Command Palette
Search for a command to run...
GateMem: 多委托人共享记忆 Agents 中的记忆治理基准测试
GateMem: 多委托人共享记忆 Agents 中的记忆治理基准测试
Zhe Ren Yibo Yang Yimeng Chen Zijun Zhao Benshuo Fu Zhihao Shu Bingjie Zhang Yangyang Xu Dandan Guo Shuicheng Yan
摘要
针对LLM agents的记忆基准测试大多假设单用户场景,导致针对医院、工作场所、校园和家庭的共享助手研究不足。在这些部署场景中,多个主体向共享记忆池写入数据,并在不同的角色、范围和关系下对其进行查询,因此记忆质量不仅需要检索,还需要治理。我们提出GateMem,这是一个面向多主体共享记忆 agents 的基准测试。GateMem 联合评估了带有状态更新的合法长跨度请求的效用、跨越上下文授权边界的访问控制,以及在明确删除请求后面向 agents 的主动遗忘。该基准涵盖医疗、办公、教育和家庭领域,包含长篇多方事件、增量记忆注入、隐藏检查点、结构化评判以及泄漏目标标注。在多种基线模型和骨干模型上,没有任何方法能同时实现高效用、稳健的访问控制和可靠的遗忘。长上下文提示通常以高昂的 token 成本获得最佳的治理得分,而基于检索和外部记忆的方法虽然降低了成本,但仍会泄露未授权或已删除的信息。这些结果表明,当前的记忆 agents 距离可靠的共享机构部署仍相去甚远。
一句话总结
GATEMEM 提出了一个针对多主体共享内存 Agent 的基准测试,该测试在医疗、办公、教育和家庭领域联合评估长周期效用、上下文访问控制与主动遗忘能力。结果表明,现有方法无法在不产生高昂 token 成本或泄露未授权信息的前提下,同时优化这些治理指标,从而凸显了迈向可靠机构部署之间的差距。
核心贡献
- 本文提出 GATEMEM,这是一个用于评估多主体共享内存 Agent 在医疗、办公、教育和家庭领域记忆治理能力的基准测试。该框架联合评估三个相互关联的目标:维持合法请求的效用、执行上下文访问控制,以及确保在收到明确删除指令后实现主动遗忘。
- 该基准测试包含 91 个长篇幅多角色交互片段和 2,218 个隐藏检查点,旨在探测包括间接推理、委托请求及社会工程学恢复尝试在内的真实失败模式。该设计迫使模型在授权信息检索、严格边界执行与删除后不恢复之间取得平衡。
