Command Palette
Search for a command to run...
HarnessX:一个可组合、自适应且可演化的智能体制造工厂
HarnessX:一个可组合、自适应且可演化的智能体制造工厂
Darwin Agent Team
摘要
AI Agent 的性能在很大程度上取决于其运行时的运行环境(Runtime Harness),该环境由提示词(Prompts)、工具(Tools)、记忆(Memory)和控制流(Control Flow)组成,它们共同调节模型如何观察、推理和行动。然而,当前的运行环境大多仍依赖手工编写且是静态的:每引入一个新模型或新任务,仍需定制专门的支撑架构,而在执行过程中产生的丰富轨迹数据很少被提炼并反馈用于系统的持续改进。为此,我们提出了 HarnessX,这是一个用于构建可组合、自适应及可演进 Agent 运行环境的工厂(Foundry)。HarnessX 通过替换代数(Substitution Algebra)组装类型化的运行环境原语;利用 AEGIS——一种基于符号适配与强化学习之间操作镜像的、由轨迹驱动的 Multi-Agent 演化引擎——对这些原语进行适配;并通过将轨迹转化为运行环境更新信号和模型训练信号,从而闭合“运行环境–模型”的闭环。在 ALFWorld、GAIA、WebShop、τ3-Bench 和 SWE-bench Verified 五个基准测试中,HarnessX 带来了平均 +14.5% 的性能提升(最高达 +44.0%),且在基线性能较低的领域提升幅度最大。这些结果表明,Agent 的进步不必仅依赖于模型规模的扩展:基于执行反馈对运行时接口进行组合和演化,是一个可行且具有互补性的优化杠杆。完整的代码库将在未来的版本中开源。
一句话总结
Darwin Agent 团队推出了 HarnessX,这是一个用于构建可组合、自适应和可进化的 agent harnesses 的构建平台,它通过替换代数组装类型化原语,并通过 AEGIS(一种基于轨迹驱动的多 agent 进化引擎)对其进行调整,从而通过将轨迹转化为 harness 更新和模型训练信号来关闭 harness-模型循环,在五个基准测试(ALFWorld、GAIA、WebShop、τ3-Bench 和 SWE-bench Verified)上实现了平均 +14.5% 的提升,并证明了进化运行时接口是对模型扩展的补充。
