Command Palette
Search for a command to run...
用于机器人策略学习的几何动作模型
用于机器人策略学习的几何动作模型
Jisang Han Seonghu Jeon Jaewoo Jung René Zurbrügg Honggyu An Tifanny Portela Marco Hutter Marc Pollefeys Seungryong Kim Sunghwan Hong
摘要
通用机器人策略需在遵循用户指令的同时,对物体、相机与机器人动作在三维物理世界中的交互方式进行推理。近期的视觉-语言-动作模型(VLA)与视频世界-动作模型(WAM)从大规模基础模型中继承了强大的语义或时序先验,但其运行仍主要局限于二维图像帧或二维派生的潜在空间,导致接触密集型操作所需的三维几何信息处于隐式状态。我们提出几何动作模型(GAM),这是一种语言条件驱动的操作策略,直接复用预训练的几何基础模型(GFM)作为感知、时序预测与动作解码的共享底层架构。GAM在中间层对GFM进行分割:浅层作为观测编码器,而在分割层处插入的因果未来预测器则基于语言指令、本体感觉与动作历史,预测未来的潜在 tokens。预测出的未来 tokens 随后被路由至剩余的 GFM 模块中进行特征传播与解码,从而使单一主干网络能够同时输出未来的几何信息与动作。该设计通过极小的架构修改,使 GFM 具备语言条件驱动的时序世界建模能力,同时完整保留其丰富的几何先验。在广泛的仿真与真实机器人操作基准测试中,GAM 相较于当前基础模型规模的基线方法,在准确性、鲁棒性、运行速度与模型轻量化方面均表现更优。
一句话总结
韩国科学技术院(KAIST)和苏黎世联邦理工学院(ETH Zurich)的研究者提出了几何动作模型(Geometric Action Model,GAM),这是一种语言条件的操控策略。该策略通过在一个中间层拆分预训练的几何基础模型,并插入一个因果未来预测器,以语言、本体感知和动作历史为条件预测潜在 token,从而重新利用该预训练模型,实现联合感知、时序预测和动作解码,同时保留三维几何先验,并在仿真和真实机器人基准上取得优越的精度、鲁棒性和效率。
核心贡献
- 提出几何动作模型(GAM)作为一种语言条件的操控策略,通过将预训练的几何基础模型拆分为观测编码器、因果未来预测器和解码器,使单一主干网络能够以最小的架构改动联合生成未来几何和动作。
