Command Palette
Search for a command to run...
OPEN-SWE-TRACES:推动软件工程智能体的双模式多语言蒸馏技术进展
OPEN-SWE-TRACES:推动软件工程智能体的双模式多语言蒸馏技术进展
Wasi Uddin Ahmad Nikolai Ludwig Somshubra Majumdar Boris Ginsburg
摘要
自主软件工程的发展路径目前受限于多样化、大规模轨迹数据的严重匮乏。为此,我们推出了 OPEN-SWE-TRACES,这是一个涵盖九种编程语言(Python、Go、TS、JS、Rust、Java、PHP、C、C++)的大型数据集,包含 207,489 条 Agent 轨迹。该数据集通过 OpenHands 和 SWE-agent 工具链源自 20,000 个真实世界的 Pull Requests,并采用混合推理合成方法:Minimax-M2.5 生成带有显式“思维”过程的轨迹,而 Qwen3.5-122B 则提供高质量的“无思维”轨迹。数据源自 SWE-rebench-V2,仅保留采用宽松许可协议(MIT、Apache、BSD)的数据,旨在支持具备长程推理能力的模型训练。我们通过微调 Qwen3-30B-A3B 系列模型(包括 Thinking、Coder 和 Instruct 版本)对该数据集进行了验证。表现最佳的模型在 SWE-bench Verified、SWE-bench Multilingual 和 SWE-bench Pro 上的解决率(resolve rates)分别达到了 61.7%、57.1% 和 36.8%。这些结果确立了 OPEN-SWE-TRACES 作为将人类级软件工程能力蒸馏至高效开源 Agent LLM 的首要资源的地位。
一句话总结
NVIDIA 研究人员推出了 OPEN-SWE-TRACES,一个包含 207,489 条软件工程轨迹的数据集,涵盖 Python、Go、TypeScript、JavaScript、Rust、Java、PHP、C 和 C++,通过混合推理合成生成,其中 Minimax-M2.5 产生显式思考轨迹,Qwen3.5-122B 提供非思考轨迹,在该数据上微调 Qwen3-30B-A3B 模型在 SWE-bench Verified 上取得 61.7%、在 SWE-bench Multilingual 上 57.1%、在 SWE-bench Pro 上 36.8% 的解决率,推动了将自主软件工程蒸馏为高效开源 agent 的进程。
