Command Palette
Search for a command to run...
从聊天机器人到数字同事:迈向持久自主人工智能的范式转变
从聊天机器人到数字同事:迈向持久自主人工智能的范式转变
摘要
大型语言模型(LLMs)正经历一场根本性转变,从对话生成器转变为具备推理、行动、记忆和自我改进能力的集成化人工智能系统。我们将这一过渡概念化为从Chatbot到Digital Colleague的转变:从对话式回答转向持续性工作。我们沿两个紧密耦合的维度来组织这一过渡过程。首先,在认知核心层面,LLMs正从由下一个token预测驱动的Chatbot时代“快速思维”系统,向利用推理时计算、Chain-of-Thought推理、反思、过程监督和强化学习以支持更审慎、更可靠认知的Thinking LLMs迈进。其次,在工具增强型任务执行层面,LLMs正从以临时方式调用外部资源的tool-calling agents,向配备持久化Workspaces、技能、验证循环和治理机制的OpenClaw-style工作站系统(OpenClaw)演进。“Workspace + Skill”范式通过状态持久化、可复用流程、任务闭环和经验复用,使偶发性的工具使用具备同事般的工作特征。我们探讨了数据构建从instruction-response pairs向State-Action-Observation trajectories的转变,以及评估方式从静态基准测试向sandboxed、auditable、self-evolving AI ecosystems的转变。
