Command Palette
Search for a command to run...
玩耍式智能体机器人学习
玩耍式智能体机器人学习
摘要
当前的agent机器人系统能够编写可执行的Code-as-Policy程序,观察反馈,并在多次尝试中修正行为,但它们仍然主要受任务驱动:可复用技能仅在明确指令下达后才会被获取。我们研究Playful Agentic Robot Learning,其中具身coding agent将自主游戏作为下游任务到来之前的持续技能学习阶段。我们提出RATs(Robotics Agent Teams),专为游戏阶段的技能获取而设计。在游戏过程中,RATs提出新颖且可学习的探索性任务,规划并执行robot-code策略,验证中间进度,诊断失败原因,利用密集的步骤级反馈进行重试,并将成功的执行过程提炼为持久的代码技能库。在测试阶段,agent从该冻结的技能库中复用相关技能,以协助解决新任务。LIBERO-PRO和MolmoSpaces上的实验表明,游戏习得的技能在保留的下游任务上优于无游戏和随机游戏基线,在LIBERO-PRO和MolmoSpaces上分别较CaP-Agent0提升了20.6和17.0个百分点。此外,只需将这些习得的技能检索至上下文中,即可将其无缝集成至其他推理阶段的Code-as-Policy agents中,在不微调底层模型的情况下,分别使RoboSuite和真实世界迁移性能提升8.9和8.8分。
一句话总结
本文提出 RATs(Robotics Agent Teams),一种注重趣味性的 Agent 式机器人学习框架。在该框架中,自主编码团队通过自我导向的玩耍(play)将成功执行的经验提炼为持久技能库,在 LIBERO-PRO 和 Molmo Spaces 基准上相比 CaP-Agent0 分别提升了 20.6 和 17.0 个百分点。同时,该框架支持无需微调即可迁移至其他 Code-as-Policy Agent,使 RoboSuite 和真实世界任务的性能分别提升 8.9 和 8.8 个点。
核心贡献
- 本文提出 RATs(Robotics Agent Teams)框架,使具身编码 Agent 能够在下游指令下达前的玩耍阶段,自主提出并执行自我导向的探索性任务。
- 该方法以主动技能发现取代被动任务跟随,通过持续验证中间进度、诊断失败原因,并将成功执行的经验提炼为持久代码技能库以供后续检索。