核心贡献
- 这项工作介绍了 HarnessX,这是一个用于构建可组合和可进化的 agent harnesses 的构建平台,旨在克服静态、手工制作的 scaffolding 的局限性。
- 该系统通过替换代数组装类型化的 harness 原语,并通过 AEGIS(一种基于轨迹驱动的进化引擎)对其进行调整,通过将执行轨迹转化为 harness 更新和模型训练信号来关闭循环。
- 在五个基准测试上的评估表明,平均性能提升为 +14.5%,峰值高达 +44.0%,表明进化运行时接口是对模型扩展的补充。
引言
AI agent 性能至关重要地依赖于通过提示词、工具和流程控制来调解模型行为的运行时 harness。尽管这一点很重要,现有的 harness 仍然是手工制作且静态的,需要针对新任务进行定制修改,同时丢弃了有价值的执行轨迹。该研究通过 HarnessX 解决了这些差距,这是一个将 harness 视为使用类型化原语和替换代数的可组合一等对象的构建平台。该系统采用 AEGIS,一种基于轨迹驱动的进化引擎,调整 harness 组件并通过模型训练关闭循环,从而在不单纯依赖模型扩展的情况下在五个基准测试上实现显著的性能提升。
数据集
该研究利用一个全面的评估套件来评估 agent 在各种失败模式下的性能。
-
数据集组成和来源
- 评估涵盖五个基准测试:GAIA、ALFWorld、WebShop、τ3-Bench 和 SWE-bench Verified。
- 这些来源涵盖的任务范围从短视野具身规划到长视野软件工程。
-
每个子集的关键细节
- GAIA: 包含 103 个任务,分布在三个难度级别上,用于评估与参考答案的精确匹配。
- ALFWorld: 使用包含 134 个任务的有效 - 未见分割,涵盖六种类型,包括抓取放置和冷却放置。
- WebShop: 采样 100 个实例,使用固定种子来模拟独立的在线购物会话。
- τ3-Bench: 专注于三个领域(零售、航空和电信),以测试对话策略的依从性。
- SWE-bench Verified: 选择了一个 55 个任务的子集,用于测量真实 GitHub 问题上的补丁解决情况。
-
数据使用和 Processing
- 固定评估集在每次进化轮次中重新评分,以在稳定的任务集上测量轮次间的变化。
