Command Palette
Search for a command to run...
小型大语言模型:剪枝与从头训练
小型大语言模型:剪枝与从头训练
Yufeng Xu Taiming Lu Kunjun Li Jiachen Zhu Mingjie Sun Zhuang Liu
摘要
剪枝有望为构建高性能的小规模语言模型(Small Language Models)提供一条捷径。在本文中,我们通过六种涵盖深度、宽度及稀疏粒度的剪枝方法,在两种受控的“Token 匹配”设置下,对 Llama-3.1-8B 模型在 0.5–0.8 的剪枝率下进行剪枝,从而对该前景进行了考察。(1) 在相同的训练 Token 预算下,剪枝初始化(pruned initialization)的表现始终优于随机初始化(random initialization)。这表明父模型提供了一个强有力的初始起点;然而,随着训练 Token 预算的增加和剪枝率的提高,这一优势逐渐缩小,并在我们研究的最高剪枝率下几乎消失。(2) 当为从头训练(training from scratch)分配整个流程所消耗的全部 Token 预算时,在较细粒度下的剪枝仍保留优势,而较粗粒度的结构化剪枝则可与从头训练持平或被其超越。这表明,只有在细粒度下,父模型所转移的知识才是仅靠额外训练 Token 无法完全恢复的。综上所述,我们的研究结果给出了明确的建议:当拥有大型预训练模型且训练 Token 预算有限时,剪枝优于从头训练;而当训练预算不受限时,从头训练在粗粒度剪枝场景下具有竞争力,因此大型预训练父模型并非总是必需的。我们的代码已开源,请访问 github.com/zlab-princeton/pruning-vs-scratch。
