Command Palette
Search for a command to run...
超越当前观测:在可控非马尔可夫博弈中评估多模态大语言模型
超越当前观测:在可控非马尔可夫博弈中评估多模态大语言模型
Shengyuan Ding Xilin Wei Xinyu Fang Haodong Duan Dahua Lin Jiaqi Wang Yuhang Zang
摘要
将多模态基础模型部署为闭环策略,日益要求在动作决策中依赖那些已不可见的观测信息。然而,现有基准测试要么暴露完整状态,将隐藏状态重建与其他agent技能相混淆,要么仅在单个episode结束后才测试回忆能力。我们提出RNG-Bench(Reconstructive Non-Markov Games),这是一套基准测试套件,旨在独立评估基础模型重建历史观测信息并在多步交互中据此采取行动的能力。RNG-Bench包含两个互补的游戏:Matching Pairs,要求模型在特定位置短暂揭示卡片身份后,在后续阶段进行回忆;以及3D Maze,要求将第一人称视角的观测信息整合为空间地图。两款游戏均在统一的评估框架下进行测试,包含三个受控的难度维度:网格尺寸、视觉图案以及观测模态。该基准进一步引入了面对面对决协议以控制实例级方差,并提出了Memory Gap指标,以区分遗忘现象与动作选择次优的问题。最具挑战性的配置要求每个episode的上下文长度约为128K tokens,并包含350个图像输入,且目前前沿的多模态大语言模型(MLLMs)在此类配置下仍未达到性能饱和。Memory Gap分析表明,模型产生的大部分残余误差主要源于对早期观测信息的遗忘,而非决策次优。最后,在最优策略rollouts及筛选后的模型演示数据上对Qwen3.5-9B进行微调,不仅提升了其在RNG-Bench上的性能,且该能力可迁移至现有基准测试中,同时未损害其通用的多模态能力。
一句话总结
作者提出了 RNG-BENCH,一个用于评估多模态大语言模型在非马尔可夫游戏中重构历史观测能力的基准测试套件。该套件通过可控的难度维度、一对一决斗协议以及旨在将遗忘与动作选择失误分离的 Memory Gap 指标进行评估。结果表明,尽管前沿模型因遗忘早期观测而尚未达到性能饱和,但在最优策略 rollout 和过滤后的演示数据上对 Qwen3.5-9B 进行微调,能够提升模型表现,并迁移至现有基准测试,且不会损害其通用多模态能力。
核心贡献
