Command Palette
Search for a command to run...
SAE 干预并不可靠:干预后抑制行为的恢复
SAE 干预并不可靠:干预后抑制行为的恢复
Mingyue Cui Linghui Shen Xingyi Yang
摘要
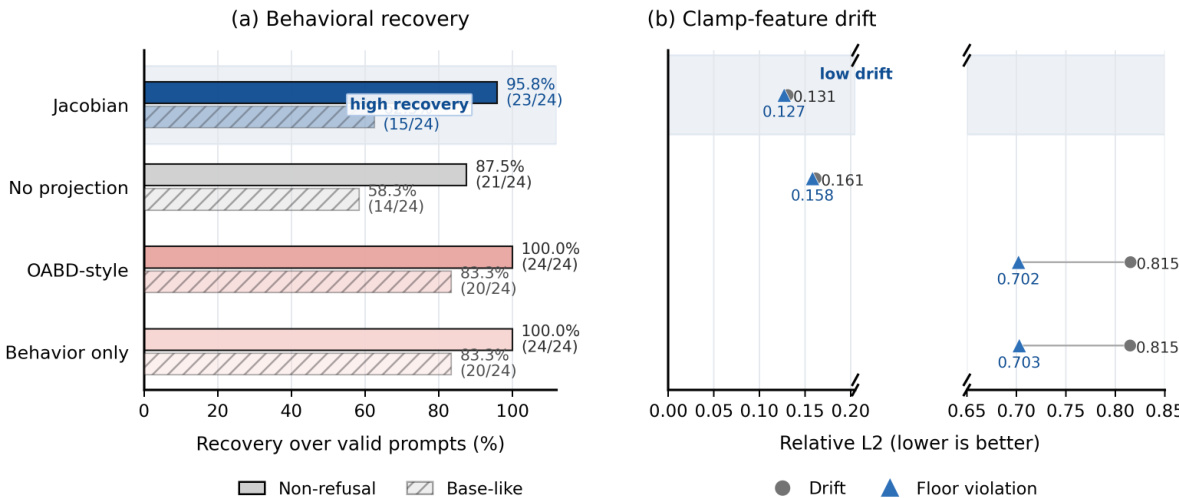
稀疏自编码器(SAEs)将残差流激活分解为可解释的特征。近期的潜在空间防御方法日益依赖这些分解,其假设是已识别的“不安全”SAE特征可作为用于监控和干预的可操作抓手。在此范式下,钳制特定的有害特征被认为能够可靠地防止模型出现不良行为。然而,我们表明,这种成功可能掩盖了一种可恢复的失效模式:钳制操作可能阻断通往该行为的一条可见路径,但并未消除行为本身。我们将此脆弱性表述为干预后恢复,这是一个受约束的残差空间优化问题。从干预后的残差状态出发,我们优化残差扰动以恢复干预前的行为,同时保持目标SAE特征在干预后的值不变。即使在强威胁模型下(即干预在优化和生成过程中始终保持激活状态),恢复仍然可行。为排除恢复仅仅是撤销干预的可能性,我们在单层干预中使用编码器正交更新,并在跨层设置中使用相应的特征图雅可比矩阵。在TPP、遗忘学习、IOI和拒绝引导实验中,尽管特征级干预取得成功,但此项压力测试仍揭示了可恢复的行为。特别是在对安全至关重要的拒绝引导设置中,我们在有效样本上实现了95.8%的恢复率,同时将受防御特征的相对漂移控制在0.131,显著低于基于后缀的基线方法。恢复路径的归因分析进一步将这种恢复定位到SAE的重构残差,即SAE未能解释的组件。这些结果揭示了特征级控制与行为完整性之间的差距:SAE特征可以支持因果干预,但控制它们并不能保证对底层行为的控制。
一句话总结
作者证明,钳制不安全稀疏自编码器(SAE)特征无法可靠地抑制有害模型行为,因为残差扰动可以在保留钳制特征的同时恢复目标行为。作者将这一漏洞形式化为“干预后恢复”(post-intervention recovery),并通过约束残差空间优化(采用编码器正交更新与特征映射雅可比矩阵)进行验证,从而揭示了潜在空间防御机制的脆弱性。
核心贡献
- 本文识别出稀疏自编码器防御中的干预后恢复漏洞,证明钳制目标特征往往无法永久抑制行为,因为模型可以通过未监控的残差方向绕过干预。
- 该研究将干预后恢复表述为约束残差空间优化问题,在保持受保护特征值不变的前提下恢复干预前的行为。该框架在单层干预中使用编码器正交更新,在跨层设置中使用特征映射雅可比投影,以确保恢复过程不会简单地逆转原始钳制操作。
