Command Palette
Search for a command to run...
JoyAI-VL-Interaction:实时视觉-语言交互智能
JoyAI-VL-Interaction:实时视觉-语言交互智能
摘要
现实世界中的许多时刻并不会等待用户发起提问。监控画面中突然起火,视频通话中闪过一丝表情,或是直播中观众心仪的商品一闪而过。然而,当今的大模型在设计上大多仍基于轮次交互:它们仅在被呼叫时才会作答,即便是看似具有交互性的视频通话应用,实际上仍作为问答系统运行,仅在受到轮询或提示时才作出反应。我们主张一种不同的范式:一种像人一样存在于世界中的模型。它能够持续观察当前正在发生的事件,自主决定是否发言或保持沉默,实现实时交互,并在遇到难题时委派给后台模型处理。为推动交互模型的发展及其在各领域的广泛应用,我们做出了两项完全开源的贡献。首先,我们发布了 JoyAI-VL-Interaction,这是一个 8B 规模、以视觉为先的 VL 交互模型。该模型在内部自主做出响应决策,每秒决定保持沉默、进行回复或委派给后台模型,并在视觉触发响应和时间感知方面表现出色。我们为其配套了一套可迁移的训练方案,从中涌现出我们未曾专门训练的能力,例如引导购物者应对不断变化的应用界面,或根据幻灯片即兴进行演讲。其次,我们发布了一个围绕该模型构建的完整、可部署的系统。该系统将任何正在进行的视频流输入模型,使其真正“在场”于现实世界中。所有其他组件均为可插拔设计,包括 ASR/TTS 模块、记忆模块、可视化 UI,以及可连接任意 API 或 agent 的后台大脑。在六个真实世界场景中,人类评估者以显著优势更倾向于 JoyAI-VL-Interaction,而非 Doubao 和 Gemini 应用内置的视频通话助手。据我们所知,这是首个连同其训练方案、数据及完整可部署系统一同开源的、以视觉驱动的交互模型。
一句话总结
作者提出了 JoyAI-VL-Interaction,这是一款 80 亿参数规模的视觉语言交互模型。该模型持续监控视觉环境并自主决定响应时机,用主动式实时范式取代了传统的轮流交互架构。它将复杂任务委派给后台模型,从而实现一种与具身智能相契合的“观察与执行”协作模式。
核心贡献
- 本文介绍了 JoyAI-VL-Interaction,这是一款 80 亿参数规模的视觉优先模型。它采用主动式事件驱动范式取代轮流查询,每秒自主判断是否进行响应。该架构在单一系统中统一了实时响应能力、连续时间记忆与自主语音生成功能。
- 发布了完全开源的部署栈,将模型与时间对齐的数据及模块化框架相结合。该框架专为持续的实时在线状态、服务部署、记忆管理与后台任务委派而设计。
- 在流媒体场景中的评估表明,相较于传统的轮询系统,这种视觉驱动的方法在安全监控、自动解说和分步引导等实时应用中展现出显著的实用优势。
引言