- 提出 RNG-BENCH 基准测试套件,该套件能够分离模型在多步交互中重构历史观测并据此条件化后续动作的能力。该套件在统一测试框架下评估两款互补游戏(Matching Pairs 与 3D Maze),难度维度涵盖网格尺寸、视觉模式及观测模态。
- 提出一对一决斗协议与 Memory Gap 指标,旨在将时间遗忘与 agent rollout 过程中的次优动作选择分离开来。该诊断框架独立评估潜在状态维持能力,避免将记忆重构与其他交互技能混淆。
- 证明在最优策略 rollout 和过滤后的演示数据上微调 Qwen3.5-9B,能够在提升 RNG-BENCH 性能的同时迁移至现有基准测试,且不损害通用多模态能力。Memory Gap 分析表明,剩余误差主要源于对早期观测的遗忘,而非次优决策,证实该基准测试成功分离了长上下文记忆缺陷。
引言
随着多模态基础模型向具身控制和多轮工具使用等闭环应用过渡,它们必须在非马尔可夫环境中运行,其中最优决策依赖于重构历史观测,而非仅依赖当前视图。现有的评估套件未能分离这一关键能力,要么在完全可见的状态下测试规划,要么将隐藏状态回忆与探索和规则发现相混淆,要么将评估局限于无交互反馈的事后问答。作者提出 RNG-BENCH,一个包含两款闭环游戏的基准测试套件,强制模型保留并利用过往的视觉与空间信息。通过实现可控难度维度、一对一决斗协议以及 Memory Gap 指标,作者将记忆损失与次优决策分离,并证明针对性微调能显著提升长程记忆能力,同时保留通用多模态能力。
数据集

- 数据集构成与来源: 作者使用两款自定义模拟器构建 RNG-Bench,通过程序化生成游戏环境,确保所有视觉观测均为合成数据,无需人工收集。轨迹数据来源于两部分:确定性规则基线(oracle)以及由更大规模多模态语言模型(Qwen3.5-397B 与 Kimi-K2.5)生成的 rollout 片段。
- 关键子集细节: Matching Pairs 环境采用矩形网格,agent 每回合翻两张卡片以匹配身份。作者调整棋盘尺寸、观测模态(文本或受控图像)、视觉模式、动作反馈及响应预算。隐藏状态记录已揭示的身份-位置绑定关系。3D Maze 环境要求 agent 利用第一人称 3D 渲染和对话历史,在程序化生成的网格中导航。作者将迷宫尺寸调整为 5x5 至 15x15,设置 0.15 的循环率以引入回路,并将步数预算上限设为 80 步或最短路径长度的四倍。隐藏状态记录空间拓扑、已访问单元格、当前坐标及朝向。