- 在 LIBERO-PRO 和 MolmoSpaces 上的评估表明,通过玩耍习得的技能相比 CaP-Agent0 基线,在保留的下游任务上分别提升了 20.6 和 17.0 个百分点。同时,通过即插即用的检索方式迁移至其他 Code-as-Policy Agent,可在无需模型微调的情况下,使 RoboSuite 和真实世界的迁移性能分别提升 8.9 和 8.8 个点。
数据集
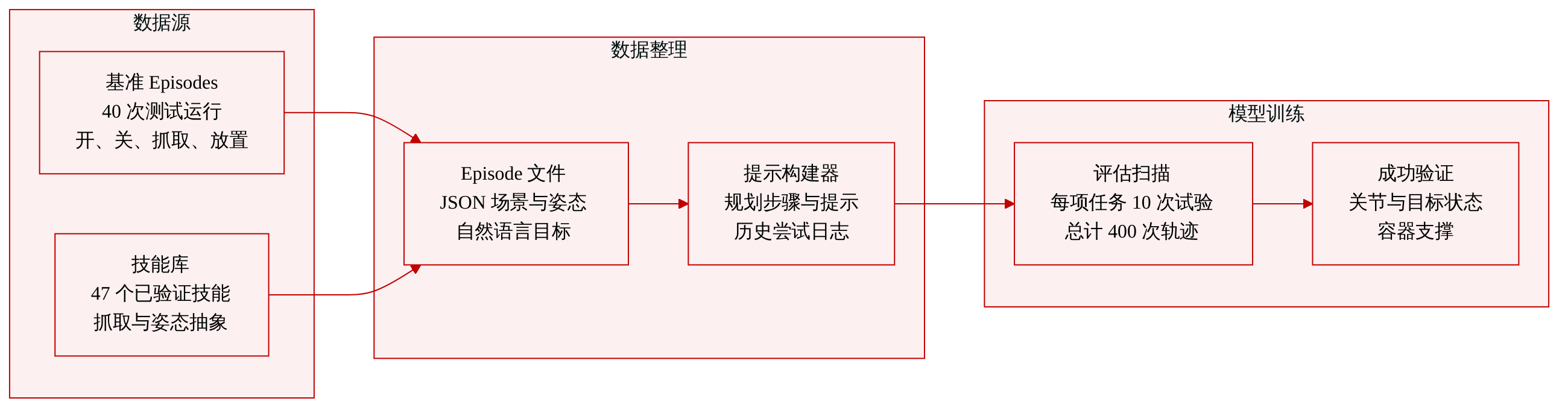
- 数据集构成与来源: 本文使用 MolmoSpaces 基准测试中一个紧凑的保留子集,并结合 LIBERO 技能库。基准测试数据源自四种上游任务变体(Open-v1、Close-v1、Pick-v2-classic 和 PnP-v2),而 LIBERO 提供经过验证的感知与操作抽象。
- 子集详情: 评估集包含 40 个测试回合,从 37 个不同的房屋场景中按任务类型随机采样,每种任务类型 10 个。每个回合存储在一个 JSON 文件中,记录场景数据集、房屋索引、Franka 初始化参数、物体位姿、任务状态、自然语言指代表达式以及相机规格。LIBERO 库提供 47 个习得技能,本文将其作为可复用的机器人控制抽象模块。
- 数据使用与处理: 本文严格将该子集保留用于评估,并对每个任务运行 10 次试验的主循环,共生成 400 次总 rollout。使用该数据将 RATs 与直接代码生成方法进行基准对比。任务成功率通过
judge_success()谓词计算,该谓词用于验证关节状态(针对铰接任务)、目标状态(针对抓取任务)以及容器支撑(针对抓取放置任务)。 - 元数据与提示词构建: 本文直接从 LIBERO 实验日志构建迭代式 Agent 提示词。每个提示词模板包含结构化占位符,用于自然语言目标、预期计划步骤、功能提示、已执行代码以及运行时执行标准。为支持自我修正,提示词末尾附加了按时间顺序排列的先前尝试日志,包含诊断说明和相关图像,使模型能够在多次试验中优化策略。
实验
png]]
表格说明:MolmoSpaces 关于玩耍策略与测试时系统的消融实验。所有基于玩耍的变体均使用 50 次玩耍迭代。所有玩耍阶段技能均由本文提出的 RATs 系统习得。