作者采用连续交互范式,旨在解决 AI 系统亟需主动运行而非被动等待明确用户提示的关键问题。当前的大模型与消费级应用仍停留在结构化的轮流交互模式,依赖对话回合切换或外部轮询周期,无法对突发的、对时间敏感的事件做出反应。现有的流媒体视频研究同样将延迟或记忆等单一能力孤立开来,未能提供适用于持续现实世界部署的连贯框架。为弥补这一空白,作者推出了 JoyAI-VL-Interaction,这是一款 80 亿参数的视觉优先模型,能够自主学习每秒自主判断响应、保持静默或将复杂任务委派给后台处理器。该架构与完全开源的模块化系统相结合,支持亚秒级延迟流媒体传输与异步推理,从而提供真正的事件驱动辅助能力,契合具身智能的实际需求。
方法
作者展示了 JoyAI-VL-Interaction,这是一款专为实时流媒体视频设计的视觉语言模型。与传统轮流交互模型不同,该系统在连续循环中运行,每秒评估一次视觉流以确定下一步操作。该模型具备三种独立行为:提供及时预警、维持持续解说,或将复杂任务委派给后台模型。

如图所示的交互流程中,该模型可处理多种场景,例如在直播中检测火灾、将手机应用界面重建为 HTML 代码,或对艺术视频进行解说。当模型决定委派任务时,会将任务移交至异步后台大脑,使主循环能够继续处理直播流,同时后台任务得以解决。该设计确立了“观察与执行”的前提,即模型观察物理世界,并将相应动作委派至数字世界。
核心架构基于 JoyAI-VL 1.0 构建,其中语言模型由 Qwen3-8B 初始化,视觉编码器由 Qwen3-VL ViT 初始化。为管理无界视频流带来的计算负载,该模型采用了一种名为 AdaCodec 的原生流媒体视频编解码器。该编解码器采用预测编码策略,仅传输预测无法解释的内容,从而最小化 token 的使用量。

如图所示,编码过程区分参考帧与可预测帧。在第一轮中,完整的 RGB 帧由 ViT 处理以生成 256 个视觉 token。在后续轮次中,系统使用 P-Tokenizer 处理残差与运动向量,仅生成 16 个视觉 token。该方法使可预测帧的 token 数量减少约 16 倍,确保计算预算随场景变化而非帧数进行扩展。
系统架构旨在将自主决策核心与可插拔的输入输出组件解耦。
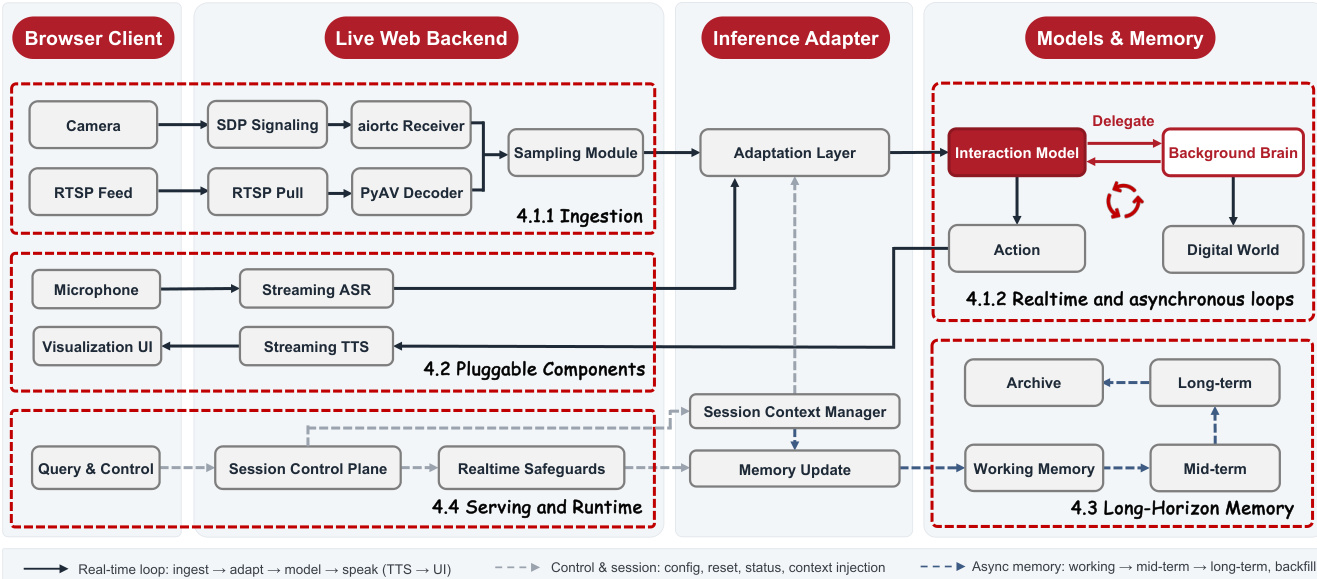
系统概览详细说明了浏览器客户端、直播 Web 后端、推理适配器以及模型与记忆模块。系统运行两个并发循环:与用户交互的实时循环,以及与后台大脑交互的异步循环。数据摄入模块以固定间隔(通常为 1 Hz)对视频流进行采样,并将其传递给交互模型。该系统还引入了分层长周期记忆机制,以在数小时的流媒体传输中维持上下文,该记忆按短期、中期和长期三个层级进行组织。
训练过程始于使用混合语料库进行的继续训练,该语料库包含时间对齐的交互数据与传统轮流交互数据。为解决静默步数远超响应步数的类别不平衡问题,作者采用了加权交叉熵损失函数。目标函数为静默 token 和响应 token 分配不同的权重:
L(θ)=−∣A∣1i∈A∑wjlogpθ(yj∣y<j).具体而言,重复的静默 token 会被降低权重,而响应起始 token 则会被提高权重。在监督微调之后,模型使用 GRPO 算法进行强化学习。该阶段针对流级奖励优化每秒策略,鼓励正确的时机把握、适当的静默以及高效的委派。
实验
该评估在六个事件驱动场景下,将紧凑型的 JoyAI-VL-Interaction 模型与来自 Doubao 和 Gemini 的成熟轮流交互视频通话助手进行了对比,以验证其实时运行、主动响应与长周期记忆能力。人工评估结果显示,该交互模型始终优于基线模型,尤其在对时间敏感且需及时且具备上下文感知能力的任务中表现突出。较大的基线系统经常表现出反应延迟、触发不稳定或会话过早中断等问题,而所提出的架构原生内化了时机决策,并能无缝将复杂子任务委派给后台进程。这些定性结果证实,将交互性视为核心架构能力,可使较小规模的模型在直播环境中超越体量大得多的轮流交互产品,涌现行为进一步验证了该方法的可行性。
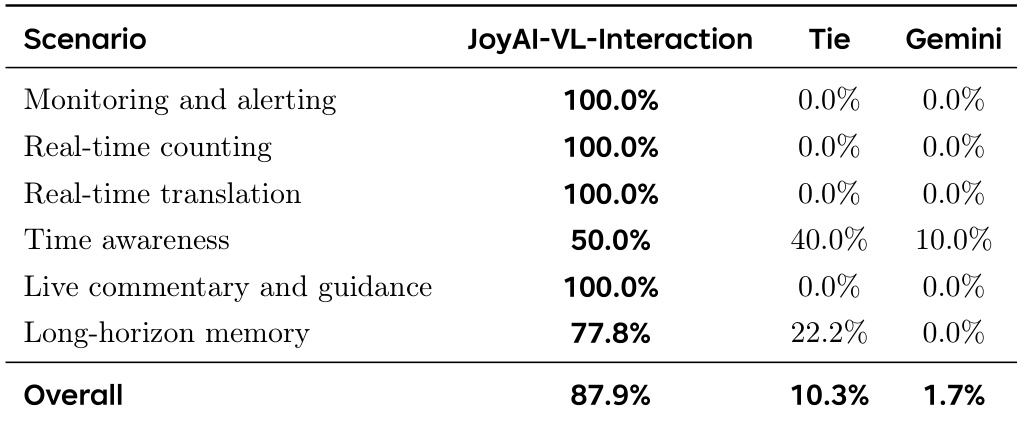
作者在六个事件驱动场景下对 JoyAI-VL-Interaction 与 Gemini 助手进行了评估。JoyAI-VL-Interaction 展现出决定性优势,赢得了绝大多数对比。该模型在需要即时、主动响应的任务中表现优异,在多个类别中取得全胜记录,而 Gemini 仅在特定的时间类任务中难以取胜。在需要即时反应的场景(包括监控、实时计数、翻译与现场解说)中,JoyAI-VL-Interaction 对 Gemini 保持全胜。时间感知场景竞争最为激烈,JoyAI 赢得半数案例,Gemini 仅占少数。在长周期记忆任务中,JoyAI-VL-Interaction 保持显著领先,赢得绝大多数对比,而 Gemini 无一胜绩。
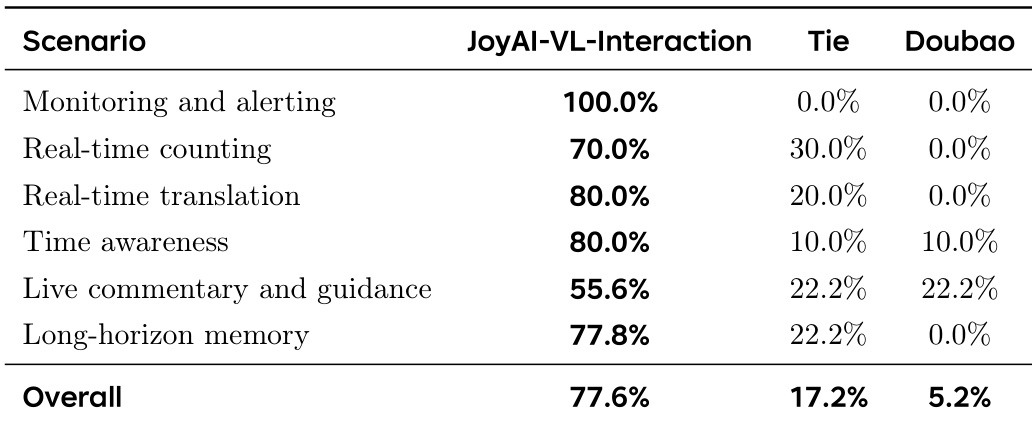
评估结果显示,JoyAI-VL-Interaction 在大多数事件驱动场景中显著优于 Doubao 基线。所提出的模型在监控、翻译和记忆等实时任务中展现出卓越能力,而基线模型仅在现场解说中表现出有限的竞争力。JoyAI-VL-Interaction 在监控与告警场景中取得主导性表现。在实时翻译与计数任务中,该模型对基线保持显著领先。尽管基线模型在现场解说中有一定表现,但 JoyAI-VL-Interaction 仍确立了整体的显著优势。
该评估在多个事件驱动场景下将 JoyAI-VL-Interaction 与主流商业助手进行对比,以评估其实时响应与上下文记忆能力。定性分析表明,该模型始终优于同类系统,尤其在要求即时反应、持续监控与长周期信息保留的任务中表现突出。尽管基线系统在特定时间敏感类别中仅表现出有限的竞争力,但 JoyAI-VL-Interaction 在主动交互与持续上下文感知方面展现出决定性优势。这些结果证实了该模型与动态交互需求的高度契合。