Command Palette
Search for a command to run...
GameCraft-Bench:Agents能否在真实游戏引擎中端到端地构建可玩的游戏?
GameCraft-Bench:Agents能否在真实游戏引擎中端到端地构建可玩的游戏?
摘要
游戏生成是编程 agents 的一项新兴应用,要求模型将自然语言规范转化为可玩的交互系统。与传统编程任务不同,游戏生成在引擎内部进行,其中的脚本、场景、资源、渲染和运行时交互必须协同生成连贯的游戏玩法。我们将端到端游戏生成形式化为一个问题,即在目标环境中,通过可观察的玩家与游戏交互,生成一个能够实现规范的完整游戏制品。我们认为,评估该场景需要满足三个要求:引擎接地、制品完整性和交互验证。我们提出了一种基于交互的评估框架,通过重放演示和基于量表的 多模态评判 来评估可执行的游戏玩法。我们将该框架实例化为 GameCraft-Bench,这是一个涵盖15类游戏、包含140个 Godot 任务的基准测试。对前沿编程 agents 的评估表明,端到端游戏生成仍然极具挑战性:表现最强的 agent 仅达到 41.46%,且大多数 agents 的得分均低于 40%。进一步分析表明,尽管 agents 通常能够实现可识别的游戏机制,但它们难以交付内容充足、具备功能性视觉反馈且呈现连贯的完整游戏。演示、代码与数据详见 https://tongxuluo.github.io/gamecraft-bench-website 。
一句话总结
