Command Palette
Search for a command to run...
EfficientRollout:用于强化学习 rollout 的系统感知自投机解码
EfficientRollout:用于强化学习 rollout 的系统感知自投机解码
Minseo Kim Minjae Lee Seunghyuk Oh Kevin Galim Donghoon Kim Coleman Hooper Harman Singh Amir Gholami Hyung Il Koo Wonjun Kang
摘要
强化学习(RL)已成为大语言模型(LLMs)的一种代表性后训练范式,赋予了其强大的推理与agent能力。然而,rollout生成仍是主要的延迟瓶颈,因为自回归采样按顺序解码响应,且少数长尾生成往往决定了整体完成时间。推测解码(SD)为解决该瓶颈提供了一种自然途径,因为它是一项成熟的服务固定LLMs的技术,能够通过快速起草tokens并通过并行验证予以接受,在保持目标模型分布的同时有效降低延迟。然而,其实际加速效果无法直接迁移至RL rollout过程:(i)不断演进的目标策略使得任何固定起草器越来越难以匹配该策略的输出分布;(ii)在rollout解码期间,活跃批大小逐渐缩小,导致解码过程从计算密集型转变为内存密集型,此时并行验证方可利用未充分利用的计算资源。因此,加速RL rollout不仅需要一种在演进策略的长程、高温度生成下仍保持高效的起草器,还需要一种避免计算密集型模式的系统感知型SD应用策略。本文提出EfficientRollout,这是一种系统感知型自推测解码(self-SD)框架,专为填补RL rollout领域的这一空白而设计。EfficientRollout从目标模型中衍生出量化起草器(即自推测解码),使其与不断演进的目标策略保持耦合,无需进行独立的起草器预训练或在线适配。该框架进一步将系统感知型SD切换策略与接受度感知型草稿长度自适应机制相协调,仅在有益的计算模式下启用推测,并将起草预算与不断变化的起草器质量相匹配。相较于加速的自回归(AR)rollout基线,EfficientRollout将rollout延迟与端到端延迟分别最高降低了19.6%和12.7%,同时保持了最终的模型质量。
一句话总结
EfficientRollout 是一种系统感知的自推测解码框架,它通过动态调整草稿生成器以适配不断演进的目标策略,并为内存受限型执行优化验证过程,从而加速大语言模型的强化学习 rollout 生成,有效克服了自回归采样与固定草稿生成器推测解码带来的延迟瓶颈。
核心贡献
- 本文提出了 EfficientRollout,一种系统感知的自推测解码框架。该框架在每个训练步骤中直接从不断演进的目标策略中生成权重量化草稿生成器,以维持高 block efficiency。
