Command Palette
Search for a command to run...
近端策略优化区域:提示中的教师,而非梯度
近端策略优化区域:提示中的教师,而非梯度
摘要
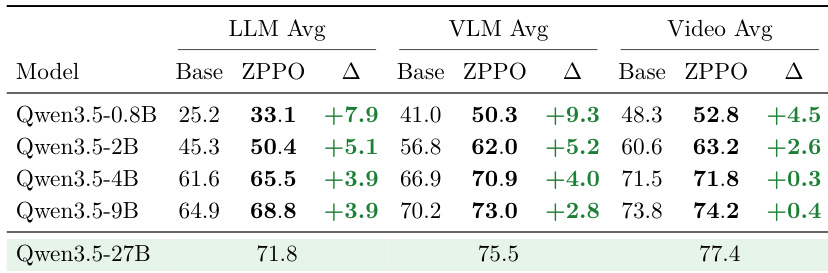
知识蒸馏将教师模型的能力迁移至小型学生模型,但在小型学生模型场景下表现脆弱:强制学生模型模仿来自更大规模教师模型的logits,会使其过度集中于教师模型最尖锐的模式,从而损害其在训练语料库之外的基准测试族上的泛化能力。强化学习(RL)通过在学生模型自身的rollouts上进行训练,避免了logit模仿。然而,在每一个rollout均失败的问题上——此类情况会产生零优势并被静默丢弃——将更强教师模型的响应注入策略梯度会破坏on-policy假设并引发漂移。我们提出了最近发展区策略优化(ZPPO),该算法受维果茨基最近发展区理论启发,将教师模型保留在prompt内部而非策略梯度中。针对难题,ZPPO构建了两种重构的prompt:二元候选包含问题(BCQ)将一个正确的教师响应与一个错误的学生响应配对,作为学生必须区分的匿名候选项;负向候选包含问题(NCQ)将学生的错误rollouts聚合至单个prompt中,以凸显其共有的失败模式。通过prompt重放缓冲区,每个难题会被循环使用,直到其“毕业”——即学生在该题上的平均rollout准确率达到50%——或在容量受限时按FIFO策略被驱逐,从而在学生当前的最近发展区内强化BCQ与NCQ的作用。在Qwen3.5系列模型上,以27B模型为教师,对四个学生规模(0.8B-9B)进行后训练,将其作为视觉-语言模型,并在包含31个基准测试的套件(16个VLM、10个LLM、5个Video基准)上进行评估,结果表明ZPPO优于off/on-policy蒸馏方法及GRPO,且在最小规模下获得的性能提升最为显著。
一句话总结