一句话总结
在 Llama-3.1-8B 上比较六种涵盖深度、宽度和稀疏粒度的剪枝方法,剪枝比率为 0.5–0.8,并在两种 token 匹配的预算下进行实验。普林斯顿大学的研究人员揭示,当训练 token 有限时,剪枝初始化明显优于随机初始化,但随着预算增加和剪枝比率上升,这一优势逐渐缩小,在最高比率下几乎消失;当从头训练获得完整流程预算时,更细粒度仍能受益,而较粗的结构化剪枝则被持平或超越,由此提供了一个清晰的指导:仅在训练 token 有限时,才必需较大的父模型。
核心贡献
- 在 Llama-3.1-8B 上,比较六种涵盖深度、宽度和稀疏粒度的剪枝方法,剪枝比率 0.5–0.8,并在两种 token 匹配的再训练条件下进行评估。
- 在相同的再训练 token 预算下,剪枝模型始终优于随机初始化模型,尽管随着 token 预算增加和剪枝比率升高,这一优势缩小,在比率 0.8 时几乎消失。
- 当从头训练获得完整的流程 token 预算时,细粒度稀疏剪枝仍能提供收益,而较粗的结构化剪枝可被持平或超越。因此,在训练 token 有限时推荐剪枝,而当 token 充足时,对于粗粒度剪枝,从头训练具备竞争力。
引言
随着大语言模型规模增长,剪枝对于降低推理成本变得至关重要,但先前的工作很少研究在 token 有限预算下剪枝粒度和再训练数据如何相互作用。作者通过在一个持续预训练框架中系统评估六种涵盖深度、宽度和稀疏粒度的剪枝方法,填补了这一空白,揭示了压缩率、精度保持和数据效率之间微妙的权衡。
