Command Palette
Search for a command to run...
VibeThinker-3B:探索小型语言模型中可验证推理的前沿
VibeThinker-3B:探索小型语言模型中可验证推理的前沿
Sen Xu Shixi Liu Wei Wang Jixin Min Yingwei Dai Zhibin Yin Yirong Chen Xin Zhou Junlin Zhang
摘要
本技术报告介绍了VibeThinker-3B,这是一款拥有30亿参数的紧凑稠密模型,旨在探究在严格的小模型范式内,可验证推理能力能够被推至何种程度。基于Spectrum-to-Signal后训练范式,我们通过一套优化的训练流水线系统性地增强该模型,该流水线涵盖基于课程学习的监督微调、多领域强化学习以及离线自蒸馏。实验评估表明,VibeThinker-3B在高度严苛的可验证任务上取得了前沿水平的性能表现。具体而言,该模型在AIME26上取得94.3分(通过断言级测试时扩展提升至97.1),在LiveCodeBench v6上Pass@1达到80.2,并在近期未见的LeetCode竞赛中展现出强大的分布外泛化能力,接受率达96.1%。这使其有效跻身一线推理系统的性能区间,其表现匹配甚至超越了参数量大数个数量级的旗舰模型,例如DeepSeek V3.2、GLM-5与Gemini 3 Pro。此外,该模型在IFEval上获得93.4分,证实了这种极致的推理能力增强并未牺牲严格的指令遵循可控性。延续我们此前在1.5B参数模型上的工作,这些发现提出了“参数压缩-覆盖假说”(Parametric Compression-Coverage Hypothesis)。