Zone of Proximal Policy Optimization (ZPPO) 通过将教师指导路由至提示词(prompt)而非梯度,解决了 logit 模仿的脆弱性及强化学习中的 on-policy 漂移问题。该方法利用 Binary Candidate-included Questions 将正确的教师回答与错误的学生输出配对作为匿名候选项,并利用 Negative Candidate-included Questions 聚合学生失败案例,从而使小型学生模型能够在不违反策略假设的前提下,通过针对性的提示词判别进行学习。
核心贡献
- 提出 Zone of Proximal Policy Optimization (ZPPO),通过将教师指导从策略梯度直接迁移至提示词中,克服小型学生模型蒸馏的脆弱性与策略漂移问题。该架构确保策略梯度处理的每一个 token 均由学生生成,从而保持严格的 on-policy 训练动态。
- 针对强化学习中优势值为零的难题,动态构建两种重构提示词。其中包括 Binary Candidate-included Questions (BCQ),将匿名的正确教师回答与错误的学生 rollout 配对用于判别;以及 Negative Candidate-included Questions (NCQ),聚合学生失败尝试以揭示共性失败模式。
- 将强化学习后训练扩展至数学、科学、广泛知识及多模态推理领域,同时规避小型学生模型常见的泛化崩溃问题。该框架通过动态候选项生成与定向提示词重放缓冲区维持 on-policy 保证,后者在学生最近发展区(zone of proximal development)内放大重构提示词。
引言
为复杂推理任务高效地对紧凑型视觉语言模型与语言模型进行后训练,对于部署可扩展 AI 至关重要,但现有方法在知识迁移方面面临挑战。知识蒸馏在小型学生模型中容易变得脆弱,常引发记忆化与泛化能力下降;而标准强化学习后训练会因组优势值为零而静默丢弃模型持续失败的提示词。将教师回答拼接到策略梯度中的混合方法违反 on-policy 假设并引发严重漂移,而基于提示词的支架通常依赖静态提示,容易诱导捷径式复制。作者利用一种以提示词为核心的框架 Zone of Proximal Policy Optimization 来突破这些瓶颈。该方法通过结合教师生成与自生成的候选项重构失败提示词并重放,仅通过提示词传递教师知识,确保所有梯度更新严格保持 on-policy,同时在学生当前学习前沿动态提供支架支持。