实验
这项工作将剪枝视为一种初始化策略,并在两种 token 匹配的设置下将其与从头训练进行比较,使用 Llama-3.1-8B 作为父模型,并采用六种涵盖结构化和稀疏粒度的剪枝方法。在相等的训练 token 预算下,剪枝初始化始终优于随机初始化,但随着剪枝比率升高,这一优势缩小,在最激进的压缩下几乎消失。当从头训练获得整个剪枝流程的完整 token 预算时,它能赶上粗结构化剪枝,但细粒度稀疏剪枝仍保持领先,表明父模型知识可传递出额外的训练 token 无法单独恢复的收益。
作者评估了 Minitron 深度剪枝初始化与不同再训练 token 预算下的从头训练的对比。结果表明,与随机初始化相比,剪枝初始化始终带来更低的损失和困惑度,以及更高的下游准确率。然而,随着再训练 token 预算增加,这一性能优势逐渐减少。在所有评估的 token 预算下,剪枝初始化始终优于随机初始化。剪枝模型与从头训练模型之间的性能差距随着再训练 token 预算的增加而缩小。从发布的模型检查点初始化与使用自定义预训练检查点性能相当或略优。
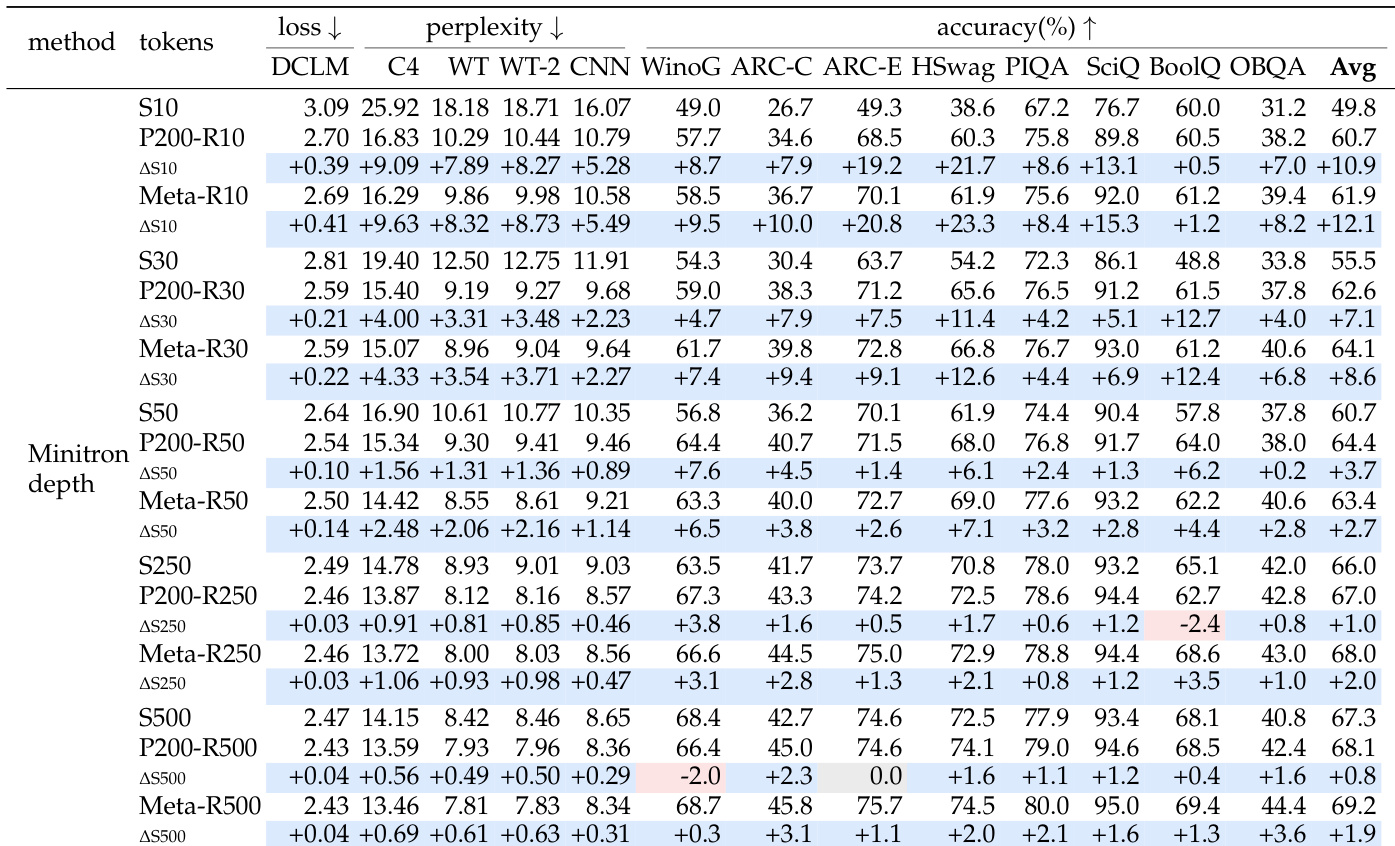
作者在相等训练 token 预算和相等总 token 预算下,比较剪枝初始化与从头训练。结果显示,当训练 token 预算相等时,剪枝初始化始终优于随机初始化。然而,当从头模型使用剪枝流程的完整 token 预算进行训练时,它与结构化剪枝方法变得有竞争力,而更细的稀疏剪枝方法仍保持优势。