Command Palette
Search for a command to run...
ACE-Ego-0:统一第一人称视角的人类与机器人数据用于VLA预训练
ACE-Ego-0:统一第一人称视角的人类与机器人数据用于VLA预训练
摘要
视觉-语言-动作(VLA)模型受益于大规模且多样化的具身数据,然而扩展机器人轨迹的收集成本高昂且耗时费力。近期的研究表明,大规模的第一人称视角人类视频能够为预训练提供互补的真实世界监督信号。然而,由于动作空间、具身结构、时间动态以及监督质量存在差异,在人类数据和机器人数据上进行联合训练仍然具有挑战性。我们提出了ACE-EGO-0,这是一种统一的VLA预训练框架,能够协同利用异构数据源。为了从第一人称视角人类视频中提取大规模预训练监督信号,我们构建了一个可扩展的第一人称视频到动作流水线,将原始人类视频转换为机器人格式的伪动作轨迹。为了使这些标签与机器人演示具有可比性,ACE-EGO-0采用了一种统一的动作表示方法,该方法基于相机空间动作、形态条件以及时间对齐的动作分块。为了稳健地利用来自第一人称视角人类视频的噪声伪动作监督信号,我们设计了一种可靠性感知训练目标,并引入人类辅助损失函数,将监督信号集中于可靠的部分。我们在4530小时的机器人和仿真数据,以及1480小时的带有伪动作标签的第一人称视角人类数据上实现了ACE-EGO-0。实验表明,在可靠性感知加权下引入大规模人类监督信号,能够一致性地提升统一联合预训练和监督微调的效果。ACE-EGO-0在RoboCasa GR1 TableTop和RoboTwin 2.0上取得了最先进的性能,同时展现出向真实世界双臂操作任务的强大迁移能力。
一句话总结
ACE-EGO-0 是一个统一的视觉-语言-动作预训练框架,通过将原始视频转换为机器人格式的伪动作,将机器人和仿真数据与第一人称人类视频相结合。该方法采用基于相机空间的统一动作表示,并设计了一个可靠性感知目标,将监督信号集中于可靠数据上,从而在 RoboCasa GR1 TableTop 和 RoboTwin 2.0 上取得了最先进的性能,同时展现出强大的真实世界双臂操作迁移能力。