核心贡献
- OPEN-SWE-TRACES 是一个包含 207,489 条 agent 轨迹的数据集,跨九种编程语言,基于 20,000 个真实世界的 pull request 合成,使用 Minimax‑M2.5 生成思考轨迹,Qwen3.5‑122B 生成非思考轨迹,并基于宽松许可证(MIT、Apache、BSD)进行过滤。
- 在 OPEN-SWE-TRACES 上微调 Qwen3‑Coder‑30B‑A3B 得到 OPEN-SWE-AGENT 模型,在 SWE‑bench Verified 上取得 61.7%、在 SWE‑bench Multilingual 上 57.1%、在 SWE‑bench Pro 上 36.8% 的解决率。
- 一项实证研究通过评估基座模型选择、数据过滤(仅已解决 vs. 所有轨迹)以及多语言 vs. 仅 Python 蒸馏,分离出 agent 性能的驱动因素;进一步分析了思考与非思考模式之间的权衡,并展示了对未知执行框架的泛化能力。
引言
LLM 驱动的 agent 能力不断扩展,正在重塑软件工程,使得系统能够自主解决整个代码仓库中的真实缺陷,这一趋势已通过多语言基准得以衡量。一个主要瓶颈是大规模交互轨迹和预构建可执行环境的稀缺,而这些正是有效训练此类 agent 所需的,这导致了日益多样化的评估套件与实际模型开发之间的鸿沟。作者通过发布 OPEN-SWE-TRACES 来弥合这一鸿沟,该语料库包含 207,489 条合成 agent 轨迹,跨九种语言,独特地设计用于双模式蒸馏,包含单独的“思考”和“非思考”轨迹。他们通过微调一个开源 agent 来验证该数据集,该 agent 在 SWE-bench Verified(61.7%)、Multilingual(57.1%)和 Pro(36.8%)上达到了最优解决率。
数据集
