Command Palette
Search for a command to run...
强化空间视觉语言模型中的双路径推理
强化空间视觉语言模型中的双路径推理
摘要
空间视觉语言模型(Spatial VLMs)在几何感知方面取得了显著进展,然而,涉及深度、距离与场景关系的多步推理等复杂空间推理任务仍具挑战性。此外,不同的空间查询需要截然不同的策略:部分问题最适合通过纯粹的语言逐步推理来解决,而另一些问题则需要在定量推理之前进行明确的三维定位。本文提出了一种用于空间视觉语言模型的双路径强化学习空间推理方法(SR-REAL)。该统一框架为空间VLM配备了两种互补的推理路径:仅语言推理(LOR),用于执行逐步的语言推导;以及检测后推理(DTR),通过区域tokens在显式几何推理之前检测三维几何线索(例如中心点或边界框)。SR-REAL首先经历一个冷启动监督微调阶段,该阶段构建了LOR与DTR的思维链监督信号,并引入了区域到三维接口;随后采用强化学习利用准确性与格式奖励对策略模型进行优化;针对DTR路径,基于离散中心点的检测奖励进一步细化了几何对齐效果。在多种空间基准测试中,SR-REAL显著优于现有的空间VLM基线模型:(i)单个经强化学习训练的模型同时支持两种推理路径,其中DTR凭借精确的三维定位在区域感知任务中表现优异,而LOR则提升了通用空间推理能力;(ii)联合训练两条路径能够促进相互增强;(iii)高质量且混合的冷启动数据对于强化学习优化的稳定性至关重要;(iv)该模型无需针对特定任务进行微调即可跨数据集与领域实现泛化,充分证明了LOR与DTR之间存在正向迁移效应。
一句话总结
作者提出了 SR-REAL,这是一种统一的空间视觉语言模型,通过两种互补策略增强复杂的多步推理能力:仅语言推理(Language-Only Reasoning)用于逐步的语言推导,以及检测后推理(Detect-Then-Reason)用于显式的 3D 几何定位。该模型采用两阶段训练流程,利用结构化的思维链监督与区域到 3D 的定位接口进行训练。
核心贡献
- SR-REAL 是一个统一的空间视觉语言框架,为模型提供两条互补的推理路径:仅语言推理(LOR)用于逐步的语言推导,以及检测后推理(DTR)用于基于区域对象定位后的显式 3D 几何推断。