平均成功率从 21.0% 提升至 25.8%,其中在闭合任务上的提升最为显著。当完整的 RATs 执行系统使用相同的习得技能时,性能提升更为明显,从无玩耍的 32.8% 提升至 Curious Play 的 38.0%。这些结果表明,玩耍阶段技能学习与结构化的 RATs 测试时执行系统提供了互补优势:仅凭习得技能库即可提升标准 Code-as-Policy Agent 的性能,而完整的执行系统则能更有效地检索、验证并组合这些技能以完成下游任务。
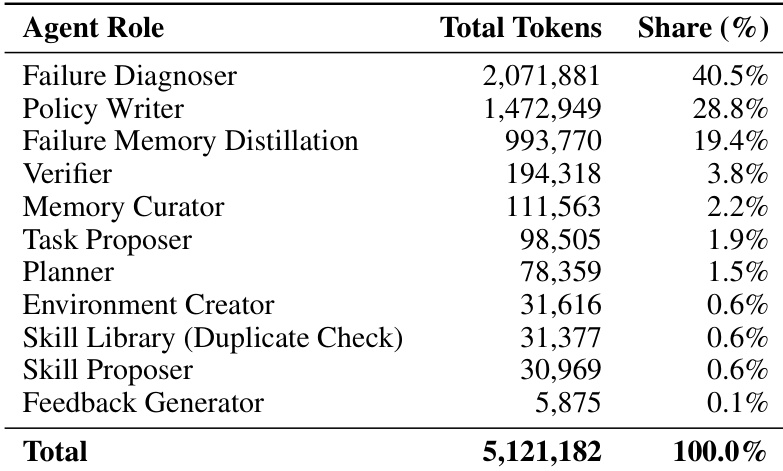
- E.2 Token 消耗分析
由于 RATs 高度依赖大型语言模型(LLM)进行任务提出、规划、代码生成与失败诊断,本文对自主玩耍阶段与测试时评估阶段的 token 消耗进行了详细分析。本节记录的所有 LLM 调用均使用 gpt-5.5。
玩耍阶段 Token 消耗。本文分析了在 libero_spatial 环境中的一次玩耍模式运行。在玩耍迭代过程中,每次迭代最多分配五次尝试机会,token 消耗严重偏向于耗尽重试预算的失败迭代。表格中的分组件拆解显示,Write-Execute-Verify-Diagnose 循环是主要的成本驱动因素。这表明,尽管内在的任务提出相对节省 token,但从反复的物理失败中提取诊断信息并修订策略,仍然是玩耍阶段最主要的计算开销。
计算量匹配的测试时对比。为确保公平比较,本文计入 RATs 在自主玩耍阶段产生的前置 token 成本。完整的 50 次迭代玩耍阶段消耗约 30M token。本文将该玩耍阶段成本分摊至 LIBERO-PRO 的 60 个保留任务上。
基线 CAP-AGENT0 在标准的 10 轮重试预算下,每个任务消耗约 1.6M token。将 RATs 分摊后的玩耍阶段 token 成本加入该基线,可为 CAP-AGENT0 分配更大的测试时计算预算,使其每个任务可运行约 15 轮。因此,本文评估了一个计算量匹配的基线:具有 15 轮预算的 CAP-AGENT0,并将其与具有标准 10 轮预算且通过 Curious Play 习得 RATs 技能库的 CAP-AGENT0 进行对比。该对比旨在明确:相同的额外 token 预算,是更有效地用于被动地增加测试时重试次数,还是更有效地用于主动地在玩耍阶段获取技能。
表格说明:各 Agent 组件的玩耍阶段 token 消耗(10 次迭代)。