数据集
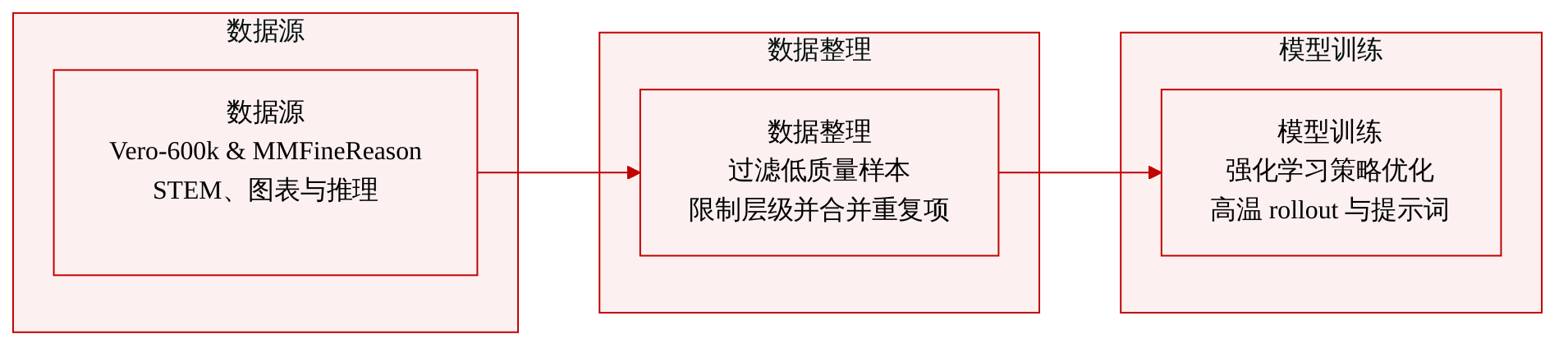
- 数据集构成与来源: 作者构建了 ZPPO-77K,这是一个包含约 77,000 组输入图像、文本问题与标准答案三元组的多模态强化学习语料库。数据来源于两个公开仓库:涵盖 STEM、图表与 OCR 以及通用视觉问答的 34 个子数据集的 Vero-600k 集合,以及由 4B 教师模型生成每样本成功率标注的链式思维语料库 MMFineReason-SFT-586K 集合。
- 子集详情与过滤: 为平衡推理深度与辅助知识,作者将语料库划分为两个层级。第一层级优先处理数学与图表分析等直接推理任务,每个子数据集上限为 2,800 条样本。第二层级涵盖辅助定位与识别任务,每个上限为 1,400 条样本。为突出真正难题,作者丢弃 4B 教师模型成功率高于 0.5 的 MMFineReason 示例。跨源重复数据通过优先采用 Vero 仓库解决,样本级过滤器则强制规定最大答案为 512 字符,最小图像分辨率为 100x100 像素。
- 训练用途与混合策略: 作者使用该清洗后的数据集通过强化学习训练学生策略。通过应用层级上限,他们构建了一种受控混合数据,大幅增加复杂多模态推理在通用识别任务中的权重。训练期间,模型使用高温度采样生成 rollout 以鼓励探索,同时标准化提示词模板强制进行内部推理过程,随后输出严格格式化的最终答案。
- 输入处理与评估流程: 作者在整个流程中应用一致的图像缩放约束,要求输入像素范围保持在 256x32x32 至 1280x32x32 之间。他们移除上游提示词中的所有特定任务格式化指令,并在训练与评估阶段应用统一的 RL closer。这确保策略针对测试中遇到的确切答案提取规则进行优化,评估指标依赖确定性解析器,仅在无法解析严格格式时回退至专用评判模型。
实验