作者构建了 OPEN-SWE-TRACES,这是一个包含 207,489 条 agent 轨迹的集合,来源于 20,000 个跨九种编程语言(Python、Go、TypeScript、JavaScript、Rust、Java、PHP、C、C++)的真实 pull request。数据来自 SWE-rebench-V2 中携带宽松许可证(MIT、Apache-2.0、BSD)的仓库,旨在将软件工程能力蒸馏到开源模型中。
数据集构成与关键细节
- 轨迹由两个 agent 框架生成:OpenHands(占语料库的 50.8%)和 SWE-agent。
- 使用混合推理合成:MiniMax-M2.5 产生带有显式思维链的“思考”轨迹,Qwen3.5-122B 提供“非思考”轨迹。
- 51.7% 的轨迹包含来自 MiniMax-M2.5 的内部推理内容。
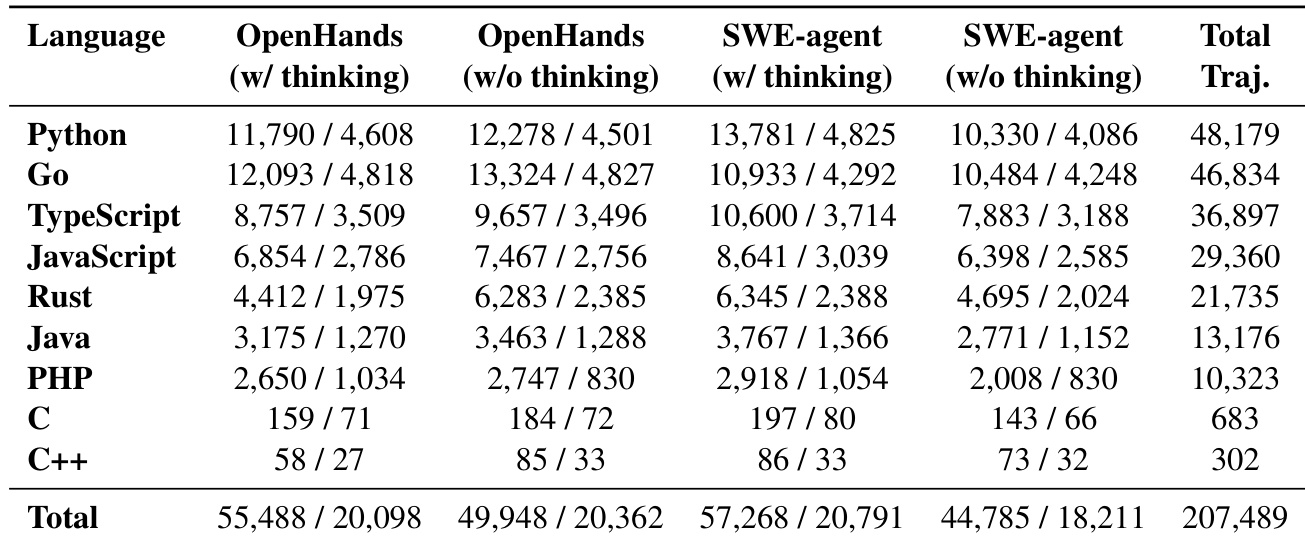
- 语言分布大致均衡;占比最高的语言是 Python(23.2%)、Go(22.6%)、TypeScript(17.8%)和 JavaScript(14.2%)。
- 约 40.6% 的生成补丁(65,244 条轨迹)经单元测试验证解决了底层问题。
过滤与处理流水线
- 阶段 1 – 执行聚合与运行时验证:将来自两个框架的异构交互日志统一为一致格式,并丢弃已损坏或未完成的轨迹(如环境异常)。
- 阶段 2 – 行为剪枝与模式标准化:作者移除达到最大迭代次数限制的轨迹、产生空补丁的轨迹、修改测试套件而非修复缺陷的轨迹,或出现畸形工具交互(非法并发调用、重复工具错误)的轨迹。随后将幸存的高保真日志标准化为 role、content 和 tool_calls 字段,同时保留 MiniMax-M2.5 轨迹中的 reasoning_content。
- 事后 Git 黑客检测:TrajectoryScanner 使用 AST 解析识别并剪除使用了被禁命令(如 reflog、blame)或不安全使用受限命令(log、diff)的轨迹,从而消除泄露仓库元数据的捷径。
数据在论文中的使用方式 完整语料库作为训练集,用于微调 Qwen3-30B-A3B 系列的三种变体:Thinking、Coder 和 Instruct。作者利用思考与非思考轨迹的混合,没有显式划分训练/验证集,使用统一模式来教授长时程的思维链推理和直接的代码编辑行为。
方法
