Command Palette
Search for a command to run...
从自身错误中学习:构建用于自蒸馏的可学习微反思轨迹
从自身错误中学习:构建用于自蒸馏的可学习微反思轨迹
Zhilin Huang Hang Gao Ziqiang Dong Yuan Chen Yifeng Luo Chujun Qin Jingyi Wang Yang Yang Guanjun Jiang
摘要
自蒸馏通过利用模型自身的 rollout 作为训练信号来提升大语言模型的推理能力,通常采用隐式的 logit 层面对齐方法,以最小化向特权目标分布的 KL 散度。然而,由于此类监督信号源于无控制的采样过程,它无法为模型的具体错误提供诊断性洞察,也未能针对其特定的失败模式提供纠正指导。因此,模型仅学会模仿特权分布,而非获得能够精准定位推理失败位置与原因的细粒度纠正。本文提出轨迹增强策略优化(Trajectory-Augmented Policy Optimization, TAPO),将自蒸馏从隐式分布对齐推进至显式轨迹构建。在强化学习训练过程中,模型会对同一查询生成正确与错误的 rollout。TAPO 利用这种对比结构构建微反思纠正(micro-reflective corrections),即新型训练轨迹:保留模型直至失败节点前的错误推理过程,随后插入由同组采样中的正确参考所引导的自然语言诊断与纠正推理。由于每条轨迹均锚定于学习者自身的前缀与解法,相较于基于 KL 散度的方法所施加的位置级对齐,该纠正信号能在更大程度上保留模型的 on-policy 分布。为有效整合这些轨迹,TAPO 在模型能力边界引入了难度感知的候选选择机制,并采用解耦的优势估计以防止梯度污染。在 AIME 2024、AIME 2025 及 HMMT 2025 上的实验结果表明,在相同训练步数下,TAPO 相较于 GRPO 均实现了稳定且一致的性能提升。进一步分析表明,TAPO 同时增强了模型的首次推理能力与纠错有效性。
一句话总结
轨迹增强策略优化(TAPO)通过将正确与错误 rollout 进行对比,构建保留失败前推理过程、插入自然语言诊断并附加修正步骤的微反思轨迹,从而将自蒸馏技术从隐式 logit 对齐推向新高度,使模型能够学习针对性的错误修正,而非泛化的分布模仿。
核心贡献
- 本文提出轨迹增强策略优化(TAPO),这是一种自蒸馏框架,使用显式的轨迹构建替代隐式 logit 对齐。TAPO 将训练序列锚定在模型的错误推理前缀上,并附加源自组内正确解答的自然语言诊断与修正步骤。
- 该框架通过三种针对性机制解决了基于优势强化学习中的整合挑战。难度感知候选选择(Difficulty-aware Candidate Selection)通过在模型能力边界内定位问题来构建涌现式课程;解耦优势估计(Decoupled Advantage Estimation)防止膨胀的组奖励导致梯度污染;OOD token 抑制(OOD token Suppression)在处理分布外修正 tokens 时稳定优化过程。
