Command Palette
Search for a command to run...
FastContext:训练面向 Coding Agents 的高效仓库探索器
FastContext:训练面向 Coding Agents 的高效仓库探索器
Shaoqiu Zhang Maoquan Wang Yuling Shi Yuhang Wang Xiaodong Gu Yongqiang Yao Rao Fu Shengyu Fu
摘要
大型语言模型(LLM)编码 agents 在软件工程任务上取得了显著成果,然而仓库探索仍然是一个主要瓶颈:定位相关代码会消耗大量的 token 预算,并用不相关的代码片段污染 agent 的上下文。在大多数 agents 中,同一模型同时负责仓库探索与任务求解,使得探索性读取与搜索操作残留在求解器的历史记录中。我们提出了 FastContext,一种专用的探索子 agent,旨在将仓库探索与任务求解相分离。在按需调用时,FastContext 会发起并行工具调用,并返回简洁的文件路径与行范围作为聚焦上下文。FastContext 由参数规模介于 4B--30B 之间的专用探索模型驱动。我们利用强参考模型的轨迹对其进行初始化,并通过基于任务的奖励对其进行优化,以支持广泛的初始轮次搜索、多轮证据收集以及精确的引用生成。在 SWE-bench Multilingual、SWE-bench Pro 和 SWE-QA 基准上,将 FastContext 集成至 Mini-SWE-Agent 中可将端到端解决率最高提升 5.5%,同时将编码 agent 的 token 消耗最高降低 60%,且仅带来微小的额外开销。这些结果表明,仓库探索可与任务求解相分离,并由专用模型高效处理。代码与数据:https://github.com/microsoft/fastcontext
一句话总结
FastContext 是一个专为 coding agent 设计的探索子 agent,通过使用经任务驱动奖励训练的 4B–30B 参数专用模型发出并行工具调用并返回简洁的文件路径和行范围,将仓库探索与问题求解解耦,在 SWE-bench Multilingual、SWE-bench Pro 和 SWE-QA 上将端到端解决率提升最高 5.5%,token 消耗降低最高 60%。
核心贡献
- 提出 FastContext 作为专用探索子 agent,通过发出并行工具调用并返回简洁的文件路径和行范围作为聚焦上下文,将仓库探索与求解 LLM 解耦。