- 该框架集成了一种系统感知的推测解码开关,将执行限制在有利于内存受限的计算区间,并采用自适应草稿长度策略,动态调整草稿生成预算以匹配实时的 token 接受率。
- 实证评估表明,与标准强化学习流程相比,该框架可将 rollout 延迟降低高达 19.6%,端到端训练延迟降低高达 12.7%。
引言
强化学习后训练对于提升大语言模型的推理能力与 agent 能力至关重要,然而 rollout 生成仍是主要的延迟瓶颈,因为顺序自回归解码难以跟上这些模型生成的长响应。尽管推测解码能够降低推理延迟,但在强化学习 rollout 中面临显著障碍:持续演进的目标策略会导致固定草稿生成器失配,而不断缩小的 batch size 会将计算负载从计算受限型转移至内存受限型,使得并行验证的收益递减。先前的解决方案要么采用 block efficiency 较低的历史依赖型草稿生成,要么依赖需要独立预训练和在线适配的辅助草稿生成器,从而增加了显著的系统复杂性。本文作者提出了 EfficientRollout,一种系统感知的自推测解码框架,它直接从演进的目标模型中生成量化草稿生成器,在无需额外训练开销的情况下保持对齐。该方法结合了区间感知开关(仅在有利条件下激活推测)与自适应草稿长度控制,使草稿生成预算与接受行为相匹配,在保持模型质量的同时实现了高达 19.6% 的 rollout 延迟降低。
方法
本文作者提出了 EfficientRollout,一种专为加速强化学习 rollout 而设计的系统感知自推测解码(SD)框架。该方法针对强化学习训练固有的三个特定挑战:演进的目标策略、不断缩小的活跃 batch 动态变化,以及 rollout 尾部的延迟瓶颈。该框架集成了目标诱导型量化草稿生成器、动态 SD 开关策略以及自适应草稿生成预算。
为应对策略演进问题,该方法采用直接从当前目标模型派生的自 SD 草稿生成器。这确保了草稿生成器能够与策略保持同步,而无需独立的预训练或在线适配。具体而言,作者对 FFN 和 QKVO 投影层应用了轻量级最近舍入(RTN)量化。此举旨在针对在 rollout 尾部主导解码延迟的密集投影时间,从而降低草稿生成器到目标模型的延迟比率。
该框架还集成了区间感知 SD 开关策略,用于判断何时推测解码能够带来收益。在 rollout 早期阶段,活跃 batch size 较大,通常会饱和计算资源,导致 SD 速度慢于标准自回归解码。作者利用校准后的 roofline 模型,基于当前 batch size 和序列长度预测加速比。仅当预测加速比超过安全阈值时才会激活 SD,这通常发生在 batch size 缩小且系统转为内存受限的“rollout 尾部”阶段。