该假说认为,可验证推理可被压缩至紧凑的推理核心中,而开放域知识与通用能力则需要在事实、概念及长尾场景上实现广泛的参数覆盖。这一视角表明,紧凑模型并非仅仅是部署高效的替代品,而是通往参数密集型能力范式前沿性能的一条互补路径。
一句话总结
VibeThinker-3B 是一款通过课程式监督微调、多领域强化学习与离线自蒸馏优化的 3B 参数模型,在 AIME26 上取得 94.3 分,在 LiveCodeBench v6 上 Pass@1 达到 80.2,在未见的 LeetCode 竞赛中接受率达 96.1%,实现了前沿水平的可验证推理。该结果证明,专业推理能力可高效压缩至紧凑架构中,从而与参数密集的旗舰模型相媲美。
核心贡献
- 本报告介绍了 VibeThinker-3B,这是一款拥有 30 亿参数的密集模型,通过融合课程式监督微调、多领域强化学习与离线自蒸馏的流水线进行优化,旨在严格限制模型规模的条件下推动可验证推理的发展。
- 评估结果表明,该模型在多项高难度基准测试中达到前沿性能,在 AIME26 上得分 94.3,在 LiveCodeBench v6 上 Pass@1 为 80.2,在分布外 LeetCode 竞赛中的接受率达 96.1%。其在 IFEval 上取得 93.4 分,进一步证实了这种推理增强在保持严格指令可控性方面的有效性。
- 分析提出了参数压缩-覆盖假说(Parametric Compression-Coverage Hypothesis),将可验证推理归类为一种参数密集型能力。该能力可压缩为可复用的核心模块,而非需要广泛覆盖的通用知识。该框架将紧凑模型开发定位为与传统参数缩放定律相补充的发展路径。