- 在 TPP、遗忘学习、IOI 和拒绝引导基准上的评估表明,该优化在安全关键引导场景中实现了 95.8% 的恢复率,同时保持受保护特征相对漂移为 0.131,显著低于基于后缀的基线方法。归因分析进一步将绕过机制定位到 SAE 重建残差中,凸显了特征级控制与行为完整性之间的根本差距。
引言
稀疏自编码器(SAE)正被越来越多地用于将神经网络激活分解为可解释的特征,从而实现潜在空间的安全干预,通过钳制有害信号来引导模型行为。该方法对 AI 对齐具有重要意义,因为它提供了一种直接的特征级机制来监控和抑制不良输出。然而,先前的防御措施基于一个假设:固定目标特征即可保证行为控制,却忽略了模型如何通过相关方向重新分配因果信息,或将其隐藏于未解释的重建残差中。作者提出“干预后恢复”作为诊断框架,以严格检验这一假设。通过将挑战表述为约束优化问题,他们系统性地搜索能够在保持受保护特征不变的情况下恢复被抑制行为的残差扰动。其在多个引导和遗忘学习基准上的结果表明,模型经常通过零空间更新绕过钳制,揭示了特征级控制与完全行为安全之间的根本差距。
数据集
- 提供的文本仅包含作者姓名、单位及联系方式,未包含任何数据集信息。
- 请分享涵盖数据集构成、来源、过滤规则、处理步骤及模型使用的相关论文段落,以便撰写所需的描述。
方法
作者提出了一种诊断框架,用于评估稀疏自编码器(SAE)特征干预是作为完全的行为瓶颈,还是仅作为局部因果控制手柄。该方法的核心在于干预后恢复机制,用于测试在保持活跃特征钳制的同时,被抑制的行为是否得以恢复。架构的核心是一个配备第 ℓ 层 SAE 的 Transformer 语言模型 M。SAE 通过编码器 Eℓ 将残差流激活 hℓ(x)∈RT×d 编码为稀疏潜在特征 zℓ(x),并通过解码器 Dℓ 重建激活:
zℓ(x)=Eℓ(hℓ(x)),h^ℓ(x)=Dℓ(zℓ(x)).zℓ(x) 的坐标代表不同的 SAE 特征,从而实现了对特定潜在维度的精确隔离与操作。
为实施行为抑制,该框架实现了特征级干预,选择目标特征集 S 并将其激活钳制为受保护值 cS。该方法并未丢弃重建误差,而是保留 SAE 重建残差以维持模型连续性。受保护的残差状态计算如下:
hℓdef(x)=Dℓ(clampS(zℓ(x);cS))+(hℓ(x)−h^ℓ(x)).该公式确保钳制特征保持在 cS,同时未解释的残差分量继续在网络中传播。评估协议将恢复测试限制在有效翻转集内,该集合仅包含基础模型表现出目标行为但钳制干预成功抑制它的输入序列。此条件保证仅在存在可恢复的被抑制行为时才进行恢复测量。
