Command Palette
Search for a command to run...
GeneralVLA-2:几何感知重建与受控记忆用于机器人规划
GeneralVLA-2:几何感知重建与受控记忆用于机器人规划
Haoyu Wang Guoqing Ma Zeyu Zhang Yandong Guo Boxin Shi Hao Tang
摘要
通用视觉-语言-动作系统需要以物体为中心的3D证据和可复用的操作经验,以规划可靠的机器人轨迹。GeneralVLA提供了一个分层接口,用于将语言指令与RGB-D观测数据转换为3D末端执行器路径,但仍存在两个瓶颈。首先,单目SAM3D风格的物体重建可能会产生姿态和未见几何结构的幻觉,而当提供校准的多视角观测数据时,操作任务更受益于稳定的物体形状。其次,原始的KnowledgeBank主要检索语义相似的片段并追加新知识,这使得难以控制记忆质量、冲突、置信度以及几何相关性。为解决第一个挑战,我们引入了GeoFuse-MV3D,这是一种由几何先验引导的MV-SAM3D重建分支,它利用输入视角掩码验证外部几何线索,应用软视觉体支撑,执行逐轴细化,并在保留外观的同时仅融合几何信息。为解决第二个挑战,我们将KnowledgeBank升级为一种受控的长期记忆系统,该系统具备明确的质量、置信度、生命周期、验证器与冲突元数据,并结合了面向精确性的检索机制。最后,我们在GSO-30上评估了重建分支,并在Terminal-Bench 2.0和SWE-Bench Verified上评估了记忆模块;GeoFuse-MV3D相较于MV-SAM3D基线,将CD和LPIPS分别降低了2.20%和2.02%,同时将PSNR和SSIM分别提升了2.36%和1.03%;KnowledgeBank相较于ReasoningBank,在Terminal-Bench SR上提升了4.53%,在SWE-Bench解决率上提升了3.73%,同时将AS分别降低了4.95%和5.65%。代码:https://github.com/AIGeeksGroup/GeneralVLA-2。网站:https://aigeeksgroup.github.io/GeneralVLA-2。