核心贡献
- ACE-EGO-0 是一个统一的视觉-语言-动作预训练框架,通过共享的相机空间动作表示、跨形态学结构条件约束以及时间对齐的动作分块,对齐异构数据源。该架构在联合训练前系统性地解决了坐标系、物理时长和运动学结构的不匹配问题。
- 一套可扩展的第一人称视频到动作的流水线将原始人类影像转换为机器人格式的伪动作轨迹,以实现大规模监督。该框架引入了可靠性感知训练目标,利用步级和数据集级的质量估计动态调整辅助损失权重,从而缓解跟踪噪声和估计偏差。
- 该模型在 4530 小时的机器人和仿真数据以及 1480 小时标注了伪动作的人类视频上进行训练,持续提升了联合预训练和监督微调的效果。ACE-EGO-0 在 RoboCasa GR1 TableTop 和 RoboTwin 2.0 基准测试中取得了最先进的性能,并在真实世界双臂操作任务中展现出强大的迁移能力。
引言
视觉-语言-动作模型需要海量且多样化的具身数据集来学习可泛化的操作技能,但扩展机器人数据采集的成本依然高昂。第一人称人类视频提供了一种高度可扩展的替代方案,但将其与机器人演示相结合会引入显著的技术障碍。现有方法难以对齐差异化的坐标系、运动学结构与控制频率,而直接使用人类视频中的噪声伪动作标签进行训练会导致策略性能下降。本文利用统一的预训练框架,通过共享的相机空间表示、形态学条件约束和时间对齐的动作分块,将大规模第一人称影像转换为机器人兼容的动作轨迹。此外,研究团队引入了可靠性感知训练目标,动态权衡监督信号的质量,使模型能够安全地结合高保真机器人演示与互补的人类视频数据,从而实现最先进的操作性能。
数据集

数据集构成与来源
- 研究团队构建了包含超过 6000 小时异构数据的 ACE-Ego-0 预训练池,数据来源于机器人演示、仿真轨迹数据以及标注了伪动作的第一人称人类视频。
- 机器人与仿真数据源包括 AgiBot Alpha 与 Beta 演示、Galaxea R1Lite 数据、AgiBot DigitalWorld 仿真环境、包含 24 个任务且各 1000 个 episode 的 RoboCasa Tabletop 仿真,以及超过 1800 小时自主采集的 Galbot 数据。
