Command Palette
Search for a command to run...
Guava:一种有效且通用的具身操作框架
Guava:一种有效且通用的具身操作框架
Haowen Liu Xirui Li Shaoxiong Yao Peng Shi Tianyi Zhou Jia-Bin Huang Furong Huang Jiayuan Mao
摘要
在大规模视觉-语言数据上训练的模型在具身 agents 方面展现出强大的潜力。通过具身工具使用来调用模型,通过将高层推理与用于感知、规划和控制的外部模块相结合,为端到端视觉-语言-动作系统提供了一种极具前景的替代方案。然而,目前尚不清楚何种设计能构成用于具身操作的有效 harness,以及此类 harness 在多大程度上能够激发广泛推理模型的具身能力。在本研究中,我们提出了 Guava,这是一个用于具身工具使用的 harness 框架。该框架通过对 agent 工作流、动作空间和观察空间的设计空间进行系统探索而构建。我们的研究确定了有效具身 agents 的三个关键要素:迭代式感知-推理-动作循环、语义动作抽象以及多模态观测。为探究这些设计原则是否对小模型同样普适,我们开发了一套端到端训练流水线,利用完全在仿真环境中收集的不足 2K 条轨迹,将具身操作能力蒸馏至一个 4B 开源模型中。在仿真与真实世界环境中的实验结果表明,该模型的性能可与前沿专有模型相媲美,同时对未见过的物体、新指令及长程任务展现出强大的泛化能力。研究结果表明,设计精良的 harness 可作为具身操作的可扩展且与模型无关的接口,仅需极少的训练数据,即可使紧凑型开源模型具备强大的涌现式具身能力。
一句话总结
Guava 是一个面向具身操作的 harness 框架,它利用迭代感知-推理-动作循环、语义动作抽象和多模态观测,将能力蒸馏至一个 4B 开源模型中。该框架仅使用不到 2K 条模拟轨迹,即可达到与前沿闭源模型相当的性能,并在模拟和真实环境中对未见物体、新指令及长视距任务展现出强大的泛化能力。
核心贡献