- 训练用途与划分: 作者对 Qwen3.5-9B 进行监督微调,针对 action token 计算损失,同时对 observation token 屏蔽损失。训练轨迹涵盖尺寸为 2x4 至 8x8 的 Matching Pairs 棋盘,以及尺寸为 5x5 至 9x9 的 3D 迷宫。所有评估片段的尺寸均严格超过上述范围,并使用互斥的随机种子以防止数据泄露并测试规模泛化能力。
- 数据处理与构建: 作者整理了两组独立的轨迹池。最优池包含由手写规则基线直接生成的 32K 无错误片段。rollout 池通过让更大规模的基础模型在 RNG-Bench 上运行收集,并应用正确性过滤器仅保留成功解决的轨迹,最终池上限为 6K。为隔离不完备策略的影响,作者将 26K 最优片段与 6K rollout 片段结合,构建包含 32K 轨迹的混合数据集。完整轨迹日志被保留以支持细粒度诊断,环境超参数被系统性地切换,以分离记忆追踪、空间推理及上下文长度需求。
方法
作者将每个基准实例建模为由元组 (S,O,A,T,Z,R) 定义的偏马尔可夫决策过程(POMDP)。其中,S、O 和 A 分别表示状态、观测与动作空间。转移函数 T 指定动作执行后状态的变化方式,观测函数 Z 决定 agent 从当前状态感知到的内容,R 提供奖励。在这些非马尔可夫环境中,当前观测 ot 不足以支持最优决策。相反,agent 必须依赖上下文内的片段历史 ht=(o1,a1,…,ot) 进行决策。核心挑战在于 agent 构建内部信念状态 bt=f(ht),以总结不再直接可见的隐藏且与任务相关的信息。作者将模型评估为基于历史的策略 π(at∣ht),默认情况下这些策略直接在原始历史上运行,无需外部信念模块。
交互流程请参考框架图。agent 处理片段历史 ht 以重构内部信念状态 bt,随后该状态指导动作 at 的选择,进而产生新观测 ot+1。
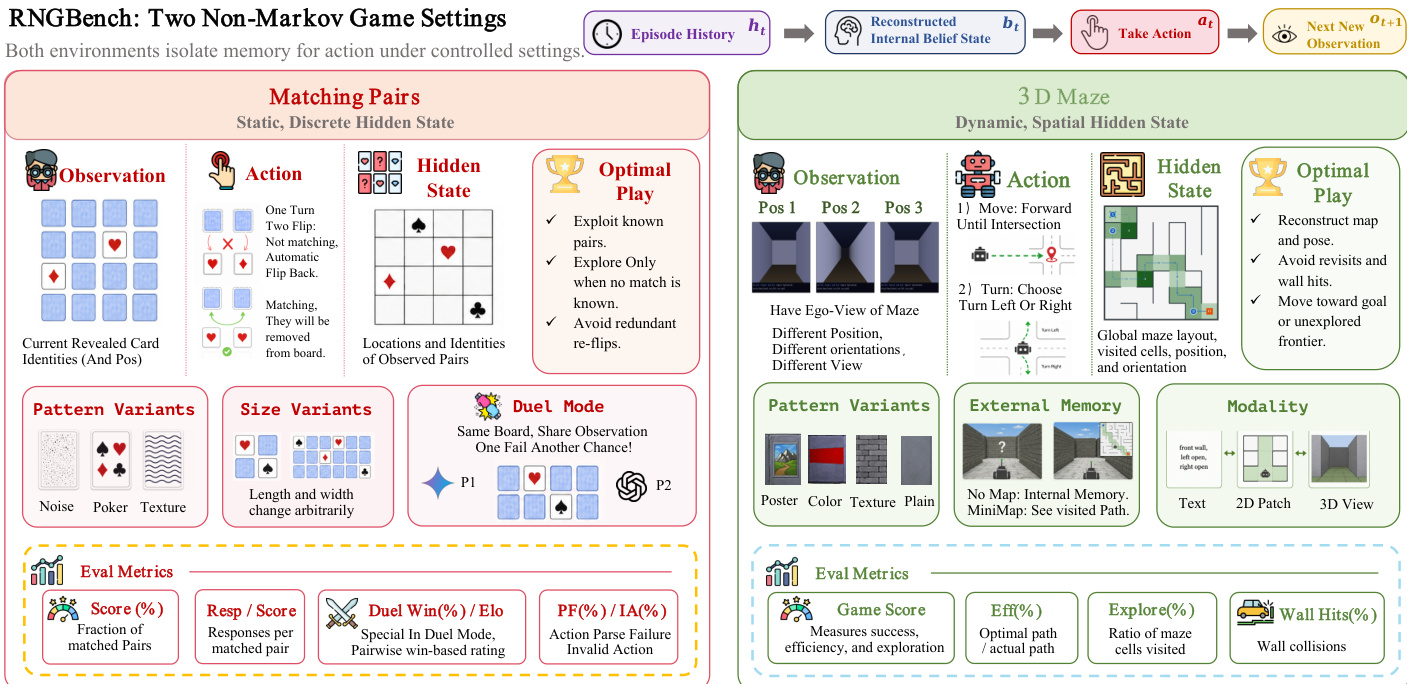
该基准测试包含两款互补环境,用于测试状态追踪的不同方面。第一款为 Matching Pairs,用于隔离静态离散隐藏状态记忆。在此设定中,agent 观察卡片网格并选择动作进行翻转。隐藏状态由配对的位置与身份组成。最优策略要求利用已知配对,仅在必要时进行探索,并避免冗余重复翻转。该环境支持噪声、扑克花色及纹理等模式变体,以及任意尺寸变化。此外,引入决斗模式,由两款模型在同一棋盘上竞争。在此模式下,玩家观察自身与对手共同揭示的卡片。成功匹配可获得额外回合,匹配失败则回合移交对手。该协议控制棋盘随机性,并测试模型将对手揭示的信息融入信念状态的能力。