一句话总结
GeneralVLA-2 集成了 GeoFuse-MV3D —— 一个几何先验引导的多视角重建分支,通过视觉外壳支撑和逐轴细化减少物体幻觉 —— 以及一个受控的长期记忆系统,该系统利用质量、置信度和冲突元数据升级 KnowledgeBank,实现面向精度的检索,从而在 GSO-30 上提升重建保真度,并在 Terminal-Bench 2.0 和 SWE-Bench Verified 上取得更高的任务成功率。
核心贡献
- GeoFuse-MV3D 将 MV-SAM3D 扩展为将外部 3D 估计视为几何先验,根据输入掩码对其进行验证,并应用软视觉外壳支撑、逐轴细化以及仅几何融合,同时保留固定视角的外观。在 GSO-30 基准测试上,与 MV-SAM3D 基线相比,该方法将 Chamfer Distance 降低了 2.20%,LPIPS 降低了 2.02%,同时将 PSNR 提高了 2.36%,SSIM 提高了 1.03%。
- KnowledgeBank 被升级为一个受控的长期记忆系统,其中记录存储了质量、置信度、生命周期状态、验证器元数据和冲突链接,从而实现面向精度的检索,而非纯粹的语义匹配。在 Terminal-Bench 2.0 上,这种受控记忆将成功率提升了 4.53%,并将动作步骤减少了 4.95%;在 SWE-Bench Verified 上,它将解决率提高了 3.73%,步骤减少了 5.65%。
- 实验评估在 GSO-30 上对 GeoFuse-MV3D 重建分支以及在 Terminal-Bench 2.0 和 SWE-Bench Verified 上对受控记忆模块进行了基准测试,证实了重建保真度和 agent 规划性能的一致提升。
引言
像 GeneralVLA 这样的机器人操作规划器将问题分解为感知、三维推理和轨迹执行,依赖物体中心几何和可复用经验来生成安全、可解释的末端执行器路径。先前的工作存在两个弱点:单目 SAM3D 风格的重建常常幻觉看不见的背面结构和姿态,这可能会破坏抓取间隙和碰撞检测,而原始的 KnowledgeBank 仅通过语义相似性检索过去的 episode,使其无法管理记忆质量、过时性、冲突或与当前场景的几何相关性。