- 本文提出 Guava,一个面向具身工具使用的模块化 harness 框架。该框架系统性地探索 agent 工作流、动作空间与观测空间,以弥合高层推理与外部感知及控制模块之间的差距。
- 研究确定了实现有效操作的三个核心设计原则:迭代感知-推理-动作循环、语义动作抽象以及多模态观测,这些原则使得显式计划检查与持续故障恢复成为可能。
- 一种数据高效的训练流水线将这些能力蒸馏至一个 4B 开源模型中,仅使用不到 2,000 条模拟轨迹,即可达到与前沿闭源模型相当的性能,同时在模拟和真实环境中泛化至未见物体、新指令及长视距任务。
引言
大型视觉语言模型为具身操作提供了极具前景的基础,然而端到端的视觉-语言-动作策略在数据效率和跨环境可扩展性方面仍面临重大挑战。现有的基于 harness 的方法通常依赖于单次程序生成或专用流水线,这不仅限制了稳健的长视距规划与故障恢复能力,还依赖于昂贵的前沿模型。作者基于这些观察开发了 Guava,一个通用的 harness 框架,通过迭代感知-推理-动作循环、语义动作抽象和多模态观测来优化具身工具使用。通过将该架构与数据高效的训练流水线相结合,研究证明紧凑的开源模型能够匹配前沿性能,并仅使用不到 2,000 条模拟轨迹就展现出强大的泛化能力与真实世界迁移能力。
数据集
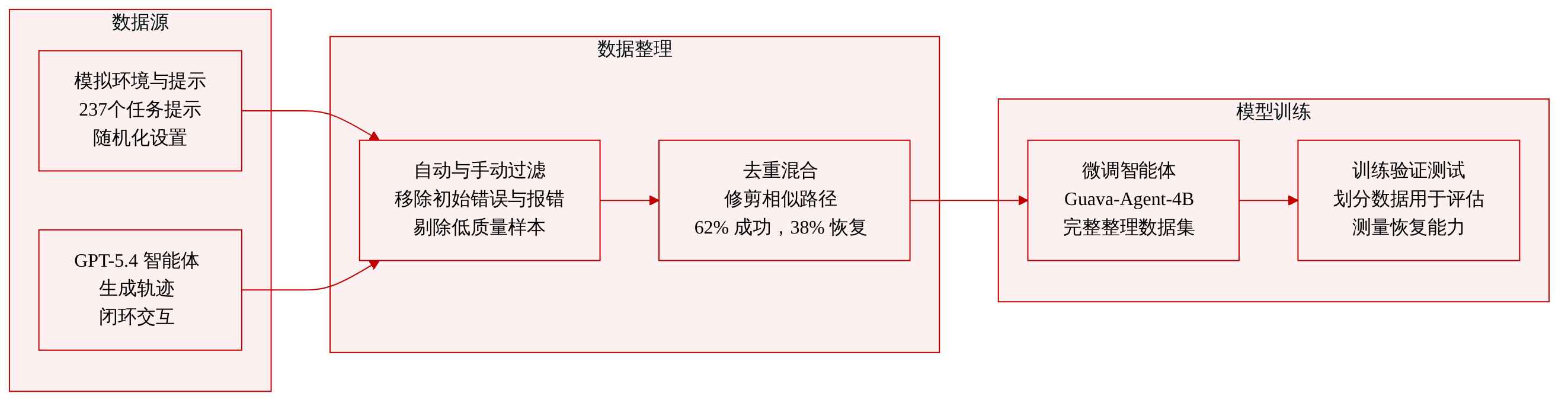
-
数据集构成与来源:作者通过在 RoboSuite 仿真环境中部署 Guava harness 框架并结合 GPT-5.4 来构建数据集。标准化的 API 通过向模型暴露场景观测、动作执行和 episode 级反馈,实现了闭环交互。
-
子集详情:
- 成功轨迹:包含 1,191 个 episode(占数据集的 62%),由 237 个独立任务提示生成。作者在生成过程中随机化姿态、光照和相机视角等环境参数以提升多样性。
- 恢复轨迹:包含剩余的 743 个 episode(占 38%)。这些轨迹通过向成功 rollout 中注入预定义的仿真错误(如抓取失败、物体掉落或对齐偏差)生成,或通过采样随机中间状态强制模型进行恢复。
