Command Palette
Search for a command to run...
LoopCoder-v2:仅循环一次以实现高效的测试时计算扩展
LoopCoder-v2:仅循环一次以实现高效的测试时计算扩展
摘要
循环Transformer通过重复应用共享模块来扩展潜在计算,但顺序循环会随循环次数的增加而增加延迟与KV缓存内存占用。并行循环Transformer(PLT)通过跨循环位置偏移(CLP)与共享KV门控滑动窗口注意力机制缓解了这一开销,使得循环次数成为一个切实可行的设计选项。因此,我们从收益与成本的权衡视角研究PLT循环次数的选择:增加一次循环可能有助于优化表征,但CLP也会在每次循环边界引入位置不匹配。我们通过从头在18T tokens上训练LoopCoder-v2(一个包含不同循环次数的7B参数PLT代码生成模型家族)来具体开展此项研究,随后进行对齐的指令微调与评估。实验结果表明,双循环变体在代码生成、代码推理、智能体软件工程及工具使用基准测试中,相较于无循环基线均取得了广泛提升,将SWE-bench Verified的得分从43.0提升至64.4,Multi-SWE的得分从14.0提升至31.0。相比之下,包含三次或更多循环的变体性能出现倒退,揭示了循环次数效应具有强烈的非单调性。我们的诊断分析表明,第二次循环提供了主要的有效优化,而后续循环仅带来收益递减、更新呈振荡状态以及表征多样性降低。随着优化收益的递减,由CLP引起的位置不匹配量大致保持固定,导致偏移开销逐渐占据主导地位。这种收益与成本的权衡关系解释了PLT在两次循环时达到性能饱和的原因,并为循环次数的选择提供了诊断依据。
一句话总结
基于 18T tokens 从零开始训练,LoopCoder-v2 是一系列 7B 参数的 Parallel Loop Transformer 模型。该模型采用跨循环位置偏移与共享 KV-cache 门控滑动窗口注意力机制以优化推理阶段的计算。实证评估表明,双循环配置能够最大化表征细化效果,在代码生成、推理及 agentic 软件工程基准测试中实现显著提升;而更深的循环则会引入位置失配与振荡更新,导致性能下降。
核心贡献
