Command Palette
Search for a command to run...
Orchestra-o1:全模态 Agent 编排
Orchestra-o1:全模态 Agent 编排
摘要
agent集群近期的成功已将基于大语言模型(LLM)的agents范式从单agent工作流转向多agents系统,凸显了agent编排对于任务分解与协作的重要性。然而,现有的编排框架仅限于有限的模态,难以泛化至异构模态共存并交互的更复杂场景。这一局限性在全模态场景中尤为突出,此类场景中的任务需要对文本、图像、音频和视频等多样化输入进行统一理解与协调。在本研究中,我们提出了Orchestra-o1,这是一种旨在支持跨多模态高效agents协作的全模态agents编排框架。Orchestra-o1引入了一种统一的编排机制,能够实现模态感知的任务分解、在线子agent专业化以及并行子任务执行。这种可扩展的设计使agents系统能够有效应对涉及异构信息源的复杂现实任务,在OmniGAIA基准测试上准确率较次优方法高出10.3%。此外,我们提出了决策对齐的组相对策略优化(DA-GRPO),这是一种用于训练Orchestra-o1-8B的高效agents强化学习方法,其在所有现有开源全模态agents中均达到了最先进的性能。
一句话总结
Orchestra-o1 是一个全模态 Agent 编排框架,采用统一的机制实现模态感知任务分解、在线子 Agent 专业化以及并行子任务执行。其经过 DA-GRPO 训练的 Orchestra-o1-8B 变体在现有开源全模态 Agent 中取得了最先进的性能,在 OmniGAIA 基准测试中准确率超越第二名 10.3%。
核心贡献
- 本文提出 Orchestra-o1,一个全模态 agent 编排框架,统一协调文本、图像、音频和视频输入。该系统采用模块化架构,具备模态感知任务分解、在线子 agent 专业化及并行子任务执行能力,以管理复杂异构信息源。