-
数据使用与混合比例:作者使用完整的精修数据集对 Guava-Agent-4B 进行微调。训练混合数据按 62% 成功与 38% 恢复的比例构建,以平衡基线性能与错误恢复能力。
-
处理与质量控制:作者采用多阶段数据精修流水线以确保质量并减少偏差。初始过滤自动移除包含无效工具参数或仿真初始化不佳的 episode。人工复核步骤剔除包含无关对话或过度自我反思的低质量样本。最后,作者对高度相似的轨迹进行去重,以防止对特定提示或执行模式过拟合,并将相同的过滤规则应用于恢复数据。
方法
作者介绍了 Guava,一个 harness 框架,该框架将具身操作从开环预测问题转化为基于现实的闭环交互过程。该框架通过整合迭代推理、语义动作抽象和多模态观测来实现稳健的性能。系统通过感知-推理-动作循环运行,模型根据新观测持续更新计划,从而能够从抓取失败和状态偏差中恢复。

设计的关键组件是语义动作空间,它将底层几何与物理推理委托给底层控制器。VLM 不输出原始关节坐标,而是使用一组预定义工具发布面向任务的命令。这些工具包括 grasp(object) 和 release() 等高层动作,以及 align(object, position, clearance) 等定位基元。align 函数接受来自集合 {top,left,right,front,back} 的位置参数和来自 {small,medium,large} 的间隙参数,使 agent 能够在无需直接管理精确 3D 坐标的情况下推理物体间的关系。与需要显式几何规划的底层接口相比,这种抽象显著提升了性能。
为将这些具身能力迁移至紧凑的开源模型,作者开发了一种数据高效的训练流水线,从前沿 VLM 中蒸馏行为。该流程始于一个数据生成引擎,用于在仿真环境中收集交互轨迹。该引擎利用场景随机化和定向误差扰动生成多样化示例,不仅包括成功完成的轨迹,还包括模型学习纠正执行失败的恢复轨迹。
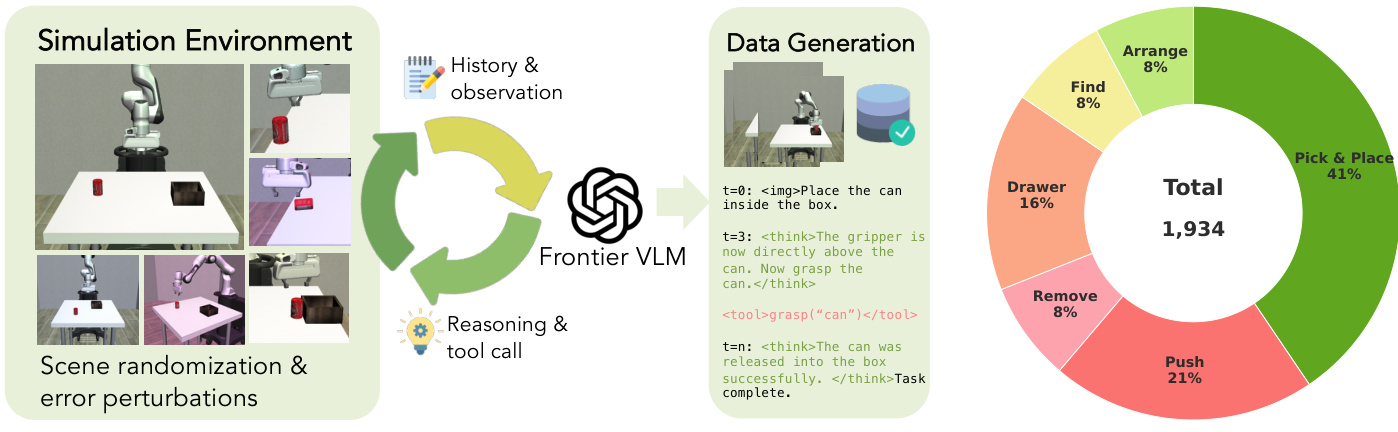