一句话总结
作者提出了一种框架,用于描述大语言模型从对话式聊天机器人向持久化数字同事的演进。该框架将利用推理时计算和强化学习的 Thinking LLM 与 OpenClaw 风格的工作站相结合,以持久化的 Workspaces 和 Skills 替代临时性的工具调用,从而实现具有状态保持和自验证特性的执行过程。整个系统由 State-Action-Observation 轨迹数据支撑,并在沙盒化、可审计、自演化的生态系统中进行评估。
核心贡献
- 本文引入“Workspace + Skill”范式,重新定义大语言模型从对话式聊天机器人向持久化数字同事的演进,实现状态持久化、可复用流程与可靠的任务闭环。
- 提出以 Workspace 为中心的建筑视角,整合碎片化的 agent 能力,证明包含文件、终端和权限的持久化环境如何决定系统感知与恢复机制,并将安全治理提升为核心设计要求。
- 建立数据与评估框架,将训练数据从指令-响应对转向 State-Action-Observation 轨迹,利用沙盒化、可审计的生态系统来度量环境状态变化与任务完成情况。
引言
大语言模型正从被动的对话接口转变为具备深思熟虑推理、环境交互与持续任务执行能力的自主系统。这一转变至关重要,因为它将 AI 从文本生成工具重新定义为能够处理复杂多步骤专业工作流的可靠数字同事。然而,先前的架构仍受限于缺乏深度验证的快速响应生成,而早期的 agent 框架则存在工具调用碎片化、状态管理短暂以及长周期执行脆弱等问题。