作者利用了一套综合流水线来构建 Open-SWE-Traces 数据集,集成了多样化的来源、LLM 驱动的合成、严格的过滤以及信任与安全检查,以生成高质量的软件工程任务语料库。
如下图所示:
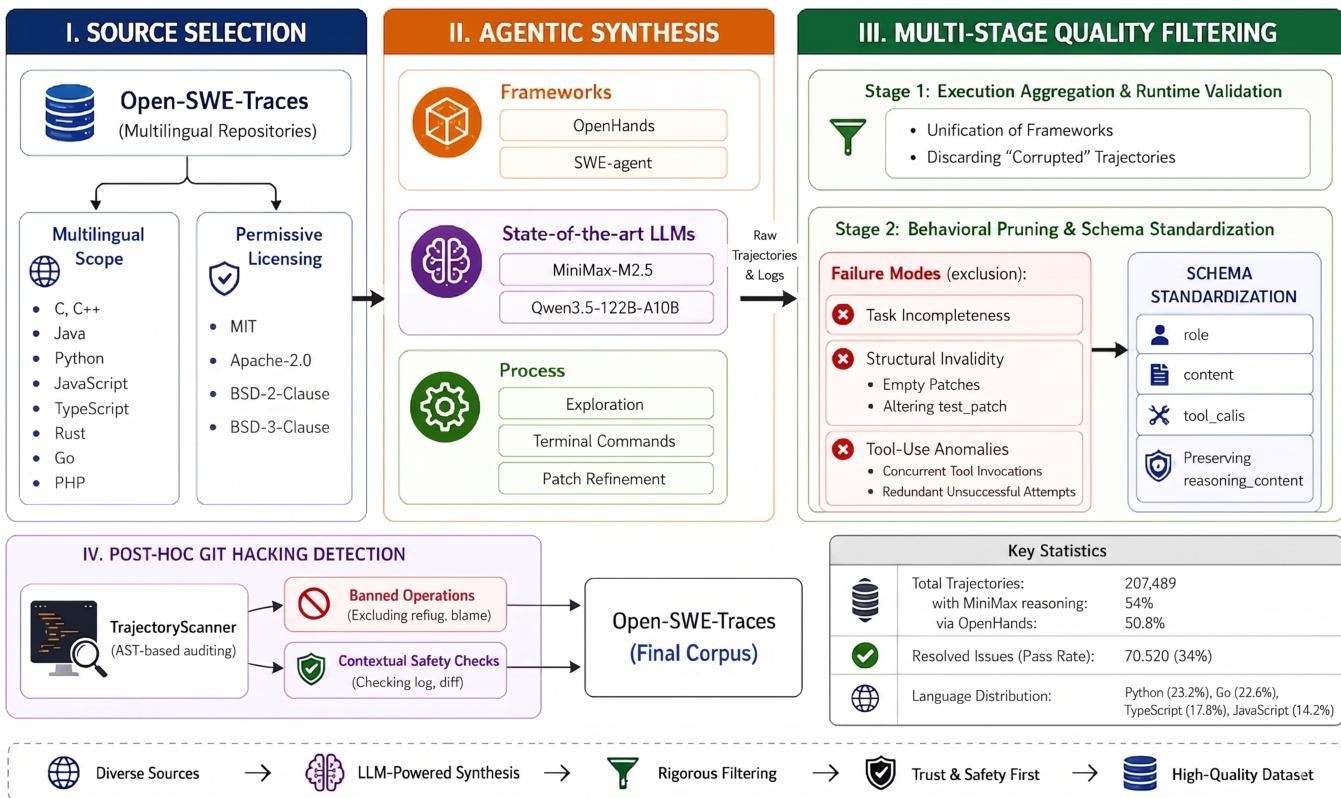
框架从源码选择开始,从多语言仓库中提取。作者基于多语言范围对这些仓库进行筛选,涵盖 C、C++、Java、Python、JavaScript、TypeScript、Rust、Go 和 PHP 等语言,并要求宽松许可证,包括 MIT、Apache-2.0、BSD-2-Clause 和 BSD-3-Clause。
在 agent 合成阶段,作者使用最先进的 LLM,具体为 MiniMax-M2.5 和 Qwen3.5-122B-A10B,集成在 OpenHands 和 SWE-agent 等框架内。合成过程包括探索、终端命令执行和补丁精修,以生成原始轨迹和日志。
随后,多阶段质量过滤机制对数据进行精炼。阶段 1 执行执行聚合与运行时验证,统一框架并丢弃已损坏的轨迹。阶段 2 应用行为剪枝与模式标准化。该阶段排除特定失败模式,包括任务未完成、结构无效(如空补丁或修改测试补丁)以及工具使用异常(如并发工具调用或冗余的失败尝试)。存活数据被标准化为定义角色、内容和工具调用的模式,同时保留推理内容。
最后,流水线通过 TrajectoryScanner 进行事后 Git 黑客检测,执行基于 AST 的审计。该模块对被禁操作进行强制,并通过检查日志和 diff 来执行上下文安全检查。生成的 Open-SWE-Traces 最终语料库包含 207,489 条总轨迹,其中 54% 使用了 MiniMax 推理,50.8% 通过 OpenHands 生成,达到了 34% 的已解决问题通过率。
实验
评估采用 MOpenHands 和 MSWE-agent 脚手架,在单语言和多语言 SWE-bench 基准上测试蒸馏后的 OPEN-SWE-AGENT 模型,证实从异构教师 agent 集合中蒸馏轨迹相比基座模型带来了显著提升。消融实验表明,融入多语言数据并包含未解决的轨迹是性能提升的关键驱动因素,而切换 agent 框架因对交互模式的过拟合导致一致性下降,思考模式在训练不充分时表现欠佳。整体性能最终受限于继承的教师偏差和执行环境的随机性。