- 动作和几何通过单次自回归前向传播在统一的 token 空间中进行预测,轻量级的回归头和深度头从同一主干网络解码动作 token 和未来场景 token。
- 在多种仿真和真实机器人操控基准上,GAM 相比现有基础模型规模的基线方法取得了更高的精度、更强的鲁棒性、更快的推理速度和更小的模型权重。
引言
机器人操控策略必须推理三维场景几何和时序动态,才能在非结构化环境中可靠地行动。此前的视频世界动作模型(WAM)在二维像素空间中预测未来隐变量和动作,缺失显式的几何结构;而几何感知的视觉-语言-动作模型(VLA)则依赖从外部几何基础模型被动蒸馏特征,形成脱节的多阶段流水线。作者引入了几何动作模型(GAM),这是一种共享主干的统一架构,将感知、几何预测和动作解码融为一体。GAM 在共享的隐空间中自回归地同时生成动作 token 和未来深度 token,消除了对外部几何模块的需求,并产生了一种比现有基础模型规模方案更精确、更鲁棒、更快且更轻量的策略。
数据集
作者在三个数据集的加权混合上预训练 GAM,结合真实机器人和仿真演示,以提供广泛的具身覆盖和清晰的几何监督。
-
数据集组成与采样比例
- Open-X Embodiment (OXE):72%
- MimicGen:18%
- RoboCasa365:10%
-
各子集的关键细节
- OXE
跨多种具身和操控领域的真实机器人演示。
仅保留动作可映射到通用控制接口的子集;与动作空间不兼容的数据集被排除。
深度监督使用教师伪深度。 - MimicGen
具有清晰几何监督的仿真演示。
深度监督使用重新渲染的仿真器深度。 - RoboCasa365
仿真演示;仅使用其中的操控任务子集。
深度监督使用重新渲染的仿真器深度。 - 所有来源均保留原始任务语言,不合成额外指令。语言编码器在预训练期间保持冻结。
- OXE
-
数据使用方式
- 三个数据集按上述采样比例混合用于预训练。
- 所有数据在训练前转换为统一的观测和动作格式。
- 模型在可用时使用两个 RGB 视图:外部视图和腕部视图,均缩放至 224×224。
-
处理与增强
- 训练时应用标准图像增强(随机裁剪、旋转、颜色抖动),评估时禁用。
- 除保留原始语言标注外,不构建额外元数据。
方法
作者提出了几何动作模型(GAM),这是一种语言条件的操控策略,直接重新利用预训练的几何基础模型(GFM)作为感知、时序预测和动作解码的共享基座。不同于依赖二维图像先验或将几何模型视为冻结特征提取器的先前方法,GAM 在中间层拆分 GFM。这一设计使模型能够在共享的几何主干内联合预测未来三维几何和动作块。