GameCraft-Bench 引入了一项基于交互验证的基准测试,通过基于评分量规的多模态评判,在 140 个 Godot 任务中评估引擎接地性、工件完整性与交互验证性。结果显示,前沿编码 Agent 难以将自然语言规范转化为真实游戏引擎中完整且可玩的游戏,表现最强的 Agent 仅达到 41.46% 的成功率。
核心贡献
- 本文提出了一项基于交互验证的评估框架,要求通过回放演示和基于评分量规的多模态评判来测试可执行游戏工件。该框架实现了三大核心诉求:引擎接地性、工件完整性与交互验证性。
- 该框架具体化为 GameCraft-Bench,包含涵盖 15 类游戏系列的 140 个 Godot 引擎任务。它要求提供完整可玩的项目及可回放演示脚本,以进行一致性的运行时评估,从而评估端到端构建能力。
- 对前沿编码 Agent 的评估表明,端到端游戏生成仍极具挑战,表现最强的模型成功率仅为 41.46%。分析显示,虽然 Agent 经常能生成可识别的局部机制,但始终无法组装出内容充足、具备功能性视觉反馈且交互连贯的完整游戏。
引言
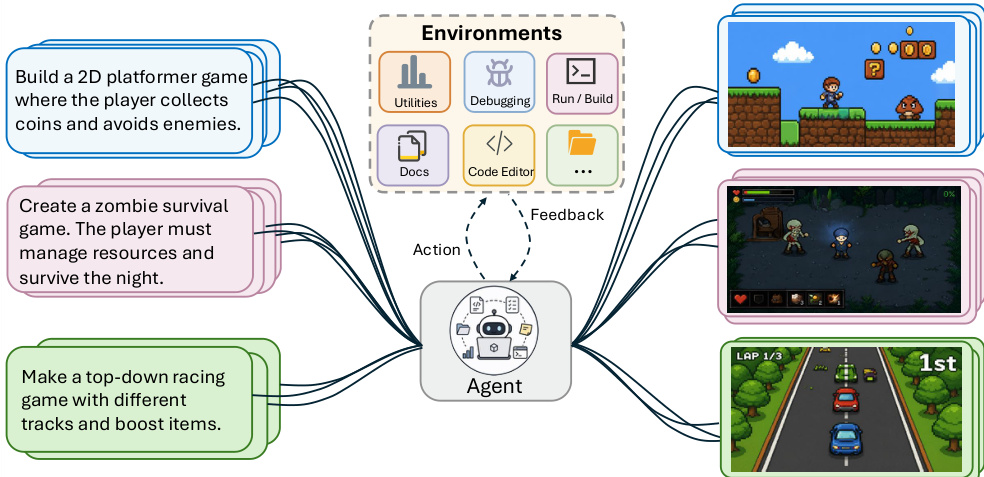
作者将端到端游戏生成视为编码 Agent 的关键前沿领域,要求将自然语言规范转化为真实游戏引擎中完全可玩的交互系统。现有基准测试存在不足,要么针对基于 Web 的项目,要么仅测试局部代码修改,或依赖静态检查而非直接的游戏玩法验证。