作者利用二维框架来描绘这一演进过程,跟踪认知层面从概率化 next-token 预测向推理时推理的迁移,以及执行层面向持久化工作站环境的转变。其核心贡献在于 Workspace + Skill 范式,该范式以持久的状态保持、可复用的流程知识与可验证的任务闭环取代了短暂的交互。通过将这一架构跃迁与训练数据及评估指标的相应转变相结合,作者为构建安全、可审计且自演化的 AI 生态系统确立了技术路线图。
数据集

- 数据集构成与来源: 作者描述了一个与模型能力同步演进的多阶段数据生态系统。数据收集涵盖静态知识语料库、人工标注的对话对、众包指令集、自生成推理轨迹以及交互式工作区执行日志。数据来源广泛,涵盖网页文本、书籍、代码仓库,直至模拟的生产力服务、真实操作系统以及专为可复现 agent 测试设计的高保真模拟环境。
- 各子集关键细节:
- 聊天机器人与 SFT 数据包含人工标注的指令-响应对、偏好比较以及侧重于指令遵循与安全对齐的自指导对话。
- 推理数据包含思维链轨迹、中间计算步骤、数学证明及代码生成路径。这些子集包含步骤级正确性标注,以及从更强模型中蒸馏或通过自洽性方法过滤的可验证轨迹。
- agent 与工作区轨迹数据包含记录工具调用、终端输出、文件系统变更、UI 截图与 DOM 状态的 State-Action-Observation 序列。该子集整合了可复用的技能包、权限边界与任务历史,以支持长周期工作流。