- 本研究提出 LoopCoder-v2,这是一系列基于 18T tokens 从零训练、并经过匹配指令微调的 7B Parallel Loop Transformer 代码模型,旨在系统评估不同的循环配置。
- 针对跨循环位置偏移的收益成本分析揭示出强烈的非单调缩放效应。结果表明,第二个循环提供主要的有效细化,而更深的迭代则产生收益递减与振荡更新。
- 在代码生成、推理及 agentic 软件工程基准上的实证评估表明,双循环变体显著优于无循环基线模型,将 SWE-bench Verified 分数从 43.0 提升至 64.4,将 Multi-SWE 从 14.0 提升至 31.0。
引言
循环 Transformer 通过重复应用共享模块来细化内部表征,从而扩展潜在计算能力,且无需生成辅助推理 tokens,为代码生成与 agentic 软件工程等复杂任务提供了一条参数高效的路径。然而,标准的顺序循环会线性增加推理延迟与 KV-cache 内存占用。PLT 等并行变体通过引入跨循环位置偏移来缓解这一瓶颈,但这会在每个边界处产生结构失配。先前研究表明,额外增加循环会迅速导致收益递减、振荡更新与性能崩溃,但缺乏解释饱和现象的诊断框架。本文作者利用收益成本分析,系统评估了 PLT 中的循环数量选择。通过训练具有不同深度的 LoopCoder-v2 变体并追踪隐藏状态动态,作者证明在位置失配占据主导之前,双循环配置能够实现最大化的有效细化。本研究提供了基于可解释性的诊断方法以优化循环分配,并阐明了循环深度架构的非单调缩放行为。
数据集

- 数据集构成与来源: 作者构建了一个包含 18 trillion token 的预训练混合数据集,来源于广泛的文本与编程数据。语料库经过明确平衡,以确保自然语言文本与代码之间的 token 比例严格为 1:1。
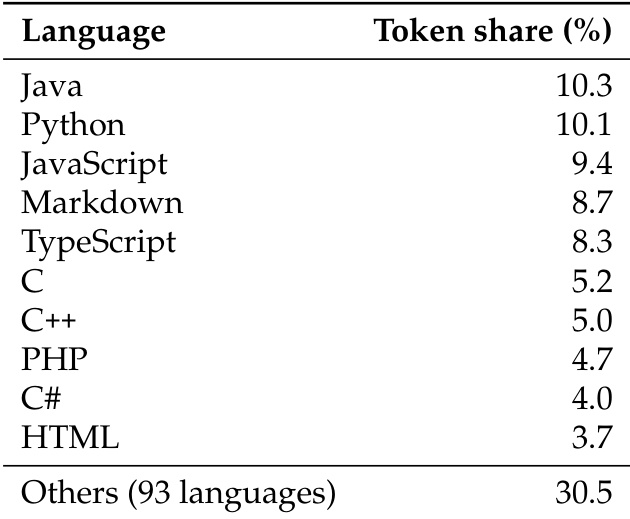
- 子集详情: 代码部分按编程语言分类。作者单独报告了按 token 占比排名的前 10 种语言,并将其余 93 种语言归入“其他”类别。所有分布百分比均仅基于代码 token 池进行计算。
- 模型使用与处理: 该平衡混合数据集作为模型预训练阶段的完整输入。作者在语料库构建过程中强制执行 token 级平衡,以确保文本与代码的表征均衡,并通过报告的 token 占比指标追踪语言分布。