- 专用探索模型(4B–30B 参数)从强参考模型轨迹引导启动,并通过任务驱动奖励进行精炼,用于广泛的首次搜索、多轮证据收集和精确引用生成。
- 将 FastContext 集成到 Mini-SWE-Agent 中,在 SWE-bench Multilingual、SWE-bench Pro 和 SWE-QA 上将解决率提升最高 5.5%,并将 coding agent 的 token 消耗降低最高 60%,证明仓库探索可以有效地被分离并由专用模型处理。
引言
能够自主导航和修改大型代码库的 coding agent 是软件工程中快速发展的前沿领域,像 SWE-bench 这样的基准要求在生成任何修复或答案之前进行仓库规模的探索。然而,现有系统要么将探索纠缠在单体 agent 轨迹中,要么依赖昂贵的图构建或专有的子 agent 设计,要么产生过于宽泛的上下文,给主求解器带来噪声和高昂的 token 成本。作者引入 FastContext,一个轻量级、可训练的探索子 agent,将仓库搜索与主 agent 解耦。FastContext 使用并行只读工具调用返回简洁的文件路径和行范围,并通过监督微调和任务驱动强化学习在 4B 到 30B 参数模型上进行训练。当集成到 Mini-SWE-Agent 中时,它在多语言和专业级基准上将端到端解决率提升最高 5.5%,同时将主模型 token 使用量降低最高 60%。
数据集
作者从公开的软件工程任务和仓库中构建了两个训练语料库,外加一个固定的评估子集。
-
监督微调(SFT)语料库:从 Sonnet 4.6 探索轨迹生成的 2,954 个示例,使用 READ、GLOB 和 GREP 工具模式序列化。包含三个子集:
- parallel_toolcalls(990 个示例):首次工具调用同时发出,覆盖路径模式、符号和入口点等多种信号。
- multiturn_traj(983 个示例):完整的探索轨迹,筛选保留包含最终 assistant 消息且至少有一次 assistant–工具交互的轨迹;仅保留角色、内容、工具调用参数和原始工具观察。
- linerange(981 个示例):最终引用生成,模型学习在给定查询和检索到的文件内容的情况下,输出一个包含文件路径和行范围的窄
<final_answer>块。 过滤确保工具调用使用运行时工具集,最终答案符合所需的文件-行格式。在构建提示之前,记录每个任务工作区的顶级目录列表,并与工作区路径一起插入到探索器系统提示中。
-