- 在 AIME 2024、AIME 2025 和 HMMT 2025 基准上的评估表明,在相同的训练步数下,TAPO 相比 GRPO 和分布对齐基线始终取得一致的性能提升。直接解答率(Direct Solution Rate)与有效反思率(Effective Reflection Rate)的分析证实,微反思训练信号在无需推理阶段显式反思提示的情况下,同时提升了首轮推理准确率与自主错误修正能力。
引言
大语言模型通过带有可验证奖励的强化学习在复杂推理方面取得了显著进展,其中自蒸馏方法利用密集的 token 级监督信号将模型输出与已验证解答对齐。然而,先前的方法依赖于隐式分布对齐,将推理目标视为不可控的概率分布,仅压制错误而非教授恢复路径。为克服这些局限,本文作者利用模型自身的错误 rollout 构建显式的微反思轨迹,用于诊断错误并展示自然语言修正过程。将这些针对性信号整合到标准的基于优势的强化学习框架中,使模型能够在保持探索多样性与训练稳定性的同时,内化自主错误修正能力。
数据集

- 数据集构成与来源: 本文作者构建了一个包含 45,000 个示例的冷启动数据集,数据源自 DeepScaleR 数据集中约 40,000 个查询。
- 各子集关键细节: 数据划分为 30,000 个监督微调示例和 15,000 个指令跟随微调示例。所有初始响应均从 Qwen3-8B-Instruct 基础模型中采样生成。
- 处理与过滤规则: 本文作者将采样响应划分为正确组与错误组。仅从错误响应中生成微反思修正轨迹,并严格执行每个查询仅生成一条轨迹的限制。该流水线对输出进行结构化处理,以可靠地生成用于分析与重建阶段的特定 XML 风格标签。
- 模型中的使用方式: 本文作者在冷启动阶段联合训练这两种示例格式,以在强化学习开始前初始化模型。这种混合数据赋予策略模型指令跟随的可靠性与基础自我错误分析能力,有效防止严重的分布外 tokens 产生,并稳定后续训练中的修正信号传播。
实验
该评估在具有挑战性的数学推理基准上测试 TAPO,采用直接训练与冷启动初始化两种设置,并与标准强化学习基线进行对比。主要结果与能力内化分析证实,TAPO 真正实现了错误修正能力的内化,显著提升了首轮推理强度与反思恢复率,而非仅仅扩充训练数据。消融实验与训练动态分析表明,保留有效推理前缀、使用负样本进行对比优势估计,以及抑制分布外 tokens,对于稳定优化与分布对齐至关重要。综上所述,这些发现表明冷启动预对齐与精心构建的修正轨迹能够实现稳健的策略学习,在复杂数学任务上显著优于传统方法。
本文作者通过测量直接解答率与有效反思率,评估 TAPO 与 GRPO 的能力内化效果。数据表明,TAPO 在所有基准上均持续优于基线模型,展现出增强的首轮推理能力与更高效的错误修正能力。TAPO 在所有基准上的直接解答率均高于基线方法。与 GRPO 相比,TAPO 的有效反思率表现更优。推理与修正指标的提升在不同数据集中保持一致。