引言
作者利用强化学习推动语言模型的逻辑推理能力,该领域的前沿性能目前依赖于要求数百亿参数模型的缩放定律。小型语言模型因部署效率高而成为极具吸引力的替代方案,但在掌握复杂数学推导与长程推理方面仍面临持续挑战,常被视为大型系统的不足替代品。为突破这些局限,作者开发了 VibeThinker-3B,这是一款拥有 30 亿参数的模型,通过应用基于 Spectrum-to-Signal 范式的优化后训练流水线,实现了对顶级大语言模型的竞争性性能。该方法整合了课程式监督微调、多领域强化学习与离线自蒸馏,将可验证推理压缩至密集核心中,并最终提出参数压缩-覆盖假说,以证明紧凑模型为迈向高密度推理能力提供了一条独特且互补的路径。
数据集

- 数据集构成与来源:作者构建了一个面向监督微调(SFT)阶段的多领域监督数据集。数据涵盖数学、编程竞赛、STEM 推理、通用对话与指令遵循。种子查询取自现有高质量数据集,具体筛选带有明确最终答案或清晰解题思路的数学问题,以及具备可靠单元测试或可执行评估规则的编程任务。
- 各子集关键细节:数学与编程子集驱动自动化查询扩展流水线,种子样本在概念组合、解题骨架、约束条件与评估目标等多个维度进行重写。推理密集型子集(数学、代码、STEM)采用多路径蒸馏策略,保留完整的中间推理步骤,而非单一标准解法。所有扩展查询均通过强教师模型的独立采样生成伪标签,最终标签通过多数投票确定。
- 论文数据使用方法:作者利用该精筛数据集为后续的强化学习建立稳定的冷启动策略。数据未按固定混合比例应用,而是根据推理链长度与题目难度进行分层,以支持课程式 SFT 调度。该结构明确保留了多解谱系,使模型在策略内采样开始前接触多样化的分解方法与验证策略。