此外,该系统具备自适应草稿长度策略。随着强化学习训练的推进,目标策略逐渐收敛,从而提升了目标模型与量化草稿生成器之间的一致性。该方法会监控 block efficiency 并相应调整草稿长度,在接受率高时增加长度,在接受率下降时减少长度。
如下图所示,整体架构将这些组件整合为一个统一流水线,负责管理 rollout 生成、奖励计算与策略更新。
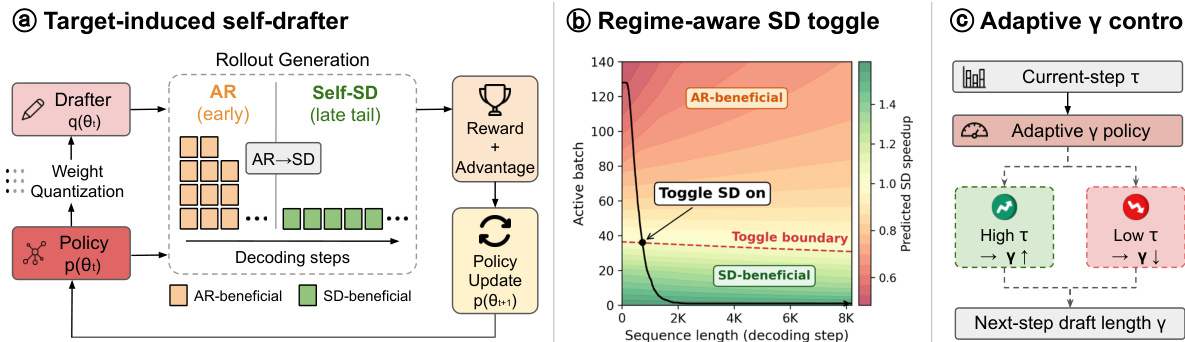
详细的解码过程遵循“草稿生成与验证”循环。该过程由草稿生成器生成一系列 token 序列开始,随后目标模型对这些 token 进行并行验证。

若在验证过程中拒绝某个 token,系统将执行 KV cache 回滚至最后一次接受的状态。这确保了策略更新基于有效轨迹,同时保留了推测解码带来的效率增益。作者利用该机制在无需改变底层强化学习分布的情况下,同时降低了 rollout 延迟与端到端延迟。
实验
3%),即使采用更短的 γˉ,也反映出在长序列、高温度强化学习 rollout 中辅助草稿生成器的效果有限(见第 5.3 节)。
训练动态与质量保持。EfficientRollout 在加速训练的同时保持了训练动态。该图显示,EfficientRollout 在 Qwen2.5-7B 上的奖励轨迹与 veRL (AR) 高度吻合。这与 SD 的无损特性一致,即保留目标分布 [6, 29],这在强化学习中尤为重要,因为 rollout 分布偏移可能影响训练稳定性 [15, 63]。所有评估模型的完整奖励与验证准确率轨迹详见第 F.2 节。
- 5.3 rollout 加速的进一步分析
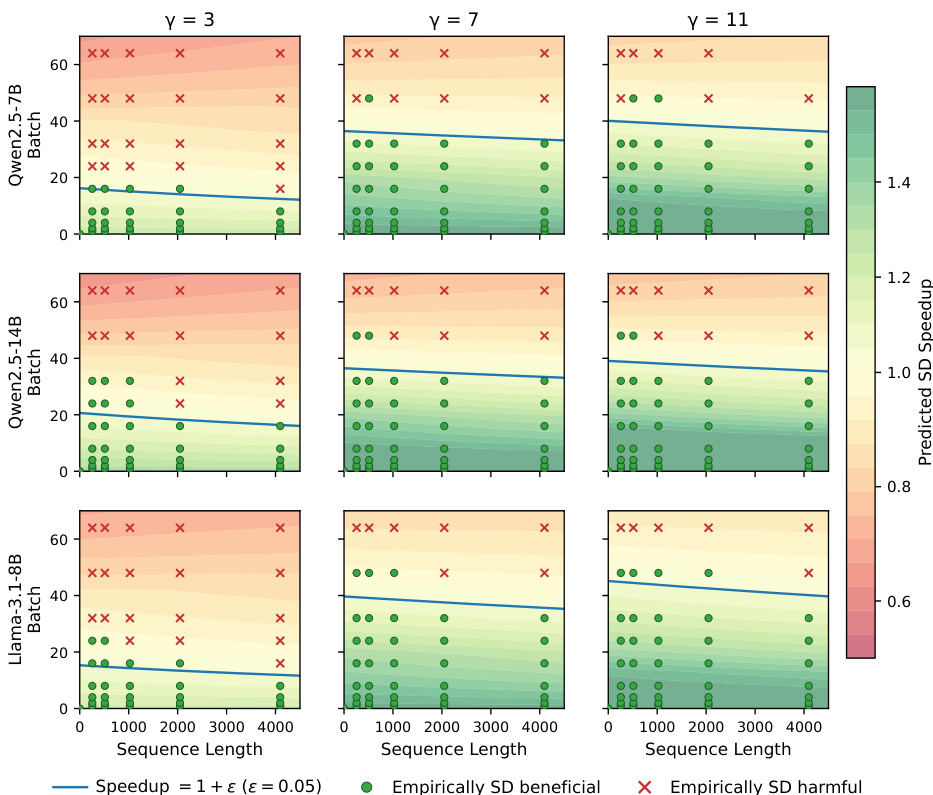
区间感知 SD 开关策略。仅靠高 τ 不足以实现实际加速,SD 必须通过开关策略 πSD 仅在有利于系统的区间内激活。该图通过展示预测加速比在 (B,S) 平面上正确区分了有利于 SD 与不利于 SD 的坐标,验证了 πSD 的校准 roofline 边界。该图通过比较在相同量化自草稿生成器下“始终启用 SD”与“按 πSD 启用 SD”的 rollout 延迟,隔离了 πSD 的效果。仅在解码步骤的前 6–11% 阶段禁用 SD,πSD 策略相较于始终启用的 SD,能产生更稳定且更大的 rollout 生成延迟降低(相对于 AR),尽管其 τ 略低。因此,这些增益不能归因于更好的草稿质量;它们源于避免了初始大 batch 区间内的验证开销,
该图:预训练辅助草稿生成器的 block efficiency。在 DAPO-Math-17K 上,评估的预训练辅助草稿生成器实现的 block efficiency 低于量化自草稿生成器。