本文作者利用直接训练与冷启动初始化两种设置,在数学推理基准上将 TAPO 与 GRPO 及 OPSD 等基线方法进行对比。结果表明,采用冷启动初始化的 TAPO 在所有基准上均持续取得最高的 Pass@1 分数,展现出卓越的首轮推理能力。相比之下,直接训练的结果参差不齐,TAPO 在 AIME 2024 上表现优异,但在缺乏冷启动阶段预对齐支持的更具挑战性的基准上,性能不及 GRPO。采用冷启动初始化的 TAPO 在所有基准上均优于 GRPO 与 OPSD,并取得最佳 Pass@1 分数。冷启动阶段对 TAPO 至关重要,因为与 GRPO 相比,直接训练会导致在更难基准上的性能下降。TAPO 在不同 Pass@k 值下均能维持性能增益,表明其实现了稳健的能力提升而非单纯的方差降低。
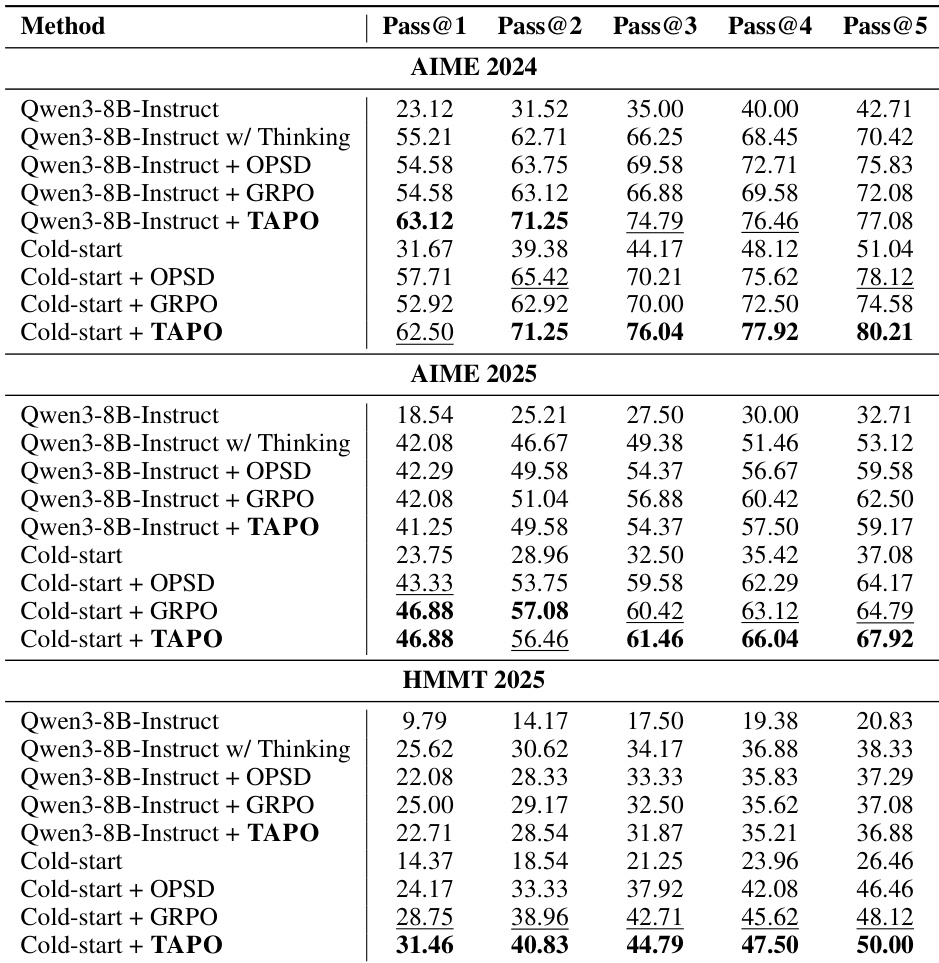
本文作者在三项数学推理基准上,将 TAPO 方法与冷启动基线及多种消融变体进行对比。结果表明,完整 TAPO 配置持续优于基线模型及所有部分配置。集成所有组件可在所有 Pass@k 设置下获得最高的性能指标。完整 TAPO 配置在所有基准与 Pass@k 指标上均持续取得最高分数。消融研究揭示,移除 OOD token 抑制或负样本等组件会导致性能低于完整方法。冷启动基线的准确率最低,随着各组件的逐步加入,其作为性能渐进提升的基础。

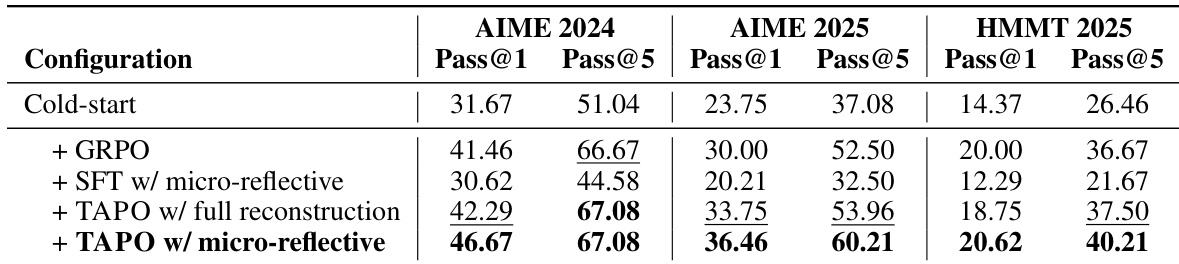
本文作者在三项数学推理基准上,将 TAPO 方法与冷启动、GRPO 及 SFT 等基线进行对比。结果表明,采用微反思轨迹构建的 TAPO 持续取得最高性能,超越标准强化学习与监督微调方法。消融研究强调,在修正过程中保留部分推理路径比完全重建更为有效,凸显了增量错误修正的价值。采用微反思构建的 TAPO 在所有测试基准上均持续优于 GRPO 与 SFT 基线。修正期间保留有效推理前缀比从头生成完整解答更能取得优异结果。该方法在具有挑战性的基准上展现出稳健的提升,尤其在难度最高的数据集上取得显著增益。
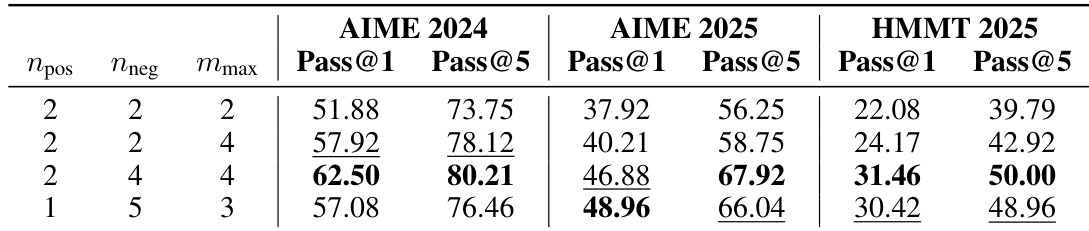
本文作者研究了 ZPD 阈值参数与最大构建数量对模型性能的影响。默认配置展现出稳健的有效性,在 AIME 2024 与 HMMT 2025 上锁定 Pass@1 最高性能,并在所有基准上取得最佳的 Pass@5 结果。默认参数配置在 AIME 2024 与 HMMT 2025 上获得最高的 Pass@1 分数。更为严格的阈值设置被证明对 AIME 2025 基准最为有效。降低最大构建数量会导致性能明显下滑,凸显了构建规模的重要性。
本文作者跨数学推理基准,将 TAPO 与多种强化学习及监督基线进行对比,采用直接训练、冷启动初始化、消融研究与超参数调优来验证其核心设计原则。结果表明,TAPO 在初始推理准确率与后续错误修正方面均持续优于竞争方法,且冷启动初始化被证明对维持复杂任务的性能至关重要。组件分析证实,与完全重建或部分配置相比,在优化过程中保留部分推理路径并集成所有架构组件能够带来最稳健的性能提升。最终,实验确立 TAPO 通过其结构化初始化与增量修正机制,实现了可靠的能力增强。