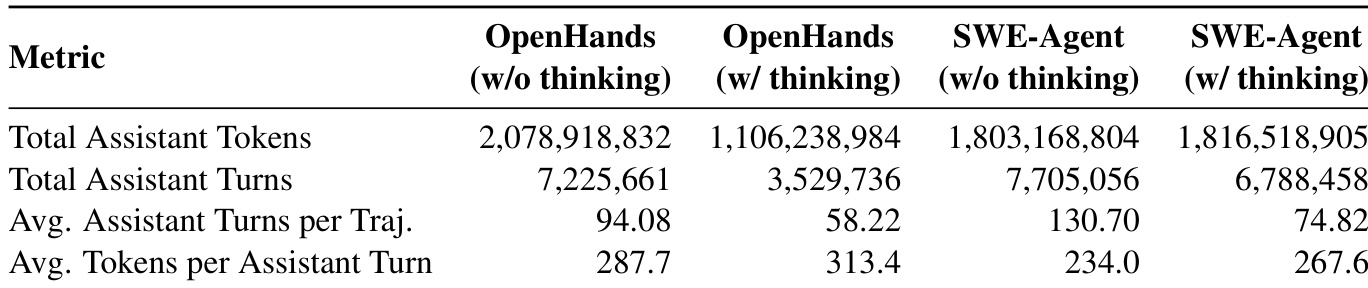
该表展示了 OpenHands 和 SWE-Agent 框架的操作指标,比较了有思考和没思考模式下的使用统计数据。启用思考模式持续降低了每个轨迹的平均 assistant 轮次以及两个环境中的总轮次。虽然思考模式在 token 数量上导致单轮交互更长,但通常能通过较少的步骤完成任务,简化交互过程。启用思考模式显著降低了 OpenHands 和 SWE-Agent 中每个轨迹的平均 assistant 轮次。在禁用思考模式时,SWE-Agent 框架展示出比 OpenHands 更高的平均每轨迹轮次。启用思考模式增加了每轮 assistant 的平均 token 数,表明每步响应更全面。
作者通过在 OpenHands 和 SWE-agent 框架上部署多种 LLM,构建了一个大规模多语言轨迹数据集,以捕获多样的推理策略。该数据集严重偏向 Python、Go 和 TypeScript 等高级语言,这些语言构成了所收集轨迹的大部分。相比之下,C 和 C++ 等低级系统语言代表性很低,反映了底层基准中任务的分布。数据集主要包含 Python、Go 和 TypeScript 的轨迹,数量远超其他语言。轨迹在 OpenHands 和 SWE-agent 框架中以思考和非思考模式生成,以确保多样的 agent 行为。C 和 C++ 等语言在数据集中代表性极低,可能是由于源基准中可用任务较少。
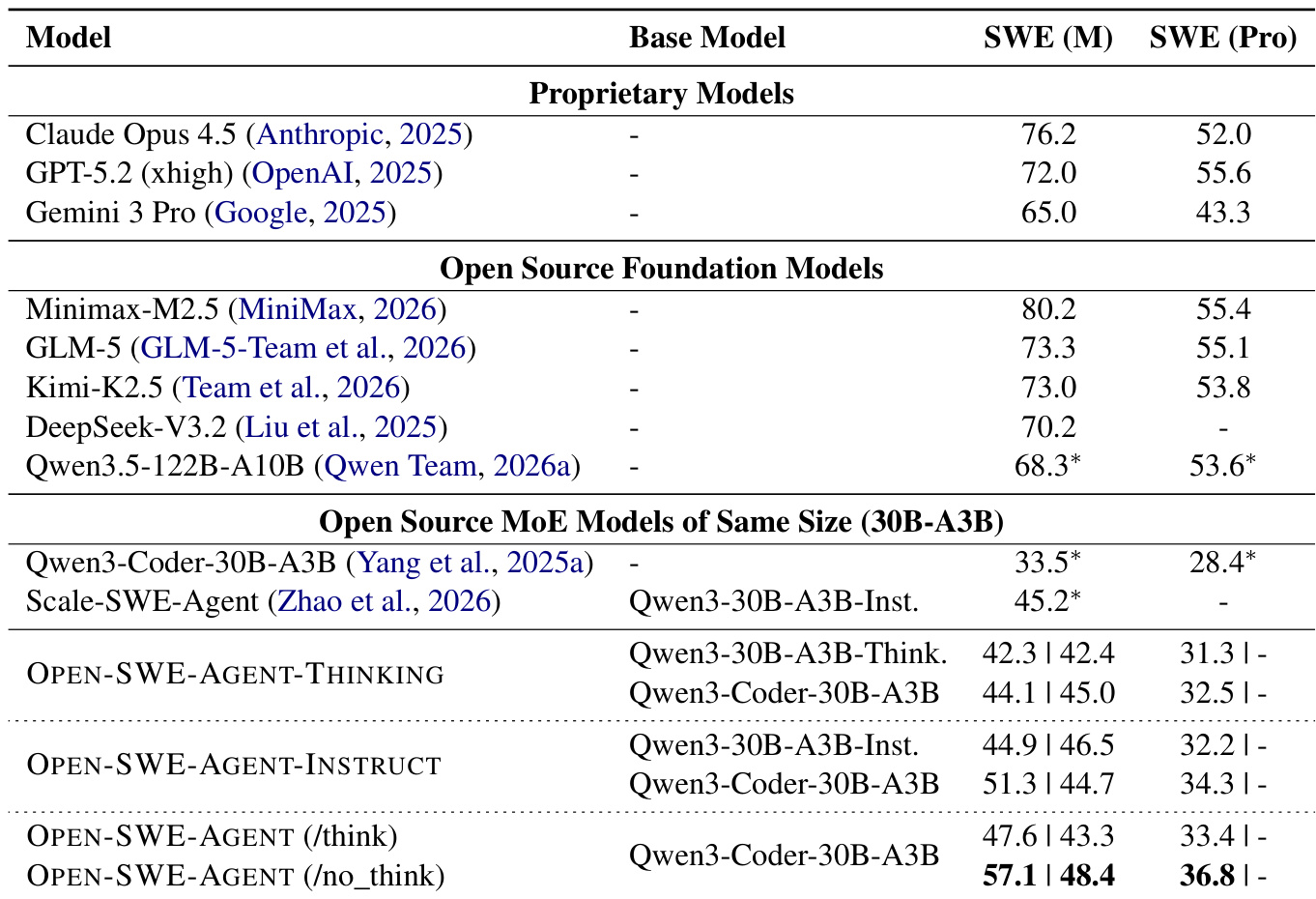
作者在多语言和专业软件工程基准上评估了蒸馏后的 OPEN-SWE-AGENT 模型,将其与专有模型、开源基础模型以及相同规模的开源 MoE 模型进行了比较。结果表明,蒸馏后的 agent 相比其基座模型取得了显著的性能提升,其中 no-think 变体在多语言和专业任务上均展现出特别强的改进。蒸馏后的 OPEN-SWE-AGENT 模型在多语言和专业编码基准上显著优于其基座模型及其他同规模的开源 MoE 基线。主 agent 的 no-think 配置在开源 MoE 模型中取得了最高性能,在两个评估基准上均超过了思考变体。尽管专有模型在绝对性能上仍处于领先地位,但所提出的开源 agent 通过有效的轨迹蒸馏,大幅缩小了差距。