当 TV/Tp 较高时。πSD 的完整验证结果详见第 D.3 节。
自适应草稿长度策略。随着演进的目标策略在训练过程中发生偏移,自适应 γ 策略有效追踪了降低延迟的最优 γ。该研究通过在完整训练过程中仅将 EfficientRollout 中的自适应 γ 策略替换为固定 γ 变体,以隔离该效果。如图所示,自适应 γ 策略实现了 rollout 生成延迟整体降低 19.6%,而固定 γ=γlow=5 与 γ=γhigh=11 的降低幅度分别为 13.5% 和 11.8%。这一改进得益于利用训练不同阶段的更大延迟降低潜力,因为较小和较大的 γ 值分别
在训练早期和后期更为有效。该自适应 γ 策略并非通过后验扫描选择单一固定 γ,而是利用观测到的 τ 反馈在预指定的 Γ 范围内动态调整
强化学习工作负载中的学习辅助草稿生成。表格中学习辅助草稿生成较低的 τ 和 α 反映了获取与长序列、高温度强化学习 rollout 对齐的辅助草稿生成器的实际困难。在 Iso 等人 [24] 先前提出的 RL-SD 配置下,该研究在 DAPO-Math-17K [63](该配置使用的 rollout 工作负载)上进一步评估了辅助草稿生成器。如图所示,评估的辅助草稿生成器 [41, 43] 在前 30 步中仅达到 τ=1.2–2.4,而在相同设置下,量化自草稿生成器始终达到 τ=3.6–3.9。这些结果表明,直接复用公开 checkpoint 或使用固定目标 LLM 服务配方预训练的草稿生成器 [32, 71],不足以在强化学习 rollout 中可靠地获得高 τ。借助学习辅助草稿生成实现有效加速可能需要更专用的辅助草稿生成器训练流程 [24, 74],例如收集分布内 rollout、在目标生成的合成数据上训练草稿生成器,并可能采用更激进的在线适配。带有额外辅助草稿生成器 checkpoint 的详细评估设置与分析见第 F.6 节。
作者通过在不同模型和草稿长度下比较预测加速区域与实测数据,验证了基于 roofline 的开关策略。结果表明,预测边界有效区分了有利于推测解码与不利于推测解码的配置。随着草稿长度增加,推测解码带来加速的运行区间显著扩大,覆盖了绝大多数测试的 batch size 和序列长度。预测加速边界在所有评估模型中准确分离了实证上有利与不利的配置。增加草稿长度显著扩大了推测解码产生加速的区域,减少了不利配置的数量。该开关策略成功识别并避免了高 batch 区间,在此区间内推测解码的开销会超过计算收益。
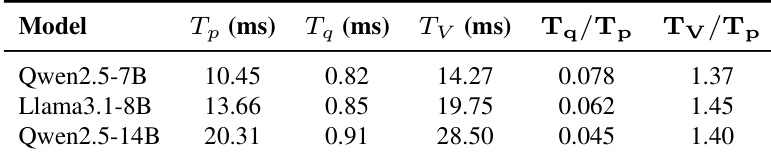