- 论文提出决策对齐的组相对策略优化(DA-GRPO),一种专为高效 agentic 训练设计的强化学习算法。该方法通过对齐决策级编排来训练 Orchestra-o1-8B 变体,同时在优化过程中保持固定的子 agent 后端不变。
- 在 OmniGAIA 基准测试中的评估表明,该框架在提供更快推理速度和更高成本效益的同时,准确率超越第二名 10.3%。该训练模型在性能上也超越了所有现有的开源全模态 agent。
引言
从单 agent 系统向多 agent 集群的转变,使得编排对于分解和协调复杂任务变得至关重要,尤其是在现实应用要求对文本、图像、音频和视频进行统一处理的背景下。然而,现有框架仍局限于单一模态,依赖僵化的线性工作流,难以有效协调异构输入或利用全面的工具集。作者通过引入 Orchestra-o1 填补了这些空白。Orchestra-o1 是一个全模态编排框架,将高层推理与专门的感知和行动解耦。其设计实现了模态感知任务分解、动态子 agent 专业化以及统一工具生态内的并行执行。为进一步提升开源能力,作者还开发了 DA-GRPO,这是一种强化学习算法,通过将步骤级编排决策与高质量参考轨迹对齐,从而实现可扩展全模态 agent 系统的高效训练。
数据集

-
数据集构成与来源: 作者使用公共多模态基准测试(具体为 FineVideo、LongVideoBench 和 COCO 2017)作为数据集基础。每个初始种子包含一个问题、一个多模态输入(图像、音频或视频)、一个真实答案以及所需的工具集。
-
子集规模与过滤规则: 从 300 个种子样本开始,流水线使用分布在简单、中等和困难三个难度级别的五种转换策略,生成约 1,500 个候选重写结果。候选结果需经过五步验证流程,包括强制覆盖锚点事实、限制词法相似度不超过 0.85、执行模态绕过测试、在 Python 沙箱中验证数值答案,以及使用 LLM 裁判进行事实一致性和重复性检查。最终得到约 1,200 个经过验证的精选样本。
-