- 人类视频数据源涵盖 Ego4D、EgoExo4D、EPIC-KITCHENS-100、HOI4D、EgoDex 和 Xperience-10M,覆盖多样的厨房、家庭与工坊场景,以捕捉长尾操作行为。
子集详情与过滤规则
- 机器人与仿真数据涵盖人形、单臂轮式及移动双臂形态,控制频率介于 10 至 30 Hz 之间,提供基于传感器反馈的末端执行器动作标签。
- 人类视频片段被过滤至 4 至 30 秒的时长范围,以确保包含完整的操作基元。
- 研究团队应用了自我交互过滤器,基于人脸检测置信度阈值剔除以观察者为中心的片段;同时采用字幕过滤机制,仅保留同时包含操作动词与物体名词的片段。
- 该处理流水线最终从人类视频源中生成 1478 小时标注了伪动作的视频片段。
训练用途与混合策略
- 研究团队在数据集组级别进行数据采样,通过可控权重独立管理各数据源的贡献比例。
- 机器人数据源通过主动作目标进行监督,而人类视频数据源则通过可靠性感知的人类损失函数进行路由,以适配基于视觉的伪标签较低的保真度。
- 这种分离机制使大规模人类视频语料库能够提供广泛的视觉与行为覆盖,同时避免淹没高保真机器人演示数据。
处理与标准化详情
- 利用校准后的相机外参,将机器人末端执行器的位姿转换至头部相机坐标系。
- 人类数据经历包含数据整理、视频筛选、3D 手部重建、动作参数化与质量控制五个阶段的处理流水线。
- 重建过程采用 SAM3 跟踪与 HaMeR 进行 MANO 参数估计,随后利用 VIPE 估计的相机位姿进行全局轨迹优化,以降低抖动与重投影误差,最终将动作转换至头部相机坐标系。
- 动作被标准化为统一的每臂 22 维双臂向量,包含位置、连续 6D 旋转、夹爪状态及活动标志位。
- 夹爪距离被线性归一化至 0.04 至 0.10 米范围,变化极小的轨迹被分配中性夹爪状态。
- 质量控制过滤器剔除包含 NaN 值、运动能量不足、出现速度尖峰或表现出不可信双臂关联的 episode。
- 研究团队通过掩码化处理深度非正或投影超出图像边界的帧来验证轨迹有效性。
实验