恢复过程搜索一个约束扰动 δx,将其添加到受保护状态后可恢复目标行为且不违反钳制条件。为归因成功恢复的来源,作者引入了恢复路径分解模块。受保护状态 hℓdef(x) 与恢复状态 hℓrec(x)=hℓdef(x)+δx 均通过 SAE 编码以计算特征级变化 δz。随后,该框架将 δz 划分为可重放组件,包括钳制的拒绝特征、非钳制 SAE 特征,以及按绝对激活变化排序的前 k 个非钳制特征。扰动的剩余部分被隔离为未解释的残差分量:
δres=δx−(Dℓ(Eℓ(hℓrec(x)))−Dℓ(Eℓ(hℓdef(x)))).每个组件随后在原始活跃钳制下作为加性残差扰动进行重放,以量化其对行为恢复的独立贡献。
如下图所示:
 分解结果表明,恢复主要集中于 SAE 重建残差中,而非钳制特征或狭窄的替代潜在子集。由于 SAE 解码器方向并非严格正交,该框架避免将组件范数解释为方差比例。相反,它依赖行为重放与敲除实验来建立稳健的归因证据。这种结构化分解使作者能够系统地隔离信息如何绕过活跃钳制并恢复目标行为。
分解结果表明,恢复主要集中于 SAE 重建残差中,而非钳制特征或狭窄的替代潜在子集。由于 SAE 解码器方向并非严格正交,该框架避免将组件范数解释为方差比例。相反,它依赖行为重放与敲除实验来建立稳健的归因证据。这种结构化分解使作者能够系统地隔离信息如何绕过活跃钳制并恢复目标行为。
实验
对于较大的特征集,钳制越来越进入广泛的副作用模式,其中类基线恢复率下降,这与受保护状态的退化程度加剧而非恢复路径消失相一致。
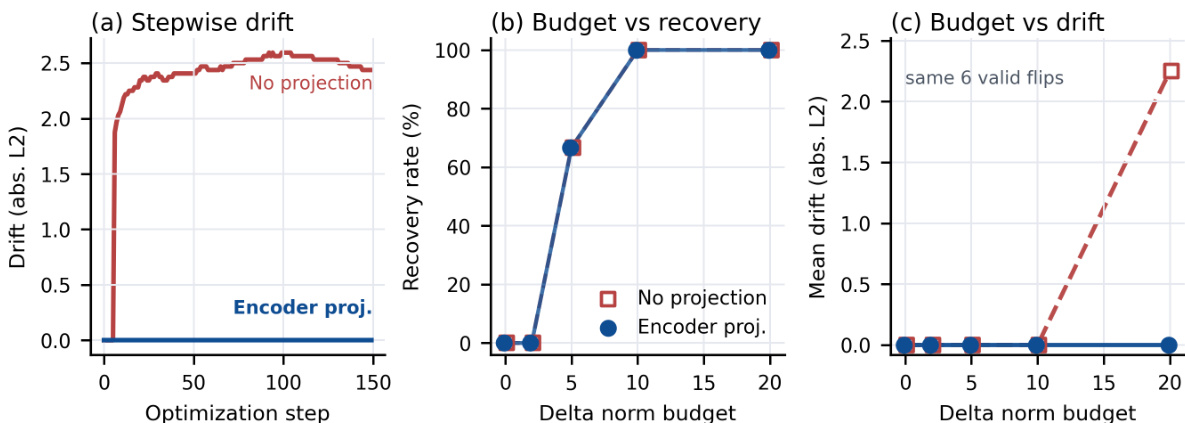
图表:遗忘恢复的预算与优化诊断。论文在相同的 SAE 钳制与事后评估器下,评估了严格 WMDP 切片中六个有效答案选项翻转的小规模匹配样本。(a) 优化期间,编码器投影恢复使选项输出受保护特征漂移保持为零,而无约束恢复迅速增加漂移。(b) 恢复率随扰动预算提升:编码器投影恢复在预算为 5 时达到 4/6,在预算为 10 时达到 6/6。(c) 增加预算并不会强制编码器投影下的受保护特征漂移;即使预算增至 20,漂移仍保持为零,而无约束恢复在同一预算下达到平均漂移 2.25。
图表:不同特征集大小的拒绝恢复情况。左图:更广泛的 SAE 特征钳制影响更多提示,增加了 K 特定有效案例的数量。对于 K≥30,阴影区域标记了放宽的有效/拒绝判断标准,用于将安全提示与负面/退化开头计为钳制诱导的抑制。右图:非拒绝恢复在扫描过程中始终保持高位,而随着钳制范围扩大,基线答案保真度下降。宽 K 行为是一种副作用模式,与 SAE 拒绝引导中报告的能力与过度拒绝权衡相一致。

表格:不同特征集大小的拒绝恢复情况。每一行重新计算由特定 K 特征钳制诱导的有效集。在稳定的 K=5–20 范围内恢复率保持高位,因此该现象并非由明显过小的特征集所解释。对于较大的 K,随着钳制进入广泛的副作用模式,类基线恢复率下降。