- 训练用途与处理: 作者采用渐进式流水线,从答案模仿转向奖励引导的探索。早期子集用于监督微调与直接偏好优化。推理子集经过蒸馏、修订与逐步过滤,以支持过程奖励建模。agent 轨迹被结构化以训练模型进行动态环境导航,并应用强化学习于可验证的任务完成信号。训练数据混合物优先保障轨迹连续性与最终状态验证,确保模型学会从错误中恢复并适应动态条件。
- 元数据构建与结构处理: 数据被组织为可验证的序列而非孤立提示。作者强调构建结构化技能资产,包含版本控制、依赖声明、触发条件与安全权限。轨迹通过显式状态快照、执行日志与最终状态差异进行捕获,以支持可复现性。处理流水线会过滤无效步骤,将工具输出与环境反馈对齐,并将安全护栏直接嵌入元数据。该方法以全面的验证栈取代简单的文本重叠指标,用于追踪任务闭环、执行可靠性与轨迹级安全。
方法
作者概述了 AI 系统的渐进式架构框架,描述了从简单响应生成向自主、任务导向数字同事的演进。该框架由五个明确的里程碑定义,每个里程碑引入新模块与能力以解决前一阶段的局限性。这一演进的整体轨迹在下方的路线图可视化中呈现:
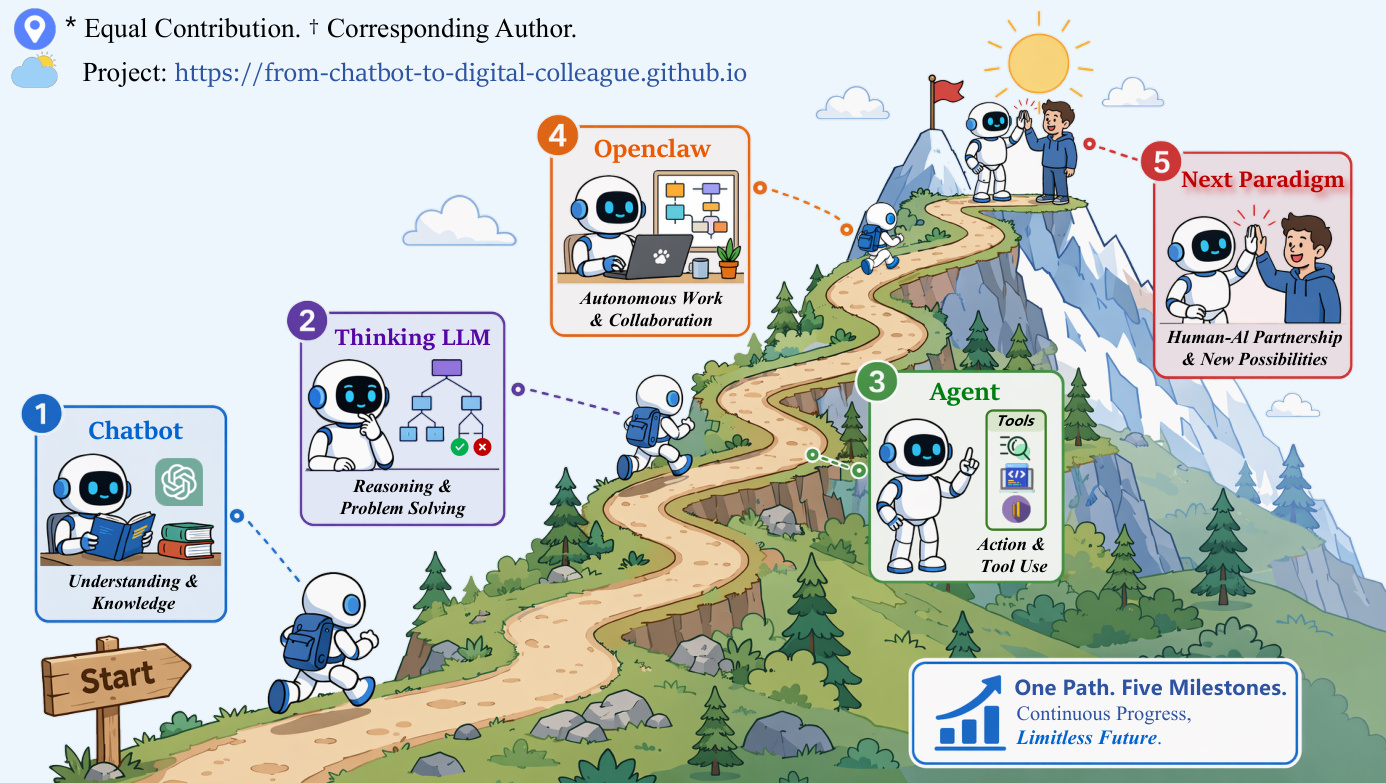
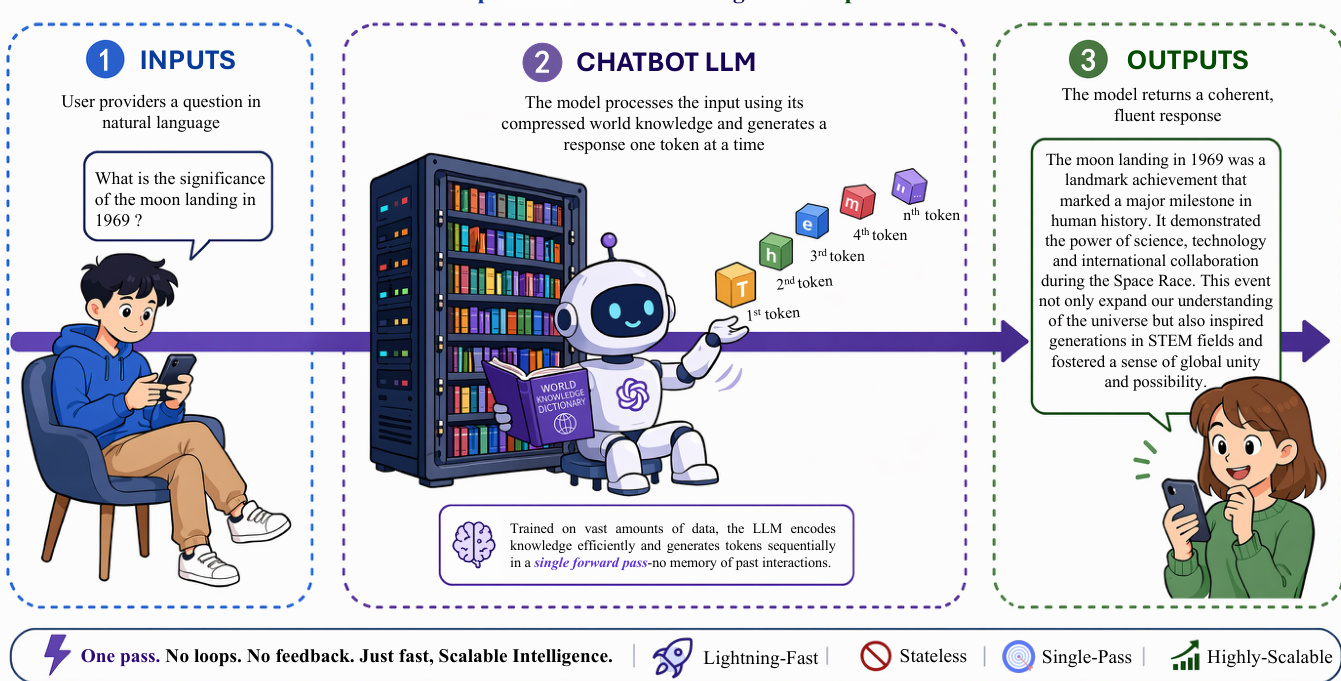
这一演进的基础是 Chatbot LLM 架构。在此范式中,模型作为无状态函数运行,处理用户输入并在单次前向传播中以 token 为单位生成响应。尽管该方法具备高可扩展性与低延迟优势,但无法在交互间保持记忆,也无法在直接上下文窗口之外执行多步推理。系统完全依赖编码于模型权重中的压缩世界知识来生成连贯文本。如下图所示:
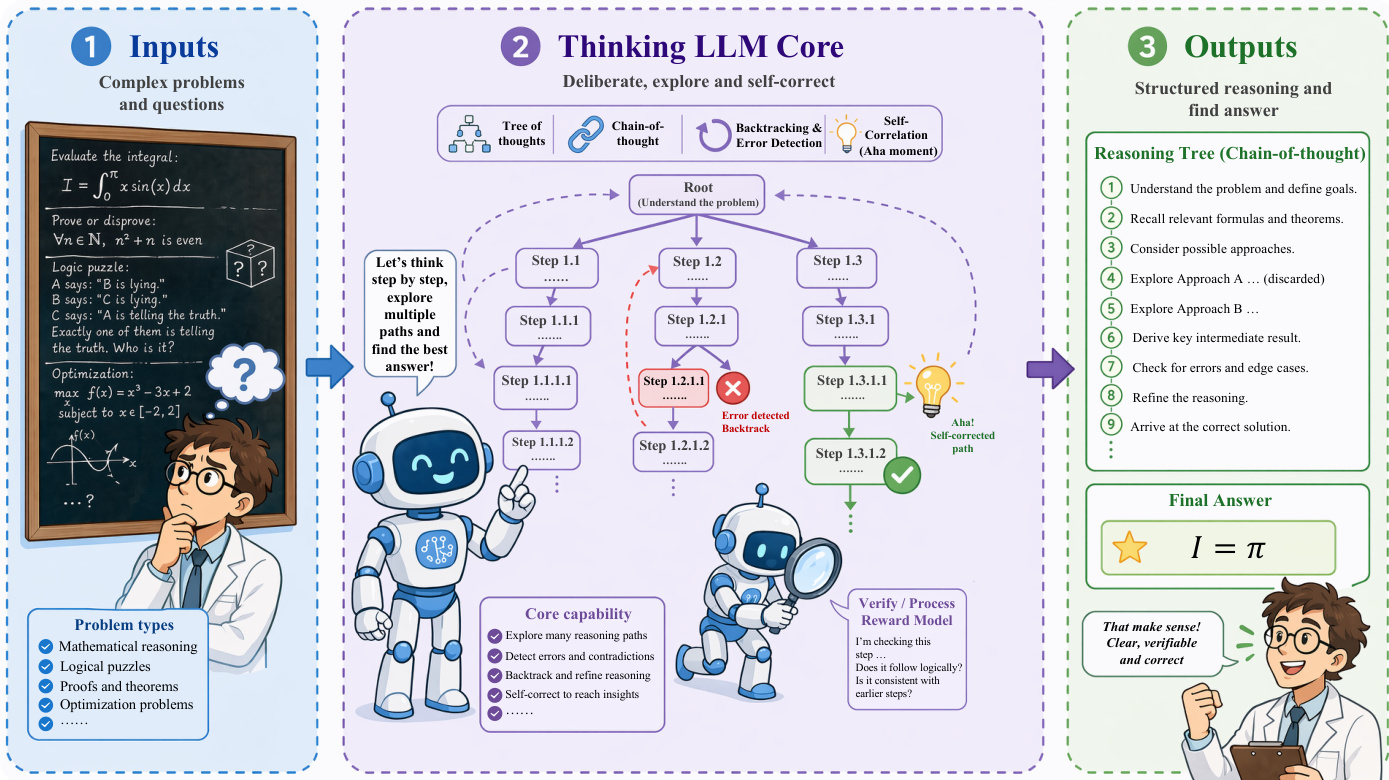