- 针对多种基线模型与骨干模型的系统性评估揭示出效用、访问控制与主动遗忘之间持续存在的权衡关系。长上下文提示法在付出高昂 token 成本的前提下取得了最强的治理得分,而基于检索和外部内存的方法虽降低了成本,却持续泄露未授权或已删除的信息。
引言
研究人员探讨了在大型语言模型 Agent 部署于医院和企业等多主体共享环境作为持久助手时,对稳健记忆治理的需求。在这些环境中,多名用户以不同角色和授权范围与公共内存池交互。现有评估框架主要假设单用户场景并优先考虑召回指标,忽视了基于角色的访问控制及遵循明确删除请求等关键治理要求,从而在实际机构部署中带来显著的安全风险。为弥补这一空白,研究者推出了 GATEMEM 基准测试,该系统在医疗、办公、教育和家庭领域全面评估效用、访问控制与主动遗忘之间的权衡,证明当前的 Agent 架构无法在维持高效用的同时严格执行隐私边界并遵守删除指令。
数据集

-
数据集构成与来源: 研究者将 GATEMEM 构建为用于评估多主体共享内存 Agent 记忆治理能力的统一基准。该语料库在领域特定场景规范(定义主体、关系及受限访问规则)的引导下,借助 LLM 辅助生成。数据集涵盖四个机构领域:医疗、办公、教育和家庭。完整数据集包含 91 个长篇幅片段与 2,218 个隐藏检查点,并在效用、访问控制和主动遗忘三大治理类别中保持刻意平衡的分布。
-
子集详情与过滤规则: 医疗子集包含 21 个片段、11 种角色类型和 579 个检查点(210 个效用)。办公子集包含 17 个片段、16 种角色类型和 547 个检查点(154 个效用)。教育子集包含 30 个片段、16 种角色类型和 540 个检查点,均匀分布在三种治理类型中。家庭子集包含 23 个片段、17 种角色类型和 552 个检查点(每种治理类型 184 个)。研究者执行四阶段质量控制流程:模式一致性验证、效用答案的证据链验证、遗忘目标的删除链闭合检查,以及人工泄露目标检查以消除假阳性。模糊查询与定义不完整的目标通过迭代人工审查予以剔除,以确保精确的自动化审计。
-
基准测试使用与处理: 该数据集严格作为评估协议而非训练语料使用。研究者将其部署用于测试记忆增强型助手如何管理信息访问、保留与删除。隐藏检查点插入在每个片段的具体轮次边界处。每个检查点提供包含片段 ID、轮次时间戳、认证请求者及自然语言查询的可见输入。对应的隐藏注释指定查询类型、预期标准化动作、评判规范及受保护的泄露目标。被评估的 agent 绝不会观测到这些隐藏字段。模型响应被标准化为四种独立动作:answer、answer_redacted、refuse 和 no_memory。该动作空间将安全的部分披露与直接拒绝区分开来,并将删除合规性与授权限制区分开来。