强化学习(RL)语料库:400 个提示,涵盖 395 个仓库。每个示例包含一个两消息输入(探索器系统指令和用户查询)、带有工作区和实例 ID 的元数据,以及从参考补丁派生的标签字段。标签通过解析补丁构建,跳过新创建的文件(旧侧块从第 0 行开始),并将剩余块转换为目标文件路径和旧文件行范围。标签平均每个提示有 11.07 个引用范围(最小 1,最大 68),仅用于奖励计算,不作为强制教师续写。
-
评估子集:固定的 200 实例 SWE-bench Pro 子集,以 JSONL 文件发布。
论文如何使用数据:SFT 语料库用于监督微调以初始化探索器策略。RL 语料库随后用于任务驱动策略精炼,其中 rollout 根据补丁派生的标签进行评分。在 RL 期间,探索器使用相同的 READ、GLOB 和 GREP 工具运行;工具观察被追加到对话中,并允许多个并发工具调用。Rollout 限制为 8 个模型回合,最后一条指令是停止探索并返回最佳答案。对于 4B 模型,每个提示采样 16 条轨迹,温度 1.0,rollout 上下文长度 65,536 token,SGLang 上下文长度 128K。
方法
作者提出 FastContext,一个专用的探索子 agent,旨在将仓库探索与主 agent 的问题求解过程分离。在标准 coding agent 中,同一模型同时处理探索和求解,这往往导致求解器上下文被不相关的片段污染,并消耗过多 token。FastContext 通过充当轻量级委托机制来解决这一问题。当主 coding agent 需要仓库上下文时,它向 FastContext 发出上下文查询。子 agent 使用只读工具探索目标仓库,并返回紧凑的文件-行证据,使主 agent 能够在不保留冗长探索历史的情况下继续编辑和测试。
如下图所示:
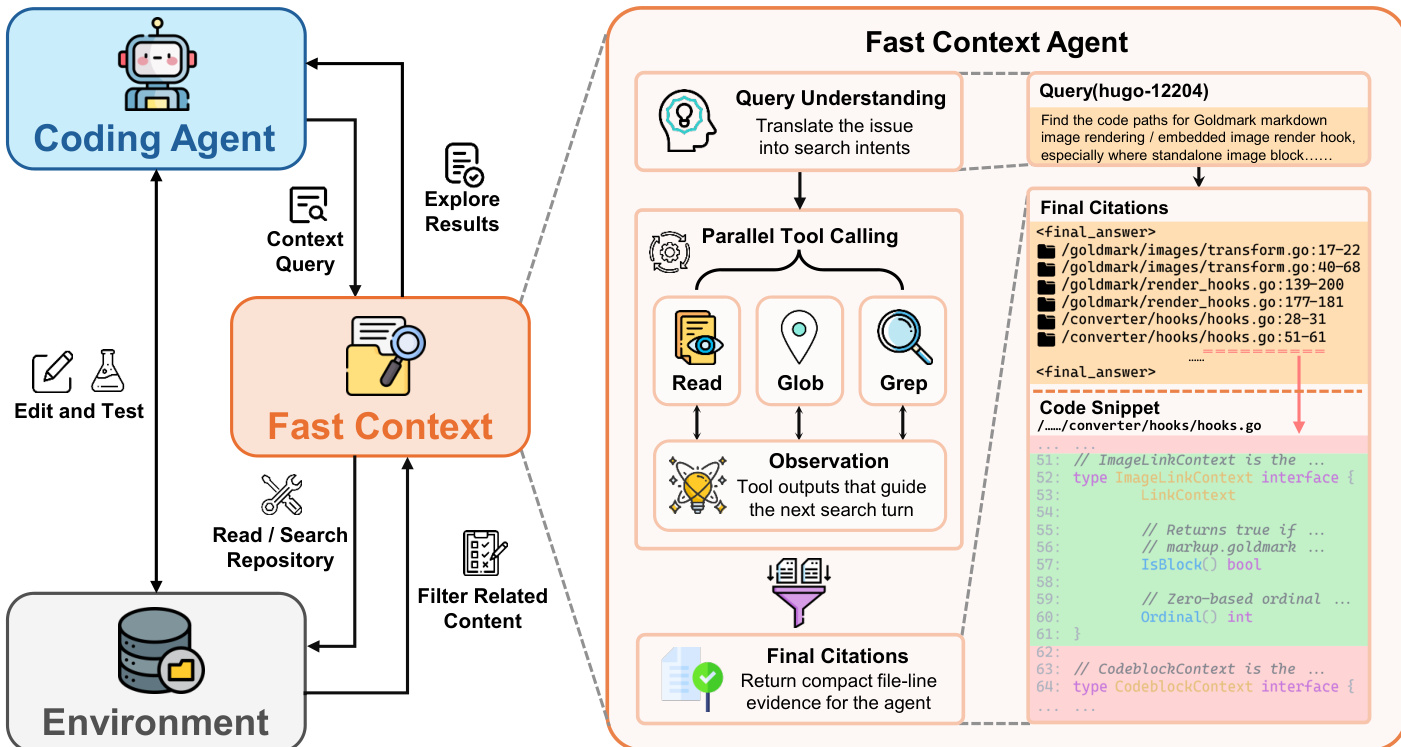
FastContext 的内部架构围绕查询理解、并行工具调用和证据综合构建。子 agent 有意仅暴露三个语言无关的工具:READ 用于检索带行号的文件内容,GLOB 用于路径发现,GREP 用于基于正则表达式的文本搜索。在每一回合,探索器可以发出一个或多个工具调用,或停止并返回最终证据列表。关键的是,同一回合内的多个工具调用是并行执行的,使探索器能够在综合观察之前高效地覆盖互补假设。输出契约是一个紧凑的最终答案块,包含文件路径和行范围,可选地后跟简短的相关性说明。这种格式确保探索器的输出可直接作为主 agent 的聚焦上下文使用。