- 训练流程采用两阶段管道,首先通过结构化的思维链监督与区域到 3D 的定位接口建立稳定的初始化,随后应用强化学习优化分组推理轨迹,并结合准确率、格式及 3D 中心检测奖励进行训练。
- 强化学习动态调节 LOR 与 DTR 路径的选择,使模型能够在无需已知相机位姿的情况下实现稳健的单视图空间推理。
引言
大型视觉语言模型在通用视觉理解方面表现优异,但在复杂空间推理(如解读 3D 布局、深度与遮挡关系)方面始终面临挑战。这一能力缺口阻碍了其在自动驾驶导航、具身机器人及增强现实等需要精确几何理解的应用中的部署。现有方法通常依赖缺乏几何感知能力的通用模型,或在单一架构中应用强化学习时未能支持多种推理策略。因此,现有系统无法在语言推导与几何定位推理之间灵活切换。作者利用名为 SR-REAL 的双路径框架来弥补这一差距。该框架为空间视觉语言模型配备了仅语言推理用于逐步语言推导,以及检测后推理用于显式 3D 坐标定位。通过将冷启动监督微调与针对性强化学习相结合,作者构建了一个统一系统,能够针对复杂空间查询动态优化两条推理路径。
数据集
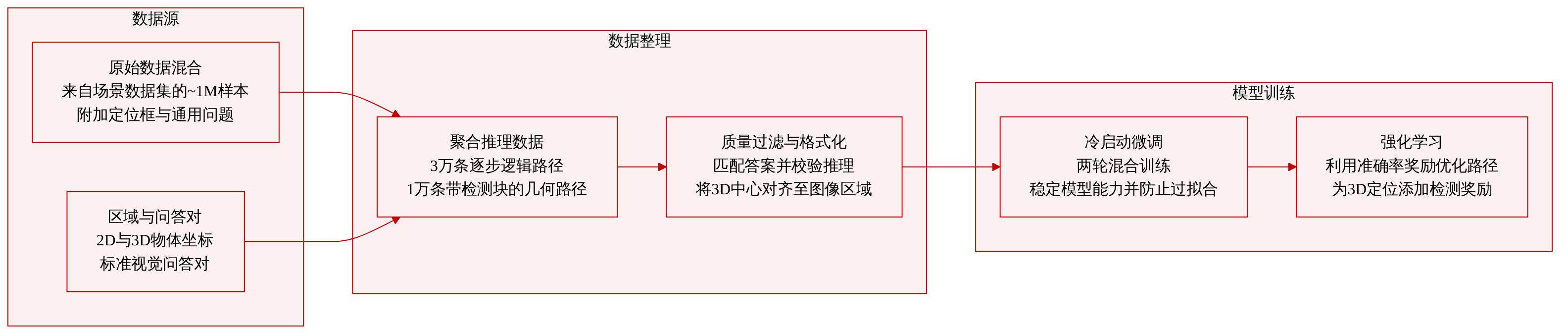
<answer> ... </answer>。
* Region token 用于将文本与视觉区域对齐。
* 3D 坐标:中心点、尺寸、方向。
- 逐节起草(思维或粗略文本大纲):
-
引言: 作者构建了一个全面的数据集管道,以支持双路径推理框架...
-
组成/来源:
- 冷启动数据集总计约一百万个样本。
- 来源包括 SPAR、CA-1M、NuScenes、RefCOCO、Omni3D、OmniNOCs、SRGPT、LLaVA-1.5 以及基于 OpenImages 派生的数据集。
-
子集:
- CoT-LOR: 3 万个样本。其中 1 万个来自 SPAR 的基础任务;2 万个来自 CA-1M 和 NuScenes 的复杂任务。仅包含语言轨迹。
- CoT-DTR: 1 万个来自 SPAR 的样本。包含 3D 检测与几何推理。
- 定位数据: 2D 数据来自 RefCOCO;3D 数据来自 Omni3D、OmniNOCs、CA-1M。
- 区域提示 VQA: 来自 SRGPT。
- 通用 VQA: 来自 LLaVA-1.5。
- RL 数据: 约 20 万道问题。约 10 万道 LOR,约 10 万道 DTR。来自 SPAR 和 OpenImages 派生数据。
-