- 每次运行生成一个自描述目录布局,包含 INDEX.md、journal.md 和 audit.jsonl 等工件。
- 元数据构建包括存储在 data/ship_outcomes.json 中的跨轮次分类账以及 digests 文件夹中的每任务分析。
- 原始 rollouts 和候选 manifests 保存为 jsonl 文件,以支持决策重建。
方法
该研究提出了 HarnessX,这是一个旨在关闭 agent scaffolding 和模型能力之间优化循环的框架。该系统通过一个连续循环运行,其中执行 harness 被组合,基于运行时轨迹进行调整,并与底层基础模型一起进化。参考框架图以了解组合、调整和进化之间的高级交互。
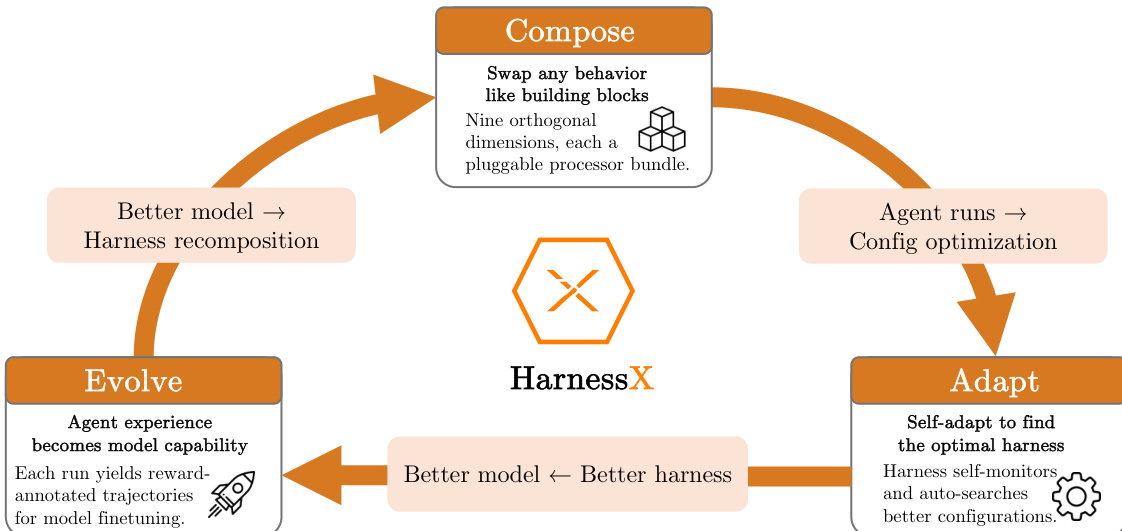
Harness 组合和 AEGIS 架构
系统的基础层是 harness,被形式化为一个一等、类型化对象。一个 harness H 由模型配置 M 和 harness 配置 C 组成。配置 C 由附加到特定生命周期钩子的处理器组成,允许插入、移除或交换行为更改而不破坏类型安全。该研究将行为空间组织为九个正交维度,涵盖模型选择、上下文组装、内存管理和工具生态系统等方面。
为了自动化这些配置的改进,该研究引入了 AEGIS,一种基于轨迹驱动的进化引擎。如下图所示:
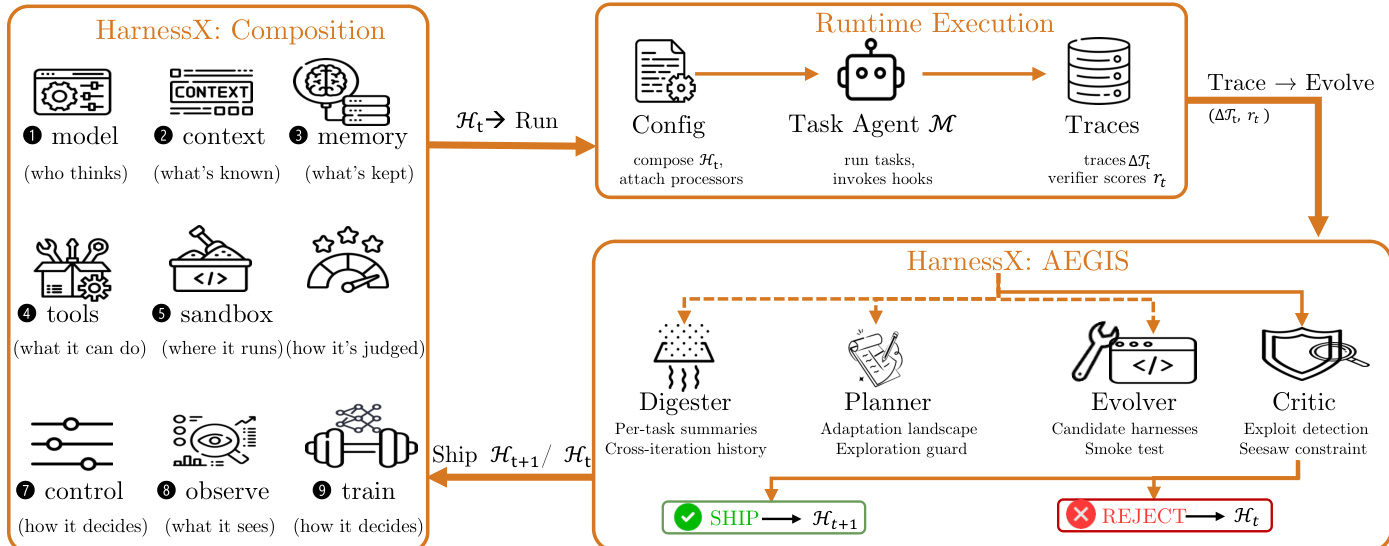
AEGIS 将 harness 调整映射到标准强化学习构造上,将 harness 配置视为状态,将类型化代码编辑视为动作。为了解决常见的 RL 病理问题,如奖励黑客攻击和灾难性遗忘,该引擎采用由 meta-agent 驱动的四阶段流水线:
- Digester: 将原始执行轨迹压缩为结构化的每任务摘要,识别失败类别和相关组件。
- Planner: 通过分析消化后的证据和历史编辑来构建调整景观,确定哪些结构性或增量式更改是可行的。
- Evolver: 基于调整景观生成候选 harness 编辑,通过构建器代数确保类型安全。
- Critic: 根据轨迹证据和回归约束验证候选项。
确定性门控层跟随 Critic,强制执行“跷跷板约束”,即候选编辑仅在不会降低先前解决任务的性能时才会发布。这确保了即使 meta-agent 提出激进更改,进化也能安全进行。