训练流水线采用两阶段方法来优化策略。首先,在收集的数据集上执行监督微调,该数据集结合成功演示与恢复场景,以教授操作技能与错误纠正。随后,采用稀疏任务成功奖励应用组相对策略优化(GRPO)。该强化学习阶段战略性地聚焦于最具挑战性的长视距任务,以提升序列规划与适应能力,同时避免在简单任务上产生过高的计算成本。
实验
评估设置在一套 Robosuite 仿真环境与实体 Franka 机械臂上,针对分布内与分布外的多种长视距操作任务测试蒸馏后的 4B 参数 VLM。实验验证了该紧凑模型在真实世界部署中能够匹配前沿闭源系统,表明具身工具使用行为可以从极少的仿真数据中有效迁移。进一步的消融实验证实,强化学习后训练与持续闭环执行对于稳健的长视距推理、错误恢复及涌现的状态感知至关重要,同时也暴露出在精确空间理解方面仍存在的局限性。总体而言,结果表明 agent 规划通过解耦高层语义推理与底层控制,成功弥合了仿真与现实之间的差距。
图表比较了 GPT-5.4 与 Guava-Agent-4B 在各类操作任务中每个 episode 的 token 消耗量。与 GPT-5.4 基线相比,Guava-Agent-4B 完成任务通常所需的 token 更少,且这一差异在总体平均值中最为显著。这表明紧凑模型在大幅降低计算开销的同时实现了相当的行为表现。在大多数独立任务中,Guava-Agent-4B 每个 episode 使用的 token 均少于 GPT-5.4。Guava-Agent-4B 的整体 token 效率显著高于 GPT-5.4 模型。尽管在特定长视距场景中存在微小波动,但该效率优势在各类任务复杂度中均得以保持。

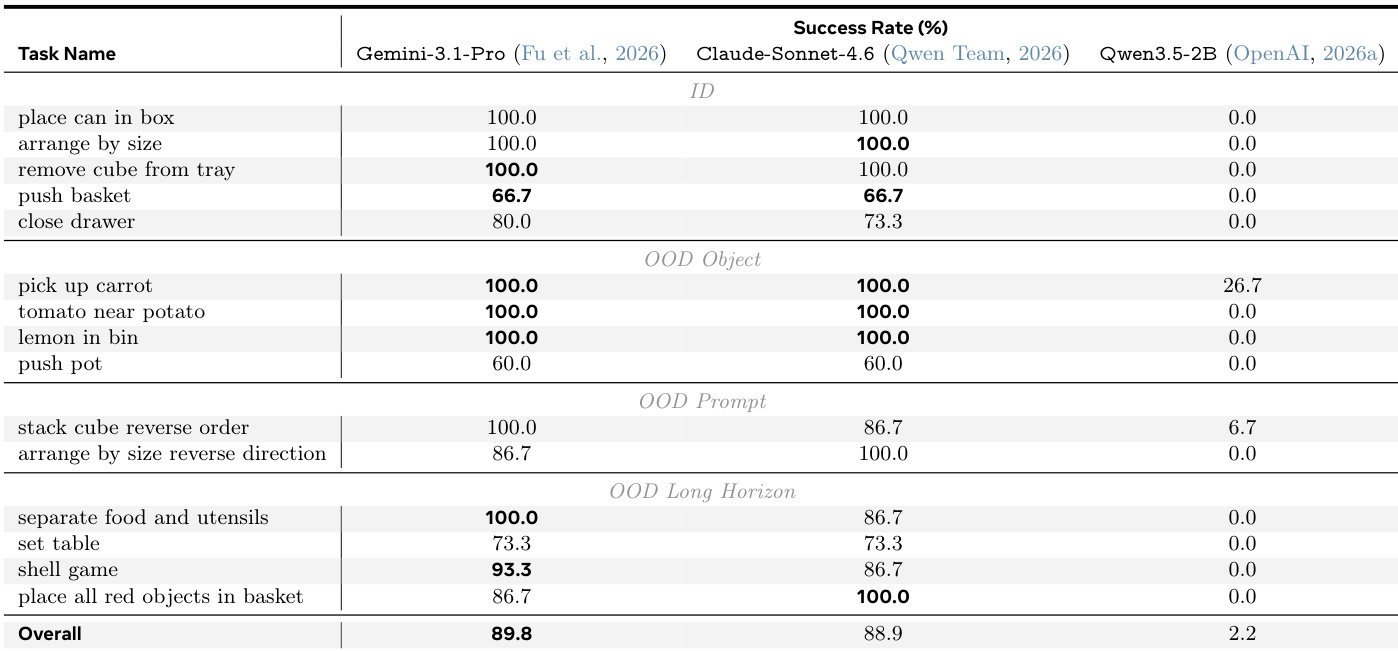
实验在不同操作任务上评估了搭载不同基础模型的 Guava harness。结果表明,大型前沿模型在分布内与分布外场景中均能保持较高的成功率,而较小模型因指令遵循与工具调用问题表现出较差的性能。大型前沿模型在处理包括复杂长视距序列在内的各类任务时展现出稳健的能力。较小模型在所有任务类型中均持续失败,凸显了其在指令遵循与工具选择方面的局限性。与其他被评估模型相比,Gemini-3.1-Pro 通常实现最高的整体成功率。