- 额外处理与元数据:训练前采用三层质量控制流水线过滤数据集。N-gram 分析用于移除重复片段、模板化退化模式及基准测试污染。具备能力的 LLM 随后评估查询质量,剔除描述不完整、逻辑缺陷或知识目标定义模糊的内容。最后,通过答案验证、代码沙箱执行与 LLM 多数投票验证轨迹正确性,丢弃无效推理路径。作者按难度与链长对最终过滤后的数据进行组织,以支持结构化课程学习。
方法
作者展示了针对 VibeThinker-3B 的分阶段后训练流水线,该流水线基于 Qwen2.5-Coder-3B 基础模型构建。框架旨在通过数据合成、多样性导向的监督微调、多领域强化学习、离线自蒸馏与指令对齐,系统性地激发并巩固推理能力。该方法延续了 Spectrum-to-Signal 原则,其中 SFT 构建多样化的解空间,强化学习则放大高价值推理信号。
如下方框架图所示:
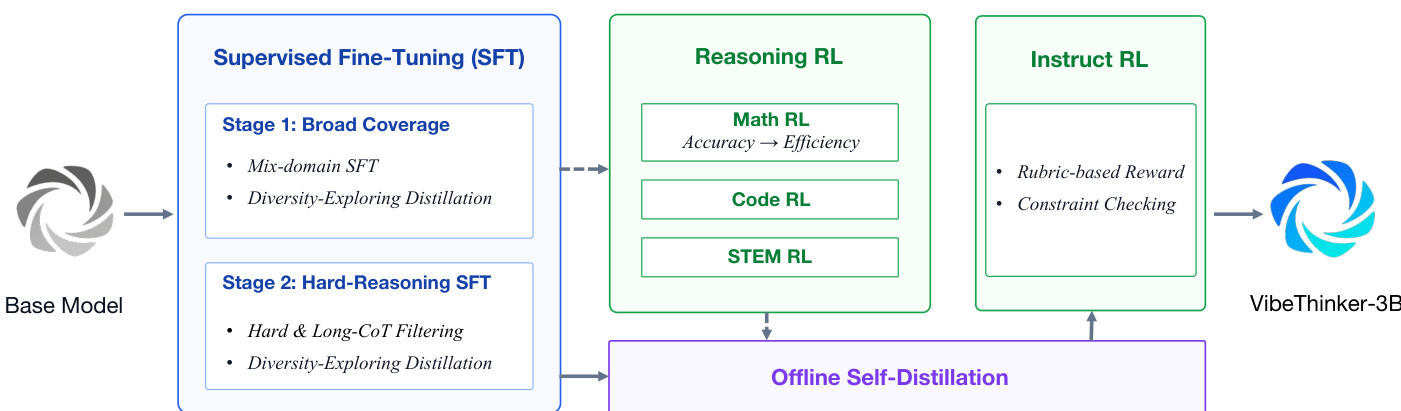
流水线从两阶段监督微调过程开始。第一阶段利用混合领域 SFT 与多样性探索蒸馏聚焦广泛覆盖。第二阶段通过高难度与长思维链过滤针对复杂推理,再次运用多样性探索蒸馏,推动模型从广泛的能力覆盖转向深度长程推理。
SFT 之后,模型使用最大熵引导策略优化(MGPO)算法进行多领域推理强化学习。MGPO 动态选择靠近模型能力边界的提示词。对于每个提示词 q,系统采样 G 个响应并计算经验组准确率。具有中间正确率的提示词会被赋予更高权重,以将更新聚焦于不确定区域。优化目标定义如下:
IMGPO(θ)=Eq,{yi}G1i=1∑G∣yi∣1t=1∑∣yi∣min(ρi,t(θ)w(q)Ai,clip(ρi,t(θ),1−ε,1+ε)w(q)Ai)作者将该方法应用于数学、代码与 STEM 领域。值得注意的是,数学强化学习阶段包含 Long2Short 阶段,通过根据响应长度重新分配奖励,在不牺牲准确性的前提下优化推理效率。
完成核心推理强化学习后,流水线进入离线自蒸馏阶段。作者从数学、代码与 STEM 的强化学习检查点中提取高质量推理轨迹。他们采用学习潜力过滤机制,估算每条轨迹对学生模型的蒸馏价值。该过程涉及计算长度归一化的负对数似然,以识别教师模型已验证但学生模型尚未充分建模的轨迹。
最终阶段为指令强化学习(Instruct RL),旨在使推理增强型模型与用户指令对齐。该阶段使用混合指令数据集,对开放式提示词应用基于量表的奖励,对带有明确约束的样本使用基于规则的验证器。这确保了模型严格遵循复杂的多步指令,同时保留已激发的推理能力。
实验
评估采用标准推理基准、声明级可靠性评估策略以及分布外编程竞赛,以验证紧凑模型能否在不依赖海量参数的情况下实现顶级逻辑性能。结果表明,该 3B 模型在可验证任务上成功跻身第一梯队推理区间,保持稳健的指令遵循对齐能力,并能有效泛化至新型算法问题。尽管在知识密集型基准上仍存在明显的性能差距,但实验整体证实推理熟练度与参数记忆仅部分耦合。最终,研究结论表明,优化的后训练流程与针对性的测试时验证可有效提升紧凑模型至竞争水平,证明高级推理并不严格受限于原始模型规模。
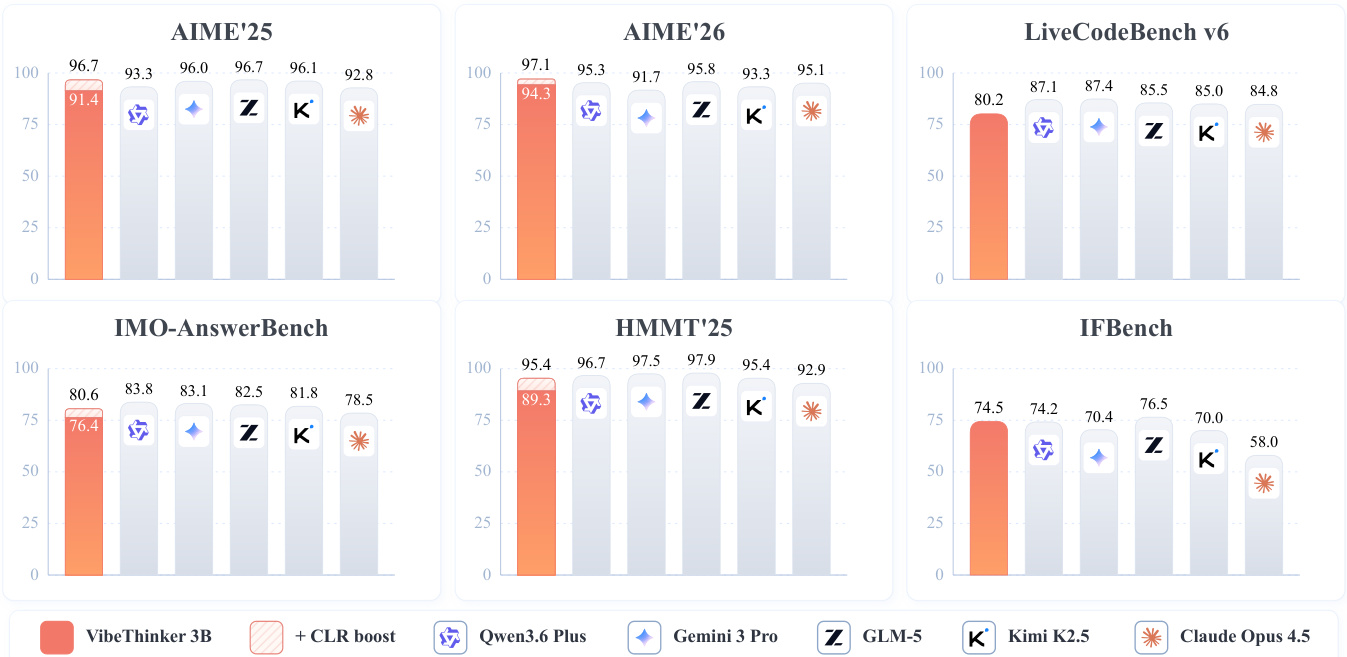