作者在 GeneralVLA-2 中解决了这两个不足。他们引入了 GeoFuse-MV3D,一个多视角重建分支,该分支将外部几何估计视为先验,根据输入掩码验证它们,应用软视觉外壳和逐轴细化,并执行保守的仅几何融合以提供稳定的形状证据。同时,他们将记忆模块升级为一个受控的长期系统,其中每条记录都携带置信度、生命周期、验证器和冲突元数据,从而实现面向精度的检索,在规划器使用之前过滤掉不安全或不合适的经验。
方法
作者提出了 GeneralVLA-2,一个为桌面操作任务设计的系统,将问题分解为示能感知、3D 轨迹规划和底层执行。如下图所示,流水线从校准的观测中构建物体中心的 3D 证据,将具备 3D 能力的规划 agent 同时基于精细的物体几何和受控的 KnowledgeBank 进行条件设定,最后通过机器人抓取和运动模块执行规划的轨迹。
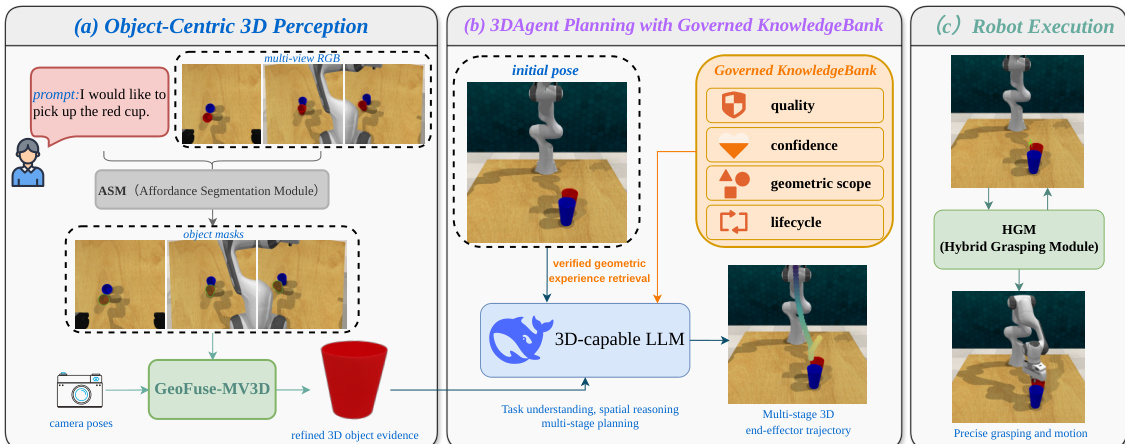
为了补充原始的示能分割,作者引入了 GeoFuse-MV3D,一个保守的多视角重建分支。当可用的校准多视角 RGB-D 观测可用时,该分支通过使用固定的输入视图和掩码来正则化几何,从而减少单目幻觉。有关该分支的详细架构,请参考框架图。该过程从多视角输入开始,包括 RGB 观测、物体掩码、相机内参和位姿。通过基线多视角重建方法生成初始高斯对象。
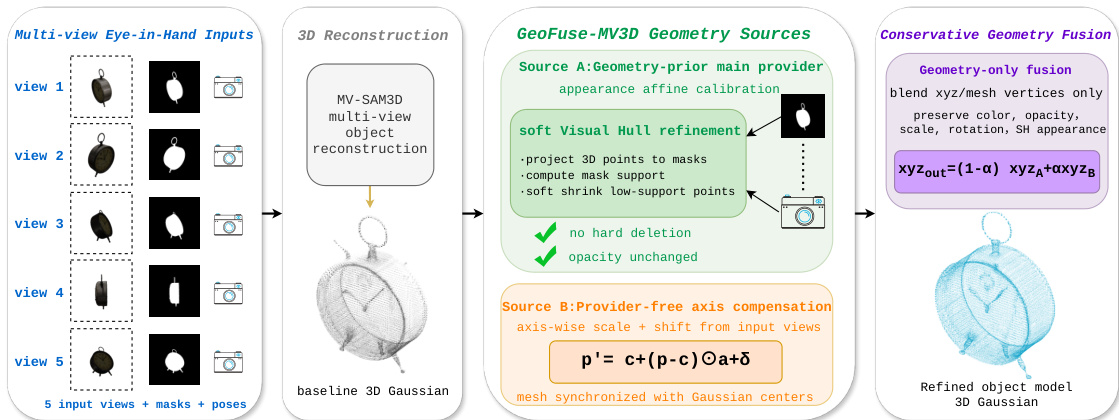
GeoFuse-MV3D 利用两个互补的几何源。源 A 包含一个外部几何先验提供者,并应用轻量级外观仿射校准。源 B 是一个输入视角轴补偿分支,无需外部提供者即可运行。两个源都根据输入掩码进行检查,以计算掩码一致性分数 s(p)。系统不会删除低支撑点,而是将低支撑转换为一个小的向内几何修正 p′=c+(p−c)(1−λ(p)),其中 c 是物体中心,λ(p) 受限于一个小的最大收缩比。然后对高斯中心应用低维逐轴修正,并将相同的变换同步到网格顶点。最后,系统仅混合两个源的几何坐标,同时保留来自可信源的颜色、不透明度、尺度、旋转和球谐外观场。