如下图所示,核心思想在于通过插入因果未来预测器来改造 GFM。浅层作为观测编码器,预测器则以语言、本体感知和动作历史为条件预测未来的隐式 token。这些预测的 token 随后通过剩余的深层 GFM 模块,以同时产生未来几何和动作。
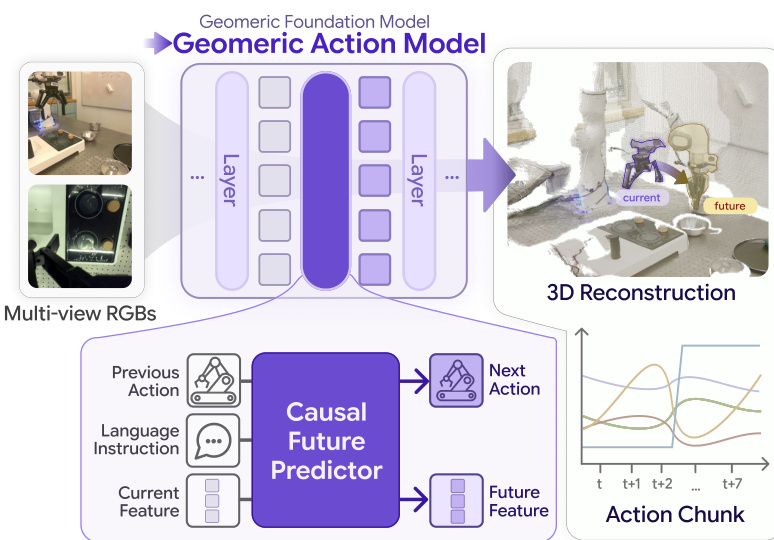
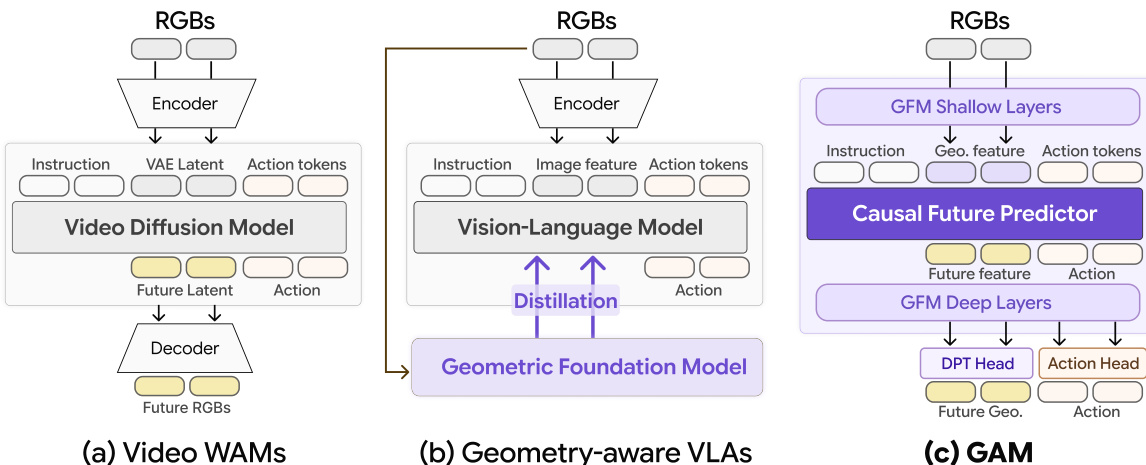
为了理解架构优势,将 GAM 与现有基线进行对比是有帮助的。视频世界-动作模型(WAM)预测未来帧,而几何感知的视觉-语言-动作模型(VLA)通常依赖蒸馏或分离头,GAM 则将预测直接集成到 GFM 隐空间中。
参考下方的框架图,其中突出了这些结构差异。在 GAM 架构(面板 c)中,GFM 浅层提取几何特征,这些特征与指令和动作 token 一起馈入因果未来预测器。输出随后由 GFM 深层处理,同时产生未来几何和动作,避免了单独的扩散过程或冻结主干。
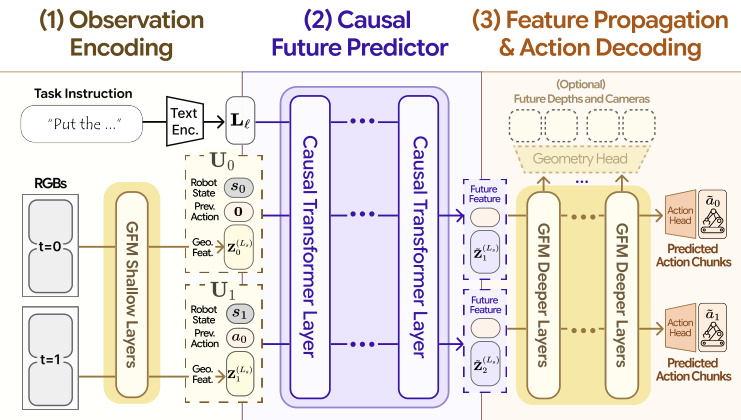
该框架在 GFM 内部按三个顺序阶段运行。
1. 观测编码器 作者重用预训练 GFM 的浅层,记为 E<Ls,其中 Ls 为拆分层。对于上下文窗口中的每个时间步 t′,使用原始 GFM 的 patch 嵌入将多视图 RGB 观测 token 化。这产生每个时间步的几何隐状态序列 {Zt−H+1(Ls),…,Zt(Ls)}。拆分层 Ls 的选择需足够深以提取丰富的视觉特征,但比用于几何解码的层更浅,确保预测的状态可被解码为三维结构。
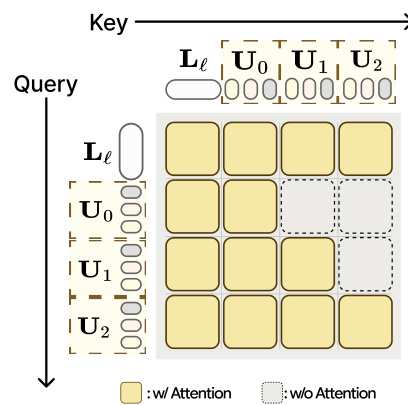
2. 因果未来预测器 在拆分层 Ls,作者插入一个因果未来预测器 gϕ。该模块将编码的几何特征与本体感知状态 st′、先前动作 at′−1 和语言指令 ℓ 结合。这些输入被嵌入并连接成一个序列 X。
为在不泄露未来信息的情况下处理该序列,模型采用块因果自注意力。如下方的注意力掩码图所示,注意力机制确保对特定时间步的预测仅关注过去和当前的上下文(黄色块),而忽略未来的 token(虚线块)。
在预测器的最后一层,模型预测未来帧的隐式几何 token Z~t′+1(Ls) 和预测的下一个动作 token a~t′。这种联合预测确保了动作与空间表示之间的紧密交互。