Harness-模型协同进化
虽然单独进化 harness 会产生显著收益,但该研究识别出一个"scaffolding 上限”,其中固定模型的推理能力最终限制了性能。相反,在固定 harness 下训练模型会触及“训练信号上限”。为了打破这些限制,HarnessX 将 harness 进化与模型强化学习交错进行,共享一个 replay buffer。
协同进化机制如下图所示:
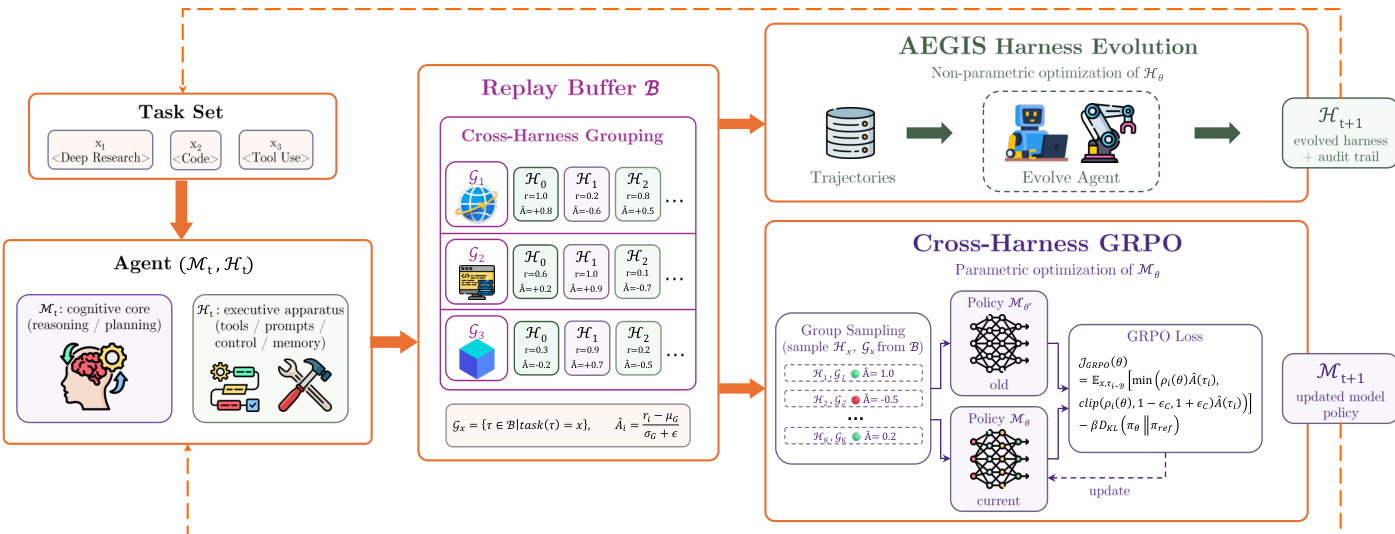
系统维护一个共享 replay buffer B,存储来自多次迭代的轨迹 (τ,r),每个轨迹都标记了生成它的具体模型和 harness 版本。该 buffer 驱动两个并行优化过程:
- AEGIS Harness 进化: meta-agent 读取缓冲的轨迹以提出对 harness Ht 的非参数结构性编辑,产生 Ht+1。
- Cross-Harness GRPO: 模型 Mt 通过 Group Relative Policy Optimization 进行更新。轨迹按任务身份在不同 harness 版本之间分组,允许模型基于跨策略奖励对比而非仅随机采样噪声来计算优势。
轨迹 τi 的组相对优势 A^(τi) 计算如下:
A^(τi)=σ(Gx)+ϵri−μ(Gx)其中 Gx 表示 buffer 中任务 x 的所有轨迹集合,无论使用的 harness 版本如何。这种方法允许模型内化来自连续 harness 版本的成功策略,有效地学习利用进化的 scaffold。通过共享 replay buffer,系统实现了无额外 rollout 成本的联合优化,因为相同的轨迹既作为 harness 的诊断证据,也作为模型的训练信号。
实验
HarnessX 在五个多样化的基准测试和三个模型家族上进行了评估,以验证基于轨迹驱动的 harness 进化相对于静态基线的有效性。实验表明,进化收益对于较弱的模型最为明显,并且变体隔离策略对于在导致灾难性遗忘的全局进化中的异构任务集上保持稳定性至关重要。进一步分析表明,基础设施效率对准确性的影响比 evolver 架构更大,而与模型训练联合协同进化成功打破了性能上限,并验证了预测的失败模式是可检测的。