为训练专用探索模型,作者采用两阶段训练方案。第一阶段是监督微调(SFT),以初始化探索行为。作者使用 Qwen 系列骨干模型,具体为 Qwen3-4B-Instruct 和 Qwen3-Coder-30B-A3B,使用 Slime/Megatron 堆栈训练 3 个 epoch,仅对 assistant token 进行损失掩码。
由于 SFT 模仿并不直接优化最终引用是否覆盖解决问题所需的代码位置,作者通过任务驱动强化学习(RL)对探索器进行精炼。他们从带有参考补丁的问题求解任务中构建数据集,将补丁解析为目标文件-行范围作为探索标签。模型作为实际的 FastContext 子 agent 进行 rollout,在有限回合内与工具交互。奖励函数是确定性的,并与输出契约绑定,结合了补丁派生的定位准确度、结构化并行探索的奖励以及无效输出的惩罚。令 Gf 和 Gl 表示由参考补丁诱导的目标文件和行集合,令 Pf 和 Pl 表示从模型最终引用中解析出的相应集合。标量奖励定义为:
R=task outcomeF1(Pf,Gf)+F1(Pl,Gl)+parallelrparallel−penaltyrformat.这里,任务结果项表示路径标准化后的文件级和行级 F1 分数之和。作者从 SFT 检查点初始化 RL 阶段,并使用 GRPO 优化策略,每个提示采样多条轨迹,以使模型与返回最小引用集、突出最相关代码区域的实际目标对齐。
实验
评估涵盖端到端 agent 基准(SWE-bench Multilingual、SWE-bench Pro 和 SWE-QA),使用 Mini-SWE-Agent 和前沿主模型,以及在 SWE-bench Verified 上的独立补丁定位测试。FastContext 是一个只读探索子 agent,将仓库搜索与主求解器解耦,返回紧凑的文件-行引用;使用 SFT 和 RL 训练的 4B–30B 探索器与直接求解和同模型探索进行比较。结果表明,FastContext 持续提高解决准确率,同时将主 agent token 消耗降低最高 60%,且经 RL 训练的 4B 探索器通常优于更大的 SFT 变体,并将证据缩小到补丁相关代码区域。独立定位证实,训练后的探索器能更精确地恢复编辑位置,验证了任务驱动 RL 可以产生小型、高效的探索子 agent。
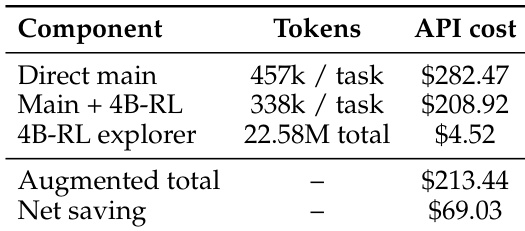