作者还将原始追加式记忆替换为受控的 KnowledgeBank,以改善中级规划器。如下图所示,该记忆子系统写入经验证器标记的记忆,检索高质量记录,并在为 3DAgent 规划器提供条件前管理其生命周期。
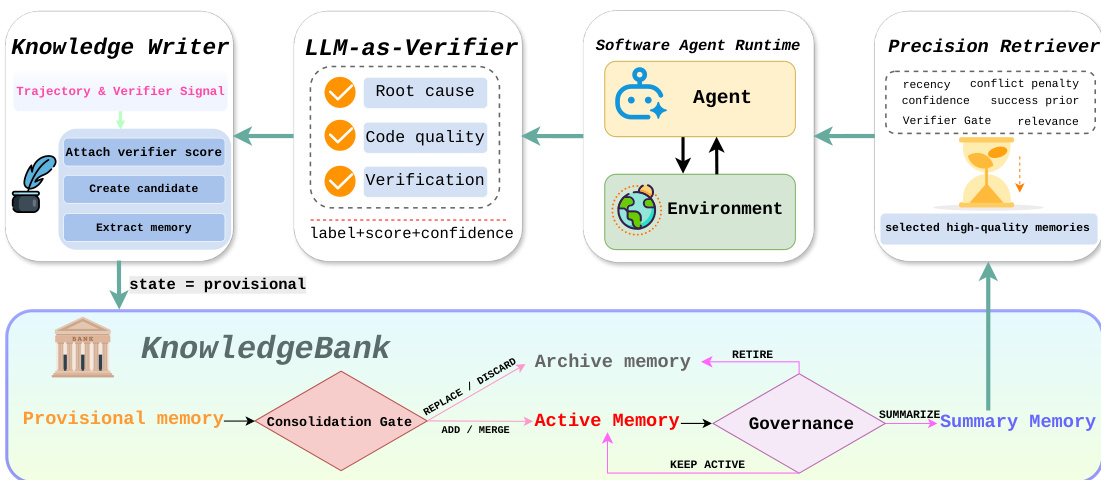
每个可复用的操作经验被存储为结构化记录 m=(q,c,y,z,κ,R,L,v),其中 q 是源查询,c 是可复用内容,y 是记忆类型,z 是生命周期状态,κ 是置信度,R 是验证器推导的质量分数,L 存储冲突或取代链接,v 存储验证器元数据。任务完成后,验证器根据任务完成度、空间一致性和碰撞安全等标准对候选知识进行评分。检索是面向精度的,结合了文本相关性、置信度、成功先验和新鲜度,同时对冲突和过时进行惩罚。检索到的记录被渲染为 3DAgent 的有界规划上下文,其中程序性记忆作为可选提示,失败记忆作为约束。在固定的活动记忆预算下执行合并操作,包括添加、合并、替换、丢弃、摘要和归档。
在推理时,3DAgent 接收语言指令、当前 3D 场景表示、可用的来自 GeoFuse-MV3D 的精细物体证据,以及结构化的 KnowledgeBank 块。然后它输出底层策略所期望的多阶段末端执行器轨迹。这种分离确保了与原始机器人栈的兼容性,同时显著改善了规划所用的几何和记忆证据。
实验
评估首先在与 MV-SAM3D 基线相同的输入条件下,在 GSO-30 多视角基准上验证了 GeoFuse-MV3D,通过几何先验引导和保守融合,在所有重建指标上显示了持续的改进。然后在 Terminal-Bench 和 SWE-Bench 上单独测试了 KnowledgeBank 模块,受控的记忆准入、验证和生命周期管理在多个骨干网络上比仅追加检索实现了更高的成功率和更低的平均步骤数。在机器人规划中,整个系统在所有 14 个 RLBench 任务上实现了免训练成功,优于先前的方法,并证明移除 KnowledgeBank 会降低性能,而真实世界实验证实了在四个不同物体姿态的操作任务上的可靠执行。总体而言,结果表明分层视觉-语言-动作系统受益于更忠实的物体几何和受控的长期记忆,尽管性能仍依赖于校准的输入,并且该方法有意地保守。