- 其他处理说明: 数据集依赖 token 级聚合而非文档级采样来实现平衡。语言分类仅应用于代码部分,从而在不改变原始 token 流的前提下透明地报告语言分布。
实验
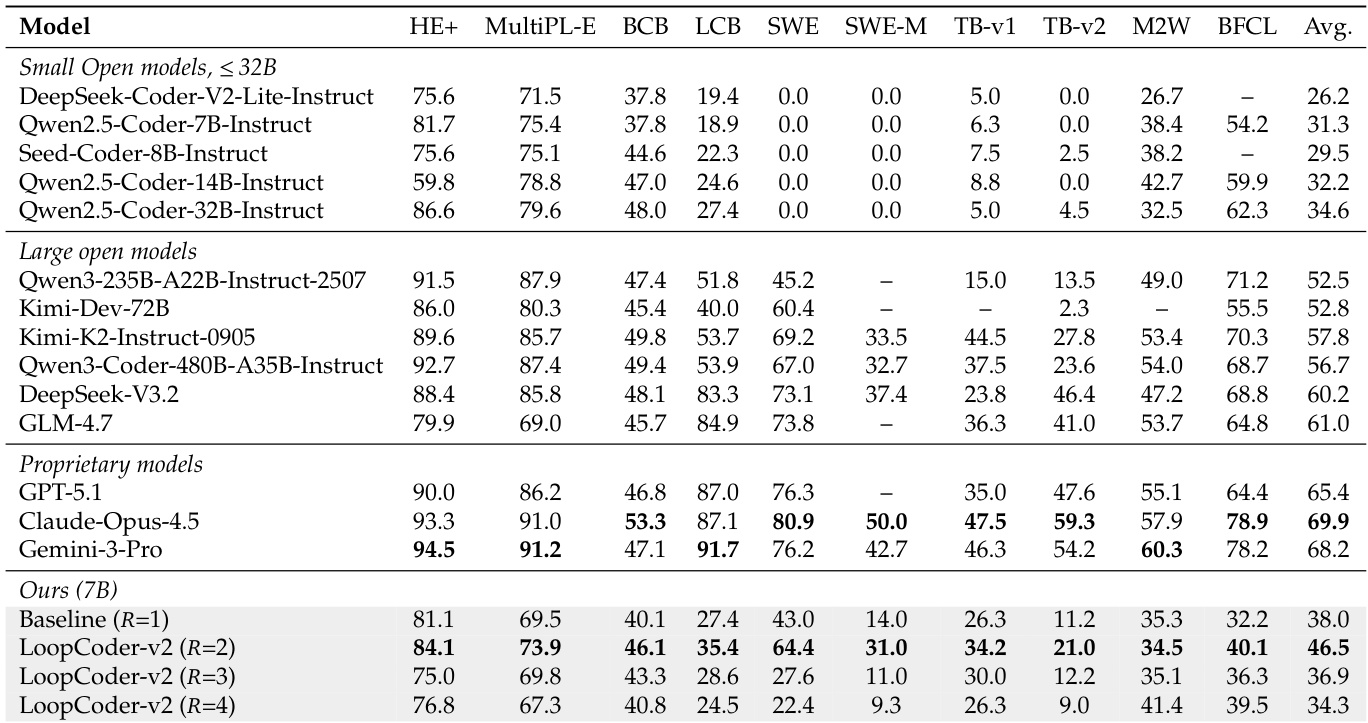
评估工作采用配备 Parallel Loop Transformer 机制的 7B 参数 Transformer,在代码、推理及 agentic 基准测试上系统评估性能,同时逐步将推理循环数量从 1 调整至 4。宏观性能分析揭示出强烈的非单调关系:仅增加一个循环即可取得最优结果,使该模型在与显著更大规模的系统竞争中具备高度竞争力。微观可解释性诊断证实,第二个循环是有效细化的主要场所,在后续迭代因收益递减与累积的位置偏移成本而受损之前,该循环能够最大化表征多样性与输出偏移。此外,实验表明这种潜在迭代细化机制与显式 chain-of-thought 推理呈互补关系,在最优循环配置下结合使用时能产生超加性提升。
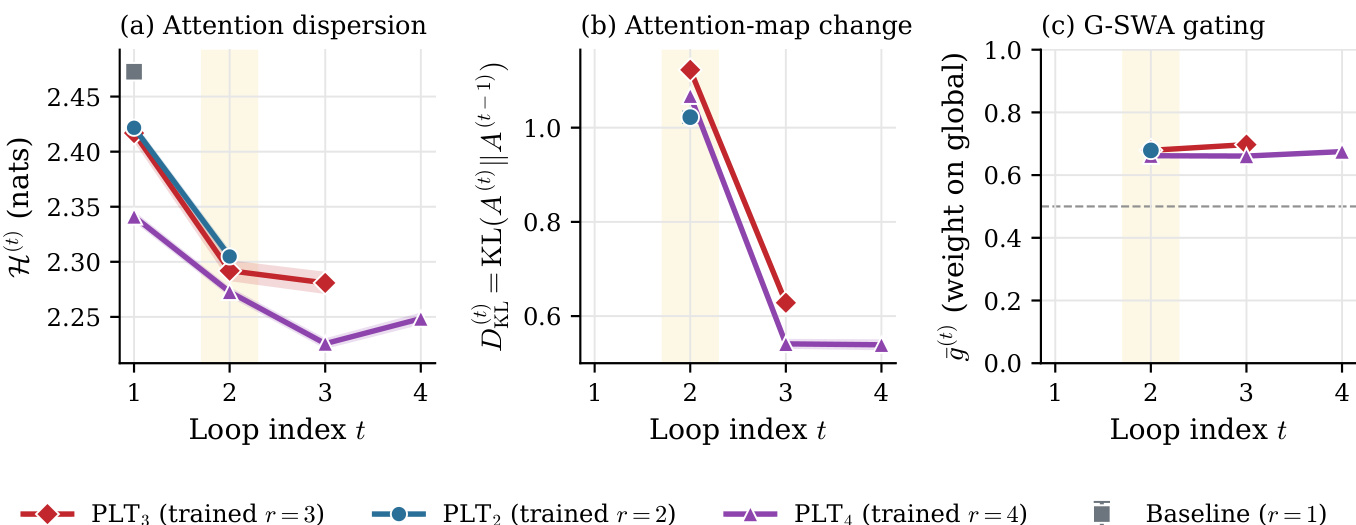
作者分析了 PLT 模型在推理循环过程中的内部动态,以理解循环数量的权衡关系。数据表明,注意力分散度在第一个循环后显著下降,而注意力图的最显著重构发生在第二个循环。此外,门控机制在整个过程中始终优先使用全局 KV cache 而非局部上下文。所有模型变体的注意力分散度从第一循环到第二循环均急剧下降。循环间的注意力变化在第二循环最为明显,随后迅速减弱。门控权重始终保持在中点以上,表明模型持续偏好全局 cache。
实验对比了仅依赖潜在循环的指令微调模型与结合了显式 chain-of-thought 推理的思维模型,两者均在循环数量 R=2 的条件下进行评估。结果表明,思维模型在所有基准测试中均稳定优于基线模型,且在推理密集型任务上提升尤为显著。这表明显式推理轨迹与潜在循环细化是互补机制,结合使用时可产生超加性收益。思维模型在所有基准上持续超越指令微调基线。性能提升在重度推理任务上最为明显,表明显式推理与潜在细化之间存在强协同效应。与单独使用任一方法相比,将显式 CoT 与潜在循环结合能带来超加性的性能改进。