在多个模型规模下的 LLM、VLM 与视频基准测试中,主实验验证了 ZPPO 在标准强化学习与蒸馏方法常导致性能下降的场景中,始终能提升泛化能力。组件消融实验证实,仅使用提示词重放并不充分,但将其与对比候选项选择及集体负向失败分析结合,可产生超加性学习信号,从而维持对难题的探索。训练动态与候选项审计进一步验证了重构策略能够从以往无法挽回的错误中提取可操作洞察,且不依赖简单的答案匹配或 off-policy 捷径。总体而言,这些发现表明该方法成功弥合了小型学生与大型教师之间的能力差距,提供了随模型容量扩展的稳健跨域性能提升。
该实验在十六个多样化基准上评估了视觉语言模型的多种训练策略。结果表明,提出的 ZPPO 方法持续优于包括策略蒸馏与标准强化学习变体在内的替代方案。这一优越性能在小型与大型模型规模中均得到体现,表明其具备稳健的泛化能力。与蒸馏和 GRPO 方法相比,ZPPO 在所有基准上均取得最高平均性能。该方法在各项独立基准上均展现一致改进,几乎每个类别均录得正向收益。扩大模型规模保持了 ZPPO 相较于其他训练技术的性能优势。
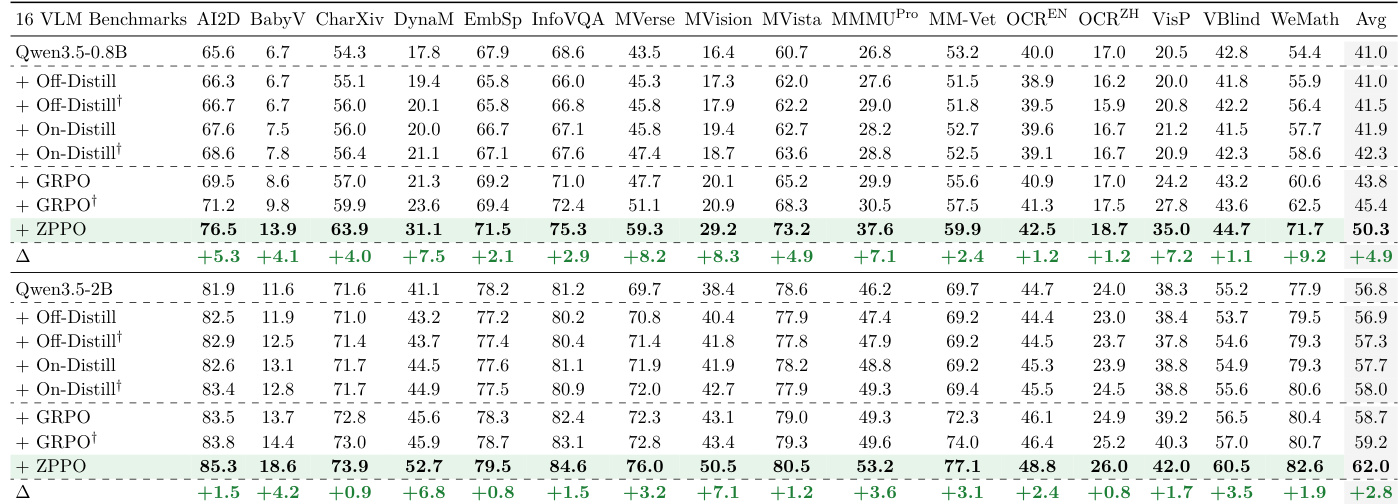
作者在多种模型规模下的语言模型与视频基准上评估了各类训练方法。结果表明,蒸馏技术通常无法改善泛化能力,且相较于基础模型常导致性能下降。相比之下,提出的 ZPPO 方法在所有基准与规模中均持续产生最大性能增益,显著优于标准强化学习与蒸馏方法。蒸馏方法在视频基准上通常表现不及基础模型,且在语言任务上收益甚微。ZPPO 在所有评估基准上取得最高平均分,相较于基线强化学习实现显著改进。ZPPO 的性能增益在小型模型规模中最明显,但在更大容量下仍保持稳健。
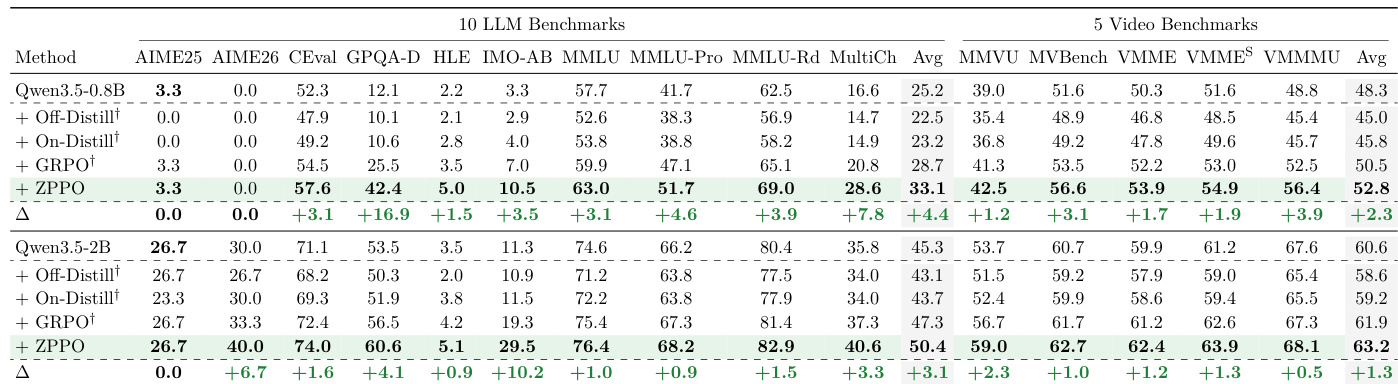
作者在多种模型规模与基准类型下,将提出的 ZPPO 方法与若干基线及消融变体进行对比评估。结果显示,ZPPO 在所有类别中持续取得最高性能,证明其核心组件结合的有效性。研究结果凸显了完整方案相较于孤立修改或简单基于提示词的引导策略的优越性。在 LLM、VLM 与 Video 基准上,ZPPO 均优于所有模型尺寸的基线与消融方法。将 BCQ 融入 GRPO 框架相较于标准 GRPO 基线带来显著改进。与完整 ZPPO 方案相比,Hint 和 Prefix 等基于提示词的引导方法收益有限。