为克服单次生成模式的局限,作者引入了 Thinking LLM 架构,为模型赋予深思熟虑的推理能力。该模块使系统能够通过探索多条推理路径、检测错误与自我修正来处理复杂问题。核心机制涉及生成推理树(如 Chain-of-Thought 或 Tree of Thoughts),模型在此过程中迭代优化其方法。系统可从失败步骤回溯,验证中间结果,并综合洞察直至推导出经验证的最终答案。该架构将模型从被动响应者转变为能够进行结构化、可验证推理的主动问题解决者。该推理核心的内部工作流程如下图所示:
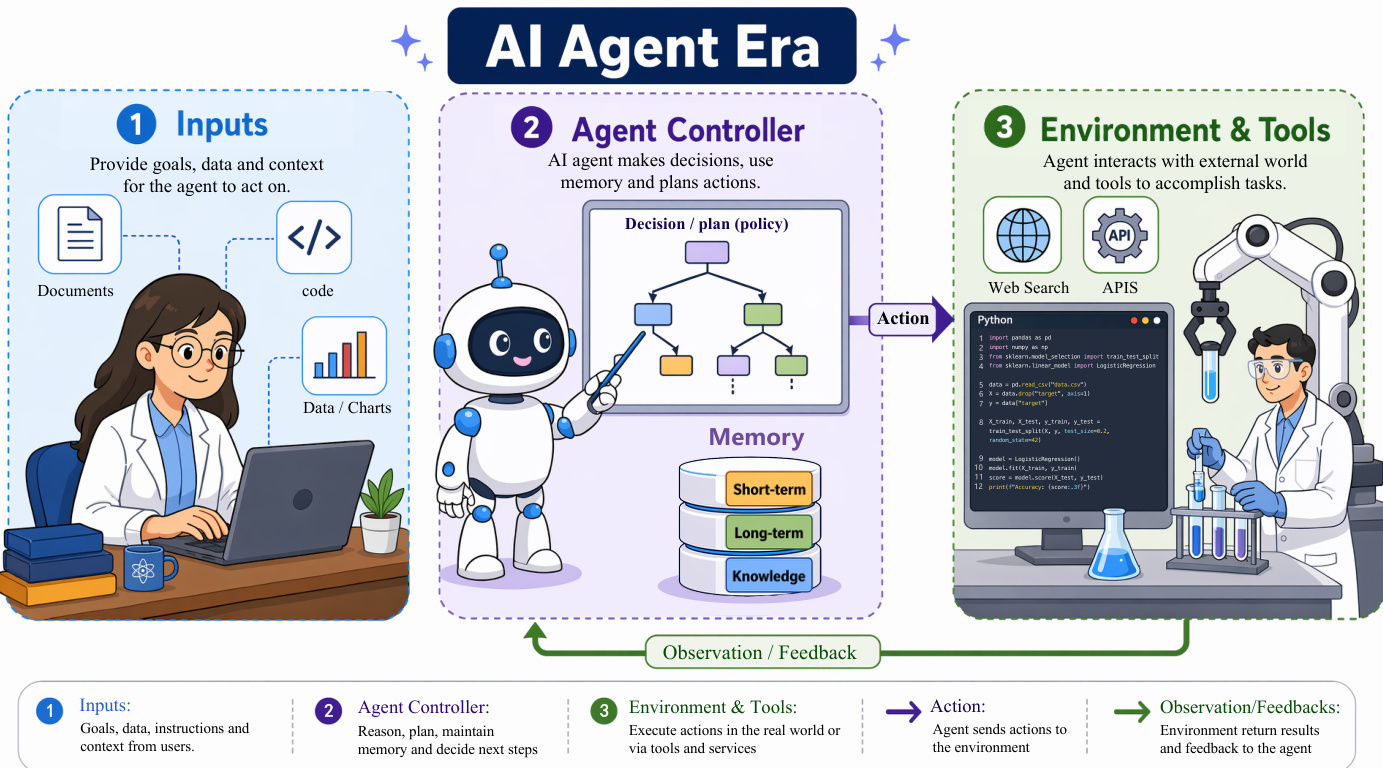
下一个架构跃迁是 Agent 时代,通过闭环交互框架将模型的认知延伸至外部世界。该系统围绕“观察-思考-行动”循环组织,agent 在此过程中感知环境、规划行动并调用工具以产生实际影响。架构通常划分为四个核心模块:感知(Perception),负责解析文本或视觉输入;规划(Planning),利用搜索或分解策略将目标拆解为可执行步骤;记忆(Memory),在长周期内维持上下文并积累经验;工具使用(Tool Use),使模型能够调用外部 API 并执行代码。该循环使 agent 能够从失败中恢复并适应动态环境,实现从孤立响应到持续交互的转变。agent 架构在闭环中运行,如下图所示:
最后,作者提出 OpenClaw 范式,将焦点从孤立工具调用转向数字工作区内持久化、受控的工作执行。该架构将持久化环境与模块化、可复用技能相结合,以确保任务闭环与可靠性。Workspace 作为持久化载体,使文件、日志与执行状态在轨迹间得以保留,允许 agent 进行检查、验证与错误恢复。Skills 以模块化包形式实现,通常围绕配置文件构建,提供流程指导、安全约束与验证逻辑。系统在安全沙盒中运行,执行操作并持续验证最终状态是否符合任务目标。该设计使 agent 能够提供可审计、可验证的结果,而非仅仅提供短暂响应。OpenClaw 系统将这些组件整合至持久化工作区中,详细工作流程如下:
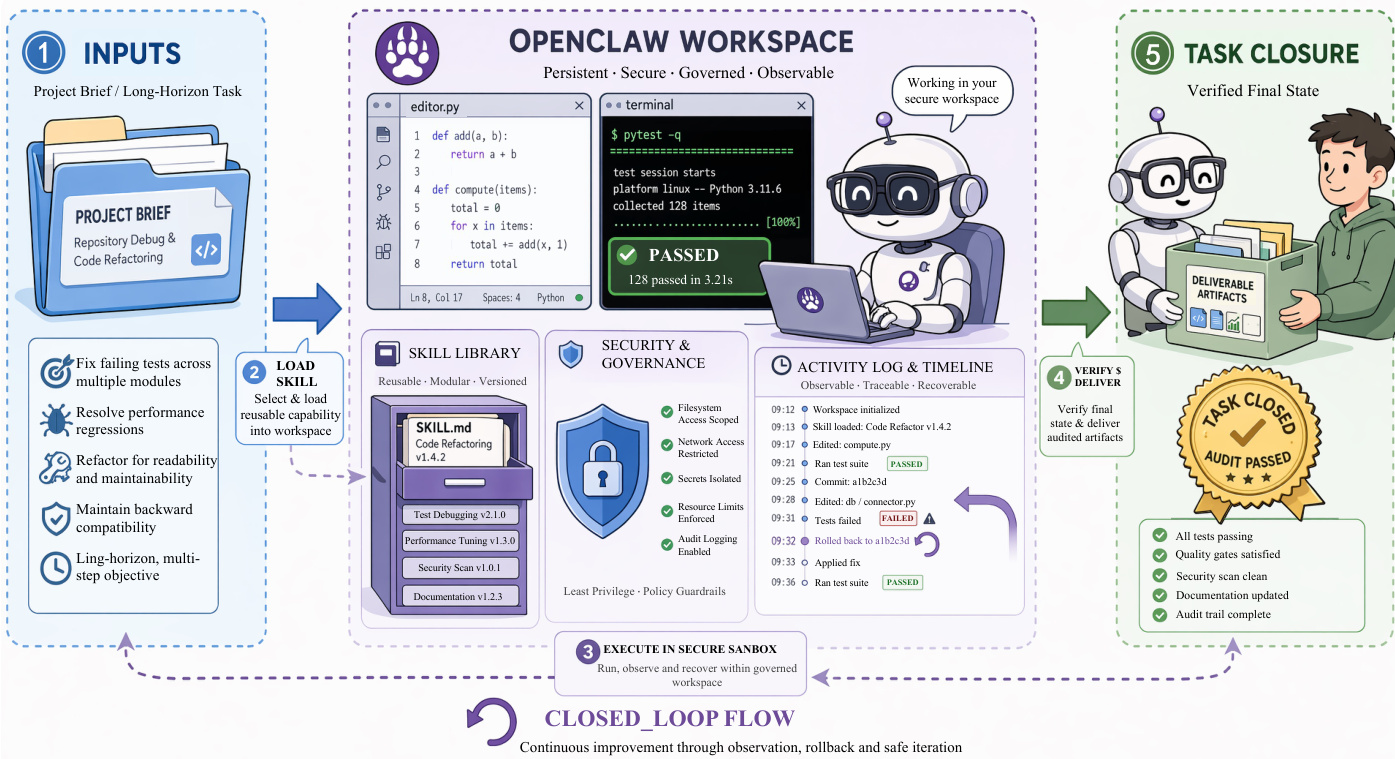
实验
评估框架已历经三个阶段,用于验证日益复杂的 AI 行为。早期方法通过最终输出正确性验证静态任务,后续方法转而评估多步推理的连贯性与忠实度。现代验证则聚焦于智能体系统的任务闭环,验证工具使用与环境修改是否成功达成预期的现实世界目标。这一演进凸显了从表层答案匹配向推理有效性与功能自主性全面评估的根本性转变。
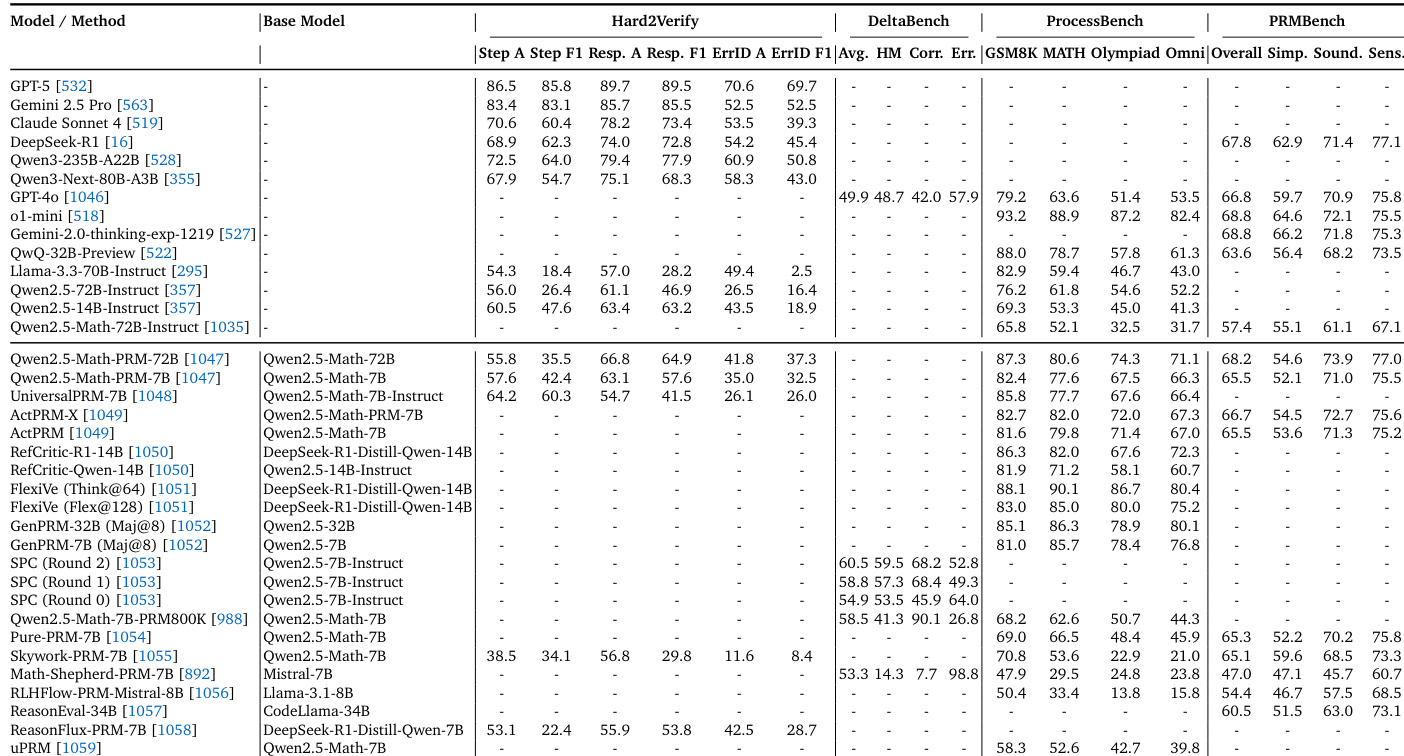
下表展示了针对第二阶段过程级推理与验证的各类模型与方法的综合评估。该表在 Hard2Verify、DeltaBench、ProcessBench 与 PRMBench 等多个基准上,对比了通用大语言模型与专用过程奖励模型(PRMs)及验证技术的表现。结果凸显了标准推理模型与专为步骤级验证及过程质量评估设计的模型之间的性能差异。GPT-5 与 o1-mini 等通用模型在步骤级验证与标准数学推理任务中展现出强大能力,在 Hard2Verify 和 ProcessBench 上的表现通常优于专用 PRM 基线。