作者评估了采用 Parallel Loop Transformer 的 7B 参数模型在不同循环数量下的表现,以权衡表征收益与位置失配成本。结果显示性能呈非单调曲线:增加单个循环可获得最高效能,显著优于无循环基线。相反,进一步增加循环数量会导致性能倒退,通常低于基线水平,表明额外迭代引入的是负面影响而非细化效果。在提出的变体中,仅增加一个循环的模型配置取得了最高的平均性能。当最优阈值后继续引入额外循环时,性能出现下降,说明位置失配的固定成本已超过表征收益的递减幅度。该最优配置在 agentic 软件工程基准上展现出强劲的竞争力,性能可与规模大得多的开源系统相媲美。
该表格分析了四循环模型中各循环的行为特征,对比了步长、输出分布偏移、有效秩与更新对齐度。第二个循环成为有效细化的核心场所,表现出最高的有效秩与输出分布偏移。后续循环的表征多样性逐渐降低,最终循环的更新对齐度发生偏移且步长反弹,这与重新读取预测结果的现象一致。第二个循环展现出最高的有效秩与输出分布偏移,标志着其作为有效细化的主要场所。后续循环的有效秩与注意力多样性持续下降,表明表征收益递减。最终循环的更新对齐度向零偏移且步长反弹,与重新读取预测结果的特征相符。

该模型在包含文本与代码平衡混合数据的语料库上进行训练,代码部分涵盖一百多种编程语言。数据分布高度集中于 Java 与 Python,两者占据最大份额。JavaScript、Markdown 与 TypeScript 也较为突出,而相当大比例的 tokens 来自多样化的其他语言。Java 与 Python 是训练数据中占主导地位的语言。JavaScript、Markdown 与 TypeScript 在排名前两位的语言之后出现频率较高。大量数据分散在许多其他较少使用的语言中。
实验在包含多语言代码与文本的数据集上,评估了 PLT 模型的内部推理动态、最优循环配置及其与显式推理的融合情况。分析表明,第二个推理循环是注意力重构与表征细化的主要阶段,而额外迭代引入的位置失配成本最终会导致性能下降。在整个过程中,门控机制始终优先关注全局上下文而非局部细节。将潜在循环细化与显式 chain-of-thought 推理相结合,可在复杂任务上产生显著的协同提升效果,证明经过紧凑优化的模型能够实现极具竞争力的结果。