为弥补这些空白,作者引入了 GameCraft-Bench,该基准测试在 140 个 Godot 任务中共同落实了引擎接地性、工件完整性与交互验证性。通过对 Agent 进行回放游戏玩法演示与基于量规的评估,作者证明当前模型能够生成孤立机制,但在组装完整、视觉连贯且功能交互的游戏方面始终面临困难。
数据集

数据集构成与来源
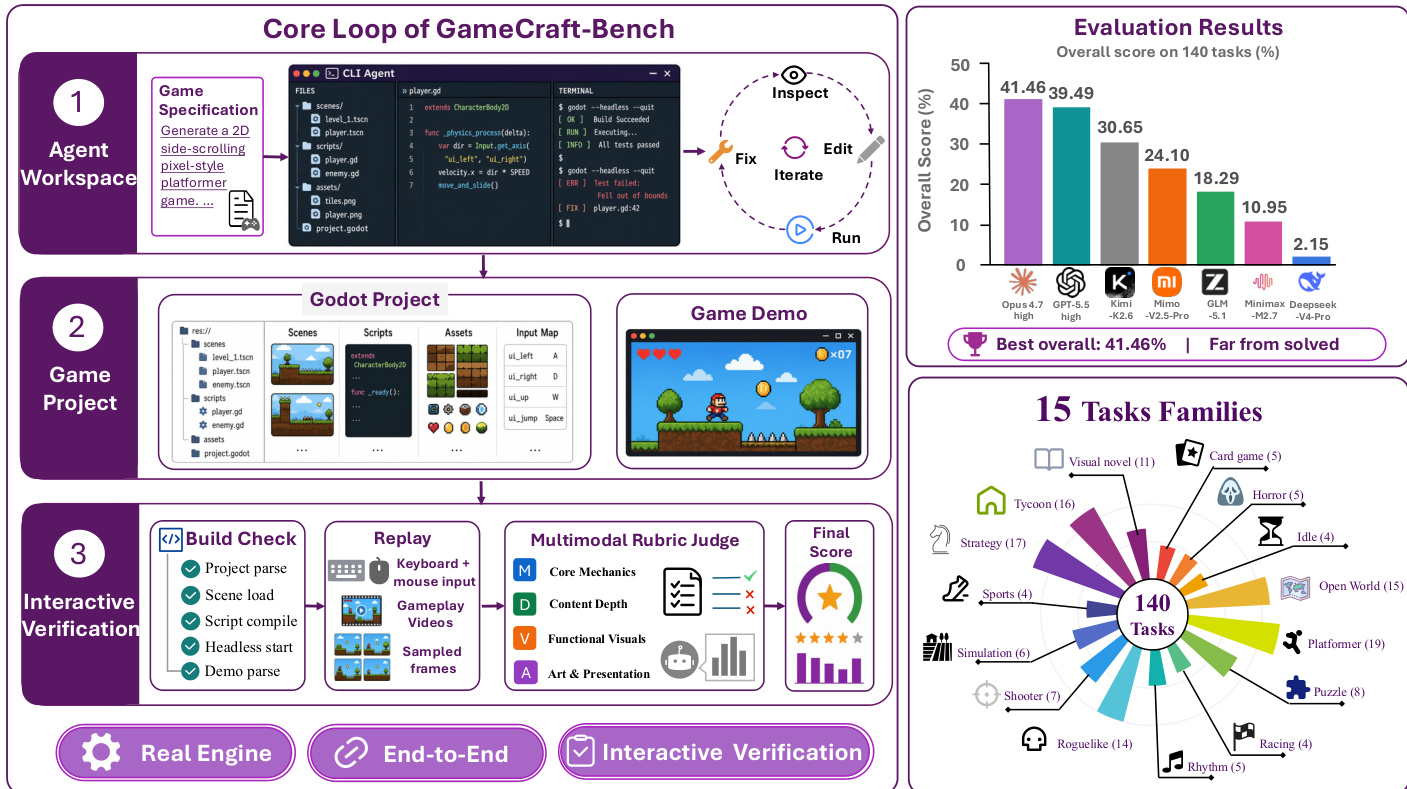
- 作者引入了 GameCraft-Bench,该基准测试包含 140 个任务,涵盖 15 种不同的游戏系列,包括平台跳跃、策略、大亨模拟、Roguelike 及视觉小说。
- 所有任务均基于开源 Godot 4 引擎构建,以实现轻量级、无头且可复现的评估。
- 视觉素材来源于 Kenney CCO 资源包与 OpenGameArt 条目,在 workspace 中以只读方式挂载。
各子集关键细节
- 基准测试精确包含 140 个任务,每个任务由 12 位经验丰富的标注员使用 Harbor 框架编写。
- 每个任务要求提供完整且可交付的微游戏,而非孤立的原型或静态原型图。
- 严格的启动门槛强制执行此规则:若生成的 Godot 项目无法运行,提交物将得零分。
- 任务结构围绕隐藏评估量规展开,将游戏玩法分解为可观察的、需求级别的指标。
数据使用与评估流程
- 该数据集专为基准测试与评估设计,而非模型训练。
- Agent 提交一个 Godot 项目以及最多十个演示轨迹文件,用于模拟玩家输入。
- 验证器在无头 Godot 运行时中回放这些轨迹,记录游戏玩法,并将视频输入多模态评判器进行打分。