作者分析了 EfficientRollout 方法在三种不同规模的开源模型上的延迟分解情况。结果表明,预测时间与验证时间均随模型规模增加而上升,而量化开销保持稳定。在所有配置下,验证时间始终比预测时间高出相近幅度,且量化开销的相对成本随模型增大而降低。在所有评估模型中,验证延迟始终高于预测延迟。量化开销保持较低水平且独立于目标模型规模。随着目标模型规模增大,量化开销的相对影响逐渐减弱。
作者评估了不同草稿长度下权重量化自草稿生成器的 block efficiency。结果表明,block efficiency 随草稿长度增长而提升,8 位量化草稿生成器始终比 4 位版本实现更高的效率。两种草稿生成器的 block efficiency 均随草稿长度增加而改善。在效率指标上,8 位量化草稿生成器优于 4 位版本。在最低测试草稿长度下,两种草稿生成器均保持了较强的效率。

该表格展示了不同序列长度范围内辅助草稿生成器的 block efficiency 指标。数据显示,对于较小模型(Qwen2.5-7B 与 Llama3.1-8B),效率随序列长度增加而下降,表明效果减弱。相比之下,较大模型(Qwen2.5-14B)在更长序列下表现出效率提升,尽管整体数值仍低于自草稿生成器。较小模型随序列长度增长呈现 block efficiency 下降趋势。较大模型在更长序列下展现出 block efficiency 改善。这些指标数值与前述辅助草稿生成器效果有限的描述一致。

实验表明,与标准自回归推理及各种推测解码基线相比,EfficientRollout 在所有评估模型上提供了最显著的端到端训练加速。该方法通过大幅降低 rollout 生成延迟来实现这一目标,同时保持高 token 接受率并保留目标分布。在所有模型规模下,EfficientRollout 始终产生最低的端到端步长时间,优于基于历史、学习辅助及量化自草稿生成方法。该方法能够维持高接受率与 block efficiency,而学习辅助草稿生成则表现出较低的对齐度与不稳定的性能。尽管基于历史的草稿生成准备开销较低,但未能降低 rollout 生成延迟,这表明在此场景下简单的词缀复用不足以实现加速。
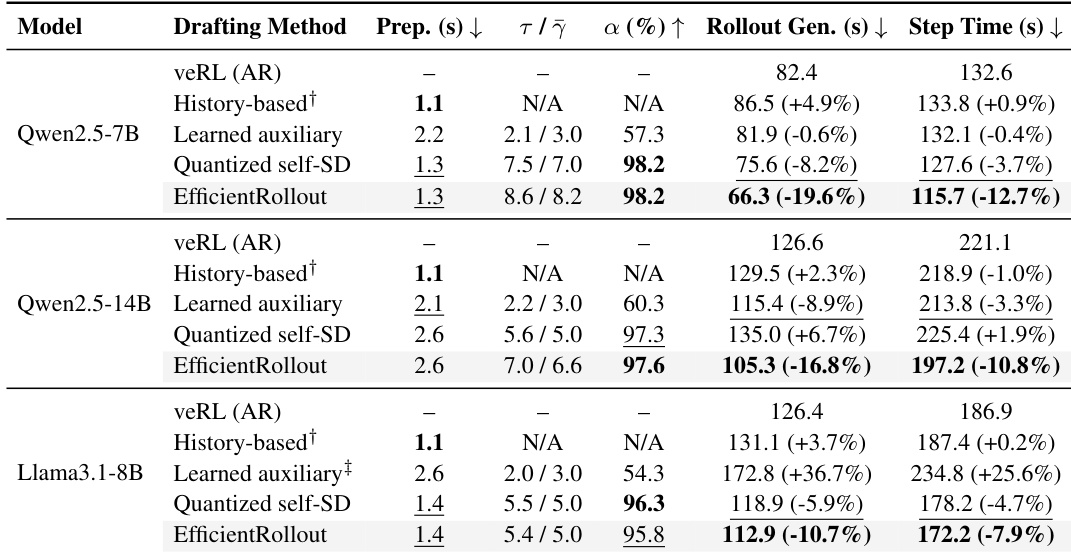
评估涵盖多种模型规模、草稿长度与序列范围,以验证开关策略、延迟分布、草稿生成效率及端到端训练加速效果。基于 roofline 的开关策略准确区分了有利与不利的推测解码配置,增加的草稿长度在规避高 batch 开销的同时扩大了性能增益。延迟与效率分解表明,验证时间始终高于预测时间,量化成本无论模型规模大小均可忽略不计,且自草稿生成器在不同条件下均能保持优于辅助方法的效率。综合来看,这些发现证实 EfficientRollout 通过降低 rollout 延迟并保持目标分布对齐,实现了显著的端到端训练加速,始终优于标准及推测解码基线。