ACE-EGO-0 在两项针对人形与双臂操作的仿真基准测试以及实体机器人平台上进行评估,以验证其跨域泛化能力与部署简便性。结果表明,相机空间动作接口与形态无关设计能够稳健执行长周期序列与高接触协调任务,且无需依赖特定数据源的坐标变换。组件与数据消融实验进一步证实,形态学条件约束、时间对齐与可靠性感知训练对稳定学习至关重要;同时,人类第一人称视频通过填补数据稀缺微调阶段的动作覆盖空白,显著提升了模型适应能力。综合来看,这些发现证实了统一预训练结合相机空间预测与人类视频增强,能够为复杂的真实世界操作任务生成高度可迁移的策略。
研究团队明确了 ACE-EGO-0 模型的超参数设置,包括辅助损失权重、人类通道先验、步长权重、数据集先验及平滑设置。人类通道先验赋予位置通道较高权重,同时降低旋转与夹爪通道的权重。步长权重与数据集先验通过相对于机器人参考值的数据集特定百分位数与比例进行校准。辅助损失采用特定权重与 Huber 转换参数。人类通道先验优先关注位置数据而非旋转与夹爪通道。步长权重与数据集先验利用从数据中派生的百分位数与比例进行自适应调整。
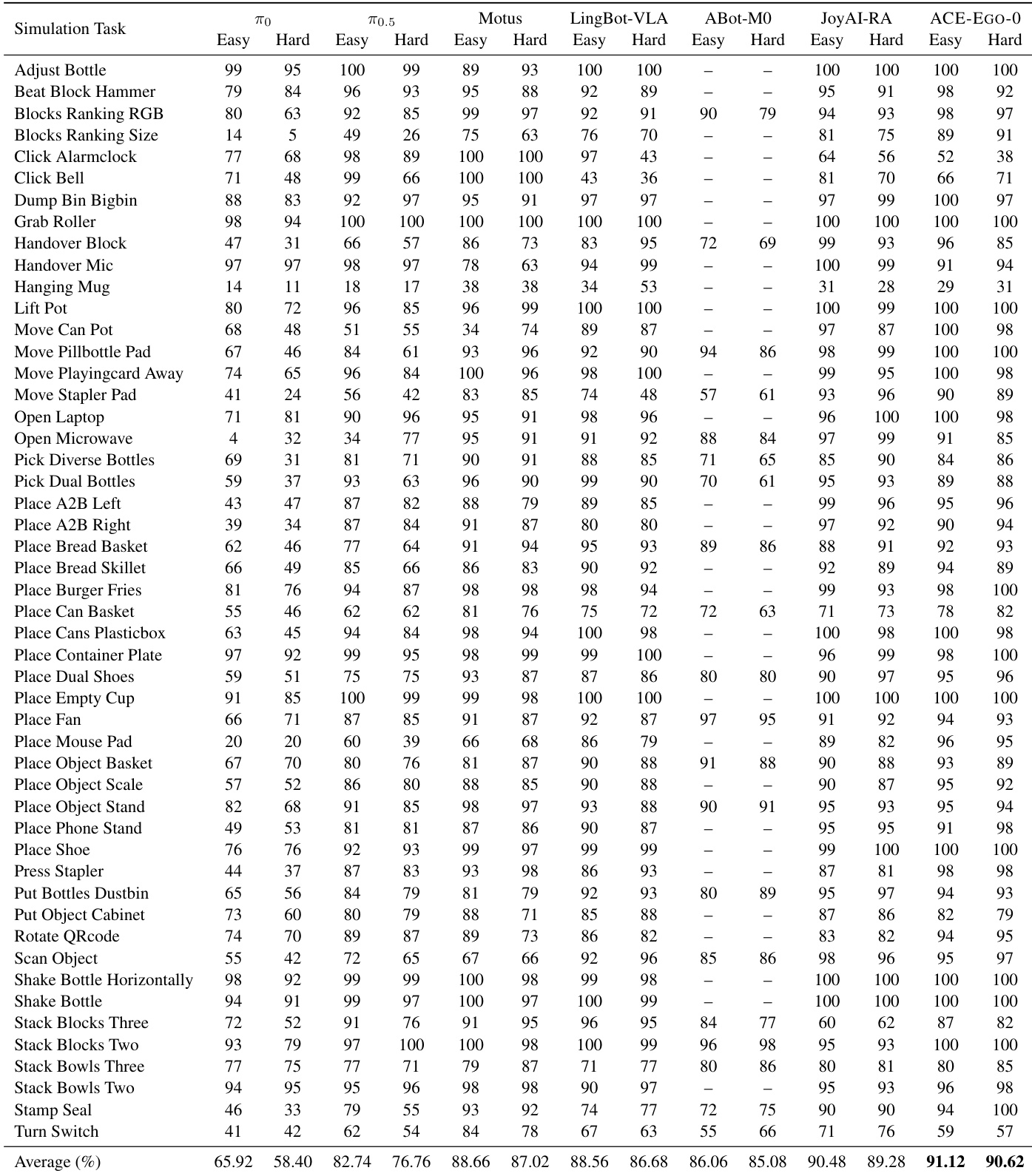
结果显示,在 RoboTwin 2.0 基准测试的简单与困难设置中,ACE-EGO-0 均取得了最高的平均成功率,超越所有基线模型。该模型在双臂协调与工具使用等多样化操作任务中展现出强大的泛化能力。与 JoyAI-RA 和 LingBot-VLA 等基线相比,ACE-EGO-0 在两种难度设置下均保持最高平均成功率。性能提升均匀分布于抓取、放置与双臂协调等多样化操作基元中。在两种难度级别下,该模型均对次优基线保持稳定的领先优势。
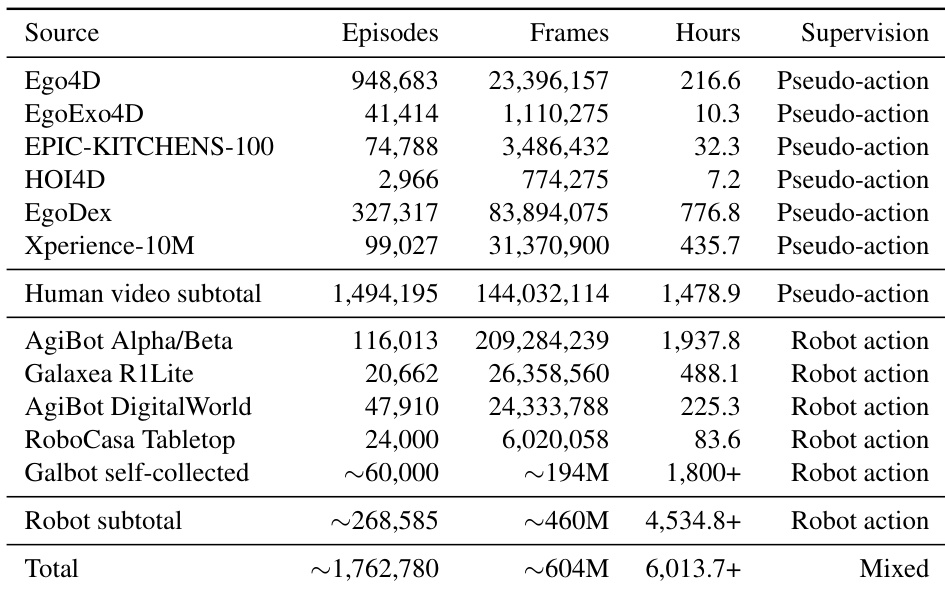
研究团队构建了一个融合人类第一人称视频与机器人操作数据的预训练数据集。人类数据通过伪动作进行监督,而机器人数据提供直接的动作监督。这种多源组合使模型能够从广泛的行为示例与控制信号中学习。数据集整合了人类第一人称视频与机器人演示,以覆盖广泛的操作任务范围。人类数据源依赖伪动作监督,机器人数据则基于直接动作日志。该数据集涵盖多种来源,包括家庭交互视频与专用机器人平台。