第二款环境为 3D Maze,旨在测试动态空间隐藏状态追踪。agent 接收来自不同位置与朝向的迷宫第一人称观测。动作包括向前移动直至交叉口,或向左/右转。隐藏状态涵盖全局迷宫布局、已访问单元格、当前位置及朝向。最优策略涉及重构地图、避免撞墙与重复访问,并向目标移动。该环境包含海报、彩色、纹理及素色墙壁等模式变体,以及从无地图到已访问路径迷你地图等外部记忆选项。同时支持文本、2D 图块与 3D 视图等模态变体。
实验
评估利用两款可控非马尔可夫环境(Matching Pairs 与 3D Maze),在单人及决斗模式下运行,旨在将上下文内信念状态追踪与规则理解及视觉感知分离。规模扫描与诊断消融实验验证,模型性能下降主要随潜在状态复杂度增加而发生,表明隐藏状态维持而非规则理解是核心瓶颈。模态与动作历史测试进一步揭示,视觉识别对追踪的限制大于上下文长度,而显式文本反馈对于更新内部状态估计至关重要。最终,实验表明长程推理依赖于模型将观测持续整合至稳定内部表示的能力,外部记忆干预仅提供部分缓解,且在不同空间与基于身份的任务中效果差异显著。
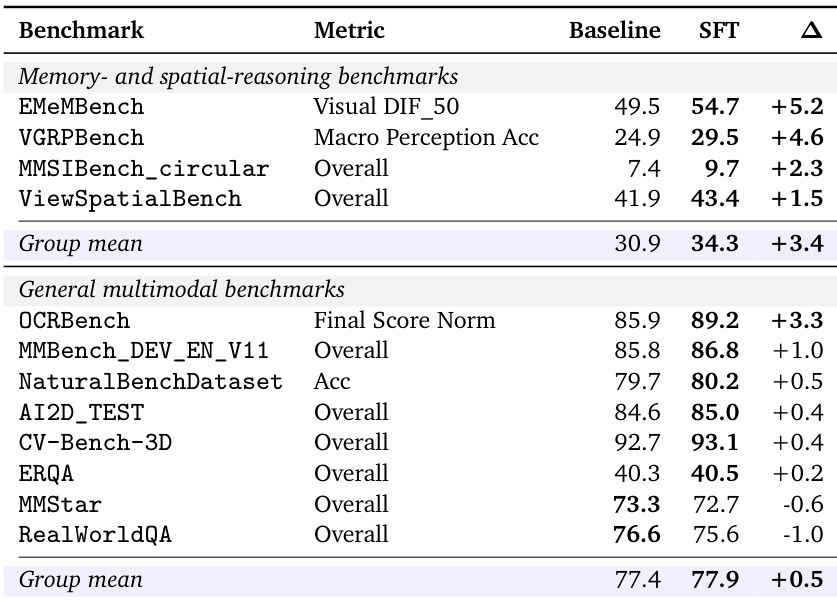
下表对比了基线模型与监督微调变体在记忆与空间推理基准测试及通用多模态基准测试上的表现。微调模型在所有记忆与空间推理任务中均展现出一致且显著的提升。相比之下,通用多模态类别整体仅呈现边际改善,多数指标微幅上升,少数略有下降。微调模型在所有记忆与空间推理基准测试中持续优于基线模型。通用多模态基准测试的性能变化极小,多数指标仅微幅改善。两项通用多模态任务在微调后出现轻微性能下降,与空间推理的明确提升形成对比。
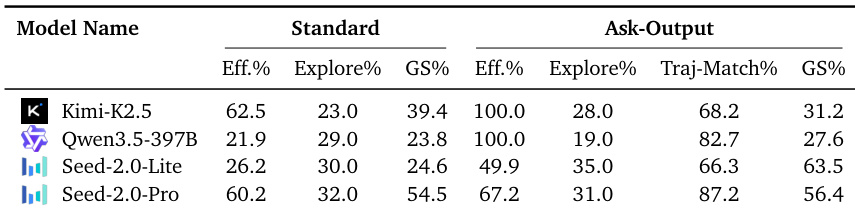
作者评估了一项干预措施,即提示模型在每一步显式生成内部空间地图以辅助导航。尽管该策略显著提升 Seed-2.0-Lite 的导航成功率,但对 Kimi-K2.5 与 Qwen3.5-397B 的收益甚微,尽管它们能够生成准确地图。Seed-2.0-Lite 从该干预中获益最多,游戏得分与轨迹匹配准确率均有大幅提升。Kimi-K2.5 与 Qwen3.5-397B 虽生成高质量空间地图,却未能将此信息转化为任务完成率的提升。Seed-2.0-Pro 在标准模式与 ask-output 模式下均保持高水平稳定表现,表明其具备强大的内在空间规划能力。
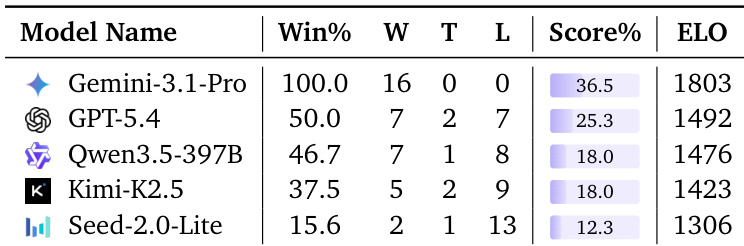