表格说明:LIBERO-PRO 上的计算量匹配性能对比。CAP-AGENT0 (15 turns) 基线在测试时获得额外的重试预算,以匹配 RATs 在玩耍阶段消耗的分摊 token 成本。CAP-AGENT0 + RATs Skills 行使用标准的 10 轮 CAP-AGENT0 测试时系统,其技能源自 50 次 Curious Play 迭代。
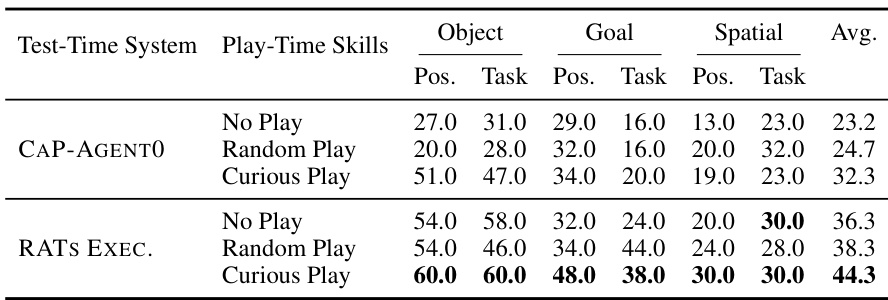
如表格所示,仅向基线分配更多测试时计算资源仅带来小幅提升,平均成功率从 23.2% 增至 26.0%。相比之下,在玩耍阶段主动消耗相当的计算预算,随后在相同的 10 轮 CAP-AGENT0 测试时系统中复用习得技能,可将平均成功率提升至 32.3%。该结果表明,性能提升并非仅仅源于给予 Agent 更多的推理时重试机会。相反,当玩耍阶段的计算被提炼为可复用的技能库,并能在保留任务中进行检索与组合时,其效率更高。
- F.1 Agent I/O 总结
表格列出了 RATs 所使用的 Agent 的输入与输出。
本文评估了通过在 LIBERO-PRO 中自主玩耍习得的技能向独立仿真环境 RoboSuite 以及真实物理机器人的跨环境迁移能力。结果表明,将玩耍习得的技能库集成至基线 Agent 中,可稳定提升大多数操作任务的性能。该系统在抓取提升操作中展现出显著增益,而在某些装配与擦拭任务上效果中性。此外,习得技能成功迁移至真实世界场景,显著提升了物理操作成功率。从单臂仿真玩耍中习得的技能有效迁移至独立的双臂协作提升任务。增强后的 Agent 在大多数 RoboSuite 操作基准上取得显著性能提升。玩耍习得的能力同样提升了初步真实物理机器人任务的成功率。
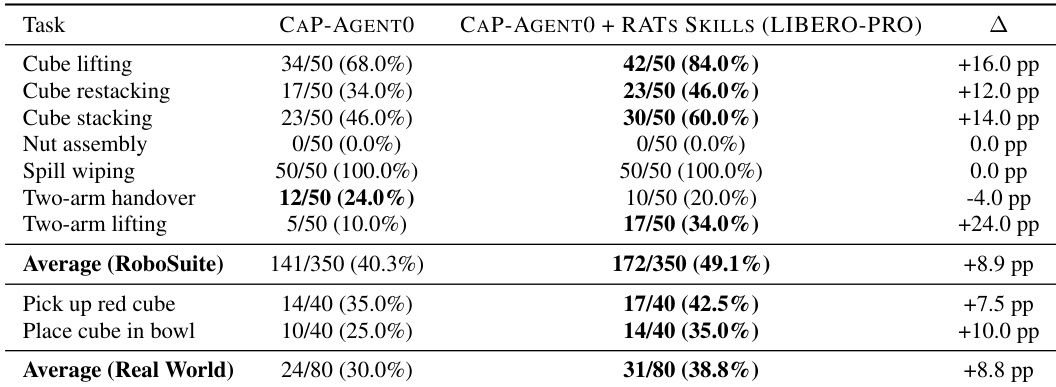
本文分析了自主玩耍阶段不同 Agent 角色之间的 token 消耗分布。结果表明,消耗严重偏向失败诊断与策略编写,两者合计占计算开销的绝大部分。相比之下,任务提出、规划与验证等辅助组件消耗的 token 占总量的比例较小。失败诊断消耗的 token 比例最大,凸显其为最主要的计算开销。策略编写与记忆提炼紧随其后,为次重要的 token 消耗项。任务提出与验证等辅助角色仅占用极小的 token 预算。
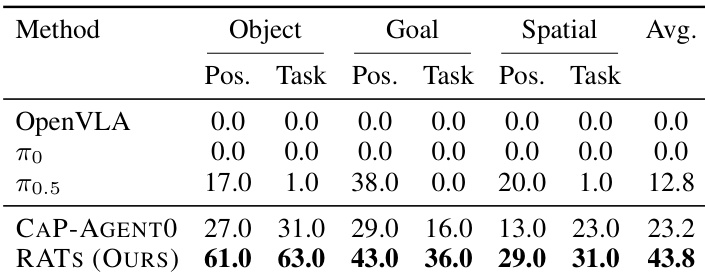