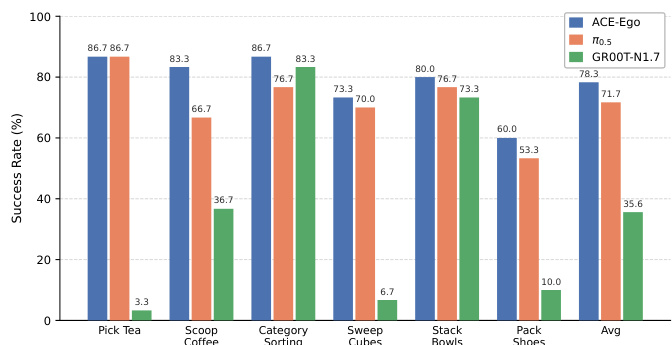
{ "summary": "该实验在实体机器人平台上评估了三种模型 ACE-Ego、π0.5 与 GR00T-N1.7 在六项操作任务中的成功率。ACE-Ego 始终取得最高成功率,在六项任务中的五项领先,并获得最高平均性能。相比之下,GR00T-N1.7 性能显著偏低,尤其在需要复杂协调或长周期序列的任务中表现较差。", "highlights": [ "ACE-Ego 取得最高平均成功率,优于 π0.5 与 GR00T-N1.7。", "ACE-Ego 在评估的六项独立任务中的五项表现领先。", "GR00T-N1.7 在抓取茶叶、清扫方块与打包鞋子等任务中表现出明显较低的成功率。" ] }
研究团队在包含 24 项涉及抓取放置与连杆物体操作的 RoboCasa GR1 TableTop 基准测试上评估了 ACE-EGO-0 模型。结果表明,ACE-EGO-0 在所有评估基线中取得了最高的平均成功率,在整个任务集上展现出优越性能。在 RoboCasa 基准测试中,ACE-EGO-0 的平均成功率超越所有基线模型,包括 GR00T-N1.6 与 JoyAI-RA。该模型在连杆物体交互与抓取放置重排两类任务中均保持稳定的性能提升。相机空间动作接口支持广泛泛化,使众多操作任务受益,而非局限于狭窄的子集。
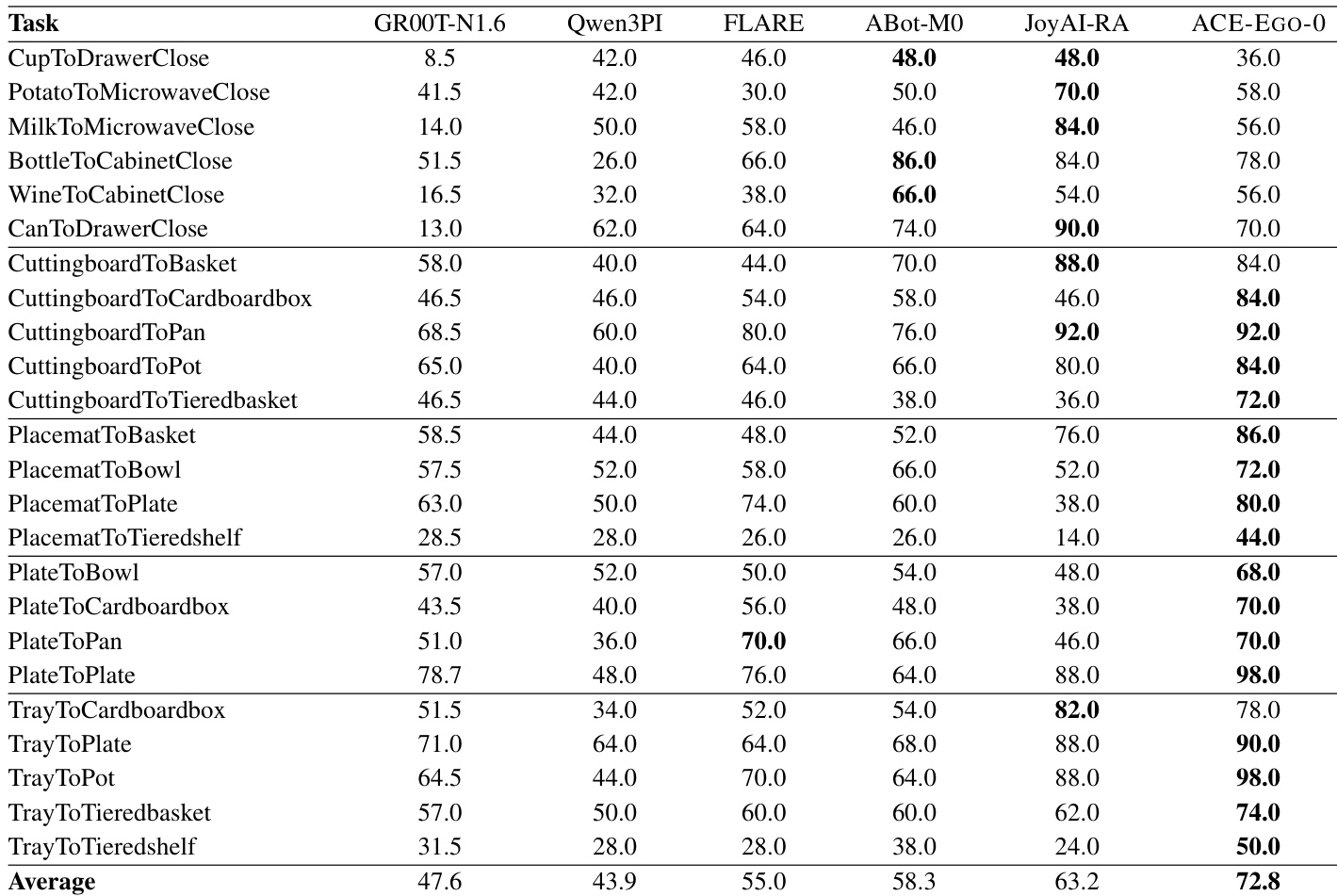
评估设置在该模型上测试了多项仿真与实体机器人基准测试,涵盖 RoboTwin 2.0、RoboCasa TableTop 以及一个六任务真实世界平台,并与多项成熟基线进行对比。这些实验共同验证了系统在多样化操作场景中跨域泛化的能力,范围涵盖双臂协调与工具使用,到连杆物体处理与长周期序列。定性分析表明,该模型在简单与困难难度级别下均始终展现出稳健性能,并对竞争方法保持明显优势。最终结果证实,结合人类与机器人的预训练策略及相机空间动作接口,能够实现可靠且广泛适用的机器人操作,且不会出现特定任务的性能退化。