作者在 GSO-30 基准上将 GeoFuse-MV3D 与 MV-SAM3D 基线进行了评估,使用相同的输入视图和配置。结果表明,GeoFuse-MV3D 一致地改善了所有四个重建指标,通过几何先验引导和掩码验证展示了更好的几何和外观质量。GeoFuse-MV3D 在所有评估的重建指标上均优于 MV-SAM3D 基线。该方法取得了更低的 Chamfer Distance 和 LPIPS 分数,表明几何精度和感知质量有所提高。GeoFuse-MV3D 的 PSNR 和 SSIM 分数更高,反映了增强的图像保真度和结构相似性。

作者在仿真中的一组机器人规划任务上评估了 GeneralVLA-2,并将其与 VoxPoser、CAP 和 Hamster 等基线进行比较。结果显示,GeneralVLA-2 在大多数任务中取得了最高的成功率,并且是唯一能够为所有评估任务成功生成轨迹的方法。此外,移除 KnowledgeBank 模块的消融研究表明性能持续下降,凸显了受控经验复用在轨迹规划中的重要性。在大多数仿真任务中,GeneralVLA-2 的成功率优于基线方法。GeneralVLA-2 是唯一能够为所有评估任务生成成功轨迹的方法,而基线方法覆盖的任务较少。移除 KnowledgeBank 模块一致地降低了成功率,表明检索到的经验指导改善了规划性能。
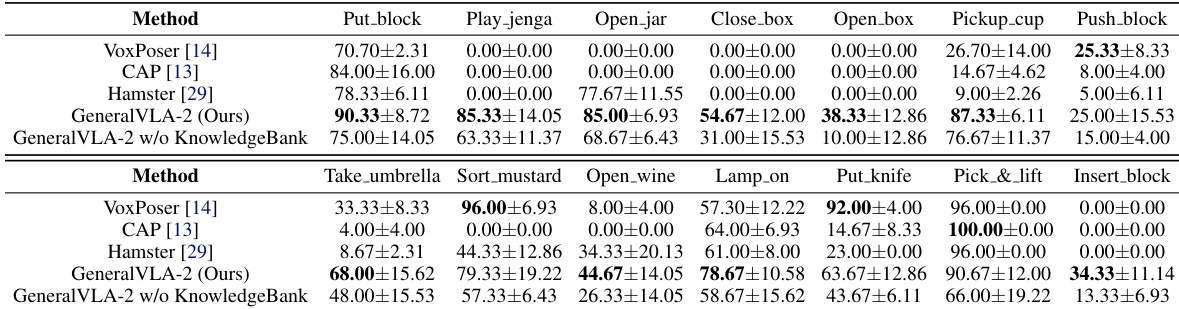
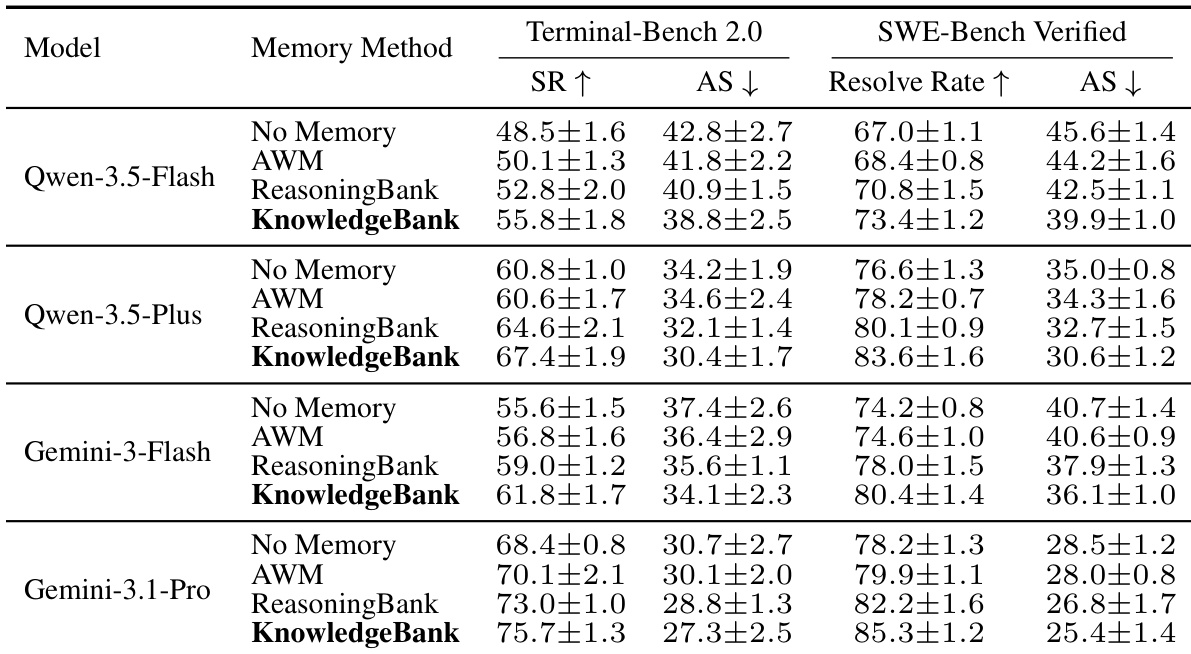
作者在长时域 agent 基准上使用四种不同的模型骨干网络评估了 KnowledgeBank 模块。结果表明,与消融变体相比,完整配置一致地取得了最高的成功率和解决率,同时所需平均步骤最少。这支持了明确管理记忆准入、检索和生命周期比简单的语义检索更有效的结论。完整的 KnowledgeBank 变体在所有指标和模型骨干网络上均优于所有消融版本。移除特定的治理组件(如准入或生命周期管理)会持续降低性能并增加解决问题所需的步骤。语义检索基线表现最差,表明受控的记忆管理显著改善了经验复用和效率。
