Command Palette
Search for a command to run...
多轮反思掩码在掩码扩散模型中激发推理
多轮反思掩码在掩码扩散模型中激发推理
Yanming Zhang Yihan Bian Jingyuan Qi Yuguang Yao Lifu Huang Tianyi Zhou
摘要
尽管在自回归(AR)模型上的推理通常通过思维链推理与反思机制实现,但即使仅需进行局部编辑,其对先前输出的优化仍依赖于完全顺序生成。相比之下,掩码扩散模型(MDMs)中的掩码机制天然支持对先前输出的显式局部编辑,使得模型能够在保留先前答案的基础上进行选择性优化,而无需将其丢弃并从头重新生成。尽管这一特性更贴近人类通过迭代局部优化来纠正错误的方式,但现有的掩码扩散模型(MDMs)尚不支持多轮掩码与去噪操作。为此,我们提出了反射掩码(Reflective Masking, RM),通过轻量级后训练在MDMs中激发此类内在推理能力。RM提供了一种原生的测试时扩展机制,使MDMs能够基于不断演化的上下文,迭代地回顾并修正其先前输出。为充分利用类似AR推理中先前轮次所获得的洞察,我们进一步引入了历史参考(History Reference)机制。该机制无需额外参数,可在修正过程中利用中间去噪状态。该方法无需对模型架构进行任何修改,即可轻松应用于现有的MDMs。在涵盖文本生成、数独求解及图像编辑等多样化任务与模态的实验中,反射掩码始终优于标准的基于掩码的基线方法,并展现出极强的泛化能力,从而确立了RM作为MDMs推理基础原语的地位。
一句话总结
作者提出了 Reflective Masking,这是一种轻量级的后训练方法,通过在 Mask Diffusion Models 中启用多轮 masking 以实现选择性局部细化,从而激发其迭代推理能力,该方法不依赖自回归顺序生成。当结合无参数的 History Reference 机制时,它能够在不修改现有架构的情况下,为各种现有架构提供原生的测试时扩展(test-time scaling),实现迭代式自我修正。
核心贡献
- 引入 Reflective Masking 作为一种轻量级后训练技术,将 token masking 构建为基于不确定性的决策过程,以在 Mask Diffusion Models 中实现迭代式自我修正。该方法无需修改模型架构即可对先前输出进行选择性细化,建立了一种区别于自回归顺序生成的原生测试时扩展机制。
- 结合专用数据生成策略的可扩展训练范式通过使优化信号与模型原生输出分布对齐来激活该能力。在图像编辑、数独推理和文本生成任务上的评估均显示出一致的性能提升,证实了该方法具有跨模态适用性。
- 提出 History Reference 作为一种无参数机制,用于保留中间去噪状态,从而维持解码轨迹的时间视图。该组件将历史预测显式纳入迭代更新中,提升了修正的一致性,并防止在多轮细化过程中重复犯错。
引言
