Command Palette
Search for a command to run...
OmniVideo-100K:一种基于结构化脚本与证据链的音视频推理数据集
OmniVideo-100K:一种基于结构化脚本与证据链的音视频推理数据集
Xinyue Cai Chaoyou Fu Yi-Fan Zhang Ran He Caifeng Shan
摘要
当前的音频-视觉问答(Audio-Visual QA)自动化数据处理管线通常采用“视频字幕-问答”范式。然而,这些方法通常将视频分割为短片段,并分别生成音频和视觉模态的描述。这种解耦处理割裂了声音与其视觉来源之间的固有联系,而独立的片段处理往往导致对同一实体在不同片段中的描述不一致。此外,将长文本理解与问答生成耦合在单一步骤中,往往限制模型仅关注局部事件,从而生成的问题缺乏长时间跨度的关联以及深度的跨模态推理能力。为解决上述问题,我们提出了一种具备两项机制的自动化数据引擎:(1) 实体锚定视频脚本生成(Entity-Anchored Video Scripting):将视频转化为结构化脚本,包含摘要、主要实体列表以及分段式的音频-视觉描述。实体列表作为全局先验信息,确保了跨片段的指代一致性,并重建了音频-视觉关联。(2) 线索引导的问答生成(Clue-Guided QA Generation):提示模型首先从脚本中挖掘跨片段、多模态的线索,随后基于这些高价值线索生成 QA 对。利用该流水线,我们构建了指令微调数据集 OmniVideo-100K 以及经人工验证的测试集 OmniVideo-Test。
一句话总结
为应对当前pipeline中解耦和短片段处理的局限,作者提出一个自动化数据引擎,通过将视频转换为实体锚定的结构化脚本以实现跨片段一致性和跨模态关联重建,并通过线索引导的问答生成挖掘长时多模态线索,构建了视听推理指令调优数据集OmniVideo-100K。
核心贡献
- 实体锚定视频脚本将视频转换为包含摘要、主实体列表和分段视听描述的结构化脚本。实体列表作为全局先验,强制跨片段的指代一致性并恢复声音与其视觉来源的关联。
- 线索引导的问答生成先提示模型从结构化脚本中挖掘跨片段、多模态的线索,然后基于这些高价值线索生成具有长期时间关联和深层跨模态推理的问答对。
- 该pipeline用于构建包含10万样本的指令调优数据集OmniVideo-100K,以及经人工验证的评测基准OmniVideo-Test,用于在多模态大语言模型上微调以实现连贯的视听问答。
引言
在视听问答中,模型必须联合推理视频中的视觉和听觉流以回答复杂的问询,这对稳健的多模态理解至关重要。先前的自动化pipeline依赖“视频-字幕-问答”方法,该方法将视频分段并分别处理音频和视觉模态,切断了声音与其视觉来源之间的自然耦合。这种解耦导致实体描述在不同片段间不一致,并将问题限制在短时局部事件上,缺乏长时推理或深层跨模态推理。作者通过一个自动化数据引擎解决这些挑战:该引擎首先构建实体锚定的视频脚本,使用全局实体列表保持指代一致性并恢复视听关联,然后采用线索引导的问答生成,在创建富含推理的问答对之前挖掘跨片段、多模态证据。该pipeline生成了OmniVideo-100K训练集和一个经过验证的测试集,在该数据上微调多模态大语言模型可显著提升视听理解与泛化能力。