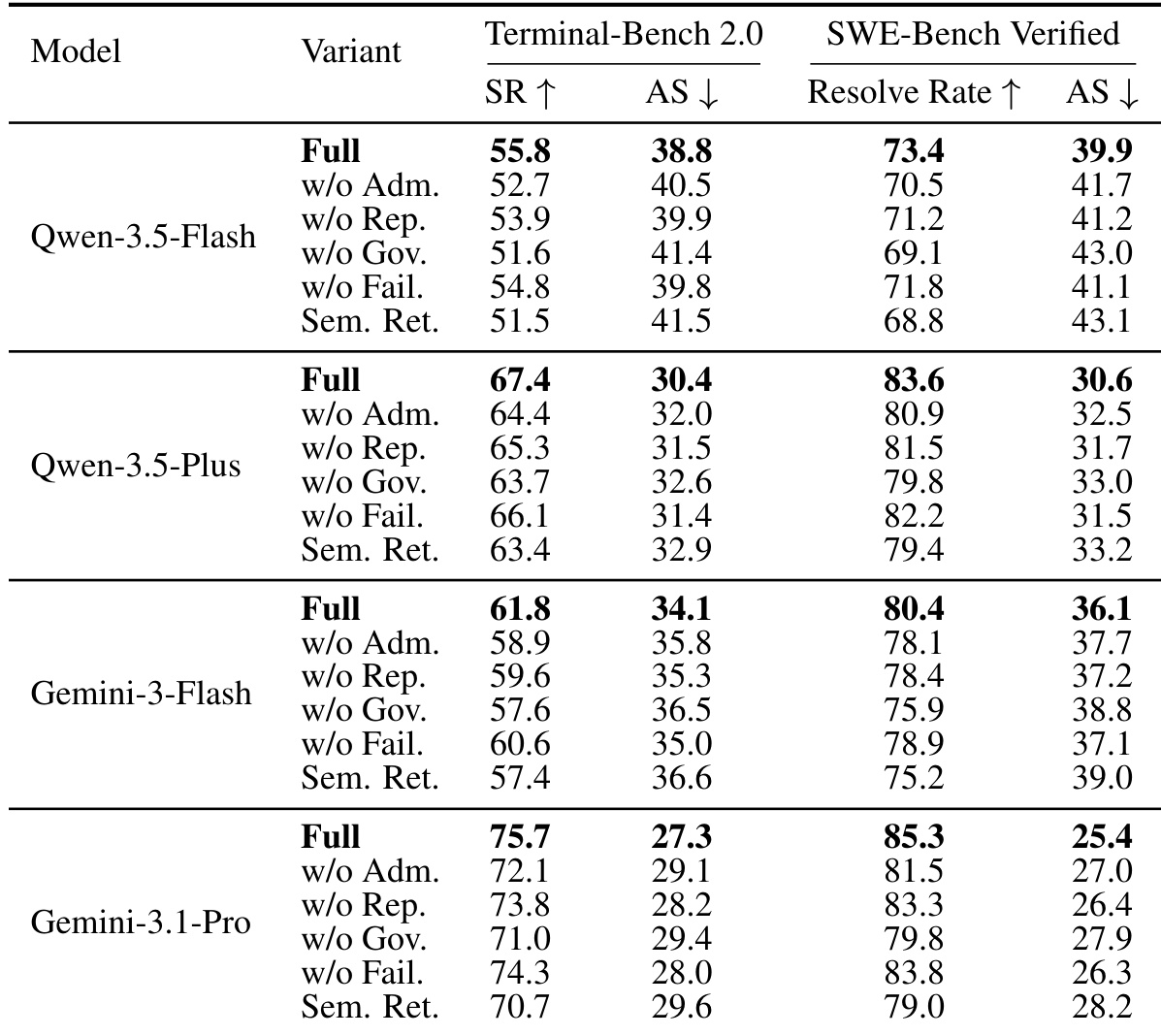
作者在 Terminal-Bench 2.0 和 SWE-Bench Verified 上跨四个模型骨干网络评估了 KnowledgeBank 记忆治理模块。结果表明,KnowledgeBank 在成功率和效率方面一直优于 ReasoningBank 和 AWM 等基线方法。这支持了明确治理记忆准入和检索可以改善经验复用的设计选择。与其他记忆方法相比,KnowledgeBank 在所有测试模型上取得了最高的成功率和解决率。该方法持续减少了解决问题所需的平均步骤,表明效率更高。在多个模型骨干网络中观察到性能提升,验证了记忆治理方法的鲁棒性。
作者在真实世界的机器人操作任务上以免训练设置评估了 GeneralVLA-2,并将其与 CAP 和 RoboPoint 基线进行比较。结果表明,GeneralVLA-2 在所有四个测试任务中取得了最高的成功率,显著优于在打开抽屉等动作上挣扎的基线方法。在所有评估的真实世界操作任务中,GeneralVLA-2 一致地优于零样本基线 CAP 和 RoboPoint。该方法在基线模型取得零成功的任务(如打开抽屉和移动喷瓶)中展示了稳健的性能。与基线相比,GeneralVLA-2 在分类物体和打开罐子等复杂操作任务中保持了领先的成功率。

GeoFuse-MV3D 在 GSO-30 基准上与 MV-SAM3D 使用相同输入进行评估,通过几何先验引导和掩码验证,持续改善了所有重建指标,实现了更好的几何和外观质量。GeneralVLA-2 在仿真机器人规划任务和真实世界操作上进行测试,优于 VoxPoser、CAP 和 RoboPoint 等基线,并且是唯一能够在所有仿真任务中生成成功轨迹的方法,同时在诸如打开抽屉等具有挑战性的真实世界动作上表现出色。KnowledgeBank 模块在长时域 agent 基准和软件工程基准上跨多个骨干网络进行评估,与消融变体和简单语义检索基线相比,完整的受控记忆配置一致地取得了最高的成功率和最少的步骤。在所有实验中,研究结果验证了对记忆准入、检索和生命周期的明确治理,以及几何先验集成,显著改善了性能、鲁棒性和效率,优于基线方法。