作者在一对一决斗模式下评估了五款模型,它们在匹配任务中直接竞争。Gemini-3.1-Pro 展现出卓越性能,赢得所有对局并获得最高 Elo 评分,优于其他领先模型。该结果表明其具备利用对手揭示信息以锁定连续匹配的强大能力。Gemini-3.1-Pro 赢得所有对局,并在所有测试模型中位列 Elo 评分榜首。GPT-5.4 位居第二,其胜率与得分百分比均高于 Qwen3.5-397B。Seed-2.0-Lite 等模型的胜率最低,凸显出显著的性能差距。
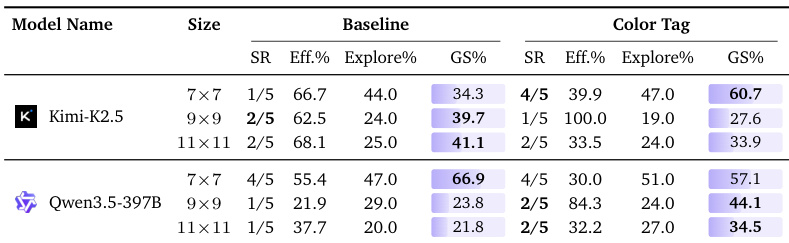
实验评估了在 3D 迷宫环境中用不同颜色粉刷墙壁以辅助空间导航的影响。结果表明,该视觉干预在不同模型架构与迷宫规模下产生的收益不一致。部分配置显示成功率或综合得分提升,而其他配置则出现性能下降或收益微乎其微。这表明简单的颜色标记不足以可靠地稳定这些模型的空间信念追踪。颜色标记干预带来混合结果,某模型在最小规模下成功率提升,但在中等规模下性能下降。另一模型在较大迷宫规模下综合得分略有增长,但成功率并未持续改善。墙壁颜色提供的视觉地标未能一致地稳定空间导航,因为性能趋势在不同模型架构与规模间差异显著。
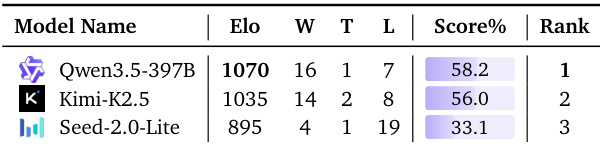
下表根据语言模型在 Matching Pairs 任务文本决斗模式下的表现进行排名。Qwen3.5-397B 凭借最高 Elo 评分与胜率占据首位,Kimi-K2.5 紧随其后。Seed-2.0-Lite 表现明显落后,胜场数与得分百分比均为最低。Qwen3.5-397B 展现出最强性能,以最高胜场数与最佳综合评分位列第一。Kimi-K2.5 保持第二的竞争力,其胜率与得分百分比与领先模型非常接近。Seed-2.0-Lite 存在显著性能差距,以最少胜场与最低成功率在评估模型中垫底。
该评估框架考察监督微调、显式空间地图生成、视觉地标增强及一对一竞争匹配,以确定架构差异与针对性干预如何影响空间推理与策略适应性。微调可靠地增强了记忆与空间能力,且未显著改变通用多模态性能;而提示模型生成内部地图或用不同颜色粉刷墙壁带来的导航收益不一致,且高度依赖底层模型设计。竞争决斗模式进一步揭示出明显的性能层级,表明仅有少数模型能有效利用对手揭示的信息以维持持续优势。综合来看,这些发现表明,尽管针对性干预可提升特定推理任务,但将内部空间表示或简单视觉线索转化为稳健可靠的执行能力,仍是许多架构面临的持久挑战。