Qwen2.5-Math-PRM 与 ActPRM 等专用过程奖励模型在 PRMBench 上接受评估,提供了简洁性、健全性与敏感性等过程质量维度的具体指标,这些指标在通用模型中通常未予报告。评估框架涵盖广泛的过程级指标,包括步骤级准确率、正确召回与错误召回的调和平均数以及综合过程质量得分,充分揭示了过程推理评估的复杂性。
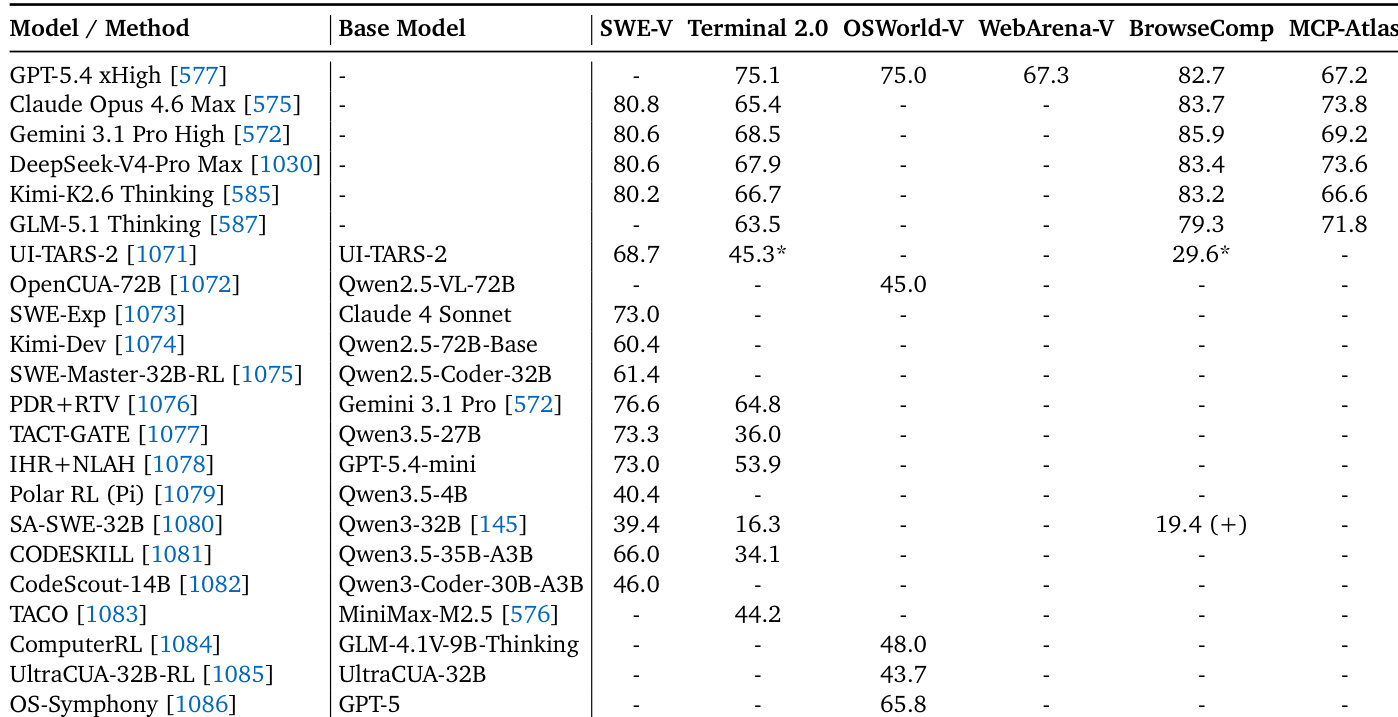
作者展示了在任务闭环基准上评估的 agentic 模型的对比分析,反映了从最终答案准确率向环境交互的范式转变。下表将通用模型与专用方法并列,评估其在软件工程、终端、操作系统与网页导航任务上的表现。GPT-5.4、Claude Opus 与 Gemini 等顶级通用模型在 SWE-V、Terminal 2.0 与 WebArena-V 等多个 agentic 基准上展现出广泛的能力。专用模型与方法通常针对特定领域,部分聚焦于 UI 任务(UI-TARS-2)、软件工程(SWE-Exp)或操作系统交互(OpenCUA-72B)。结果表明,专用方法(尤其是利用 Qwen2.5 变体等特定基础模型的方案)在 SWE-V 与 OSWorld-V 等基准上可达到具有竞争力的性能。
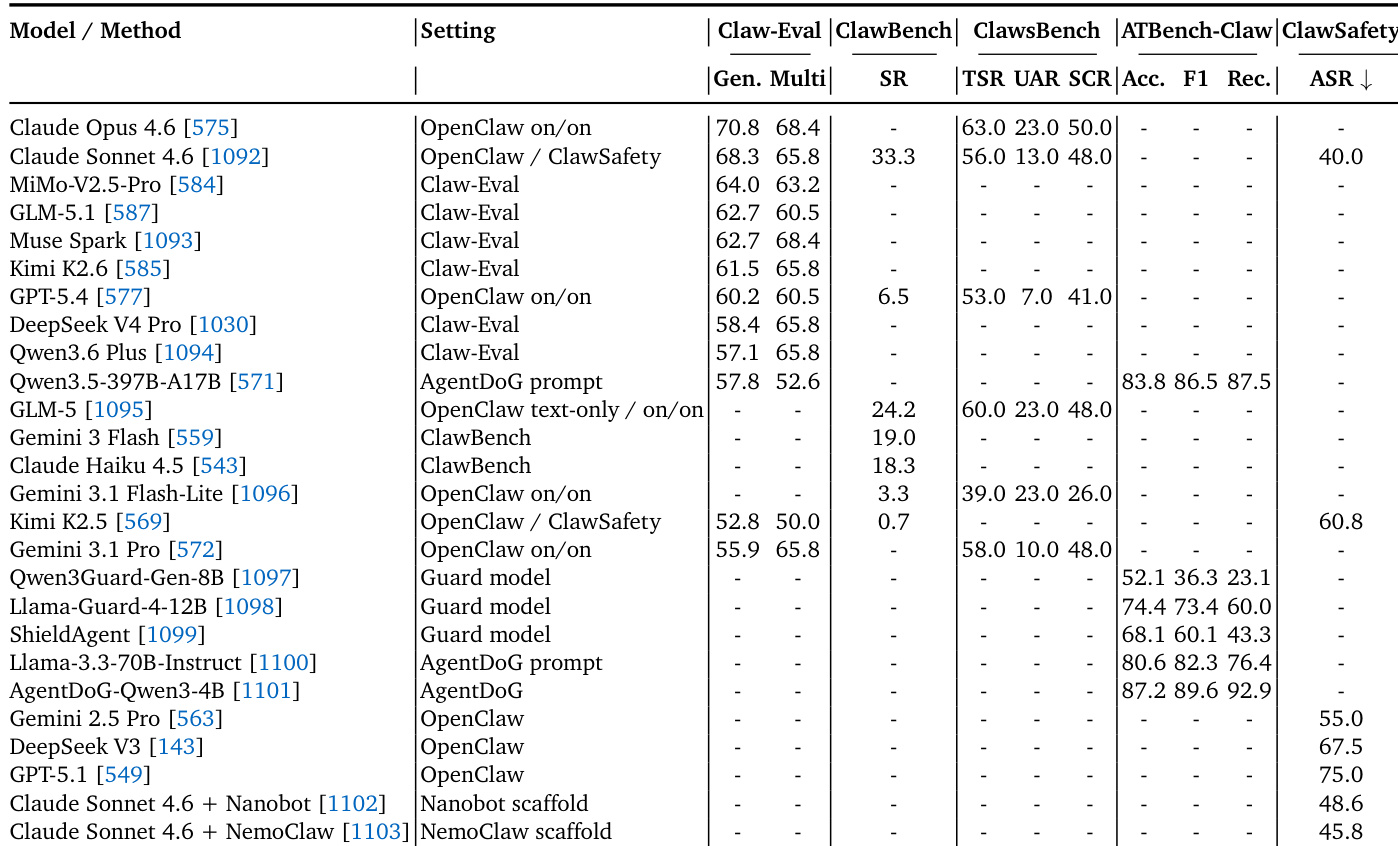