数据集
作者构建了OmniVideo数据集,这是一个用于指令调优和评估的大规模视听问答资源。其组成、处理和使用方式总结如下。
-
数据集组成与来源
- 视频采集自在线平台,初始关键词池涵盖七个类别(vlog、新闻、动画、体育、纪录片、电视、自我视角),并通过迭代扩展新的视频标签。
- 所有视频经过筛选,仅保留英文内容且最低分辨率为480p。此外,视觉动态和词汇密度过滤确保丰富的视听信息,包含硬编码字幕的视频通过自动字幕检测被丢弃。
- 整理后的源视频池包含5214个视频,时长主要在1至3分钟,涵盖多样化的现实领域。
-
关键子集
- OmniVideo-100K(训练集): 包含10万个自动生成的问答对,均匀覆盖10种视听任务。问题以开放式和多项选择题混合形式存在,比例为7:3。开放式答案明显更长,因其在最终结论之外还包含详细的推理说明;四个多选题选项长度均衡,以避免长度偏差。
- OmniVideo-Test(评估集): 包含505个多选题问答对,来自264个视频。所有样本首先由同一条pipeline生成,然后经过严格的人工审核。审核人员强制要求事实准确性、跨模态依赖性(丢弃仅凭单一模态即可回答的问题)以及答案唯一性。仅约38%的初始生成内容通过此筛选,形成了高质量的测试集。
-
数据在模型中的使用方式
- 完整的OmniVideo-100K用作Qwen2.5-Omni的指令调优语料库。在此微调阶段不混合任何额外数据集。
- 训练超参数与基线方法(AVQA和JavisInst-Und)保持一致,以实现公平对比。微调后的模型在OmniVideo-Test和外部基准上进行评估。
-
裁剪、元数据与处理细节
- 数据集由一条自动化pipeline构建,使用了Gemini-2.5-Pro和Gemini-3-Pro。对于基本的对齐和上下文理解任务,大多数查询针对短片段中的局部事件;作者直接提示模型挖掘线索并一次生成问答对,而非采用为更复杂任务设计的多步策略。
- 该pipeline采用线索引导策略,将每个问答对锚定到显式的跨模态证据链。作为副产品,它生成了结构化的视听脚本,可作为可复用的中间表示,不仅用于问答生成(例如视频编辑)。
- 训练或评估输入中未对视频进行裁剪;模型接收完整视频及相关问题。
方法
作者提出一种自动化的视听问答生成pipeline,旨在增强多模态大语言模型的跨模态理解能力。如下方框架图所示,该方法由两个主要模块组成:实体锚定视频脚本与线索引导的问答生成。
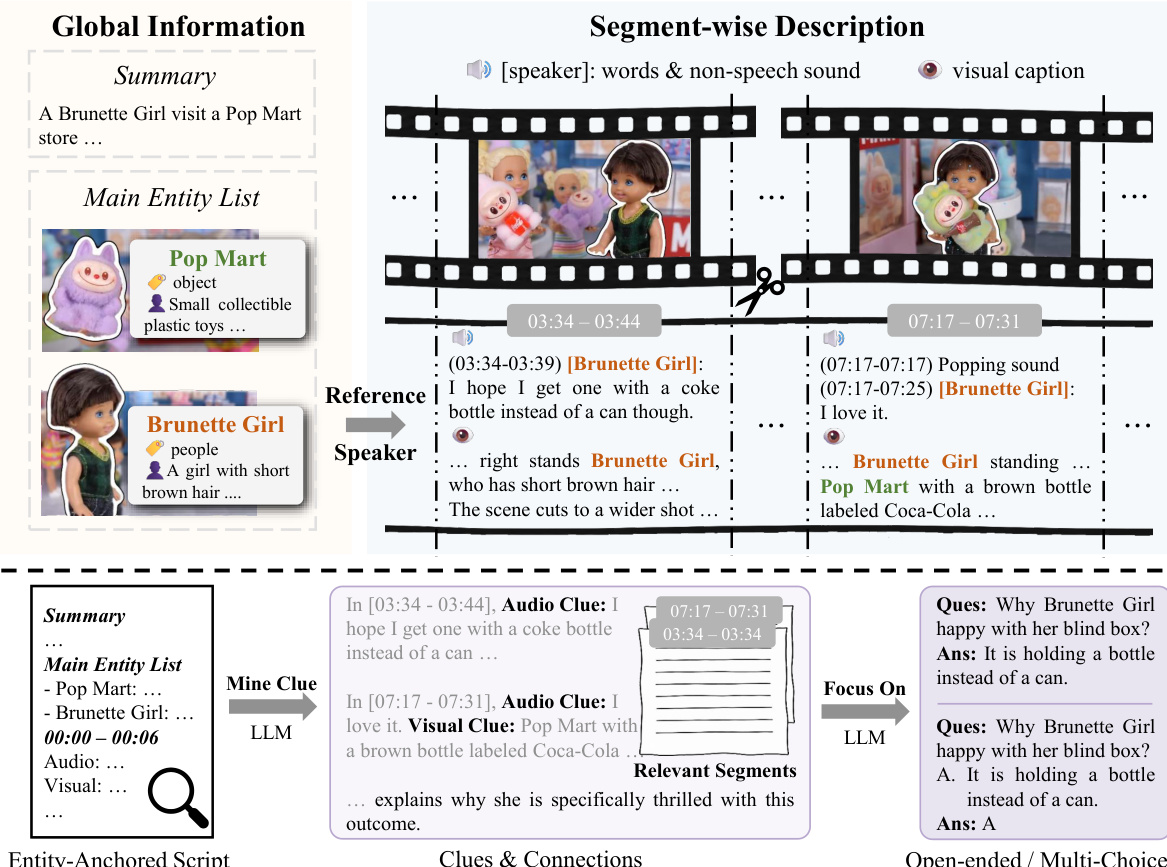
实体锚定视频脚本
该阶段将原始视听视频转换为结构化的脚本式文本,以确保叙事连贯性和显式的视听关联。
主实体列表 在处理片段之前,作者利用多模态大语言模型识别对视频叙事至关重要的主要活动实体(人、动物、物体)。为每个实体生成唯一的描述标识符和详细特征描述。此列表作为全局先验,约束后续描述并确保实体引用的一致性。该识别过程使用的提示如下所示。