实验在 IMO-AnswerBench 基准上评估紧凑模型 VibeThinker-3B 与参数量大得多的系统之间的推理性能。尽管参数量仅为竞争对手的零头,该模型仍展现出更优的基础性能,并在引入测试时缩放策略后,取得与前沿模型相当的成绩。在 IMO-AnswerBench 基准上,VibeThinker-3B 显著优于 MiniMax M2.7 与 GPT-OSS-20B 等参数量大得多的模型。应用 CLR 测试时缩放策略将模型性能提升至前沿分数区间,达到与 GLM-5 及 Kimi K2.5 等顶级系统相当的水平。结果表明,在复杂数学任务上,紧凑模型能够媲美甚至超越拥有数百亿参数系统的推理能力。

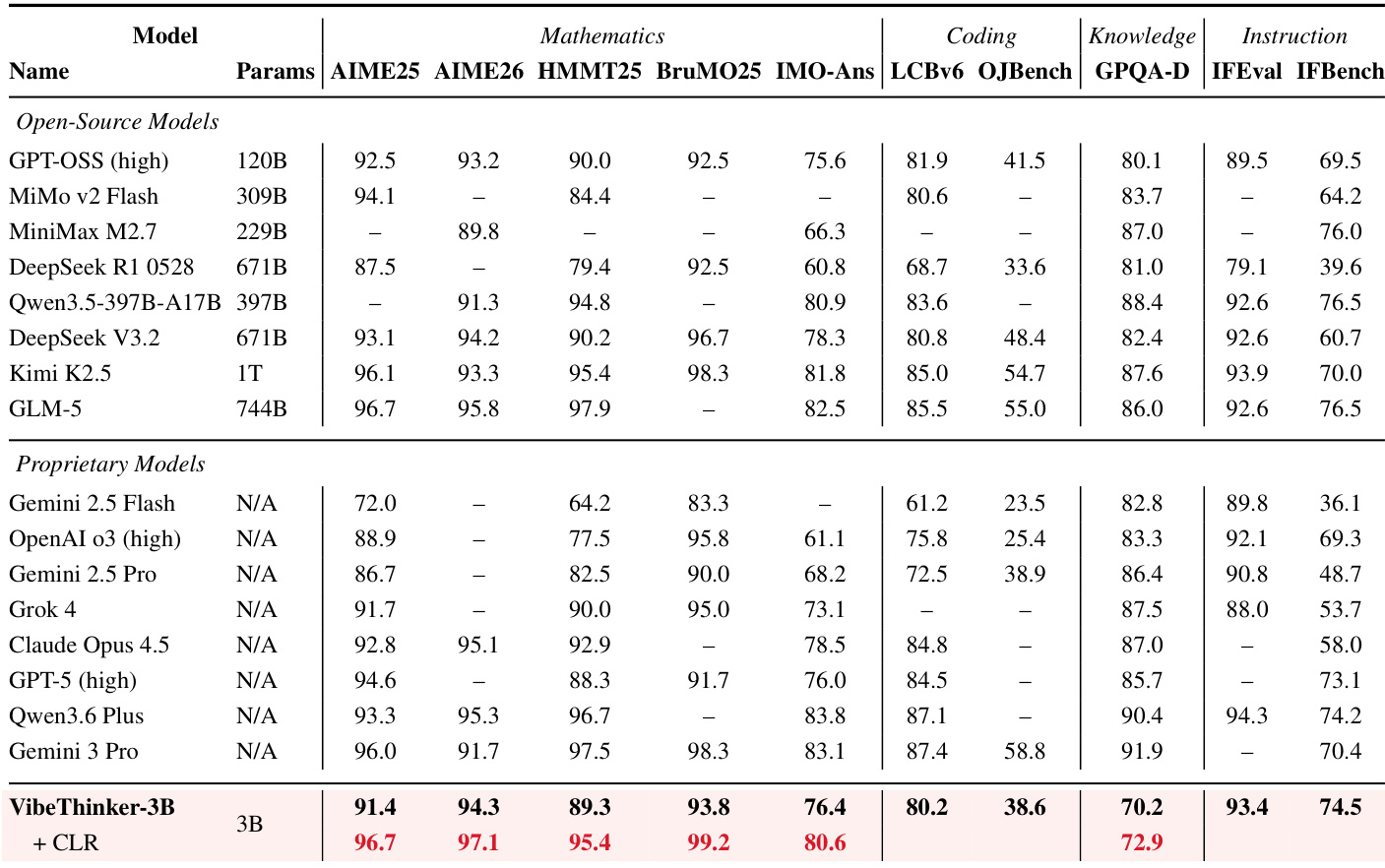
作者将参数量预算较小的紧凑模型 VibeThinker-3B 与一系列显著更大的开源及专有系统进行对比评估。结果表明,该小型模型在数学推理、代码生成与指令遵循任务上,取得了与参数量大得多的系统相当的性能。此外,引入名为声明级可靠性评估(Claim-Level Reliability Assessment, CLR)的测试时缩放策略,使模型能够缩小与顶级旗舰模型的差距,尤其在可验证推理基准上表现突出。在数学与代码基准上,VibeThinker-3B 展现出与参数量在数百亿至数十亿之间的模型相竞争的性能。声明级可靠性评估(CLR)的加入显著增强了模型的推理能力,使其在关键基准上能够匹配或超越领先的专有与开源系统。结果表明,紧凑模型无需依赖通常与此类能力关联的海量参数规模,即可在可验证任务上实现高级推理性能。
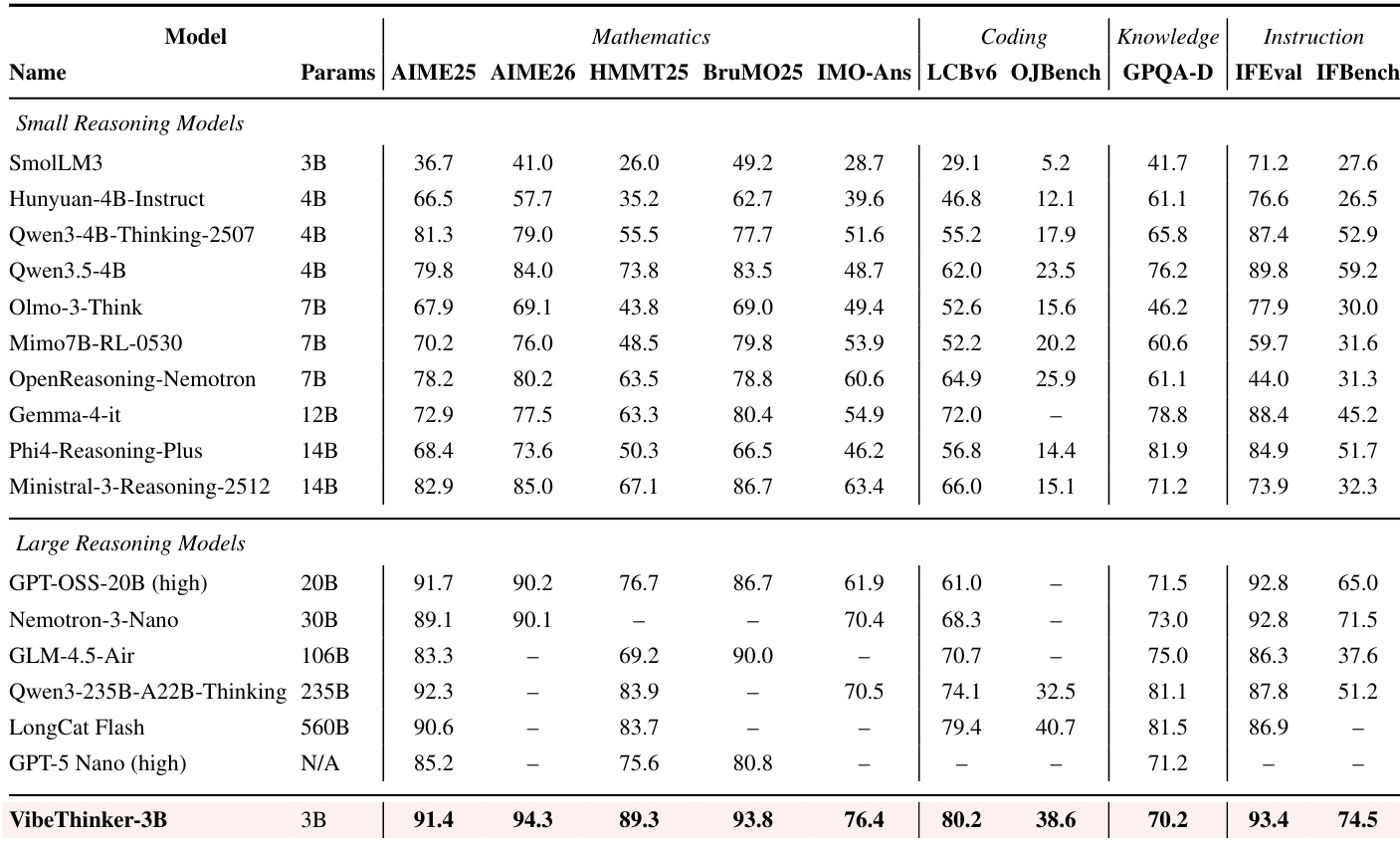