- 未定义明确的训练或验证划分,因为重点在于针对预定义规范对 Agent 生成的工件进行零样本评估。
处理、元数据与评分细节
- 每个任务附带三个元数据文件:用于运行时配置的
task.toml、用于公开游戏规范的instruction.md,以及用于隐藏评分标准的tests/rubric.json。 - 量规分为四个固定类别:核心机制、内容深度、功能性视觉表现、艺术与呈现,每个任务最多包含 24 个评分项。
- 输入轨迹格式化为 JSON 文件,包含带时间戳的鼠标点击、按键操作与等待命令,映射至 1280 乘 720 的视口。
- 游戏玩法录制采样率为每秒两帧,压缩至 854 乘 480 分辨率,每个演示限制在 20 秒的确定性窗口内。
- 评分对可读性与艺术一致性等稳定特征采用均值聚合,对存在性检查采用最大值聚合。薄弱或纯装饰性实现最高只能得 0.5 分(满分 1.0)。
方法
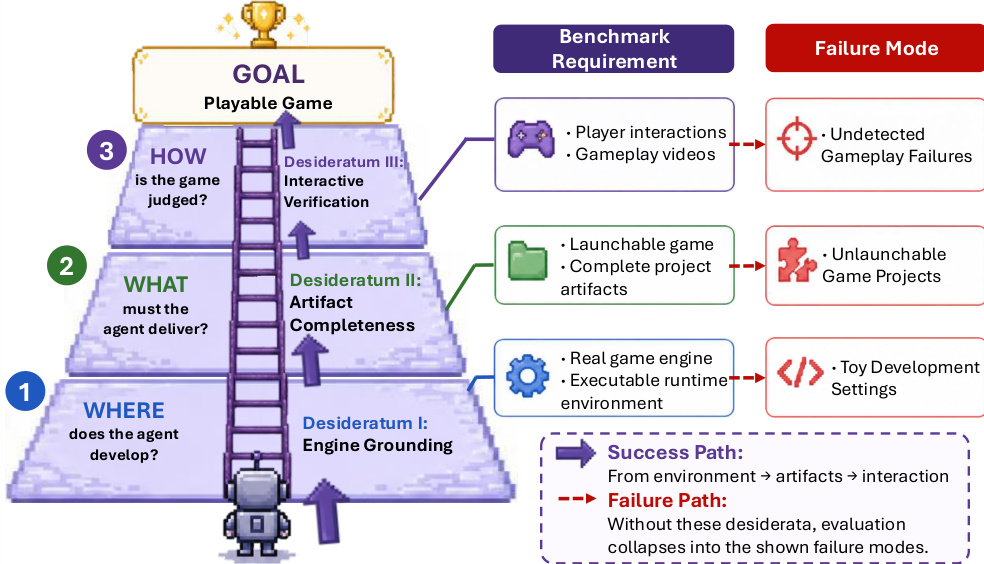
作者将 AI 游戏生成任务框架化为映射 (s,E)↦G,其中 Agent 将游戏规范 s 与目标环境 E 转换为可玩工件 G。为确保严格评估,该框架强制执行三大诉求:引擎接地性(要求在实际引擎中运行)、工件完整性(要求提供可启动项目)与交互验证性(通过游戏玩法进行评判)。
如下框架图所示,这些诉求构成金字塔结构,定义了游戏生成的成功路径。