数据使用与训练集成: 作者使用该数据集对源自 Qwen3-8B 的 Orchestra-o1-8B 进行后训练。数据并未被视为静态配对,而是将完整的编排轨迹分解为决策级样本。每个样本在专家决策前重构主 agent 状态,并将其与参考编排动作配对,为委托、工具路由、后端选择和并行调度提供密集监督。
-
处理与元数据构建: 在整个流水线中,作者保持原始模态文件不变以保留感知基础。他们提取特定模态的锚点事实,作为重写过程中不可绕过的约束条件。所有语言模型组件(包括锚点提取器、问题重写器和验证裁判)均采用 Claude-Opus-4.6 实现,以确保质量一致性和事实对齐。
方法
作者将全模态 agent 编排形式化为针对异构输入的多轮决策问题。给定任务实例 x=(q,M),其中 q 表示自然语言问题,M 代表图像、音频和视频等辅助模态输入集合,目标是生成一个最大化任务奖励的简洁最终答案。传统方法通常依赖单一的原生全模态 agent 在内部处理所有输入。
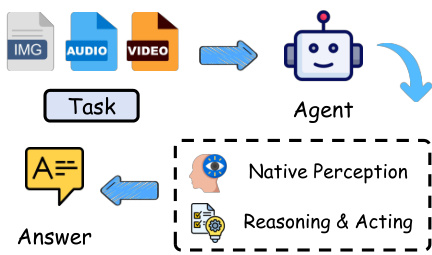
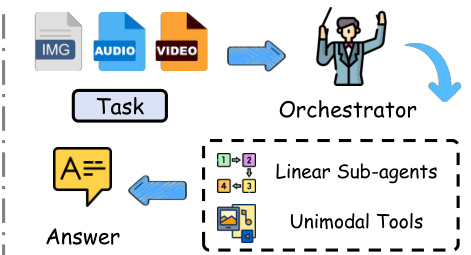
如上图所示,这种原生设计将多种模态压缩为单一的内部表示,通常会导致信息瓶颈和高昂的计算成本。为克服这些局限,作者探索了替代的编排范式。线性编排器将任务分解为由单模态工具处理的顺序子任务,但无法利用并发优势。
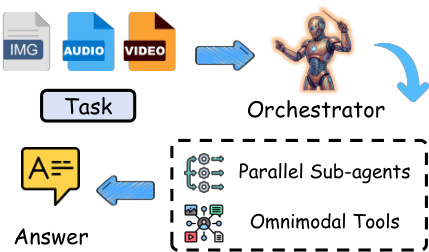
相反,并行编排器尝试使用全模态工具同时执行多个子任务,但缺乏复杂推理所需的精细依赖跟踪能力。
完整架构请参考下方框架图。该框架实现了一种分层策略,将复杂问题解决分解为高层编排与底层专门执行。主 agent 扮演编排器角色,而非直接操作每种模态。在每个编排轮次 t,它观察由问题、模态输入、累积上下文、结构化子任务历史、可用子 agent 模型以及工具生态定义的状态。系统状态形式化如下:
st=(q,M,ct,Ht,B,T),其中 ct 为累积上下文,Ht 为结构化子任务历史,B 为可用子 agent 模型集合,T 为子 agent 可用工具集合。主 agent 从两种动作类型(委托或完成)中输出结构化决策 yt。若选择完成动作,主 agent 终止轨迹并返回最终答案。若选择委托动作,则生成一批子任务。