作者将 VibeThinker-3B 与一系列更小及显著更大的推理系统进行对比评估,以确定实现第一梯队性能所需的参数容量。结果表明,该紧凑模型在数学、代码与指令遵循基准上均取得优异性能,经常超越参数量大得多的模型。该模型在数学与代码基准上取得最高分,领先于参数量大得多的竞争对手。其展现出稳健的指令遵循能力,在指令基准中名列前茅,同时保持与用户约束的对齐。与广泛的知识基准相比,在重度推理任务上,紧凑模型与最大规模系统之间的性能差距并不显著。
作者利用近期的 LeetCode 周赛与双周赛评估 VibeThinker-3B 解决未见算法问题的能力。该模型取得较高的综合成功率,展现出稳健的分布外泛化能力。其性能与顶级系统具备竞争力,优于多款大型模型,且与表现最佳的模型高度接近。在近期的 LeetCode 竞赛中,VibeThinker-3B 取得较高的综合成功率,超越 GPT-5.2 与 Qwen3-Max 等模型。该模型在新型算法问题上展现出强大的泛化能力,性能紧密贴合 Gemini 3 Flash 等顶级系统。单样本 Python 生成评估进一步证实,模型无需针对测试分布进行特定微调,即可处理复杂的、经执行验证的代码任务。
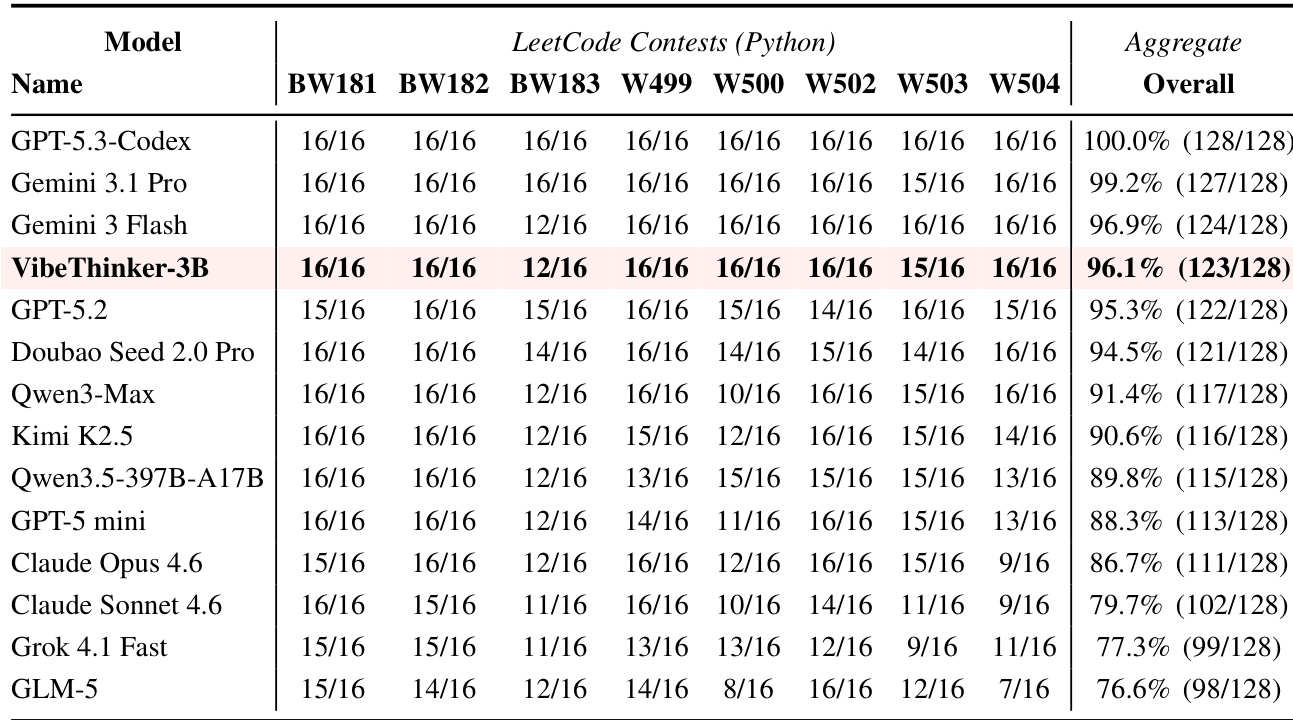
实验在数学推理、代码与指令遵循基准上,将紧凑模型 VibeThinker-3B 与参数量大得多的开源及专有系统进行对比,以评估其参数效率与推理能力。基础评估表明,该模型在结构化任务上已能匹配或超越参数量大得多的竞争对手,而在新型算法问题上的额外测试进一步证实其出色的分布外泛化能力。引入测试时缩放策略后,性能进一步提升至前沿水平,有效缩小了与顶级旗舰模型的差距。这些发现共同表明,紧凑架构无需依赖海量参数规模,即可在可验证任务上实现高级推理性能。