在相等训练 token 预算下,剪枝初始化在所有评估方法中始终达到更低的困惑度和更高的平均准确率。当给予完整的 token 预算时,从头训练变得与较粗的结构化剪枝方法有竞争力或超越这些方法,有效缩小了性能差距。与粗结构化方法不同,更细粒度的稀疏剪枝即使在总 token 预算匹配时仍保持相对于从头训练的准确率优势。
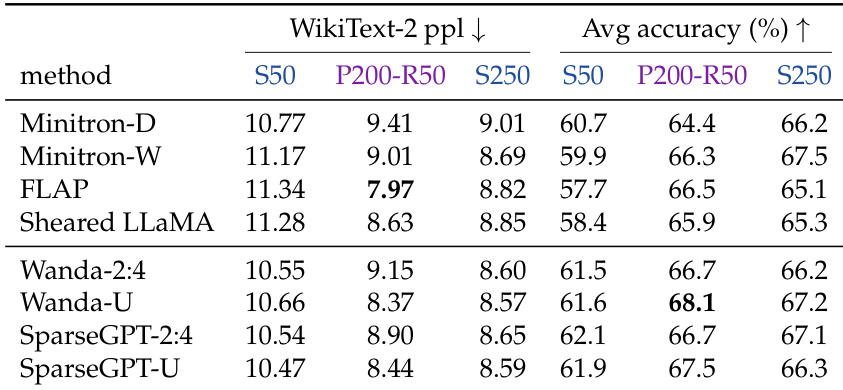
作者在各种剪枝方法和粒度下,比较了相等训练 token 预算和相等总 token 预算下的剪枝初始化与从头训练。结果显示,当训练 token 预算相等时,剪枝初始化始终优于随机初始化,但当总 token 预算匹配时,对于较粗粒度,这一优势减弱。更细粒度的稀疏剪枝方法即使在从头模型使用剪枝流程的完整 token 预算训练时,仍保有对从头训练的性能优势。在相等训练 token 预算下,剪枝初始化在所有评估方法中始终获得更低的困惑度和更高的下游准确率。当给予剪枝流程的完整 token 预算时,从头训练持平或超越较粗的结构化剪枝方法,但难以赶上更细的稀疏剪枝方法。与较粗的结构化方法相比,更细的剪枝粒度提供了更强的初始化优势,并能更好地保留父模型能力。
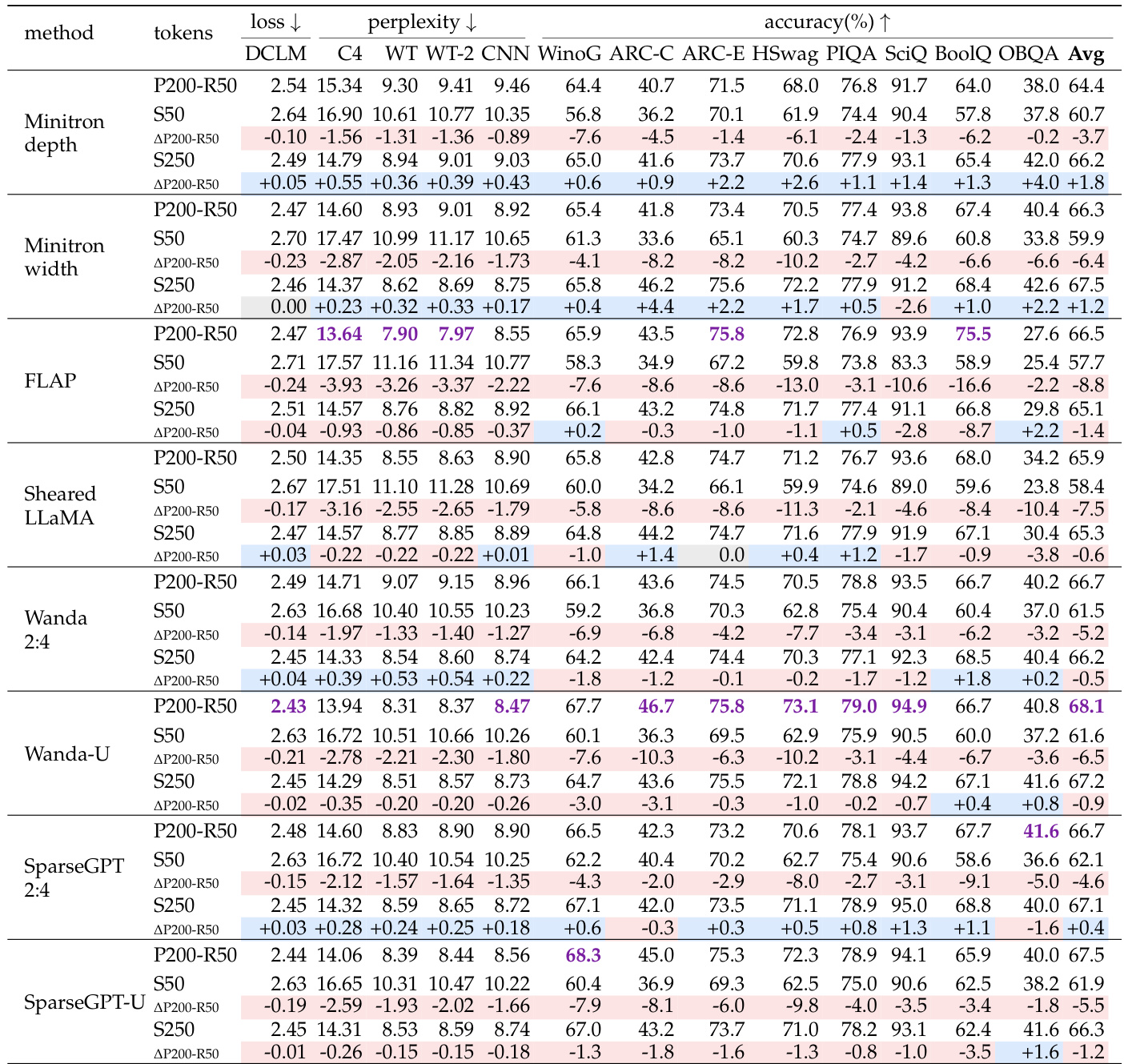
作者评估 FLAP 剪枝方法作为初始化策略与不同再训练 token 预算下的从头训练的对比。结果表明,使用剪枝模型初始化在困惑度和下游准确率方面始终优于随机初始化。