该实现利用五阶段流水线来实例化此映射。流程始于任务封装,将自然语言规范、Godot 开发环境与隐藏量规结合。该量规将意图分解为四个评分类别:核心机制、内容深度、功能性视觉表现、艺术与呈现。
详细工作流程请参阅端到端评估流水线:
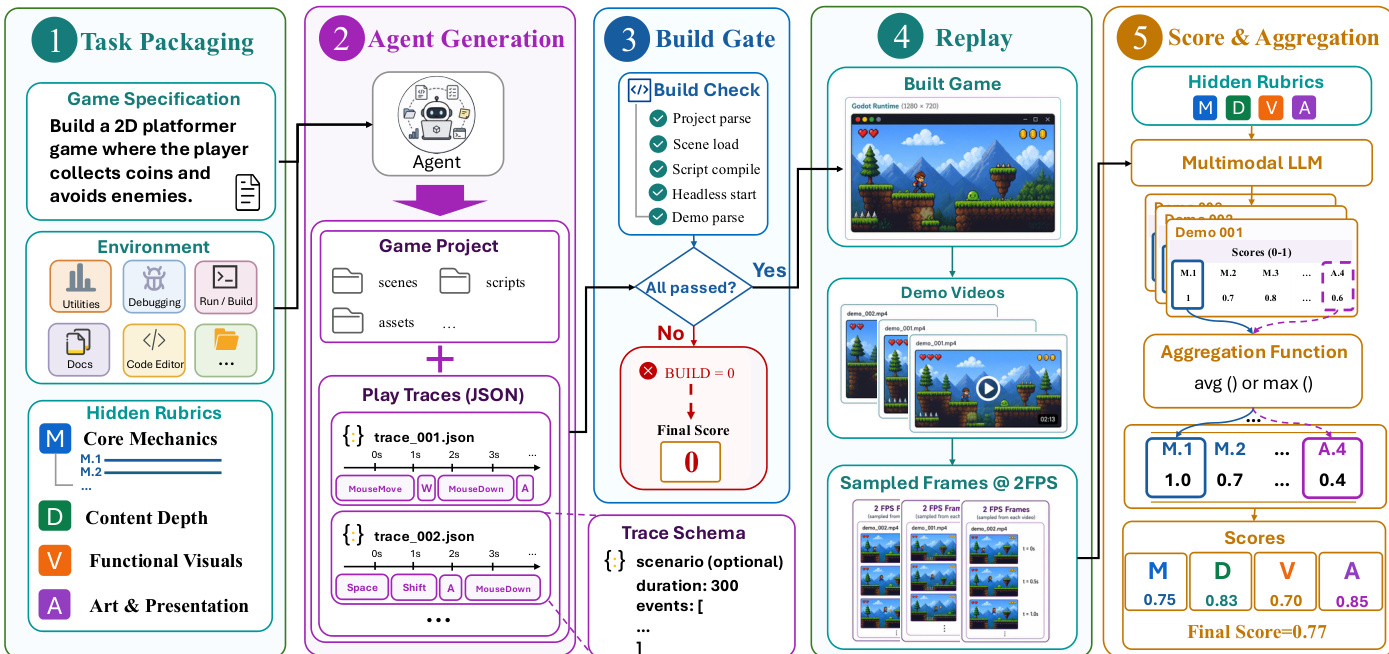
在 Agent 生成阶段,Agent 构建游戏项目 G 与一组可回放轨迹 Π。此阶段作为迭代循环运行,Agent 编写代码、运行项目、检查输出并修复错误。
请参阅核心循环图以了解 Agent 的迭代工作流程:
Agent 通过检查、编辑与修复游戏进行迭代,直至符合规范。轨迹 Π 被记录以提供标准化的交互证据。
提交物准备就绪后,构建门槛会验证其可启动性。若项目无法解析或启动,得分为零。对于有效提交物,回放阶段在 Godot 运行时中回放轨迹以生成游戏玩法视频与采样帧。
如问题定义图所示,Agent 与环境交互以生成最终可玩工件。
最后,评分与聚合阶段采用多模态评判器,将回放证据与隐藏量规进行对比评估。分数根据需求使用特定函数(如均值或最大值)进行聚合,并合并为最终加权分数,优先考量内容深度与呈现效果,以反映生成游戏的复杂性。
实验
七款前沿编码 Agent 在基于交互验证的基准测试中接受了评估,该测试通过渲染后的游戏玩法,从机制、内容深度、功能性视觉表现与呈现效果四个维度评估端到端游戏生成能力。实验验证了视觉反馈在迭代调试中的作用、过多命令行工具带来的有限收益,以及自动化可玩性评判器的可靠性。结果显示,Agent 经常能生成可运行的原型,但在组装连贯、打磨完善的完整游戏方面始终面临困难。