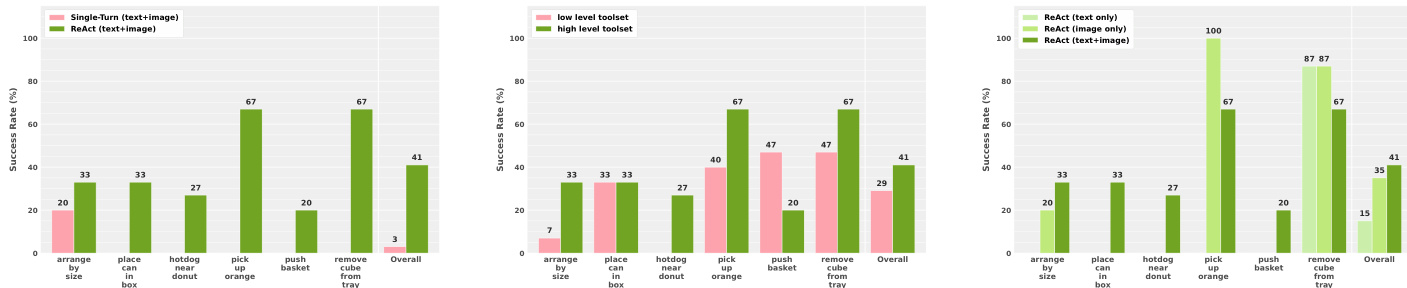
实验评估了用于具身操作的 Guava 框架,结果表明闭环 ReAct 规划显著优于单轮方法。高层工具集通常能提升拾取物体等复杂任务的性能,而底层工具在推挤等特定动作上更为有效。此外,视觉输入至关重要,与多模态图文输入相比,纯图像输入在特定空间任务中取得了更优的结果。闭环 ReAct 执行在整体成功率上显著优于单轮规划。高层工具集提升了拾取橘子和移除立方体等任务的性能,而底层工具更适合推挤操作。与多模态图文输入相比,纯图像输入在特定空间任务中实现了更优的性能。
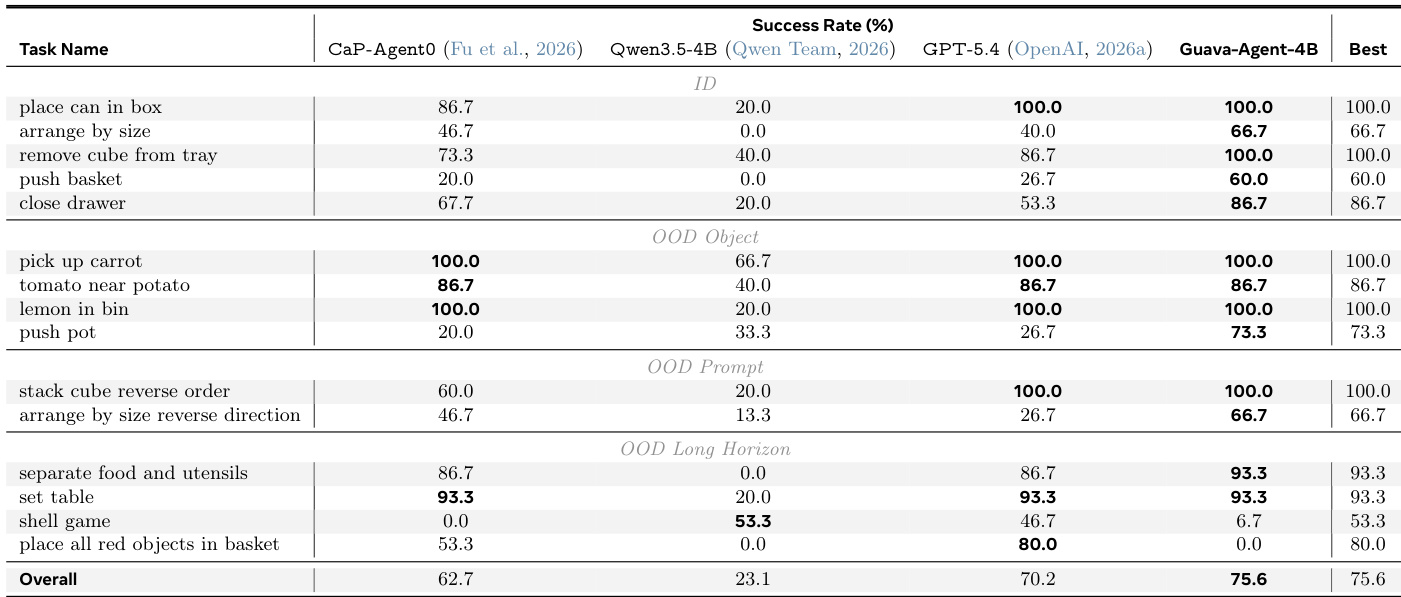
实验在一系列具身操作任务中将 Guava-Agent-4B 与多个基线模型进行了对比评估。结果表明,Guava-Agent-4B 取得了最高的整体成功率,通常优于闭源 GPT-5.4 模型及同期的 CaP-Agent0。基础 Qwen3.5-4B 模型表现出显著较低的性能,凸显了所提出蒸馏 harness 的有效性。在各类任务中,Guava-Agent-4B 均展现出优于闭源与开源基线的整体性能。该模型有效泛化至分布外场景,在涉及未见物体与新指令的任务中保持了较高的成功率。训练后的 Guava-Agent-4B 与未训练的基础 Qwen3.5-4B 模型之间存在显著的性能差距,凸显了训练过程的影响。
实验在多样化的具身操作任务中评估了 Guava 框架及其蒸馏后的 agent,验证了训练 harness、规划架构、工具选择策略及计算效率的有效性。定性评估表明,闭环 ReAct 规划始终优于单轮方法,而专用的高层与底层工具集有效优化了复杂物体操作与精确物理交互。此外,蒸馏模型在未见场景上实现了稳健的泛化,与大型闭源基线相比大幅降低了计算开销,且纯图像输入被证明对空间推理极为有效。总体而言,研究结果证实,所提出的框架使紧凑模型无需依赖庞大的前沿架构,即可实现卓越的任务成功率与效率。