然而,剪枝的性能优势随着再训练 token 预算增加而减弱,表明额外的训练数据有助于缩小两种方法之间的差距。在所有评估的 token 预算下,剪枝初始化始终实现更低的困惑度和更高的平均准确率。剪枝相对于从头训练的性能优势随着再训练 token 数量的增加而缩小。从公开发布的大模型检查点初始化比作者自定义的预训练流程结果略优。
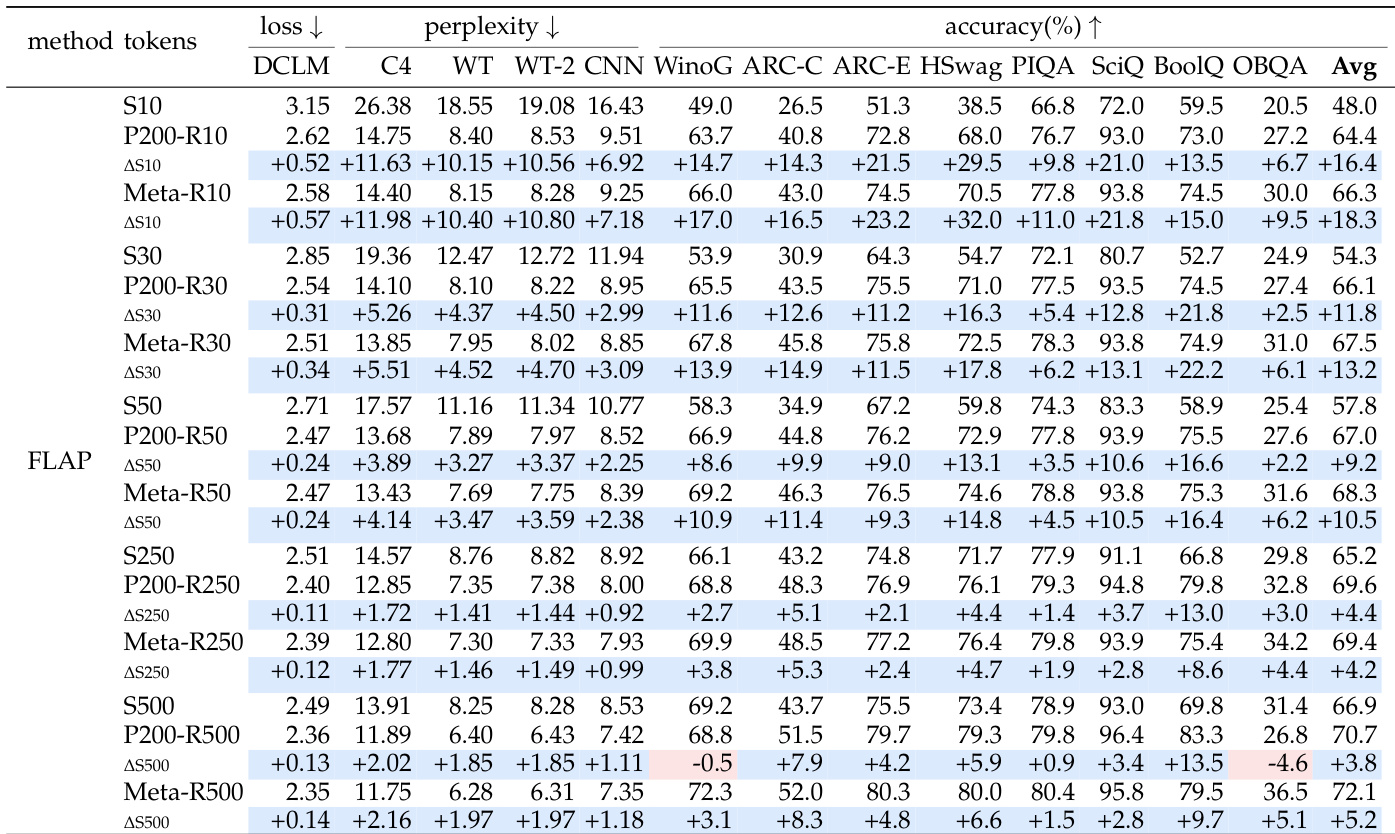
作者比较了剪枝大语言模型与从头训练,利用架构搜索在标准剪枝比率下定义目标模型配置。结果表明,在相等训练预算下,剪枝初始化始终优于随机初始化,相当于一条 token 高效的捷径。然而,这一优势随着压缩程度升高而减弱,虽然粗结构化剪枝可通过延长训练被持平,但细粒度稀疏剪枝仍保持优势。剪枝初始化提供了一个强大的起点,在相等训练 token 预算下优于随机初始化。剪枝的优势随着剪枝比率增加和目标模型变小而缩小。细粒度稀疏剪枝即使在从头模型使用剪枝流程的完整 token 预算训练时,也优于从头训练。
在多个将剪枝初始化与从头训练进行比较的实验设置中,剪枝在相等再训练 token 预算下始终取得更低的困惑度和更高的准确率,尽管其优势随着再训练 token 数量的增加或剪枝粒度变粗而减弱。当从头训练被给予剪枝流程的完整 token 预算时,它变得与较粗的结构化方法有竞争力或超越这些方法,而更细的稀疏剪枝方法保持明显的性能优势。利用公开发布的模型检查点进行初始化,其表现与自定义预训练检查点相当或略优。整体发现证实,剪枝能够传递有价值的父模型知识,且当细粒度稀疏剪枝和有限再训练数据时,这一收益最为显著。