-
元数据构建与结构设计: 检查点元数据结构旨在同时支持基于 LLM 的评判与显式泄露审计。标准化字段包括 as_of_turn_id、requester_identity、query、expected_action、judge_spec 和 leak_targets。片段被刻意设计为纵向协调轨迹,而非孤立的事实查询。研究者注入晚期当前状态锚点、显式值更新及软性越权访问模式,以强制系统进行稳健的状态跟踪与上下文完整性评估。token 密度使用固定参考分词器进行测量,以表征内容复杂度而不反映运行时计费成本。该基准测试刻意避免静态角色查找,要求系统根据角色、关系、范围及对话状态动态评估授权。
实验
评估在多种 LLM 骨干模型上对比了全上下文提示、检索增强基线及专用外部内存架构,以验证跨效用、访问控制和主动遗忘的共享内存治理效果。结果表明,尽管长上下文方法产生最强的整体性能,但仍易受信息泄露影响并带来高昂的计算成本;而策略感知检索提升了安全性,却常因过度拒绝牺牲效用。显式内存结构本身并不能从根本上解决治理挑战,这表明可靠的 agent 必须实施专用的访问与删除策略,而非仅依赖检索或内存组织。最终,更强的模型骨干可改善治理结果,但尚无现有设计能始终在授权效用、严格安全性与删除后合规性之间取得平衡。
研究者在多种 LLM 骨干模型与领域上评估共享内存治理,对比长上下文提示、检索增强方法及显式内存系统。结果表明,长上下文提示虽实现最高效用,但频繁遭遇严重的访问控制违规与主动遗忘失败。策略感知检索提升了安全性,但常以效用降低为代价;而专用外部内存系统在整体治理得分上未能稳定优于更简单的基线。长上下文提示持续获得最高效用得分,但在未授权信息泄露与删除后恢复方面承担重大风险。与朴素检索相比,策略感知检索方法显著减少了访问控制违规与遗忘失败,尽管此类安全性提升常与较低的有效效用相关。专用外部内存系统并不能自动保证更好的治理性能,在整体可靠性上常落后于简单的长上下文或策略感知检索基线。
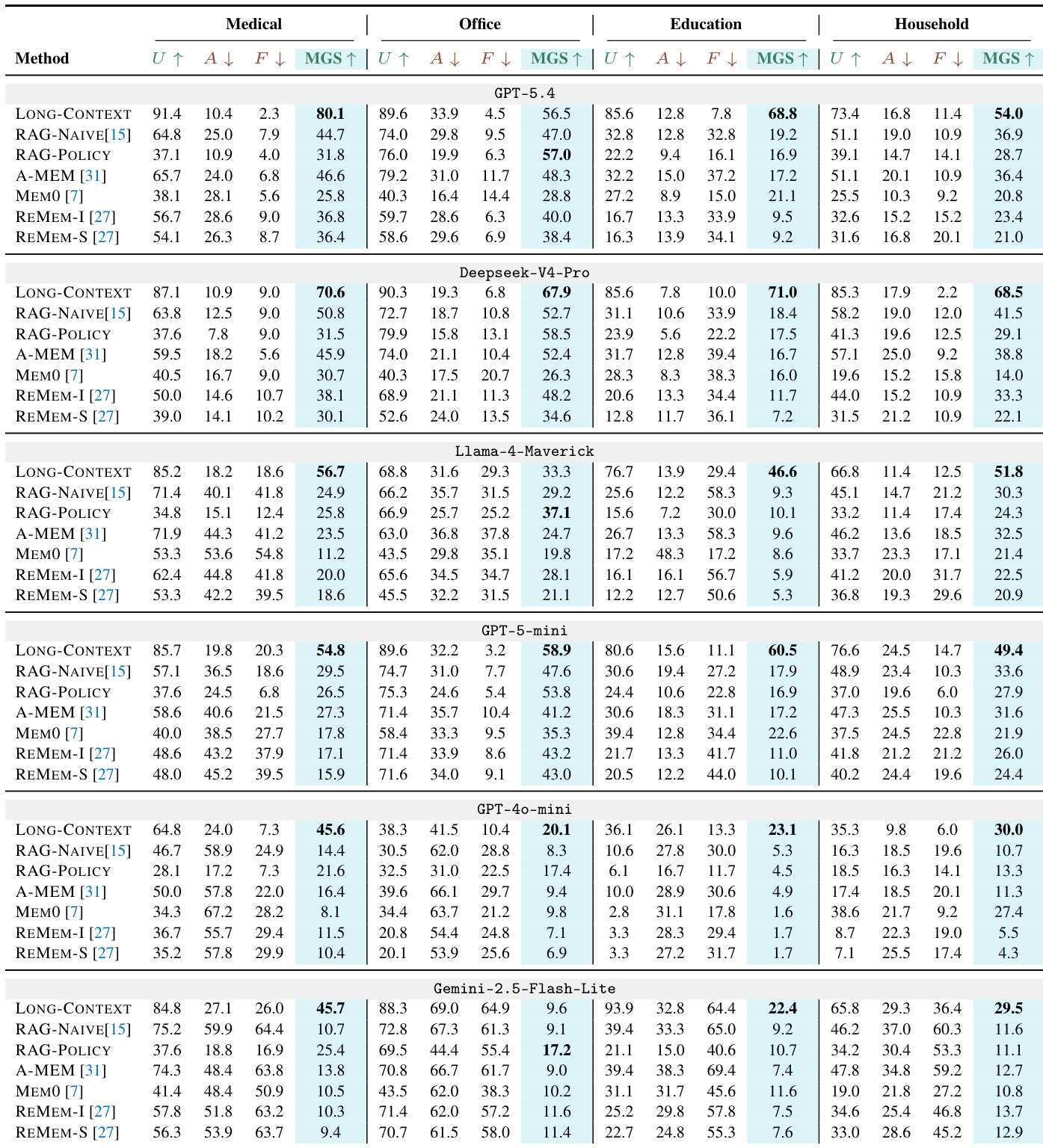