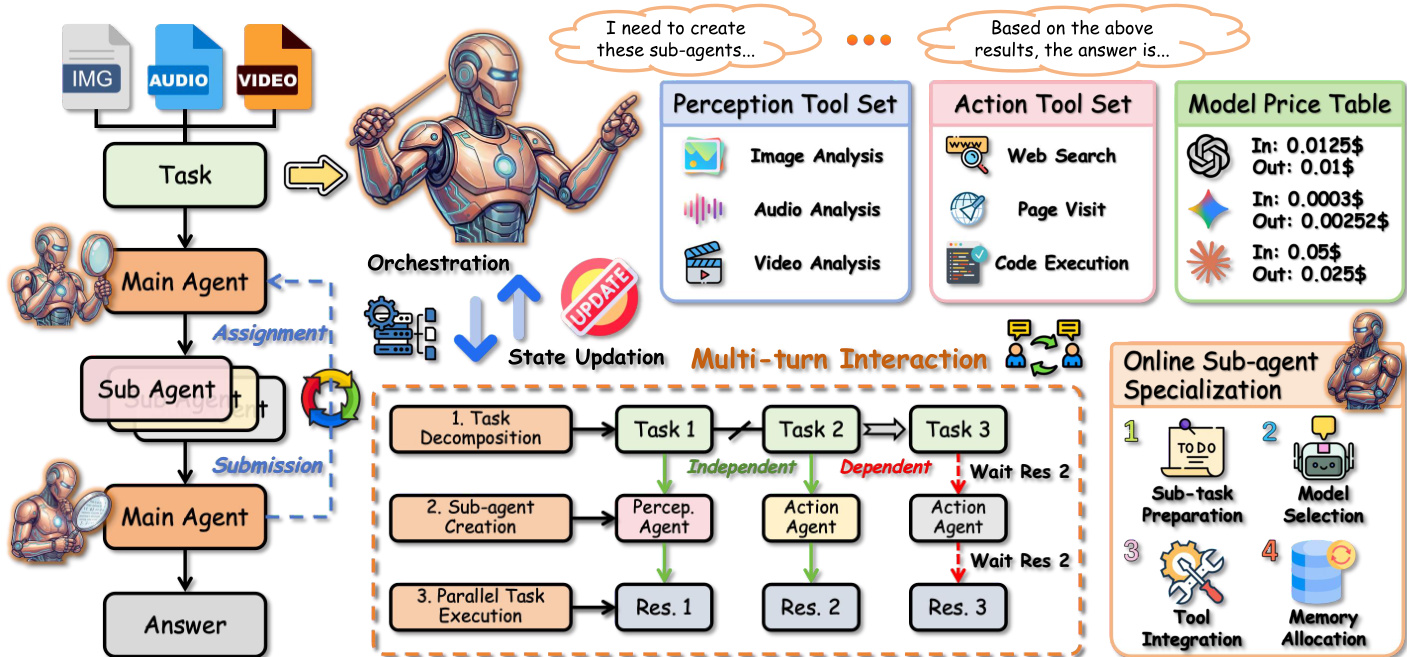
该框架集成了灵活的 agent 后端与统一的全模态工具生态。每个后端由技能向量和成本延迟特征表示。主 agent 为每个候选子任务预测需求向量,并通过最大化成本感知匹配分数来选择最优后端。同样,工具分配被形式化为需求匹配问题,系统选择工具子集以在最小化冗余的同时最大化稀疏覆盖。感知工具集包含图像、音频和视频分析能力,行动工具集则包含网页搜索、页面访问和代码执行工具。
在每一轮中,主 agent 在未解决的子目标上构建隐式依赖图。每个节点关联一个模态掩码和一个工具掩码。仅当所有前驱节点完成后,子目标才可执行。主 agent 在依赖和预算约束下从就绪集中选择并行批次。对于每个选中的节点,系统通过分配特定后端和工具子集将具体子任务实例化。随后,每个委托的子任务由独立的 ReAct 风格子 agent 执行。由于并行批次中的子任务在当前状态下条件独立且不共享可变环境状态,其执行过程相互独立,从而在延迟上相比顺序执行具有理论优势。
每次委托轮次结束后,系统会更新存储所有子 agent 返回证据的结构化记忆。为将主 agent 上下文保持在 token 预算内,Orchestra-o1 通过求解信息相关性优化问题来构建压缩上下文。当证据充分性得分超过预设阈值时,主 agent 终止流程。否则,它根据新证据细化依赖图并继续委托。这一闭环决策过程将高层规划与专门的感知和行动执行分离,确保了模块化与可扩展性。
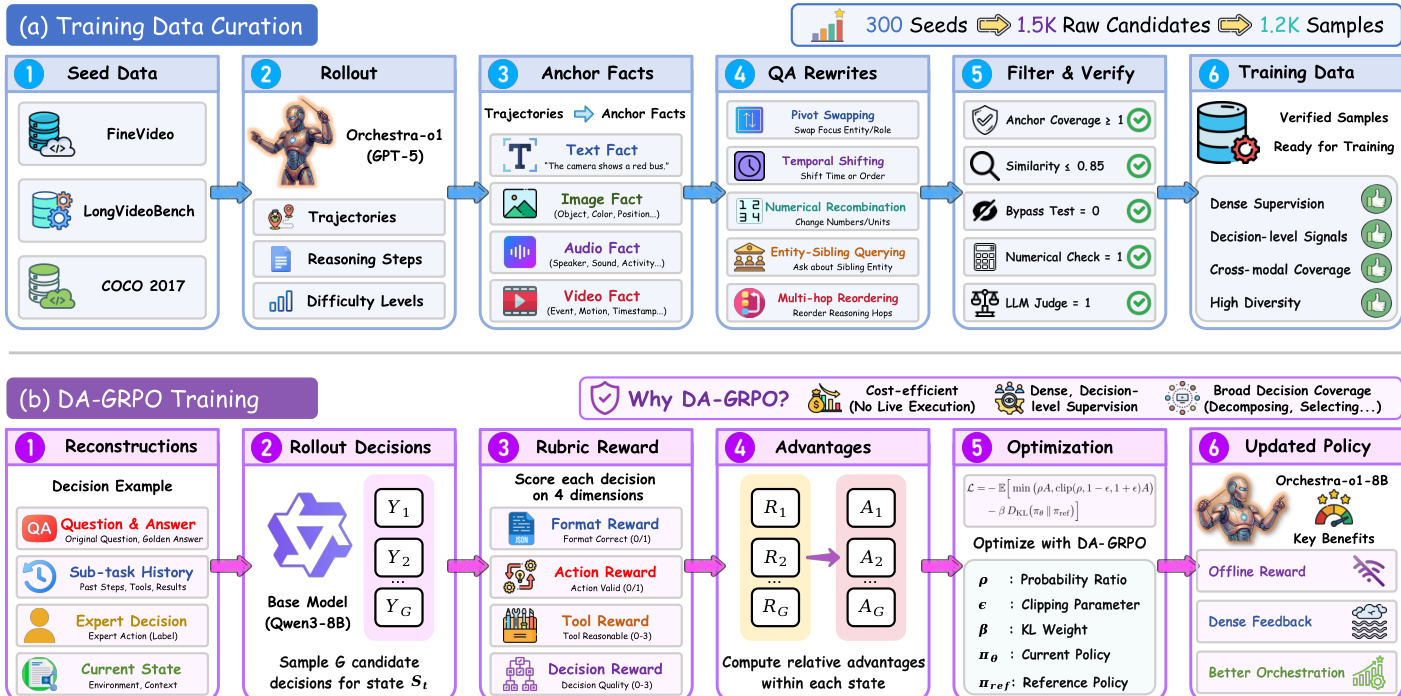
为训练出具备有效编排能力的开源主 agent,作者提出了一种以决策对齐的组相对策略优化(DA-GRPO)为核心的训练方案。标准的组相对策略优化在多 agent 系统中面临最终答案奖励稀疏且高昂的问题。DA-GRPO 则利用包含格式正确性、动作有效性、工具合理性及整体决策质量评估的评分奖励,直接在当前编排状态下评估每个采样的主 agent 决策。