表格:复现主要恢复结果的实验细节。该表格总结了每个实验的核心配置;完整的命令行与日志见补充材料。
- K 实验细节与计算资源
实验细节。该表格总结了每个实验所使用的模型、SAE 版本、干预目标、恢复目标及评估器。确切的脚本路径与配置文件包含在补充材料中。
计算资源。所有实验均使用冻结的语言模型与冻结的 SAE。论文未训练新的语言模型或新的 SAE;所报告的实验仅优化逐样本恢复扰动或软后缀基线。
- L 局限性
该结果并非针对基于 SAE 干预的普遍不可能性结论。论文指出在评估设置中存在恢复路径,而非主张每种可能的 SAE 干预都必须可恢复。其结果依赖于特征选择与 SAE 版本:所测试的防御措施作用于特定字典与模型设置中选定的 SAE 特征。不同的 SAE 目标、更密集的字典、更宽的多层钳制,或专门针对钳制后恢复进行训练的干预,可能会改变观察到的权衡关系。
表格:所报告实验的近似计算资源。运行时间因批处理大小与集群可用性而异;这些数值旨在记录复现所报告诊断所需的工作规模。
恢复过程属于白盒诊断而非黑盒攻击。它假设可以访问内部激活与梯度,并优化逐输入残差扰动。这适用于测试干预的完整性,但不应被解释为可直接部署的越狱攻击。
最后,拒绝案例研究采用严格的有效过滤协议,这提高了可解释性,但导致干净恢复示例的主集合相对较小。因此,需要在不同模型、提示、钳制强度与 SAE 版本上进行更广泛的评估,以确定该现象的完整范围。
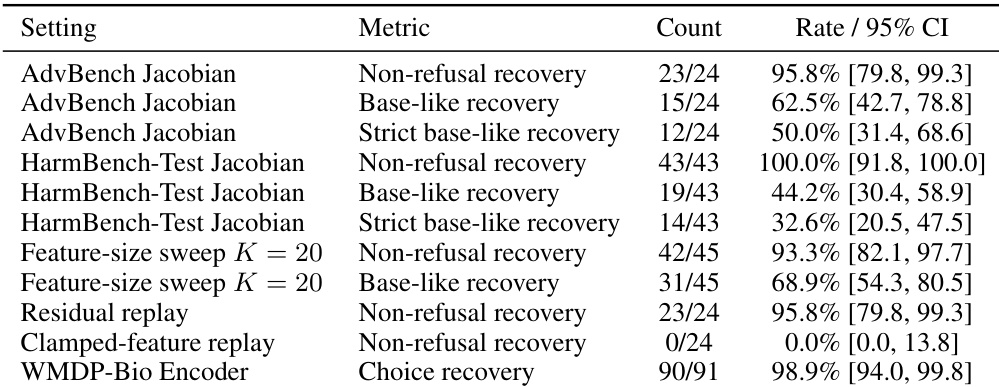
该表格比较了 AdvBench 与 HarmBench-Test 数据集上的恢复指标,显示高非拒绝恢复率与低特征漂移并存。作者证明,即使活跃 SAE 钳制仍然生效,非拒绝行为仍可从受保护残差状态中大幅恢复。该恢复过程伴随受保护特征状态的极小变动,表明该干预并未形成完全的行为瓶颈。在两个评估数据集中,绝大多数严格有效示例的非拒绝行为均被成功恢复。恢复过程使受保护特征状态保持在其钳制值附近,表明激活漂移极小。归因分析表明,恢复的行为主要由 SAE 重建残差承载,而非可见的 SAE 特征。

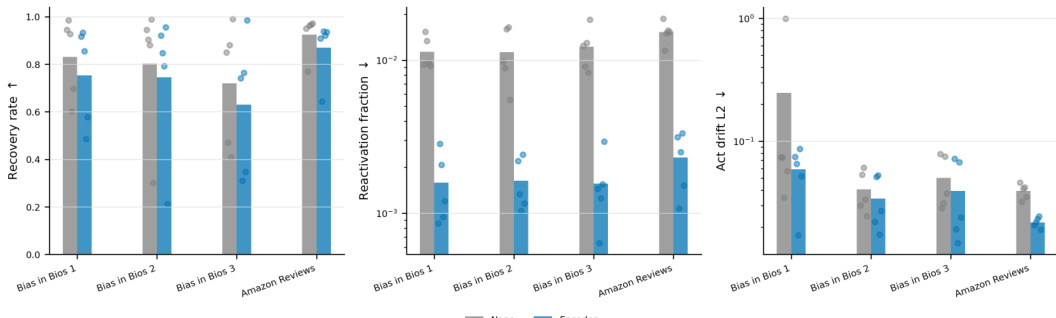
作者跨多个数据集评估了干预后恢复,以测试目标稀疏自编码器特征是否能在完全抑制的同时阻止行为恢复。结果表明,尽管编码器正交恢复保持了较高的行为恢复率,但它显著降低了受保护特征的重新激活及其相关的激活漂移。这证明即使更新被约束以避免钳制特征方向,恢复路径依然存在。编码器正交恢复在最小化特征重新激活的同时维持了高行为恢复率。当更新被约束远离受保护编码器方向时,激活漂移持续降低。在编码器投影优化下,无特征重开的恢复率显著增加。