音频信息处理 处理音频流以提取语音和非语音声音。多模态大语言模型根据自然停顿或说话人变化生成带时间戳的语音转录。生成这些转录的具体提示如下所示。

同时,模型识别非语音声音(如音乐、环境噪声),并按时序记录时间戳,避免推断上下文。该声学事件记录的提示如下所示。

连贯的分段视觉叙事 视频被划分为主要片段(目标时长15秒),以建立时间骨架。基于视频帧为每个片段生成视觉描述。多模态大语言模型从四个维度分析镜头:场景与环境、角色与物体、动作与交互、电影摄影。主实体列表用作先验以确保引用一致性。指示模型生成这些详细视觉描述的提示如下所示。

声源关联与摘要 为连接音频与视觉模态,多模态大语言模型通过联合分析视觉和音频特征识别每个转录的说话人。若说话人已在主实体列表中,则使用现有标识符;否则生成新的。此过程也处理画外说话人。最后,受主实体列表约束,生成视频的高级摘要。该摘要生成的提示如下所示。

线索引导的问答生成
基于连贯的脚本,作者采用两步策略构建具有长期时间跨度和深层跨模态依赖的问答对。
全局线索挖掘 大语言模型扫描整个脚本,提取特定任务问答生成所需的线索(例如因果推理)。此步骤强调整合多个片段和模态的信息以构建推理链。模型提供相关片段的时间戳以及视听协同的逻辑描述,将隐式理解转化为显式推理步骤。
局部聚焦生成 利用挖掘步骤提供的逻辑描述和时间戳作为上下文提示,模型聚焦关键片段生成问答对。此方法过滤无关内容,降低认知负荷,并确保生成的问题同时需要长期时间推理和视听协同。生成过程产生开放式和多项选择题,需通过严格的可解性测试(如盲测和单模态陷阱检查)加以验证,以防止单模态或简单匹配式答案。
实验
评估阶段在OmniVideo-100K上微调了VITA-1.5、Qwen2.5-Omni-7B和Qwen3-Omni-30B-A3B,并在新提出的OmniVideo-Test套件及若干现有视听和通用视频基准上进行评估。关键发现是,OmniVideo-100K大幅提升了跨模态协同与时间对齐,使模型从单模态推测转向有依据的视听推理,在具有挑战性的对齐与推理任务上取得巨大提升,同时保持通用视频理解能力。数据生成消融研究表明,基于线索引导、脚本驱动的pipeline产生的问题具有更长的时间跨度和更严格的跨模态依赖性;保持实体一致性和说话人标签显著减少了指代混乱和声源不匹配,验证了数据集的质量。数据扩展实验证实,即使使用小子集也能快速提升性能,约在7.5万样本时趋于饱和,表明自动化生成方法的高效性。
作者比较了各种多模态大语言模型在直接生成与线索引导策略生成的问答对上的准确率。结果显示,所有模型在线索引导集上准确率更低,表明该策略生成了更有挑战性的问题。微调后的模型在要求更高的线索引导集上相比基线有显著提升,验证了训练数据的有效性。所有模型在线索引导式问答对上表现均不如直接生成对,确认了线索引导策略带来的难度增加。微调后的模型在具有挑战性的线索引导集上相比基线模型取得了显著的准确率提升。不同模型在线索引导对上的性能差距更加明显,表明该策略能更好地区分不同的模型能力。

作者研究了生成的训练数据量如何影响模型性能,通过在大小不同的子集上进行微调。结果显示,即使引入少量数据也能在多个基准上带来显著性能提升,随着数据量增加到一定程度,性能稳步提升,之后在最大规模时达到饱和或出现轻微波动。与基线相比,引入一小部分训练数据几乎在所有评估基准上带来了巨大的性能飞跃。随着训练数据量从小规模增加到中等规模,模型性能表现出稳步提升。将数据集扩展到最大规模时性能略有波动或饱和,表明继续扩展数据带来的收益递减。