3. 特征传播与动作解码 预测的动作 token 为每个视图复制,并与几何 token 连接。它们被馈入剩余的深层 GFM 模块 D>Ls。因果掩码策略扩展到这些全局注意力层以防止信息泄露。最后,两个头解码输出:轻量级动作头聚合 token 以回归可执行的动作块 a^t′,原始 GFM 深度头将几何 token 解码为未来深度图。
这三个阶段的详细流程见下方的流水线图。
训练目标 策略通过最小化多任务目标进行端到端训练: Ltotal=λactLact+λfeatLfeat+λdepthLdepth 动作损失 Lact 是解码动作块与专家动作之间的 ℓ1 回归。未来特征损失 Lfeat 对齐预测的未来 token 与从冻结 GFM 提取的实际下一帧 token: Lfeat=∑t′∈HZ~t′+1(Ls)−Zt′+1(Ls)1 未来深度损失 Ldepth 使用尺度不变和梯度匹配惩罚监督解码深度与真实未来深度。推理时,作者通过键值缓存维护历史上下文,使每一步仅需处理新的观测和前一动作,通过单次前馈传播完成。
实验
评估涵盖仿真基准(LIBERO 和 LIBERO-Plus)、真实机器人任务以及一个额外的厨房基准,将 GAM 与视觉-语言-动作、世界-动作和几何感知基线进行比较。GAM 在参数显著更少且推理速度最高快 55 倍的情况下,达到或超越这些方法,尤其在相机视角扰动下鲁棒性突出。消融实验表明,预训练和几何基础模型层的深度集成对泛化至关重要,且未来深度和特征预测损失有助于编码几何动态。真实世界实验确认,GAM 在分布外相机偏移下保持高成功率,验证了其对三维几何先验的充分挖掘。
作者在原始 LIBERO 基准的四个不同任务套件上评估模型,涵盖空间、物体、目标和长时程操控。结果表明,模型在几乎所有单个任务上均取得极具竞争力的成功率,反映了在基线性能高度饱和的标准基准上的强劲表现。模型在所有四个评估套件的大多数任务中持续展现高成功率。性能在多样化的操控场景中表现鲁棒,仅有极少数任务成功率略低。整体套件级性能异常强大,为评估在扰动环境下的泛化能力奠定了坚实基础。
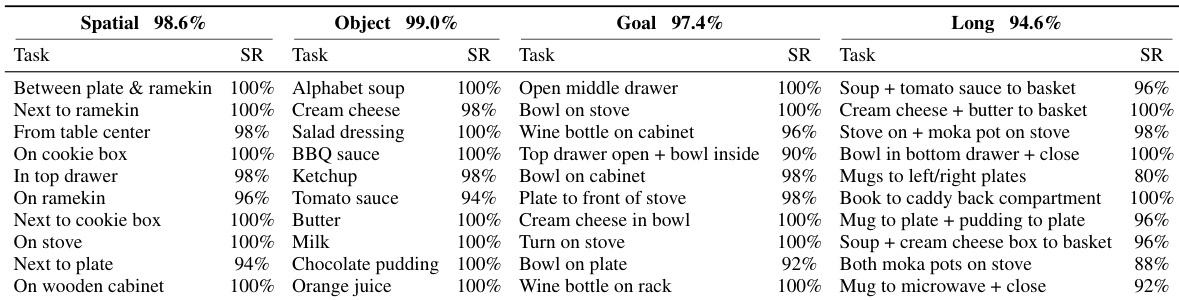
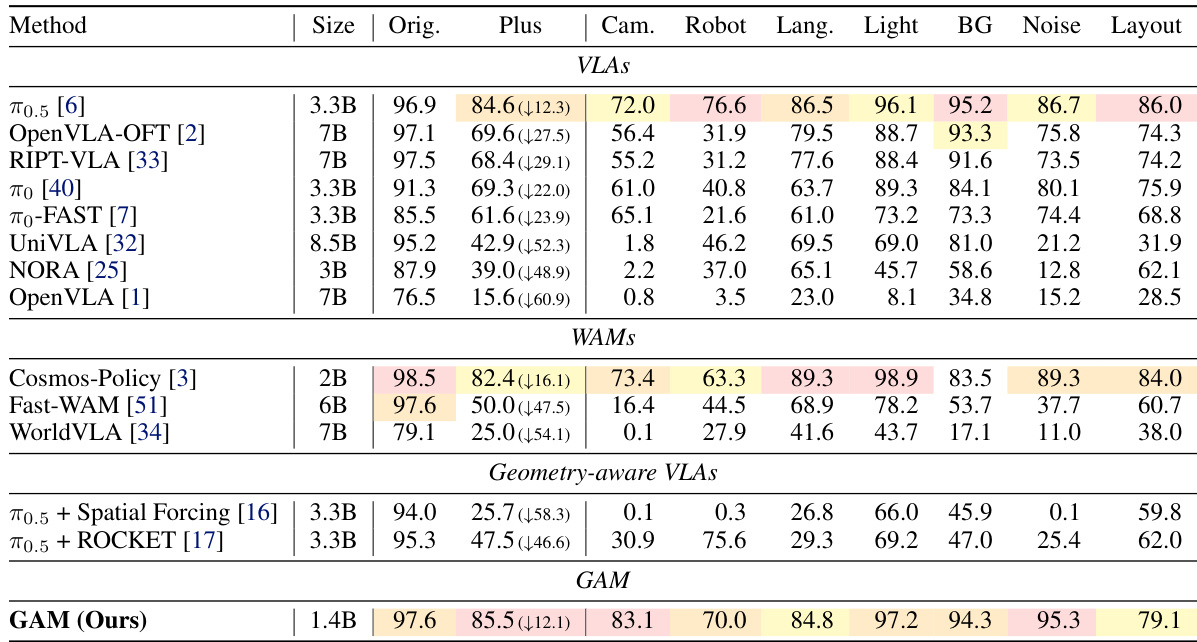