使用/处理:
- 冷启动:微调两个 epoch。混合数据以防止过拟合。
- RL:DAPO 风格的 GRPO。在线过滤。奖励包含准确率、格式以及 DTR 的检测奖励。
- 过滤:两阶段。答案匹配加 LLM 验证器用于逻辑/计算。
- 元数据:DTR 使用
<detect>块。使用相机参数进行区域到 3D 投影。
-
语言优化(约束检查):
- 无破折号。 使用逗号、冒号、括号或重写。
- 列表结构。
- 解释者视角。
- 简洁。
-
起草内容:
- 数据集组成与来源:
- 作者通过混合专用推理数据与通用多模态及定位语料库,构建了约一百万个样本的冷启动数据集。主要来源包括 SPAR、CA-1M、NuScenes、RefCOCO、Omni3D、OmniNOCs、SRGPT、LLaVA-1.5 以及基于 OpenImages 派生的数据集。
- 各子集关键细节:
- CoT-LOR:3 万个样本,包含 1 万个来自 SPAR 的基础空间任务轨迹,以及 2 万个由 CA-1M 和 NuScenes 生成的复杂推理样本。这些样本仅包含纯语言的逐步解释,无几何监督。
- CoT-DTR:1 万个源自 SPAR 的样本,要求显式的基于区域的检测,随后进行定量几何分析。
- 定位数据:包含来自 RefCOCO 的 2D 定位以及来自 Omni3D、OmniNOCs 和 CA-1M 的 3D 定位,以支持区域到 3D 的定位。
- 区域提示 VQA:来自 SRGPT 的区域感知问答对,用于构建局部空间理解。
- 通用 VQA:来自 LLaVA-1.5 的非空间问答数据,用于保留广泛的多模态能力。
- RL 训练数据:约 20 万道空间问题,均匀分配给约 10 万道用于 LOR 的全局查询和约 10 万道用于 DTR 的区域定位查询,数据源自 SPAR 和 OpenImages 派生数据集。
- 使用与处理:
- 作者在强化学习之前,在冷启动混合数据上对模型进行两个 epoch 的微调,以建立推理能力。这种混合初始化可防止仅使用 CoT 数据训练时导致的一般多模态技能退化。
- 在强化学习期间,模型使用带在线过滤的组相对策略优化框架优化两条推理路径。奖励信号结合了任务准确率、格式奖励以及 DTR 路径的离散化检测奖励。
- CoT 数据经过两阶段过滤,其中答案匹配保留结论正确的样本,LLM 验证器检查逻辑一致性与中间计算准确性。