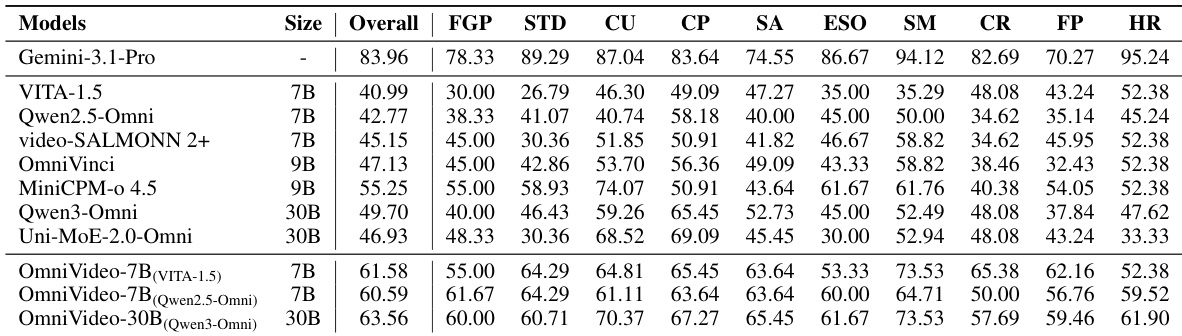
作者在OmniVideo-Test基准上评估了各种多模态大语言模型,以评估其在理解、对齐和推理任务上的能力。结果表明,现有开源模型通常在理解任务上表现优于对齐和推理任务。在这些模型上使用OmniVideo-100K数据集进行微调,在所有任务维度上都带来了显著的性能提升,有效增强了其协同视听理解能力。现有开源模型通常在理解任务上表现优于对齐和推理任务,表明其在时间对齐和深层跨模态推理方面存在局限。在OmniVideo-100K数据集上微调后的模型在所有任务维度上均显著超越其基线,包括细粒度感知和因果推理。微调后的模型一致地优于其他开源基线,其中最大的微调模型在开源变体中取得了最高的总得分。
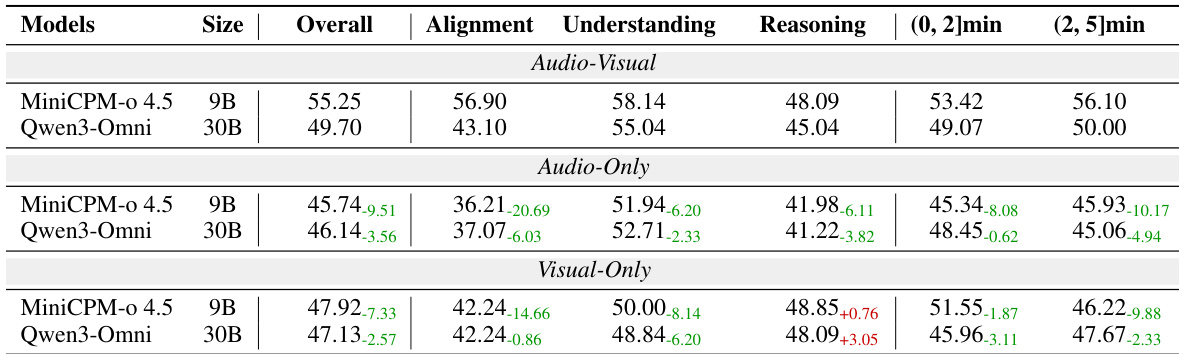
作者在视听、仅音频和仅视觉设置下评估了MiniCPM-o 4.5和Qwen3-Omni,以分析跨模态依赖性。结果显示,当限制为单一模态时,两个模型性能均下降,证实测试集需要跨模态协同。MiniCPM-o 4.5在提供两种模态时相比Qwen3-Omni表现出更大的性能提升,表明其协同增益更高。与完整视听设置相比,两个模型在单模态设置下性能均下降。MiniCPM-o 4.5通过结合模态获得的性能提升大于Qwen3-Omni。两个模型的单模态性能相当,差距极小。
作者评估了在OmniVideo-100K上微调后的模型在各种视听和通用视频基准上的泛化能力。结果表明,在该数据集上微调持续提升了专业视听任务的性能,同时保持了模型原有的通用视频理解能力。使用OmniVideo-100K微调在多个视听基准(如Daily-Omni和JointAVBench)上带来了一致的性能提升。微调后的模型在通用视频理解任务(如Video-MME)上保持了基线性能,未见显著下降。在评估基准上,AVQA和JavisInst-Und等替代数据增强方法通常表现不及OmniVideo-100K微调模型。

实验首先验证了线索引导式的问答生成策略产生了更难的多模态评估集,因为所有模型在这些问题上的准确率更低,且性能差距加大,更好地区分了模型能力;一个微调模型在这一具有挑战性的集合上取得了显著增益。在OmniVideo-100K数据集上微调持续提升了模型在理解、对齐和推理任务上的表现,同时保持了通用视频理解能力,即使少量训练数据也能在饱和前带来显著提升。跨模态协同至关重要,模型在单模态设置下性能急剧下降,而MiniCPM-o 4.5表现出更大的协同增益,微调后的模型一致地超越其他开源基线。