视觉交互对于纠正错位的游戏状态至关重要,而单纯的执行量收益递减;自动化评判器展现出稳定的打分能力,与人类标注员相比仅表现出轻微的宽容度。这些发现证实,机械功能性与视觉打磨及内容深度之间仍存在松散耦合,最终表明可靠的创意软件生成需要基于交互验证的评估,而非传统的静态代码评估。
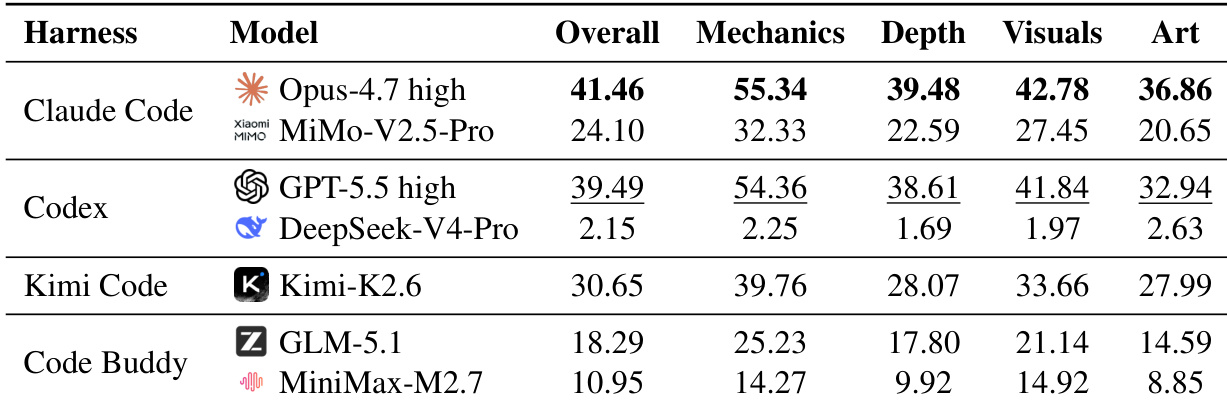
下表对比了不同游戏类型与评估量规下编码 Agent 的配置,显示核心机制的表现始终强于内容深度与呈现效果。Opus-4.7 与 GPT-5.5 等顶级模型取得了更高的总分,但即便如此,它们仍难以实现可靠的端到端游戏生成。数据凸显了生成可运行代码与创建视觉打磨完整的游戏之间存在的持续差距。在领先 Agent 中,核心机制的分数始终高于内容深度与呈现效果。顶级模型与 DeepSeek-V4-Pro 等低性能 Agent 之间存在显著差距。即使最佳配置也无法稳定实现请求的机制、视觉状态与呈现质量。
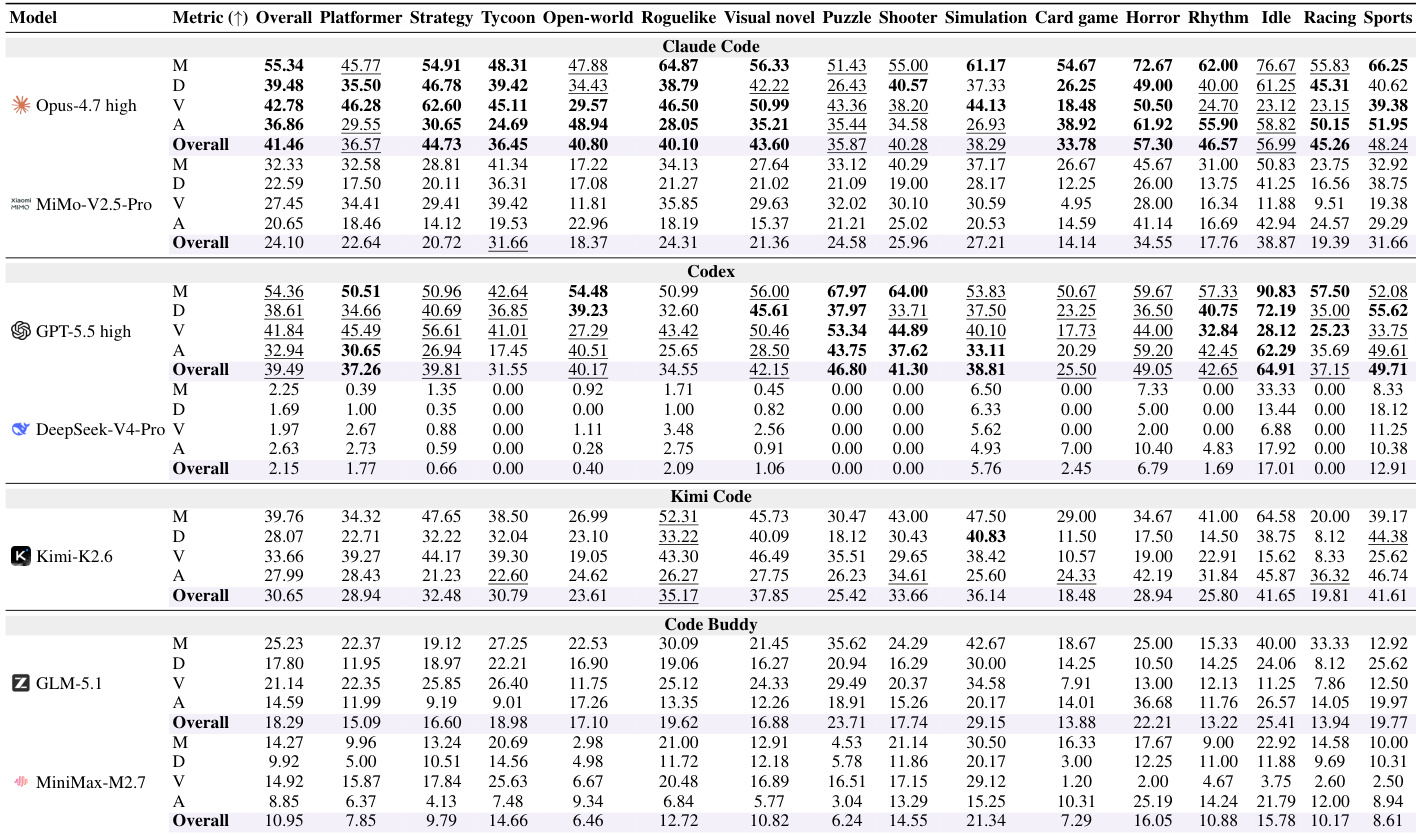
下表展示了针对 Kimi-K2.6 Agent 在三类游戏系列中的人类与多模态评判器分数的初步校准对比。评判器通常给出比人类标注员更高的总分,表明其具有轻微的宽容度。然而,评判器在功能性视觉表现上更为严格,而人类在内容深度与艺术呈现上更为严格。多模态评判器整体比人类评分者略微宽容。人类在内容深度与艺术呈现上更为严格,而评判器在功能性视觉表现上更为严格。人类与评判器分数之间的最大差异出现在放置类游戏系列中。