大语言模型在推理任务中占据主导地位,但在多轮设置中经常传播错误,这种结构性缺陷迫使模型进行完整的序列重新生成并浪费计算资源。Mask diffusion models 提供了一种极具吸引力的替代方案,其支持局部的 token 更新,能够保持更清晰的中间上下文并实现高效的自我修正。然而,标准解码遵循被动过程,会锁定早期预测结果,导致模型无法主动回溯或修复先前犯下的错误。为释放这一潜在能力,作者提出了 Reflective Masking,这是一种后训练框架,将 token masking 视为用于选择性修正的基于不确定性的决策过程。作者将其与轻量级训练流水线以及 History Reference 相结合,后者是一种保留中间解码状态的无参数机制,用于指导迭代细化。这些创新共同将 mask diffusion 生成从线性前向扩展转变为自我修正的推理循环,从而在文本、结构和图像任务中持续提升性能。
方法
作者提出了 Reflective Masking (RM),该框架将 Mask Diffusion Models (MDMs) 转变为具备局部编辑能力的迭代推理引擎。标准 MDMs 通常遵循吸收马尔可夫过程,而 RM 引入了逐位置决策机制,允许模型在多次去噪步骤中选择性地细化输出,同时保留先前答案。
在每个时间步 t,模型评估当前状态 x~(t),并基于其输出概率分布 pθ(⋅∣x~(t))i 确定每个位置 i 的下一个状态 x~(t+1)。状态转移由一条确定性规则控制,该规则根据当前位置是否被 masking 进行分支:
x~i(t+1)=⎩⎨⎧Mx~i(t)argmaxv∈Vpθ(v∣x~(t))iif x~i(t)=M and pθ(M∣x~(t))i>pθ(x~i(t)∣x~(t))iif x~i(t)=M and pθ(M∣x~(t))i≤pθ(x~i(t)∣x~(t))iif x~i(t)=M如图所示:
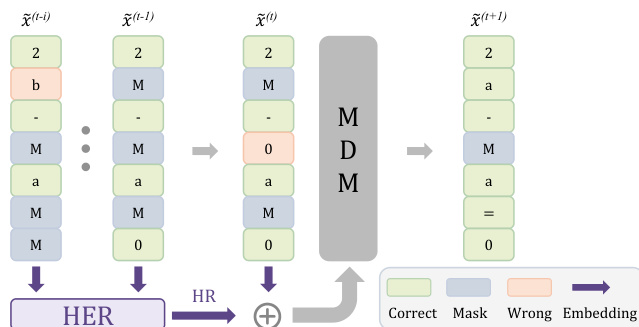
该图展示了迭代细化过程:错误的 token(橙色)被重新 masking(蓝色),随后被揭示为正确的 token(绿色)。为防止模型陷入重复生成相同状态的循环,作者引入了 History Reference (HER) 模块。这一无参数机制将中间去噪状态聚合为历史感知嵌入,为模型提供关于其修正轨迹的上下文信息,并稳定多轮细化过程。
为使模型适应此推理行为,作者设计了一种训练范式,使用逐位置的 oracle 标签对模型进行监督。训练数据通过模拟合成轨迹构建。从干净序列开始,特定位置会被污染,替换为从污染分布中采样的 mask tokens 或错误 tokens。
如下图所示:
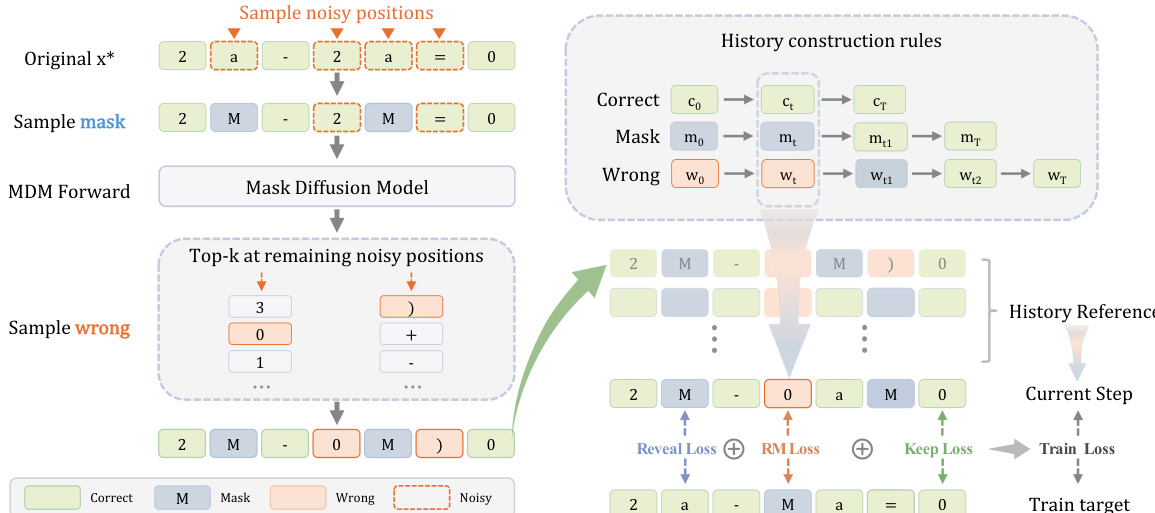
该图详细说明了历史构建规则与训练损失的分解方式。转移规则规定,错误 tokens 最终应过渡为 mask tokens,随后再过渡至正确目标,而被 masking 的 tokens 则直接过渡至目标。训练目标通过最小化与这些 oracle 动作的交叉熵损失来实现,该损失分解为三个部分:针对 masking 位置的 reveal loss、针对错误位置的 mask loss,以及针对正确 tokens 的 keep loss。此设置确保模型学会正确判断何时修正 token 以及何时保留 token,从而有效启用 reflective masking 能力。
实验
