Command Palette
Search for a command to run...
InterleaveThinker:强化智能体交错生成
InterleaveThinker:强化智能体交错生成
Dian Zheng Harry Lee Manyuan Zhang Kaituo Feng Zoey Guo Ray Zhang Hongsheng Li
摘要
最近的图像生成器在单图像生成和编辑方面展示了令人印象深刻的照片级真实感和指令遵循能力。然而,受限于其架构,它们无法实现交错生成(文本-图像序列),而该技术在视觉叙事、引导和具身操作中具有关键应用。即使是最新的开源统一多模态模型(UMMs)在此方面也表现出有限的性能。在本文中,我们引入InterleaveThinker,这是首个专为赋予任何现有图像生成器交错生成能力而设计的多agent流水线。具体而言,我们采用planner agent来组织图像-文本输入序列,指导图像生成器在每个步骤所需的执行操作。随后,我们引入critic agent来评估生成器的输出,识别偏离计划指令的样本,并优化指令以进行重新生成。为实现该流水线,我们构建了Interleave-Planner-SFT-80k和Interleave-Critic-SFT-112k以执行格式冷启动。接着,我们开发Interleave-Critic-RL-13k,利用GRPO强化生成轨迹内的逐步指令纠正能力。由于单个交错生成轨迹可能涉及超过25次生成器调用,优化整个轨迹在计算上是不切实际的。因此,我们提出了准确性奖励和逐步奖励,使单步强化学习能够有效指导整个生成轨迹。结果表明,InterleaveThinker提升了各种图像生成器的性能。在交错生成基准测试中,其性能与Nano Banana和GPT-5相当。令人惊讶的是,它在基于推理的基准测试中也显著增强了基础模型;例如,在4-step FLUX.2-klein上,我们在WISE和RISE上观察到了显著提升。
一句话总结
InterleaveThinker 是一个 multi-agent 流水线,通过协调 planner agent 构建分步指令,并协调 critic agent 评估输出并优化后续提示词,为现有图像生成器赋予交错文本-图像序列生成能力。该框架通过 GRPO 强化生成轨迹中的分步指令修正,以解决此前统一多模态模型在视觉叙事和具身操作中的架构限制。
核心贡献
- 本文提出 InterleaveThinker,这是一种 multi-agent 流水线,能够在不修改基础架构的前提下,为冻结的图像生成器添加交错文本-图像序列生成能力。planner agent 负责构建执行步骤,而 critic agent 负责评估输出、识别偏差并优化提示词,以确保严格遵循生成轨迹。
- 训练通过三个精心构建的数据集实现:Interleave-Planner-SFT-80k 和 Interleave-Critic-SFT-112k 用于格式冷启动,Interleave-Critic-RL-13k 用于强化学习。基于 GRPO 的优化采用包含准确性奖励与分步奖励的双奖励策略,在降低计算成本的同时高效对齐长周期生成轨迹。