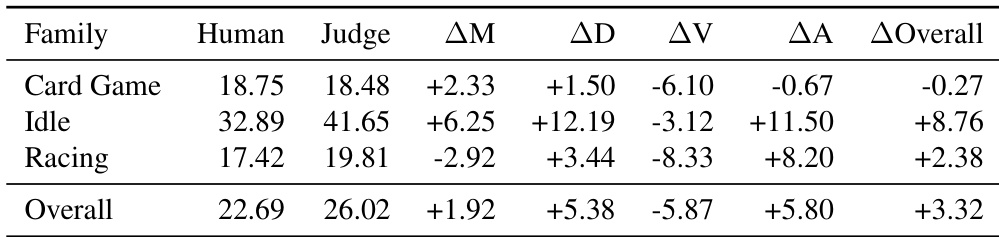
下表将多种基准测试与游戏生成评估的三大核心标准进行对比:引擎接地性、工件完整性与交互验证性。GameCraft-Bench 被视为最稳健的选项,通过使用 Godot 引擎、要求完整工件并支持交互验证,满足了全部三项要求。其他基准测试仅具备部分能力,例如 WebGameBench 满足完整性和验证性但缺乏引擎接地性,或 GameDevBench 提供引擎接地性但在完整性与验证性上不足。GameCraft-Bench 是唯一列出满足全部三项评估标准的基准测试:引擎接地性、工件完整性与交互验证性。GameDevBench 提供引擎接地性,但仅限于单一操作,且缺乏交互验证能力。基于 Web 的基准测试如 WebGameBench 支持工件完整性与交互验证,但未使用 Godot 等特定游戏引擎。
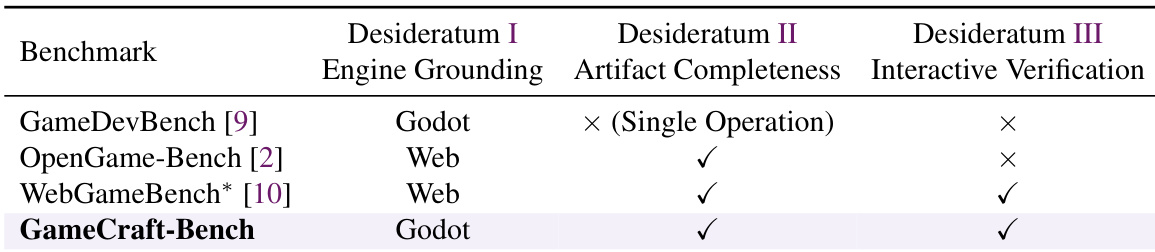
该实验在 GameCraft-Bench 上评估了七种编码 Agent 配置,显示当前前沿模型在端到端游戏生成方面面临挑战。Claude Code 中的 Opus-4.7 high 模型取得最高总分,GPT-5.5 high 紧随其后,而 DeepSeek-V4-Pro 表现显著较差。结果表明,Agent 在基础机制方面表现优异,但在交付具有足够深度与视觉连贯性的完整、打磨完善的游戏时存在不足。