Command Palette
Search for a command to run...
PerceptionDLM:基于多模态扩散语言模型的并行区域感知
PerceptionDLM:基于多模态扩散语言模型的并行区域感知
摘要
多模态大语言模型(MLLMs)在视觉理解任务中取得了显著进展。然而,大多数现有的MLLMs依赖于自回归生成,这限制了其在需要为多个区域生成描述的感知任务中的效率。在本工作中,我们提出了PerceptionDLM,这是一种专为高效并行区域感知而优化的多模态扩散语言模型。该架构建立在PerceptionDLM-Base这一强大的基础基线之上,后者在开源扩散多模态大语言模型中达到了最先进的性能,我们的架构充分利用了扩散语言模型(DLMs)的并行解码特性。具体而言,我们引入了高效提示与结构化注意力掩码,以实现多个掩码区域的同步感知,使模型能够在序列和token级别并行生成区域描述。与现有顺序处理区域的方法相比,该设计显著提高了推理效率。为了系统评估扩散语言模型在视觉感知能力方面的并行特性,我们通过扩展DLC-Bench构建了新的并行详细局部描述基准测试(ParaDLC-Bench),该基准测试为每张图像包含多个区域掩码,从而能够联合评估描述质量与推理效率。实验表明,PerceptionDLM在区域描述任务中保持了具有竞争力的性能,同时在多区域感知任务中实现了显著的速度提升。我们的结果突显了多模态扩散语言模型在高效并行视觉感知方面的潜力。据我们所知,我们是首个利用扩散语言模型的优势实现并行区域描述与感知的研究。代码、模型与数据集已开源发布。
一句话总结
PerceptionDLM 是一种多模态扩散语言模型,采用高效提示与结构化注意力掩码,在序列级与 token 级同时生成区域描述,在保持新建构的 ParaDLC-Bench 基准测试上具有竞争力的准确率的同时,显著加速了多区域视觉描述生成。
核心贡献
- 本文提出 PerceptionDLM,一种多模态扩散语言模型,采用高效提示与结构化注意力掩码同时为多个图像区域生成描述。该架构支持序列级与 token 级的并行解码,直接解决了自回归区域感知中推理延迟随查询密度线性增长的问题。
- 为评估并行视觉感知能力,本研究构建了 ParaDLC-Bench,作为 DLC-Bench 的扩展版,将局部描述数据集扩展至支持单张图像包含多个并发区域掩码。该基准测试实现了对顺序解码与并行解码范式下描述质量与推理效率的联合直接评估。
- 实验表明,PerceptionDLM 在保持具有竞争力的区域描述准确率的同时,在密集感知场景下相比自回归基线模型实现了高达 3.5 倍的吞吐量加速。该框架还在 16 项多模态基准测试中的 15 项上超越 LLaDA-V,确立了强大的开源扩散基线。
引言
多模态大语言模型已显著推动视觉理解的发展,然而实际应用日益要求细粒度定位能力,即需要同时描述多个图像区域。现有系统主要依赖自回归解码,按顺序处理区域,导致推理延迟随查询密度增加而线性增长。为突破此效率瓶颈,研究团队提出 PerceptionDLM,一种专为并行区域感知优化的多模态扩散语言模型。通过结合强大的离散扩散基线与高效提示及结构化注意力掩码,该框架在单次去噪过程中联合生成多个区域描述,在不牺牲准确率的前提下大幅提升吞吐量。研究团队同时构建 ParaDLC-Bench 以系统化评估并行视觉感知,并开源代码与模型以加速开放研究。
数据集

-
数据集构成与来源: 研究团队构建 ParaCaption-5.7M,这是一个专为多模态扩散语言模型并行区域描述设计的高质量训练语料库。该数据集整合了来自 SA-1B 分割数据集与 COCONut 数据集的区域级掩码与描述配对数据。
-
子集详情与过滤规则:
- COCONut 子集:提供 334,000 张图像,包含 340 万个掩码。研究团队利用其内置的掩码与类别标注,使用 GAR-8B 生成初始描述,并通过 Qwen3-8B 验证与真实类别的语义对齐情况。
- SA-1B 子集:提供 83,000 张图像,包含 230 万个掩码。处理流程首先移除完全遮挡或仅包含部分结构的掩码。GAR-8B 生成初始描述后,大语言模型提取核心类别。SAM3 随后重新预测掩码,研究团队丢弃任何重预测掩码与原始真实掩码交集并集比(IoU)较低样本。
-
模型应用与训练策略: 最终的 570 万掩码-描述配对数据合并为单一训练语料库,用于微调扩散语言模型,以生成跨多个掩码区域的并行描述。研究团队将该聚合数据集视为统一训练资源,未明确划分训练集与验证集比例,而是专注于提升区域间特征独立性,并在并发生成过程中减少跨目标幻觉。
-
处理与元数据构建: 两个子集均经历统一的后期处理阶段,实施严格的长度限制并应用防重复过滤以消除幻觉内容。研究团队部署自动化数据构建管道,将分割掩码与大语言模型生成的描述文本配对,确保多目标场景下的高语义保真度。
方法
研究团队提出一套围绕 PerceptionDLM 构建的框架,该模型旨在处理并行区域感知与逐区域生成。参考框架示意图:

架构始于视觉编码器,通过动态分块与 patch embedding 处理输入图像。这些视觉 token 随后经过 MLP Projector 生成像素未打乱的表示。为处理特定感兴趣区域,模型通过 RoI-Align 模块采用 RoI-aligned feature replay 提取区域对齐特征 token。此外,区域提示通过 Visual Prompt Embedding 实现,将特定区域映射至对应嵌入向量。模型还利用 Structured Attention Mask 管理图像 token、RoI 特征与生成描述之间的交互,确保解码过程中注意力得到适当限制。
在生成阶段,研究团队采用两种不同策略。在并行区域感知中,模型接收多个掩码区域并执行并行解码,同时为每个掩码生成描述。在逐区域生成中,模型采用自回归方法,按顺序描述区域,从而实现详细且针对特定区域的描述。该顺序过程由基于 AR 的区域特定模型驱动,随着更多区域被掩码并描述,逐步优化描述内容。
训练与评估过程涉及为掩码区域生成描述,并通过正向与负向问题评估其准确性。大语言模型裁判对生成的描述进行评分,根据描述是否正确提及、错误定位或幻觉化掩码区域属性进行打分。该结构化评估确保模型学习为每个区域生成准确且符合上下文的描述。
实验
这些提升表明,所提出的训练管道与多模态架构显著增强了基于扩散模型在通用理解与感知方面的能力。
与先进自回归 VLM 具有竞争力。PerceptionDLM-Base 在参数量相近的情况下,与近期自回归 VLM 表现相当。在 16 项基准测试中,PerceptionDLM-Base 在大多数任务上取得更优或相当的成绩。其在细粒度视觉感知方面表现尤为突出,系统性超越 Qwen2.5-VL-7B [3] 与 InternVL3-8B [62]。这表明 PerceptionDLM-Base 在区域敏感与细节导向的视觉理解方面具备独特优势。尽管在复杂且重度依赖推理的场景(如 MMMU [55] 与 MathVista [27])中仍存在性能差距,但研究指出任意顺序的并行解码从根本上限制了扩散语言模型的推理潜力 [32]。因此,在进行数学推理评估时,本研究为 PerceptionDLM-Base 采用自回归顺序解码以更好地保留推理轨迹。受 DeepSeek-R1 [16] 等近期进展启发,该瓶颈凸显了明确的研究方向:利用强化学习(RL)进一步释放基于扩散的 VLM 的推理潜力。
- 4.3 基于 PerceptionDLM 的 Captionina 基准测试评估
为进一步评估细粒度多模态理解能力,本研究在区域描述基准测试上评估 PerceptionDLM,包括多区域 ParaDLC-Bench 与单区域 DLC-Bench [23]。
ParaDLC-Bench 与 DLC-Bench 对比表格。符号 1∗ 表示在推理这些基线扩散 VLM 时,本研究将去噪步数设置为等于生成长度,旨在实现其最佳生成质量。

在扩散 VLM 中具备领先的区域描述能力。如表格所示,PerceptionDLM 相比现有基于扩散的 VLM 展现领先优势。在 ParaDLC-Bench 上,其平均准确率达到 62.4%,几乎是 SDAR-VL [9](31.3%)与 LLaDA-V [50](35.2%)的两倍。这一显著优势在 DLC-Bench [23] 上同样一致(51.9% 对比基线的 24.6%)。
具备竞争力的性能与前所未有的效率。为分析效率,本研究采用前向传递每 token 数(TPF)指标 [35],量化每次前向传递生成的平均 token 数量。与基于 AR 的区域特定模型(如 DAM 与 GAR)相比,PerceptionDLM 在展现高度竞争力准确率的同时释放了巨大的速度优势。尽管其在 ParaDLC-Bench 上的平均准确率略低于 AR 模型,但 PerceptionDLM 将基准测试的总推理时间大幅缩减至 276 秒,而 GAR 为 479 秒,PixelRefer [53] 为 718 秒。
该效率由并行解码范式驱动。AR 模型与标准 DVLM 基线被限制在 TPF 为 1,而 PerceptionDLM 达到 TPF 2.9,同时生成多个区域描述。需注意,在 DLC-Bench 中,样本仅包含单个掩码,并行处理优势无法完全发挥。尽管如此,PerceptionDLM 在两种设置下仍为基于扩散的 VLM 设立了新基准。
为系统分析 PerceptionDLM 的计算优势,本研究进行速度与效率分析。如图(b)所示,PerceptionDLM 在保持每图像稳定延迟(约 2.9 秒)的同时实现接近线性的 TPS 增长。相比之下,GAR-8B 的 TPS 瓶颈维持在近乎恒定水平,且其延迟随区域数量增加而近似线性恶化。如图(c)所示,在恒定重负载(每张图像 4 个掩码)下,增加并行度(每次处理掩码数)为 PerceptionDLM 带来强扩展性:吞吐量提升 3.44 倍,单图像延迟从 10.04 秒降至 2.92 秒。
研究团队采用四阶段训练管道,始于在较小数据集上训练 Projector。后续阶段扩展训练范围以包含 LLM 主干,并使用规模更大且更多样化的数据集。学习率在后续阶段逐步降低,以促进整个模型的稳定微调。训练过程从仅 Projector 对齐过渡到视觉塔与语言模型的联合训练。数据集规模与多样性在各阶段显著增加,后期阶段超过两千万样本。所有训练阶段均一致使用相同的视觉塔与 LLM 主干。