- 元数据与构建细节:
- 对于 DTR,作者利用已知相机参数将 EmbodiedScan 中的 3D 对象标注投影到图像平面,从而构建元数据以匹配 3D 坐标与 2D 区域。
- 数据格式强制要求结构化输出,其中 DTR 轨迹以包含 3D 边界框或中心点的
<detect>块开头,随后是推理步骤和最终答案。 - 模型区域分支的 Region token 用于将文本提及与视觉掩码或边界框对齐,以支持检测与推理期间的准确空间定位。
-
实验
评估在冷启动微调与强化学习框架内,通过语言推理与显式坐标检测范式,在标准及分布外空间基准上测试模型性能。主要实验与定性分析验证了模型能够借助对齐的 3D 坐标与避障路径规划,有效处理精确几何计算、多视图距离估算及复杂导航任务。消融研究进一步证实,两种推理模式的联合训练、精确的检测奖励以及多样化的冷启动数据,对于维持逻辑一致性与稳健泛化能力至关重要。最终结果表明,将显式空间定位与语言推导相融合,在保留基础感知能力的同时,显著提升了复杂推理性能。
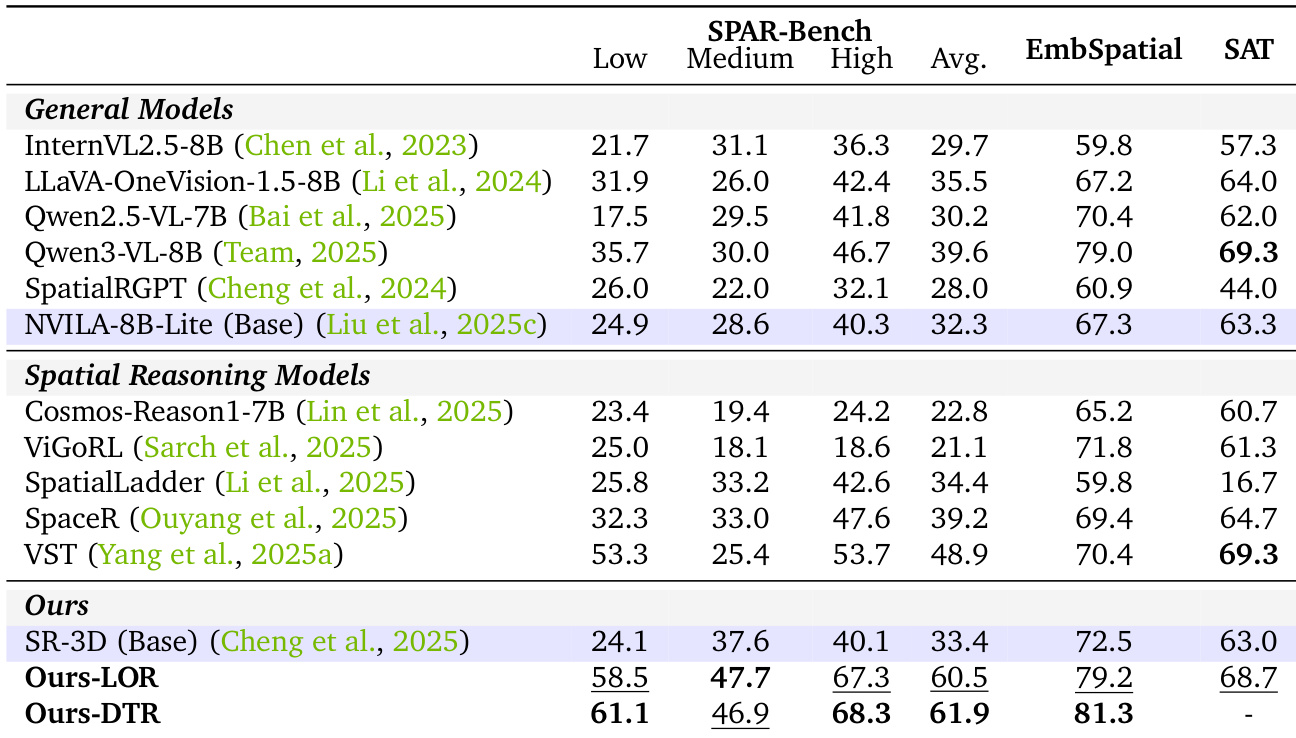
作者将所提模型与通用及专用空间推理基线在多个基准上进行对比评估。结果表明,语言推理(LOR)与检测后推理(DTR)变体在空间基准测试中均显著优于基础模型。具体而言,DTR 变体在 SPAR-Bench 和 EmbSpatial 数据集上取得最佳综合性能,而 LOR 变体在 SAT 基准上表现优异。DTR 方法在 SPAR-Bench 和 EmbSpatial 上交付最强结果,超越通用与专用基线。LOR 方法在 SAT 基准上取得领先分数,凸显其在全局空间推理任务中的稳健性。两种变体均大幅超越基础模型性能,验证了联合训练策略的优势。
消融分析表明,在训练过程中结合语言推理与显式坐标检测会产生相互促进的效果。完全集成的模型在不同空间基准上始终优于单模式变体,证明统一两种范式能够提升整体空间理解能力。联合训练两种推理方法比单独训练能获得更高准确率。接触几何检测数据可提升模型的语言空间推理能力。引入语言推理数据则能增强模型在显式坐标计算方面的表现。
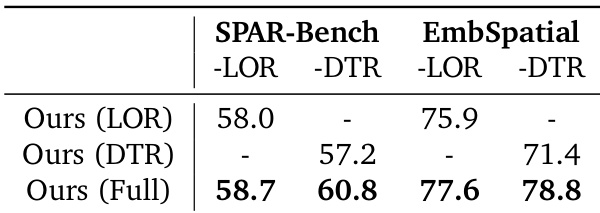