针对每个提示词,策略会采样一组候选决策。每个决策由多维奖励函数评分,该函数将二值化的格式与动作奖励同分级化的工具与决策奖励相结合。一个轻量级奖励模型通过单次调用评估这些维度,以专家轨迹为参考,同时对合理但不同的分解方案给予奖励。基于组奖励,DA-GRPO 通过在组内进行归一化来计算每个采样决策的相对优势。随后,策略通过裁剪策略梯度目标和针对参考模型的 KL 正则化进行优化。该方法在训练期间避免了重复执行昂贵的子 agent 轨迹,同时为主 agent 的核心职责提供密集反馈。由此产生的开源模型 Orchestra-o1-8B 展现出显著优势,它通过系统化且高效的方式学习协调专门 agent、工具和证据源,大幅超越了强大的开源全模态基线。
实验
在 OmniGAIA 基准测试上的评估表明,实验将 Orchestra-o1 与原生、专有及基于编排的基线在不同多模态类别和难度级别上进行了对比。主要结果验证了显式编排能显著提升多步推理和跨领域准确率,并通过并行任务执行提高成本效益。消融实验进一步证实,这些性能提升源于结构化分解框架和针对性训练流水线,而非仅靠底层模型容量。最终,研究结果表明,战略性编排结合专门的强化学习,使紧凑型与先进模型均能在复杂全模态任务中实现稳健高效的性能。
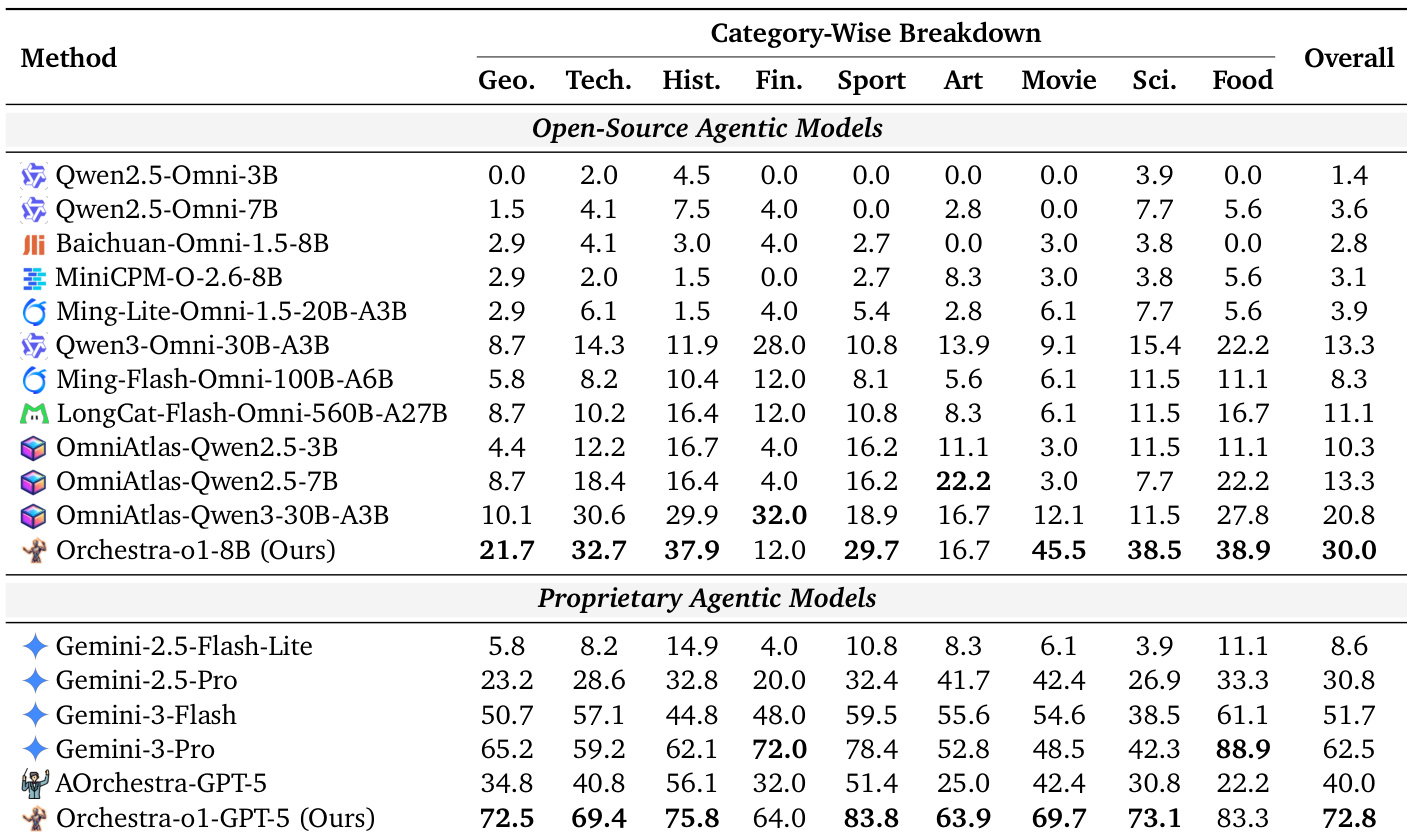
作者在 OmniGAIA 基准测试上评估了提出的 Orchestra-o1 框架,并将其与一系列开源和专有 agent 模型进行对比。结果表明,Orchestra-o1 的开源和专有变体均在各自组别中取得了最高的整体准确率,在多种主题类别上持续超越 Gemini-3-Pro 和 OmniAtlas 等强基线。Orchestra-o1-GPT-5 在专有模型中整体准确率最高,超越 Gemini-3-Pro。开源 Orchestra-o1-8B 模型领跑开源组别,超越 OmniAtlas-Qwen-3-30B-A3B。该方法在几乎所有按类别细分的指标上均表现出一致的提升,显示出广泛的适用性。