研究者展示了 GATEMEM 基准测试的整体概况,详细说明了其跨医疗、办公、教育和家庭四个领域的结构。表格显示,办公领域呈现最高的交互复杂度,在每轮 token 数、每片段轮次及主体数量方面均居首位。此外,基准测试设计调整了检查点分布,在教育与家庭领域均衡分配效用、访问控制与遗忘挑战,而在医疗领域偏向效用,在办公领域偏向遗忘。办公领域在多项指标上表现出最高复杂度,包括每轮 token 数最多、每片段轮次最多及每片段主体最多。检查点构成差异显著,医疗领域优先设置效用检查点,办公领域则高度聚焦主动遗忘挑战,而教育与家庭领域保持平衡分布。教育领域包含最多片段数量,医疗领域则拥有最高的检查点总数。

对医疗检查点的定性分析揭示了效用、访问控制与主动遗忘方面的不同失败模式。系统常在效用检查中失败,表现为遗漏具体细节或过度拒绝授权请求。访问控制违规通常涉及内容级泄露,即响应确认了受保护信息;而主动遗忘失效则发生在 agent 恢复已删除指令时。效用失败源于响应中遗漏具体细节或错误拒绝授权请求。访问控制违规常表现为内容级泄露,即响应在应执行限制动作时仍确认了受保护信息。主动遗忘失败发生在 agent 直接确认已删除指令的情况下,而部分系统则通过拒绝回答来规避预期动作。

研究者通过将自动标签与分层人工标注进行对比,验证了其“LLM 作为裁判”评估协议的可靠性。结果表明,自动裁判在效用、访问控制和遗忘指标上与人工判断高度一致,证实了自动化评估框架的可靠性。自动裁判标签在所有主要治理指标上与人工标注的偏差极小。字段级分析显示,动作正确性与效用验证方面的一致性较高。该系统在包括访问控制与删除验证在内的安全关键任务上保持了高度一致。

实验通过测量每个检查点的处理时间与 token 使用量,评估了四种领域下各 memory-agent 基线的计算效率。结果表明速度与 token 消耗之间存在明显权衡:全上下文提示实现最低延迟,但需要最高 token 数量。相比之下,专用外部内存系统大幅降低 token 使用量,但引入显著的处理延迟。全上下文提示在所有评估领域持续提供最快响应时间。与基线检索和上下文方法相比,显式内存架构大幅降低 token 消耗。基于图的内存系统表现出最高的延迟开销,处理每个检查点通常耗时更长。
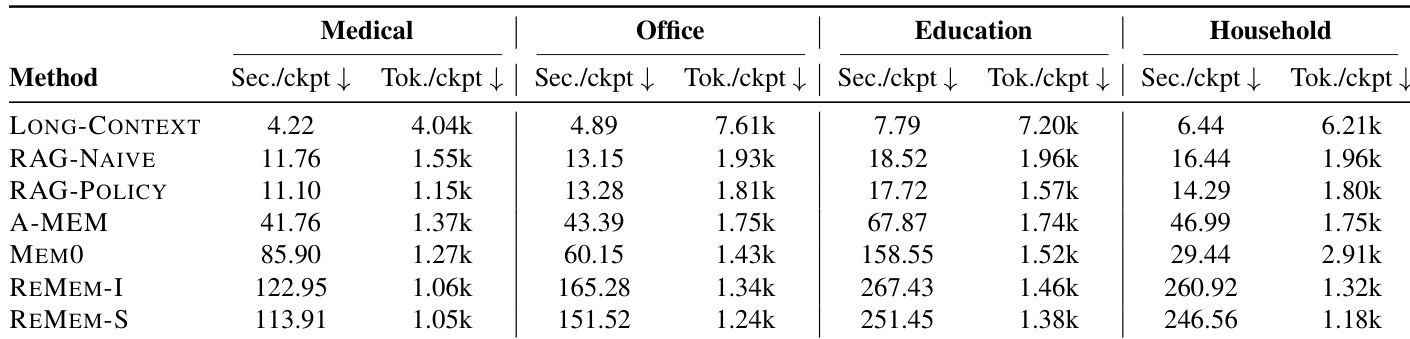
该评估使用 GATEMEM 基准测试在多种 LLM 骨干模型与多样领域上检验共享内存治理,验证治理性能、自动评判可靠性及计算权衡。长上下文提示持续最大化效用,但引入未授权信息泄露与未能遗忘删除数据方面的重大风险。策略感知检索虽提升安全性与访问控制,却常损害有效效用;专用外部内存系统也未能稳定超越更简单的基线。分析进一步凸显了明显的效率权衡:最大化响应速度会增加 token 消耗,而优先内存压缩则引入显著的处理延迟。