研究团队对比 PerceptionDLM-Base 模型的两种变体,以确定训练 Vision Transformer 与保持其冻结的有效性。数据表明,冻结视觉编码器通常在大多数多模态基准测试上带来更佳性能。尽管训练变体在 MMMU 等复杂推理任务中略占优势,但冻结基线在通用视觉理解与 VQA 任务中表现更优。冻结 Vision Transformer 在多数评估基准上取得更好成绩。冻结基线模型在需要通用视觉感知与 VQA 的任务中优于训练变体。训练视觉编码器主要在 MMMU 等复杂推理场景中提供边际收益。
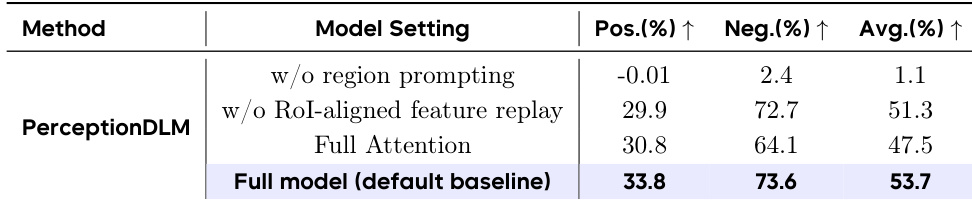
研究团队对 PerceptionDLM 模型进行消融实验,以评估区域提示与 RoI-aligned feature replay 等特定组件的贡献。结果表明,与消融变体相比,完整模型配置在正向、负向与平均指标上均取得最高性能。完整模型设置产生最佳整体表现,优于移除组件的配置。移除区域提示导致性能急剧下降,表明其不可或缺。缺失 RoI-aligned feature replay 导致得分低于完整模型,验证了其贡献。
研究团队评估 PerceptionDLM 模型在不同序列长度下的性能,以评估区域感知能力。结果表明,与长度为 64 相比,长度为 32 在所有测量类别中均带来更优准确率。这表明模型在受限于较短生成序列时实现更好的区域理解。PerceptionDLM 在序列长度为 32 时表现优于长度为 64。模型在较短长度下于正向、负向与平均指标上均呈现一致提升。

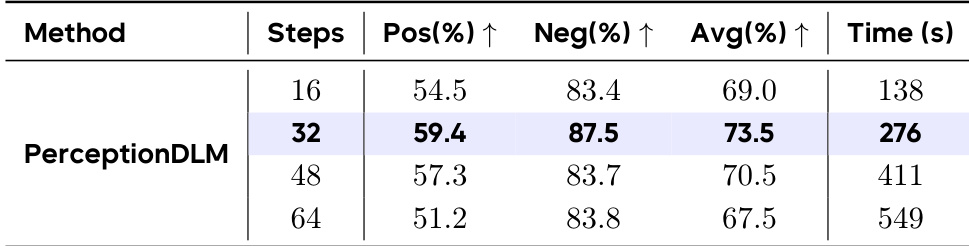
研究团队分析不同生成步数对 PerceptionDLM 模型性能与效率的影响。结果表明,高亮显示的配置(对应默认推理设置)实现最高平均准确率。偏离该设置(增加或减少步数)会导致性能得分下降。模型在默认推理设置下达到峰值性能,该设置在表格中高亮显示。超出最优点增加步数会导致收益递减与更长推理时间。减少步数会加快推理,但准确率显著低于默认设置。
评估采用渐进式四阶段训练管道,从 Projector 对齐过渡到在日益多样化的数据集上进行联合微调,以验证模型的架构与优化策略。对比实验表明,冻结视觉编码器通常提升标准视觉理解任务的性能,而训练它仅在复杂推理中带来边际增益。进一步的消融与敏感性分析确认,区域提示与 RoI-aligned feature replay 对稳健的多模态能力至关重要,且最短生成序列与校准后的推理步数始终能实现最佳准确率。