本文在测试物体、目标与空间泛化能力的基准上,将所提框架与多种基线方法进行对比。结果表明,所提方法显著优于所有对比方法,在每种测试类别与扰动类型上均取得最高成功率。与视觉语言模型基线相比,性能差距尤为明显,后者在这些任务上成功率几乎为零。所提方法在所有评估的泛化划分(包括物体、目标与空间类别)上均实现卓越性能。在初始位置交换与任务扰动下,性能提升保持一致。该系统大幅领先视觉语言模型基线,后者在相同任务上的成功率极低。
本文评估了通过在 MolmoSpaces 中仿真玩耍习得的技能向真实世界操作任务的迁移效果。在涉及物体重排与铰接物体交互的任务中,对比了标准 Code-as-Policy Agent 与集成这些玩耍习得技能后的 Agent。结果表明,集成这些习得技能可大幅提升 Agent 在两种测试真实场景中的成功率。通过仿真玩耍习得的技能增强基线 Agent 后,能够成功执行标准 Agent 无法完成的复杂物体重排任务。技能增强系统在处理铰接物体方面表现出显著改进,相比基线,抽屉操作的成功率大幅提升。在评估的真实世界任务中,集成玩耍习得的能力带来了整体性能的显著跃升,凸显了将仿真技能迁移至物理硬件的有效性。

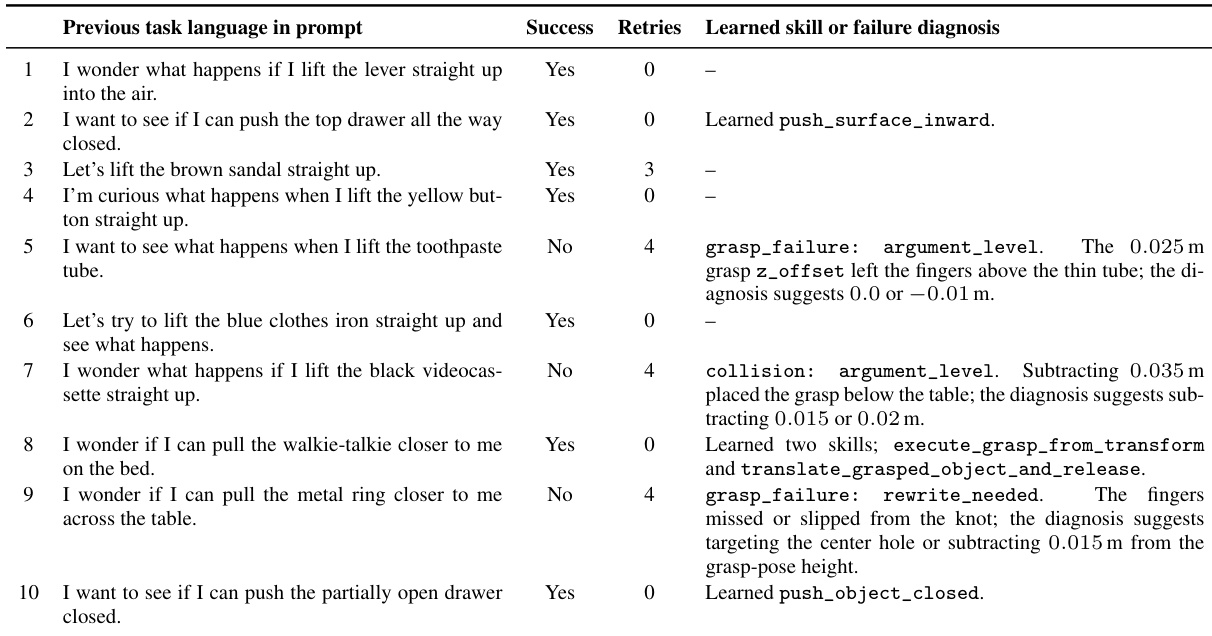
表格记录了一系列操作尝试过程,其中 Agent 提出任务、执行任务并记录结果。成功试验通常无需重试,并经常促生新的可复用技能;而困难或失败的试验则产生详细的诊断反馈,提示具体的参数调整或代码重写。这一迭代循环展示了系统如何基于直接物理反馈积累能力并优化执行策略。成功任务通常无需重试即可完成任务,并直接贡献于不断扩充的技能库。失败尝试生成详细的诊断反馈,精准定位具体执行问题,如抓取位置错误或碰撞风险。系统通过变换任务目标并基于先前结果优化执行参数,迭代构建出多样化的习得技能与失败记忆集合。
评估设置旨在跨仿真与物理环境测试自主玩耍框架,以验证跨环境技能迁移、计算效率与空间泛化能力。集成玩耍习得的能力可稳定提升基线 Agent 在多样基准与真实任务中的性能,尤其在复杂抓取提升与铰接物体操作方面表现突出,同时展现出对不同硬件设置的稳健迁移能力。计算分析表明,失败诊断与策略生成主导了 token 使用量,凸显系统对迭代反馈以积累技能的依赖。总体而言,该方法通过直接物理交互成功构建了多样化的能力库,大幅领先视觉语言基线,并为可扩展的仿真到真实技能获取确立了可靠路径。