下表在旨在评估 agentic 能力(包括任务完成、安全推理与抗攻击性)的基准上,对一系列大语言模型与专用方法进行了评估。Claude Opus 4.6 与 Claude Sonnet 4.6 通常在任务成功指标上领先,并展现出比其他模型更强的安全韧性。专用防护模型与脚手架表现出参差的结果,部分在推理任务中表现优异,而另一些则未能在安全指标上超越基础模型。Claude Opus 4.6 在通用与多轮任务完成基准上取得最高性能,优于其他领先模型。Claude Sonnet 4.6 展现出最强的安全配置,攻击成功率最低,显著优于 GPT-5.1 等模型。采用提示策略的专用 agent 方法在轨迹安全推理方面达到高度熟练,而专用防护模型在这些指标上的表现相对较低。
下表在通用知识、数学推理与编程基准上对比了各类语言模型。顶级商业模型在大多数通用与编程基准上展现出优越的性能。专用模型通常聚焦特定领域,在数学推理任务中表现强劲,但在通用知识评估中有时得分较低。顶级商业模型在通用知识与编程基准上领先。专用模型在数学推理任务中表现卓越。专注于特定推理技术的模型通常在数学基准上得分较高,但缺乏跨类别的全面评估。
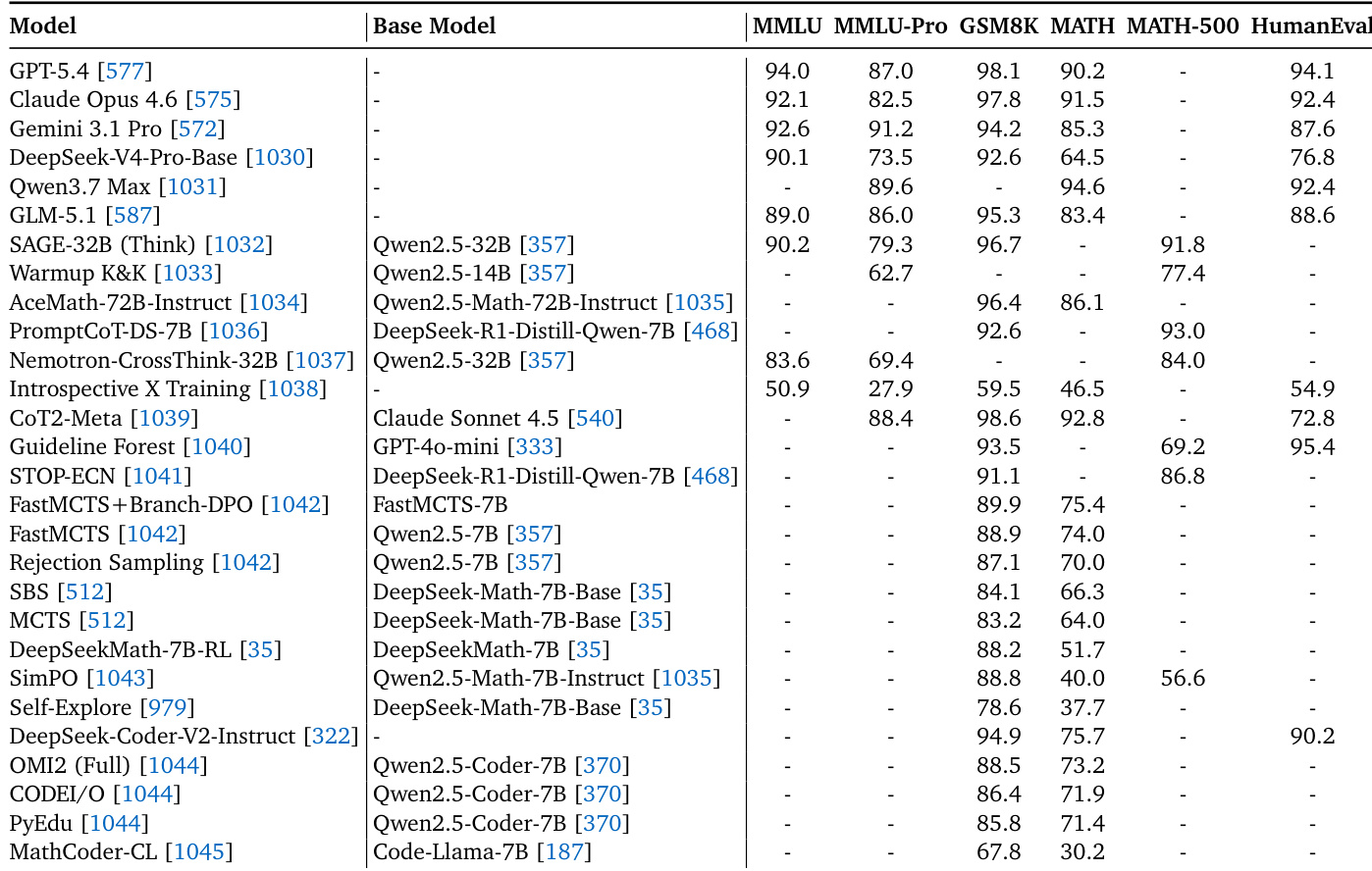
实验在针对过程级推理、agentic 任务闭环、安全韧性以及核心领域能力的基准上,评估了广泛分布的通用与专用大语言模型。结果一致表明,领先商业模型在通用知识、编程与多轮 agentic 任务中展现出广泛的适应性与强劲性能。相比之下,专用模型与验证技术表现出针对性优势,尤其在步骤级数学推理与领域特定交互方面,尽管它们往往缺乏全面的跨领域覆盖。总体而言,研究结果凸显了通用模型的广泛适应能力与专用方法的聚焦效能之间的明确权衡。