结果表明,钳制与安全相关的 SAE 特征并未完全消除模型生成非拒绝响应的底层能力。恢复的行为主要由 SAE 重建残差促进,而非通过重新激活目标特征或其他可见潜在变量。此外,恢复优化成功维持了受保护特征状态的完整性,导致漂移与底线违规极小。SAE 重建残差作为行为恢复的主导路径,有效绕过了被抑制的特征集。钳制特征的重新激活及其他可见 SAE 潜在变量的补偿对恢复行为的贡献微乎其微。恢复过程有效保留了受保护特征状态,与无约束方法相比,始终保持更低的漂移与底线违规水平。
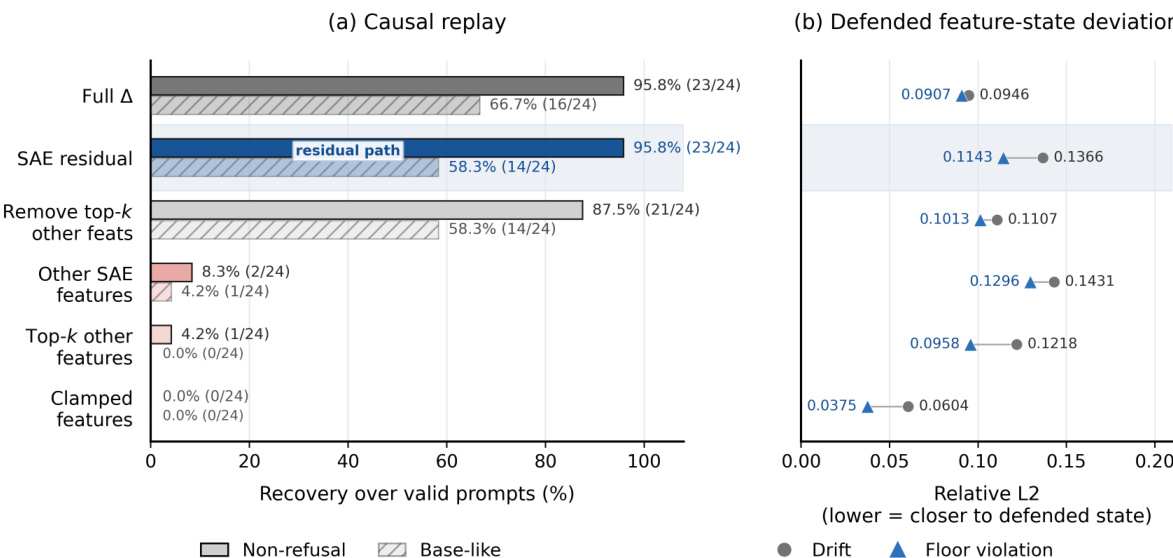
作者跨多个实验设置评估了干预后恢复,以测试稀疏自编码器特征钳制是否充当完全的行为瓶颈。结果表明,即使优化更新被约束以防止钳制特征的重新激活,目标行为仍可从受保护残差状态中成功恢复。该恢复模式在潜在层、输出层与电路级任务中保持一致,归因分析表明 SAE 重建残差主要承载恢复的行为。投影恢复方法在维持极小受保护特征漂移的同时,成功在潜在层、输出层与电路级任务中恢复目标行为。行为恢复在不同扰动预算与特征集大小下保持稳健,表明钳制并未消除所有底层计算路径。归因分析揭示 SAE 重建残差作为恢复行为的主导载体,无需重新激活钳制特征或替代可见特征。

实验证明,目标稀疏自编码器特征钳制并未完全消除模型行为,因为被抑制的响应可通过干预后优化有效恢复。恢复主要由 SAE 重建残差驱动,而非通过重新激活钳制特征或通过其他可见潜在方向进行补偿。因此,SAE 干预作为部分因果控制手柄,但在各种基准与设置中未能建立完全的行为瓶颈。非拒绝输出的恢复率在多个基准中始终保持高位,而仅通过重放钳制特征来恢复行为的尝试则完全失败。该表格表明,类基线与严格类基线恢复指标通常低于非拒绝恢复,这表明虽然目标行为可以恢复,但往往偏离原始响应格式。不同特征尺寸扫描与重放条件下的结果证明,行为恢复具有稳健性,且主要依赖 SAE 重建残差而非钳制潜在方向。
实验跨多个基准、优化约束与特征集配置评估了干预后行为恢复,以验证钳制与安全相关的稀疏自编码器特征是否创建完全的行为瓶颈。结果一致表明,目标抑制并未消除底层计算路径,因为模型成功通过 SAE 重建残差恢复非拒绝及其他目标行为,而非重新激活钳制潜在变量或通过可见方向进行补偿。该恢复过程在多样化的实验设置中保持极小激活漂移,并维持受保护特征状态的完整性。最终,研究结果表明 SAE 干预作为部分因果控制手柄,能有效调节但无法完全约束模型行为。