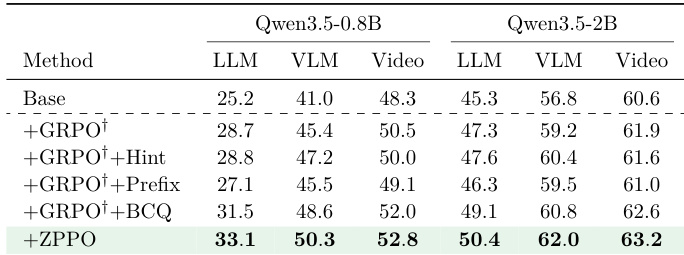
作者在 LLM、VLM 与 Video 基准的多种模型规模下评估 ZPPO 方法。结果表明,ZPPO 在所有规模与基准家族中持续优于基础模型。性能增益在小型模型中最显著,此时学生与教师之间的差距最大,且随着模型规模增大而减弱。这表明 ZPPO 在增强小型学生模型的泛化能力与从困难样本中学习方面尤为有效。与基础模型相比,ZPPO 在所有模型尺寸与基准类别中均持续改善性能。小型模型获得最大的相对增益,凸显了该方法对能力较弱学生模型的有效性。该方法展现出强大的泛化能力,在训练域之外的 LLM 与 Video 任务中均取得正向结果。
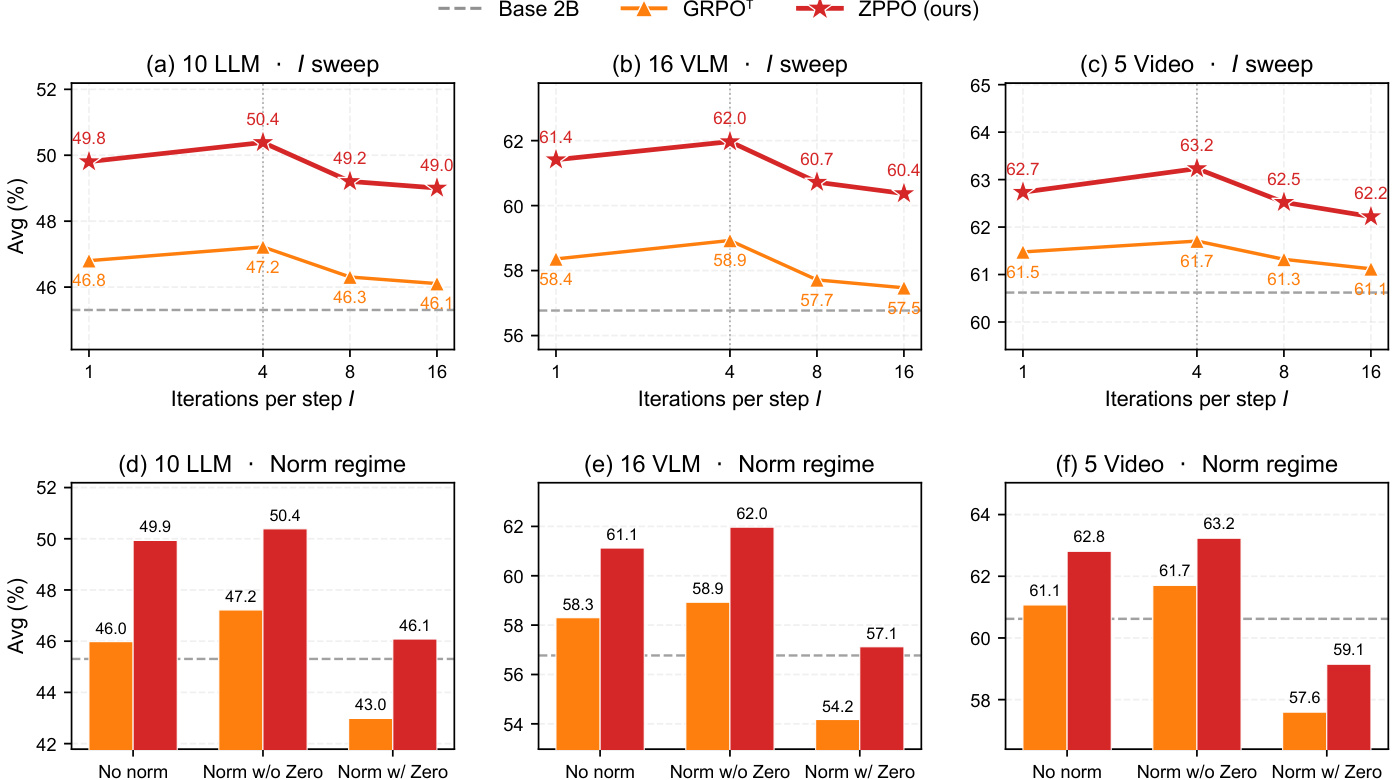
作者分析了内层循环迭代次数与批归一化选择在语言、视觉语言与视频基准上对性能的影响。数据显示,适度迭代设置可使准确率最大化,而较高次数会因加剧策略漂移导致结果下降。此外,剔除零优势组的归一化方法持续优于未归一化与完全包含的变体。准确率在内层循环适度迭代次数时达到峰值,更高值会因 off-policy 漂移引发性能下降。排除零优势组的批归一化可靠地优于未归一化设置及保留 trivial 组的设置。最优训练配置平衡了更新频率与稳定性,在所有评估基准家族中提供一致增益。
实验在多种模型规模下,于多样化语言、视觉语言与视频基准上将提出的 ZPPO 方法与蒸馏、标准强化学习及基于提示词的基线进行对比。结果表明,ZPPO 持续优于所有竞争方案,为小型模型带来尤为显著的增益,同时在更大容量下保持稳健改进。消融研究证实完整的方法组合必不可少,孤立组件会导致性能显著下降。最后,超参数分析表明,适度的内层循环迭代与排除零优势组的批归一化对于最大化训练稳定性与跨域准确率至关重要。