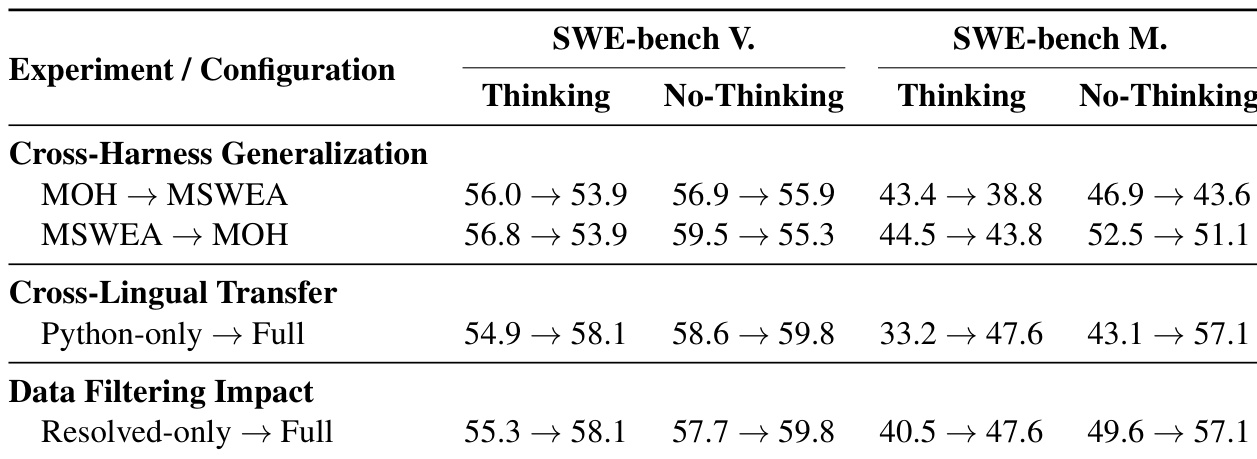
作者评估了训练配置如何影响不同环境和模态下的 agent 能力。结果表明,切换 agent 框架会导致一致性的性能损失,不过在一个框架上训练的模型在转移到另一个框架时,泛化能力随方向不同而异。此外,将训练数据从仅 Python 扩展到完整的多语言语料库,并包含未解决的轨迹,在单语言和多语言基准上均带来了显著性能提升。在 MSWEA 框架上训练的模型,在转移到 MOH 框架时,与反向转移相比表现出更优的稳定性和更小的性能下降。从仅 Python 训练集切换到完整的多语言数据集带来了实质性增益,尤其在非思考模式的非 Python 任务中。在训练语料库中包含未解决的轨迹始终优于仅使用已解决样本,有助于模型在所有基准上应对复杂状态。
作者将蒸馏后的 OPEN-SWE-AGENT 模型与各种专有、基础以及专用开源模型在软件工程基准上进行了比较。结果显示,虽然专有和顶级基础模型在性能上领先,但所提出的蒸馏 agent 在相似规模的开源模型中取得了有竞争力的结果。蒸馏过程与基座模型相比带来了显著提升,no-think 配置通常优于 think 变体。专有模型和领先的开源基础模型取得了最高的解决率,超过大多数专用开源模型。蒸馏后的 OPEN-SWE-AGENT 变体显示出比其基座模型大幅的性能提升,证明了该训练方法的有效性。在同等规模的开源模型中,所提出的 agent 与顶级专用模型表现相当,尤其在 no-think 配置下。

作者通过在 OpenHands 和 SWE-Agent 框架上以思考和非思考模式运行多种 LLM,构建了一个大规模多语言轨迹数据集,数据严重偏向 Python、Go 和 TypeScript 等高级语言。启用思考模式减少了每个轨迹的 assistant 轮次,但增加了每轮的 token 数量,从而简化了整体交互。蒸馏后的 OPEN-SWE-AGENT 模型显著优于其基座模型和其他开源 MoE 基线,no-think 配置在开源 agent 中取得了最佳结果,并大幅缩小了与专有模型的差距。融入多语言数据和未解决的轨迹对提升鲁棒性至关重要,而在 MSWEA 框架上训练的模型在切换环境时表现出更稳定的迁移能力。