作者在多个空间基准上评估了初始训练阶段辅助定位监督的必要性。研究结果表明,省略该监督会持续降低整体准确率,且在要求精确三维定位的任务中下降幅度最大。相反,标准单视图空间问题的表现相对平稳,表明较简单的推理路径对显式定位线索的依赖程度较低。初始训练阶段的辅助定位监督对于维持复杂三维空间任务的高准确率至关重要。移除定位数据会导致专注于具身位置关系与 3D 场景理解的基准测试性能显著下滑。相较于更复杂的评估指标,标准单视图空间推理对缺失定位数据表现出更强的鲁棒性。

作者在全面的空间推理任务集上,将所提模型 Ours-LOR 与 Ours-DTR 与多种基线模型进行对比评估。结果表明,两种变体在几乎所有维度上均显著优于 SR-3D 基础模型。Ours-DTR 取得最高综合性能,尤其在距离相关任务中表现突出;Ours-LOR 保持高度竞争力,尤其在空间关系任务中。两种模型在几乎所有评估维度上均大幅超越 SR-3D 基础模型。Ours-DTR 取得最高平均综合性能,并在多数距离相关任务中领先。Ours-LOR 展现出强劲竞争力,尤其在空间关系任务中,其表现常与其他基线持平或超越。
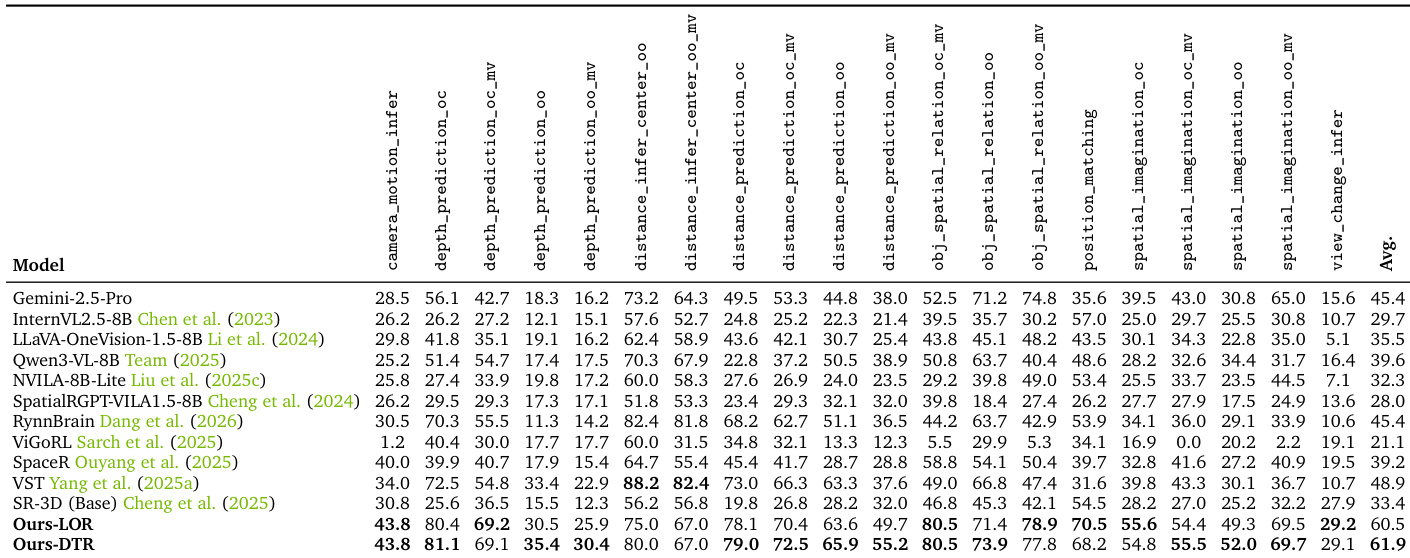
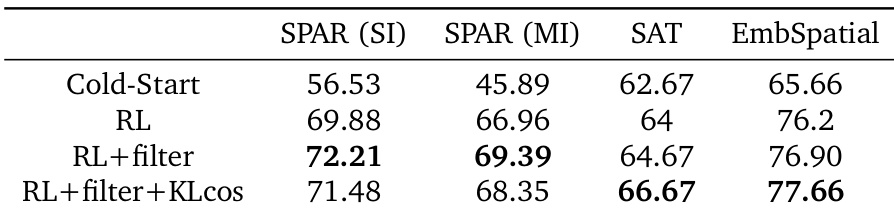
该表格评估了 LOR 训练阶段不同强化学习机制的影响。表格对比了多种空间基准上的性能,涵盖单视图与多视图任务,以及全局与具身空间推理。结果表明,加入在线过滤器可持续提升性能,而引入衰减的 KL 系数虽在域内任务上存在轻微权衡,但进一步增强了分布外基准的泛化能力。与标准强化学习相比,在强化学习过程中集成在线过滤器可全面提升所有评估基准的性能。应用衰减 KL 系数能够改善 SAT 与 EmbSpatial 等分布外任务的泛化能力,尽管其略微降低了主要 SPAR 基准的性能。结合冷启动、强化学习、过滤与 KL 衰减的完整训练管道在全局与具身空间推理任务上取得最强结果。
作者在多个空间推理基准上将所提出的语言推理与检测后推理变体与成熟基线进行对比,以验证其综合训练框架的有效性。结果表明,联合训练两种范式会产生相互促进的效果,检测后推理方法在距离与具身空间任务中表现优异,而语言变体在全局关系推理中更具优势。消融研究进一步证实,辅助定位监督对复杂三维定位不可或缺,而集成在线过滤与衰减 KL 系数的强化学习机制能显著提升分布外任务的泛化能力。最终,相较于单模式或基础模型,该集成方法大幅提升了整体空间理解能力。