评估涵盖三个任务类别,其推理复杂度逐步提升,外部指导逐步减少:基于指令的图像编辑、结构化数独修正以及完全自主的文本推理与代码生成。这些实验验证了 Reflective Masking 如何在显式监督下实现精确的局部修正,同时 History Reference 如何在指导极少的情况下促进自主错误检测与迭代修正。定性来看,模型展现出有针对性的自我修正能力,在图像中保留未修改区域,并在多步推理过程中系统化地细化对逻辑至关重要的 tokens。总体而言,研究结果证实,将迭代修正与结构化历史记忆相结合,能够持续提升不同生成任务的准确性与逻辑一致性。
作者从编辑定位、背景保留和整体编辑质量三个关键维度,将所提出的图像编辑方法与 Lumina 及微调基线进行了对比评估。结果表明,该方法在准确定位特定区域的同时保持周围图像完整性方面,始终优于基线模型。与基线模型相比,该方法在识别编辑目标区域时实现了更高的精度与覆盖率。背景保留效果显著提升,该方法在未编辑区域保持了更高的相似性与更低的错误率。该方法带来了更好的整体编辑质量,在自动评分与用户偏好研究中均位列第一。

作者通过测试包含 Reflective Masking 与 History Reference 的方法变体,评估了数独修正能力。结果表明,引入 History Reference 显著提升了精确准确率与有效性,同时降低了错误率与冲突。集成所有组件(包括衰减机制与 HER)的完整模型在所有指标上均实现了最优性能。与基线相比,集成 History Reference 大幅提高了精确准确率与有效率,同时将重复犯错与冲突单元格降至最低。结合所有组件的完整方法取得了最佳整体表现,优于缺少特定机制的变体。仅在 History Reference 中添加衰减因子相比不使用衰减因子的 History Reference 收益有限,但与 HER 结合时则展现出优势。

作者在其涵盖数学、代码生成与多项选择题的文本推理任务上评估了该方法。结果表明,该方法在所有评估类别中均持续优于基线模型。值得注意的是,与数学推理相比,该方法在代码生成任务中取得了显著改进。该方法在数学、代码与多项选择题基准测试中,始终优于 LLaDA 与 Vanilla SFT 基线。性能提升在代码生成任务中尤为明显,模型从迭代修正能力中获益良多。该方法有效提升了多步推理与结构化输出生成能力,且未损害标准推理能力。

作者在不同数学学科的 Minerva MATH 基准上评估了该方法。结果表明,该方法在所有学科类别及总分上均持续优于 Vanilla SFT 基线。在代数、几何与数论等每个学科类别中,该方法均取得了高于基线的准确率。综合性能指标呈现出持续的正向提升。该方法有效增强了多样化数学推理任务的表现。

在图像编辑、数独修正、文本推理与数学解题等广泛基线对比下,实验验证了该方法的精确性、降错能力与迭代推理能力。在图像编辑中,该方法持续实现更优的区域定位与背景保留,同时提供更高的整体质量。针对数独与代码生成等结构化任务,引入基于历史的参考与修正机制显著提升了准确率并最小化冲突,且未降低标准推理性能。在数学基准测试中,该方法在各推理类别中均实现均匀的性能提升,展现出稳健的跨领域改进效果。