表现最佳的模型在核心机制上得分最高,而在内容深度与艺术呈现上面临更大困难。DeepSeek-V4-Pro 整体表现最低,经常无法生成评估所需的演示轨迹。即使最强的 Agent 在实现可靠的端到端游戏生成能力方面也相差甚远。
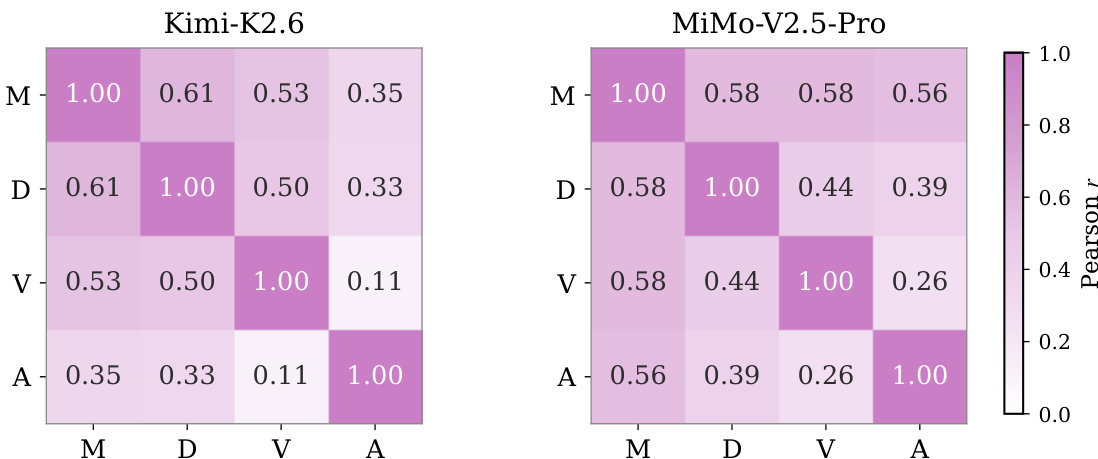
作者分析了 Kimi-K2.6 与 MiMo-V2.5-Pro 的量规类别相关性,以评估游戏生成能力的可分解性。研究结果显示,核心机制、内容深度与功能性视觉表现呈中度相关,而艺术与呈现通常与其他类别耦合度较低。Kimi-K2.6 在艺术与呈现和功能性视觉表现之间表现出弱相关性。MiMo-V2.5-Pro 显示出更强的全局耦合模式,艺术与呈现与其他类别之间的相关性更高。机制、深度与视觉表现的中度耦合表明,更强的交互循环往往会暴露更多的游戏状态与反馈。
实验在多种游戏类型中评估了多个编码 Agent 与基准测试,以评估端到端游戏生成能力,并通过人类与多模态评判器打分及综合量规框架验证了性能。Agent 评估显示,虽然顶级模型在实现核心机制方面始终表现优异,但在交付具有足够深度、视觉打磨完善的完整游戏方面存在困难,凸显了功能性代码与生产就绪体验之间的持续差距。基准测试对比验证了 GameCraft-Bench 作为最稳健评估框架的地位,这得益于其独特整合了引擎接地性、工件完整性与交互验证性。最后,相关性分析表明,机械与功能性视觉元素中度相互依赖,而艺术呈现相对独立,表明存在不同的底层生成动态。