作者对在 SWE-bench Multilingual 基准上运行的主 agent 进行了 token 和成本审计,以评估探索子 agent 的开销。结果表明,集成紧凑探索器显著降低了主 agent 的 token 消耗和 API 成本。即使计入子 agent 自身的 token 使用量和估计 API 成本,增强系统相比直接求解也实现了可观的净节省。与直接求解相比,当使用紧凑探索器增强时,主 agent 每个任务的 token 使用量显著下降。在增强设置中,主 agent 的 API 成本大幅降低,超过了探索器子 agent 产生的微小成本。总系统成本仍低于直接求解基线,表明探索子 agent 在提供效率增益的同时增加了可忽略不计的开销。
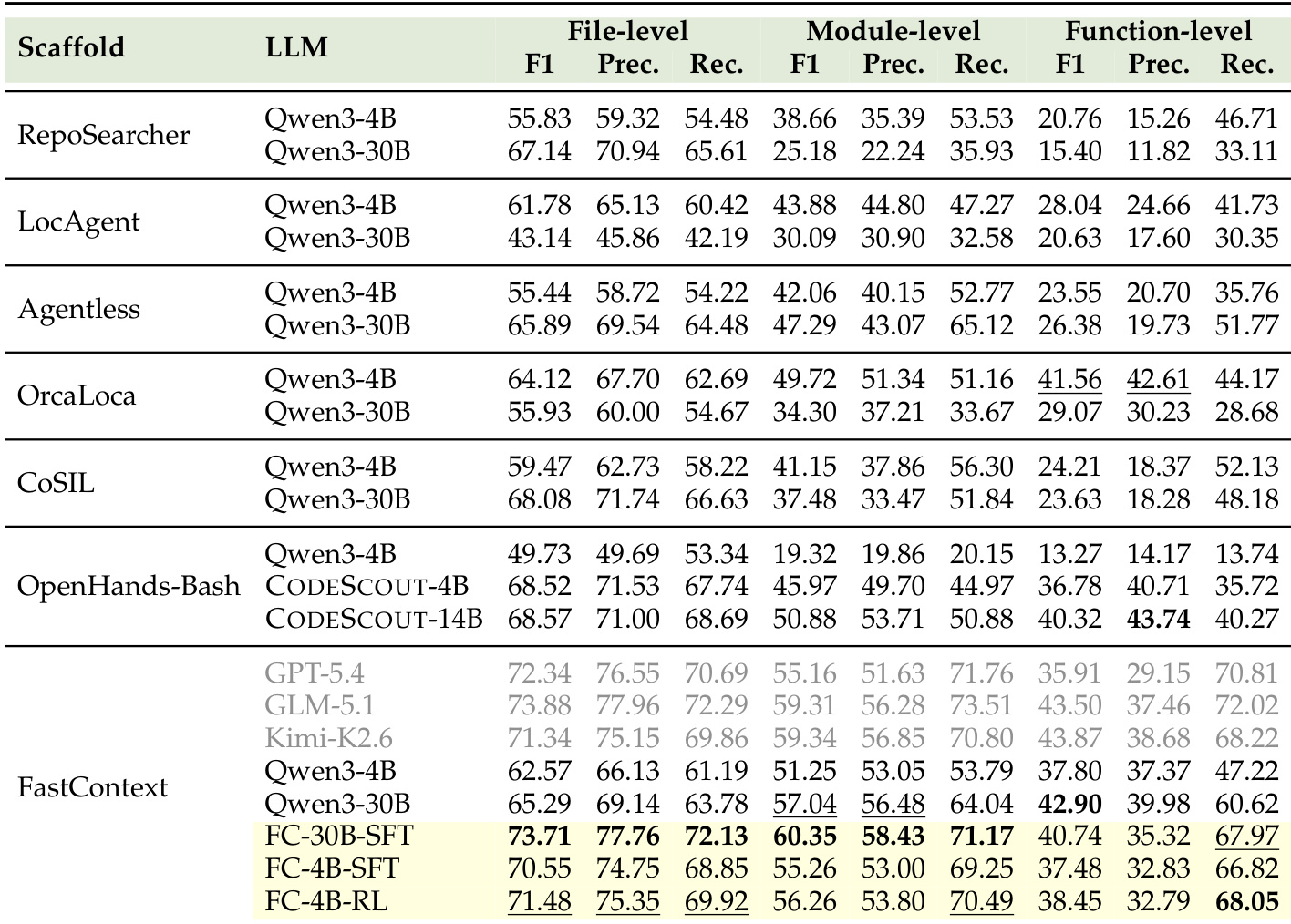
作者通过衡量 FastContext 恢复参考补丁所涉及代码位置的准确度来评估其独立探索质量。结果表明,与其他定位框架相比,训练后的 FastContext 变体在文件和模块粒度上均达到最高性能。此外,应用监督微调和强化学习持续改进紧凑探索器,其中强化学习主要提升召回率。训练后的 FastContext 模型在文件和模块级别优于其他非前沿定位框架。经强化学习的紧凑 4B 探索器实现了与更大未训练模型相当的性能。强化学习主要通过提高召回率同时保持精确度来改进紧凑探索器。
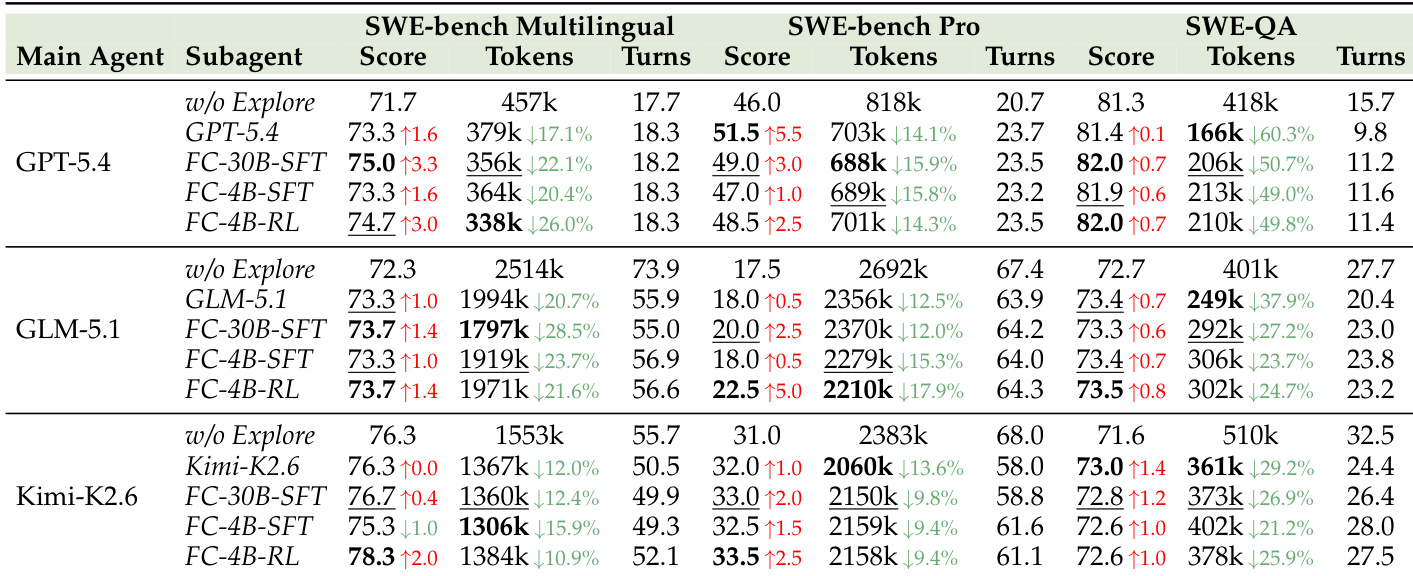
作者将 FastContext 作为探索子 agent 与多种主 coding agent 集成,在多个基准上进行评估。结果表明,与直接求解相比,集成训练后的 FastContext 探索器持续提高任务解决准确率,同时大幅降低主 agent 的 token 消耗和交互回合数。紧凑的强化学习变体通常匹配或超过更大模型和同模型探索的性能,证明任务驱动优化能够实现高效的仓库搜索。训练后的 FastContext 探索器在所有测试的主模型和基准上持续提高端到端准确率,并显著降低主 agent token 使用量。紧凑的强化学习探索器在成功率和 token 效率方面经常优于同模型探索和更大的监督微调变体。在复杂基准上 token 节省最为显著,子 agent 有效地将昂贵的读取和搜索操作从主求解器卸载。
作者通过 token 成本审计、独立定位准确率测试以及与多种 coding agent 在多个基准上的集成来评估 FastContext 作为探索子 agent。紧凑探索器大幅降低主 agent 的 token 消耗和 API 成本,即使在计入自身开销后仍产生净节省。经强化学习训练,它实现了高文件和模块级定位召回率,同时保持精确度,并在所有测试模型上持续提升端到端任务解决率。紧凑的 RL 变体通常匹配或超过更大模型和同模型探索,在复杂任务上 token 节省最为显著,因为它卸载了昂贵的搜索和读取操作。