实验比较了 GAIA 基准测试上的全局进化策略与变体隔离消融,以及 ALFWorld 的结果。虽然全局策略未能提升 GAIA 的性能,但变体隔离方法成功产生了正向增益,并且效率更高。相比之下,全局策略在 ALFWorld 基准测试上实现了改进。变体隔离解决了 GAIA 基准测试上全局策略观察到的性能停滞。变体隔离方法在 token 消耗更低的情况下取得了比全局策略更好的结果。ALFWorld 基准测试在全局策略配置下展示了成功的性能提升。

该研究比较了变体隔离策略与单 harness 全局策略,以解决 harness 进化中的稳定性问题。结果表明,维护多个 harness 变体可防止全局方法中看到的性能下降,从而实现更高的最终准确率和稳定的轨迹。与全局基线相比,变体策略还以更高的 token 效率实现了这些改进。集成策略在最后一轮保持了其峰值性能,而全局策略的准确率大幅下降。变体隔离避免了导致单 harness 方法停滞或回归的灾难性遗忘。多变体方法比单 harness 基线消耗更少的 token,同时提供 superior 结果。

该研究评估了四阶段 AEGIS evolver 与单 agent 基线,以确定架构分解的价值。结果表明,两种方法都产生了可比的准确率,多阶段流水线实现了可忽略的改进。四阶段流水线的主要优势在于其效率,消耗明显更少的 token 来实现相似的性能结果。多阶段 evolver 实现了与单 agent 基线可比的准确率。四阶段架构的 token 消耗显著更低。性能提升似乎由共享基础设施驱动,而非 evolver 的内部结构。

该研究评估了其进化框架在多个基准测试和模型家族上的有效性。结果表明,进化后的 harness 通常导致性能优于初始静态配置。数据表明基线能力与改进幅度之间存在反比关系,其中较弱的模型从进化过程中受益最多。进化在几乎所有测试的模型和基准测试组合中都提高了性能。初始基线分数较低的模型始终表现出最大的性能提升。性能停滞发生在特定的异构任务设置中,表明单 harness 策略存在局限性。
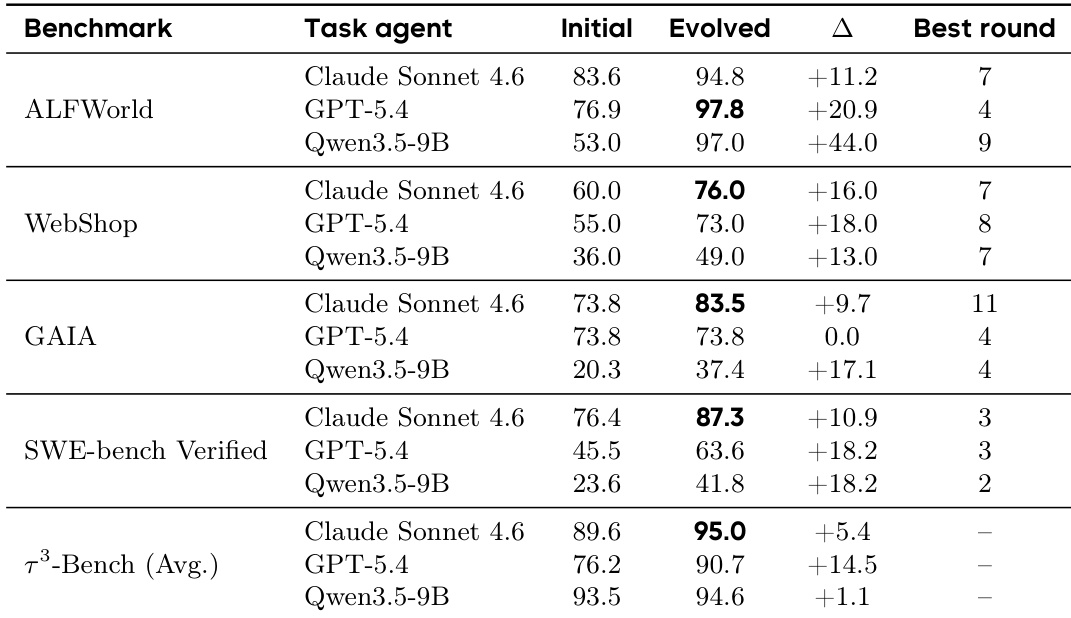
实验评估了 GAIA、ALFWorld 和各种模型家族上的全局和变体隔离策略以及四阶段 evolver。变体隔离防止了全局方法中观察到的性能停滞和灾难性遗忘,同时提高了 token 效率。四阶段流水线以较低的 token 消耗匹配单 agent 准确率,并且进化为具有较弱基线能力的模型带来了最大的收益。