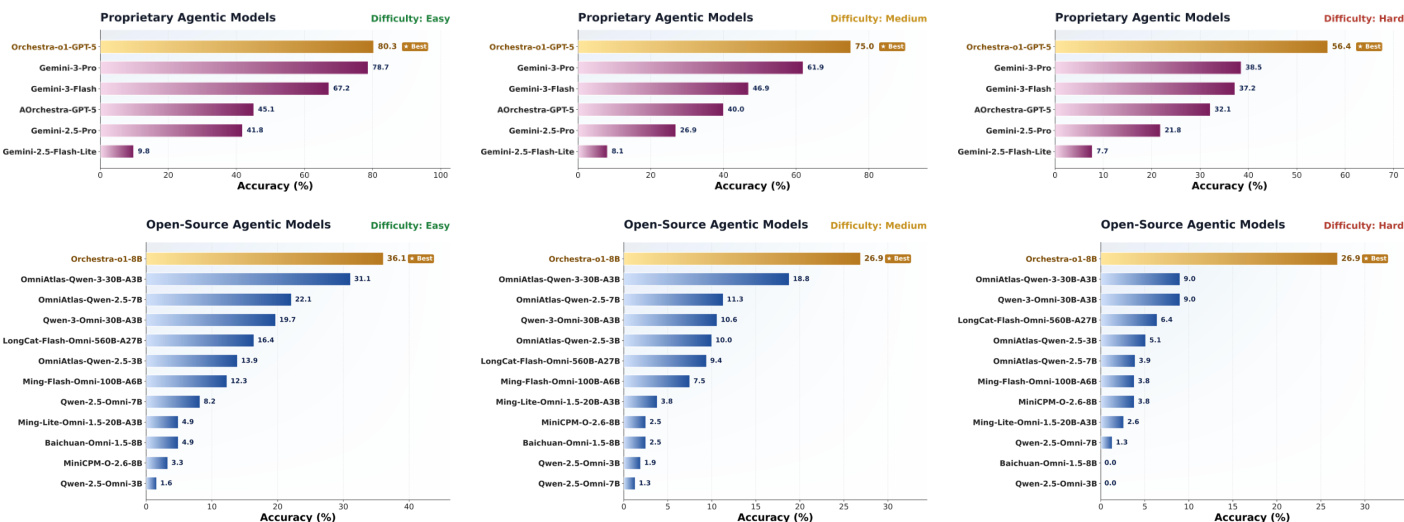
作者在 OmniGAIA 基准测试上评估了 agent 模型,将提出的 Orchestra-o1 框架与专有和开源基线进行对比。结果表明,Orchestra-o1 在两种模型类别的简单、中等和困难难度级别上均稳定保持最高准确率。Orchestra-o1-GPT-5 在专有模型中表现最佳,显著超越 Gemini-3-Pro 和 AOrchestra-GPT-5。开源 Orchestra-o1-8B 变体领跑开源类别,在所有难度级别上均超越最强基线 OmniAtlas-Qwen-3-30B-A3B。尽管所有模型的性能随难度增加而下降,但 Orchestra-o1 仍保持显著领先优势,且在更困难的任务上与其他竞争对手的性能差距更为明显。
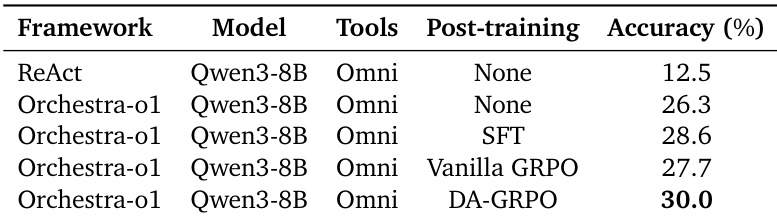
作者在 OmniGAIA 基准测试上评估 Qwen3-8B 模型,以考察 Orchestra-o1 框架及多种后训练技术的影响。结果表明,编排框架为标准基线带来了显著的性能提升,特定的后训练方法进一步增强了这些能力,其中 DA-GRPO 取得了最佳结果。与未进行任何后训练的标准 ReAct 基线相比,Orchestra-o1 框架显著提升了准确率。当应用于编排框架时,监督微调(SFT)的效果优于基础 GRPO。DA-GRPO 方法达到了最高准确率,展现出优于其他后训练策略的性能。
在 OmniGAIA 基准测试上的评估表明,Orchestra-o1 框架在多种主题和难度级别上持续领先于主流的专有和开源 agent 模型。初步对比验证了该框架卓越的通用推理能力,而基于难度的测试则确认其性能优势随任务复杂度提升而扩大。组件分析进一步表明,核心编排架构为标准基线带来了显著的准确率提升,专门的后训练方法则提供了最优效果。综合来看,这些发现确立了 Orchestra-o1 作为解决复杂 agent 工作流的高效且广泛适用的方案。