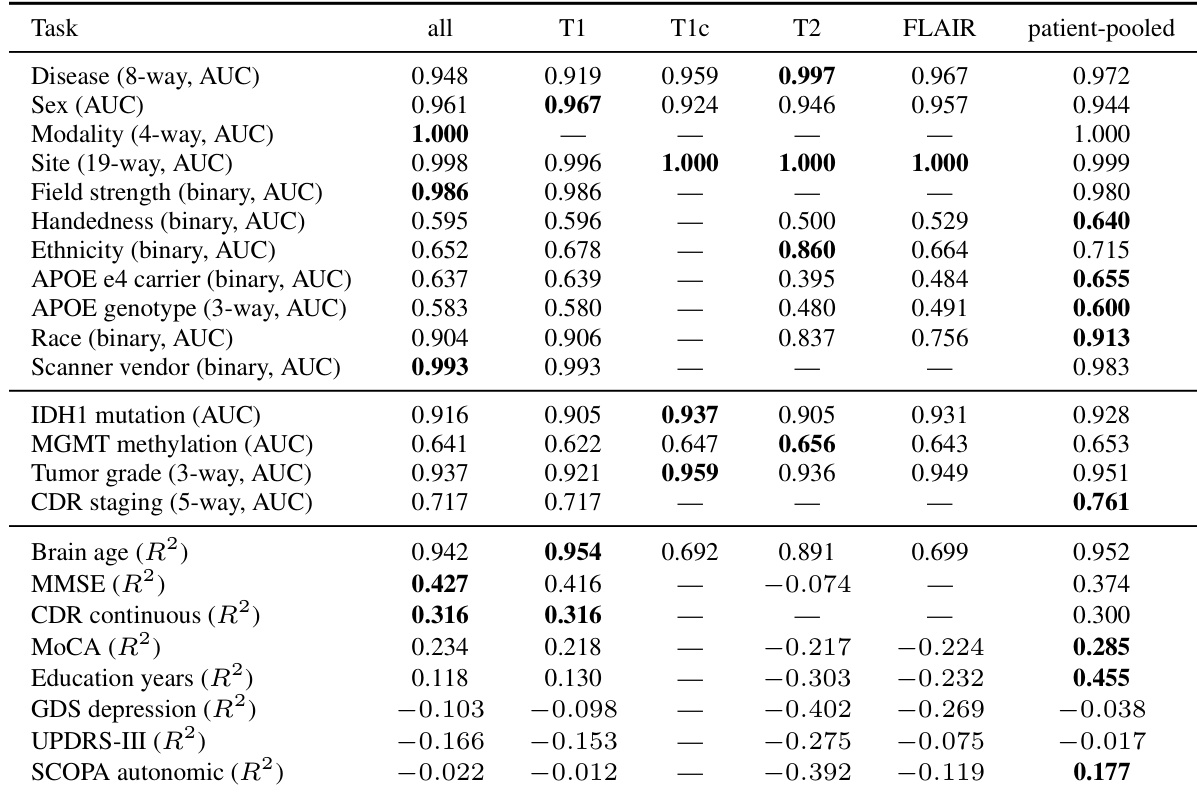
作者使用线性探针在大型脑 MRI 语料库的一系列分类和回归任务中评估其冻结编码器嵌入的临床内容。结果表明,编码器捕捉到了人口统计学、采集和主要疾病相关变量的强烈信号,但性能因 MRI 模态而异。分类任务通常实现了高预测精度,而回归任务的性能更参差,一些临床量表在所有模态中都难以预测。包含疾病诊断、性别和扫描仪厂商的分类任务获得了高预测性能,最佳 MRI 模态因任务而异。回归任务显示出混合结果,脑龄预测表现强劲,而其他临床量表在大多数模态中得分较低甚至接近零。在个体模态子集样本不足或预测力较弱的情况下,患者集合评估通常能获得最佳性能。
作者通过计算各种条件臂下的 FID 分数来评估其条件扩散 Transformer 的生成保真度。结果显示,生成样本与真实体积之间的差距主要由 tokenizer 对高频细节的压缩驱动,而非生成器质量问题,因为生成器与 tokenizer 重建的匹配程度比与原始真实体积更高。生成样本与 tokenizer 重建之间的池化 FID 分数显著低于与原始真实体积的分数,表明与潜空间高度对齐。生成保真度因条件而异,像 IDH1 和疾病等条件相对于重建的 FID 分数低于像性别和模态等条件。tokenizer 相对于真实体积的重建下限占据了生成样本与原始真实数据之间的大部分差异。
作者评估了条件生成对无分类器引导尺度的敏感性。结果表明,较低的引导尺度能很好地保持疾病、性别和年龄属性的恢复,而较高的尺度则会降低连续年龄预测的性能。在所有测试的引导尺度下,模型都难以导向罕见的 IDH1 突变类别。疾病和性别属性在所有测试的引导尺度下都能可靠恢复。引导尺度过大会导致连续年龄预测因过度外推而退化。无论引导尺度如何,IDH1 突变状态始终接近随机一致水平。

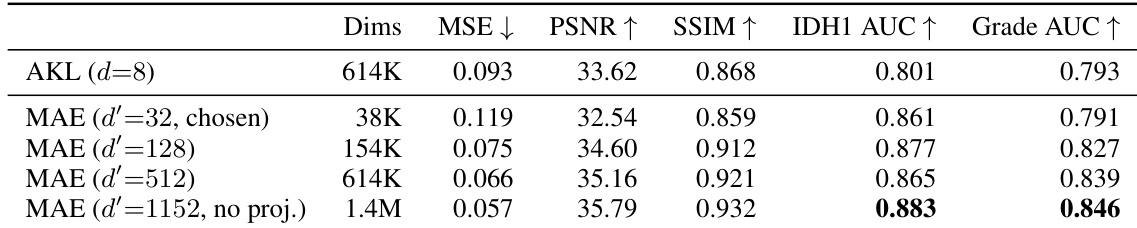
作者在肿瘤队列上比较了冻结的 MAE-CNN tokenizer 与 AutoencoderKL 基线,评估了不同瓶颈维度下的重建质量和临床探针性能。结果表明,即使使用显著更小的瓶颈维度,MAE tokenizer 在临床探针任务上也始终优于基线,这使得作者选择小型投影以平衡降维与临床内容保留。在相同维度下,MAE tokenizer 在 IDH1 和肿瘤分级上均取得了比 AutoencoderKL 基线更高的临床探针性能。带有小瓶颈的 MAE tokenizer 在 IDH1 分类上优于大得多的基线,并在肿瘤分级上与之持平。MAE tokenizer 的重建质量随投影维度增加而单调提升,但即使在最小瓶颈下,临床内容仍得到良好保持。
作者进行了涵盖生成保真度、表示质量、条件鲁棒性和 tokenizer 设计的综合评估。分解的 3D-FID 分数表明,生成器与 tokenizer 的潜空间高度一致,生成样本与真实体积之间的主要差距源于 tokenizer 对高频细节的压缩,而非生成器的局限。对冻结编码器嵌入的线性探针证实,在分类任务中能捕捉到疾病、人口统计学和采集属性的强烈临床信号,但回归性能更为多变。引导敏感性分析显示,性别和疾病属性在不同尺度下稳定恢复,而连续年龄预测在高尺度下退化,罕见 IDH1 突变仍接近随机水平;tokenizer 的对比确立了冻结 MAE 变体即使在远小得多的瓶颈维度下也比 AutoencoderKL 基线更好地保留了临床信息。