作者将提出的几何动作模型与各种视觉-语言-动作模型、世界-动作模型和几何感知基线在标准和扰动操控基准上进行比较。结果显示,所提模型在标准基准上取得极具竞争力的性能,同时在更具挑战性的扰动基准上持续优于对比方法,尤其在相机视角变化下。这证明了将几何世界动态直接集成到策略预测通路中的优势。所提模型在多个扰动类别(包括相机视角、光照和背景变化)中取得顶尖成功率,尽管模型规模小于大多数基线。该方法在相机扰动设置下展现出显著的鲁棒性,大幅超越现有几何感知视觉-语言-动作模型。模型在原始基准上保持强劲性能,同时在扰动任务上评估时性能下降极小。
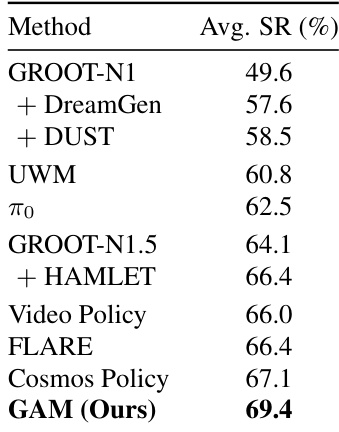
作者将提出的几何动作模型与若干基线操控策略(包括视觉-语言-动作模型和视频世界-动作模型)进行评估。结果表明,所提方法在所有对比方法中取得最高平均成功率,展现出优越的性能和鲁棒性。发现强调了重新利用几何基础模型进行端到端策略学习的有效性。所提模型超越所有竞争基线,在评估中取得最高平均成功率。该方法相比 Cosmos Policy 和 GROOT 变体等先前方法具有明显优势。将几何世界动态集成到策略中可带来持续更优的操控表现。
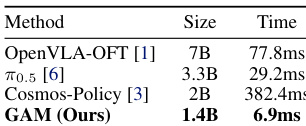
作者评估了所提方法与代表性基线的推理速度和模型大小。结果显示,所提模型实现了最低延迟和最小参数量,相比基于扩散和视觉-语言的基线能够显著更快地执行。所提方法在所有对比方法中模型尺寸最小。它实现了最快的推理时间,比基于扩散的基线快得多。紧凑的架构允许在不依赖大型语言或视频生成主干的情况下高效部署。
作者通过将完整模型与一个直接将动作监督应用于因果未来预测器的变体进行比较,评估了将动作 token 通过深层几何解码器的影响。结果表明,利用剩余的解码器层可提升性能,尤其是在扰动环境中,表明这些层细化了动作表示以获得更好的鲁棒性。完整模型在原始和扰动基准上均一致优于直接动作监督变体。完整模型在扰动设置下的性能优势更为显著,凸显了深层几何处理对鲁棒性的益处。与直接监督相比,将动作 token 通过剩余的解码器层使模型能更好地应对相机扰动。

实验在标准和扰动操控基准上评估模型,表明其在原始任务上取得极具竞争力的成功率,同时在相机、光照和背景扰动下大幅超越现有方法。将几何世界动态直接集成到策略中可产生鲁棒性能,从标准到扰动设置时性能下降极小,且紧凑的设计在对比方法中实现了最快的推理速度和最小的模型尺寸。消融研究进一步证实,通过深层几何解码器层处理动作 token 对于处理扰动至关重要,验证了几何处理对鲁棒操控的优势。