- 在 FLUX.2-klein 等现成生成器上的评估显示,该框架在交错生成基准测试中超越开源统一多模态模型,并与 Nano Banana 和 GPT-5 等专有系统表现相当。该方法还显著提升了 WISE 基准(0.47 到 0.73)和 RISE 基准(13.3 到 28.9)上的推理性能。
引言
现代图像生成模型在单图合成方面表现优异,但视觉叙事和具身操作等实际应用需要交错生成,以无缝交替输出文本与图像。尽管统一多模态模型试图支持此工作流,但它们经常表现出对中间状态的视觉过度依赖,并在长序列中产生累积的逐步误差。为了解决这些限制,本文提出 InterleaveThinker,这是一个多 agent 框架,能够为冻结的图像生成器添加强大的序列能力。该系统利用 Planner agent 提前预测完整的指令轨迹,有效规避过早的视觉依赖,同时 Critic agent 评估输出并优化提示词以防止误差累积。通过将该架构与精心构建的训练数据集及双奖励强化学习策略相结合,该框架实现了与专有模型相匹敌的轨迹级对齐,并显著增强了基础模型的推理能力。
数据集
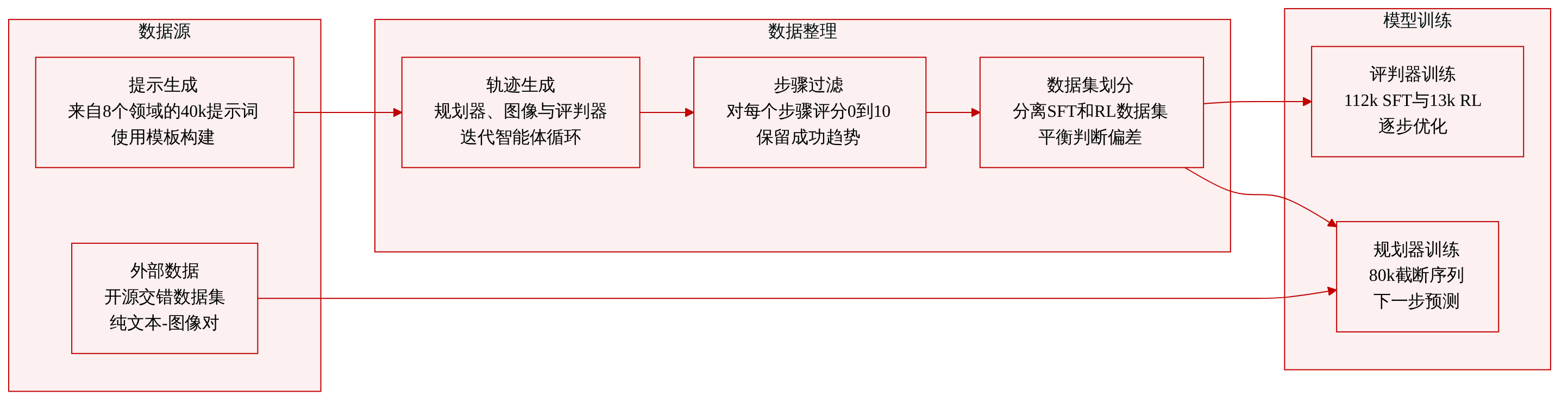
- 数据集构成与来源: 研究团队通过自顶向下的流水线生成约 4 万条文本提示词。该流程始于 8 个广泛领域,扩展至 75 个细粒度子类别,并利用 Gemini 2.5 Pro 构建领域专属词库与指令模板。多 agent 轨迹生成结合 Gemini 2.5 Pro 与 Nano Banana Pro,并加入 FLUX.2-klein-9B 以平衡视觉质量并防止 critic 偏差。最终语料库还整合了现有的开源交错数据集,以补充 planner 训练。
- 子集详情与过滤: Interleave-Critic-SFT-112k 包含 11.2 万条样本,经过过滤以确保具备成功的优化趋势、稳定的高分以及较低的迭代分数方差。Interleave-Critic-RL-13k 包含 1.3 万条样本,因高分方差被选中以捕捉动态优化过程,与 SFT 子集保持严格的 2:1 比例。Interleave-Planner-SFT-80k 包含 8 万条样本,完全绕过 critic 过滤,保留原始未过滤轨迹用于 planner 训练。
- 训练划分与处理: 该流水线将完整轨迹分解为独立的分步片段,以实现稳定的单次迭代优化,避免计算成本高昂的端到端强化学习。每个优化步骤均使用基于 VIEScore 适配的 Gemini 2.5 Pro 从 0 到 10 进行语义对齐与视觉质量评分。研究团队应用定向重采样以平衡 critic 的二元判断分布,确保迭代预测训练的无偏性。
- 元数据与结构处理: Planner 训练对通过随机截断交错文本-图像序列构建,其中前置上下文作为输入,后续文本规划作为目标输出。元数据明确追踪原始用户指令、重写后的优化提示词以及配对的原图与生成图,以支持分步评估。过滤流水线丢弃表现出负面优化趋势或持续低质量的步骤,仅保留展示成功迭代改进的步骤。
实验
评估采用多 agent InterleaveThinker 框架,在交错生成与基于推理的编辑基准测试中,使用域内与泛化图像模型验证性能。结果表明,该方法通过有效缓解视觉过度依赖与分步误差累积,同时保持文本保真度与图像质量,显著优于现有开源方法。消融研究证实,专用的 planner-critic 架构、微调训练阶段及闭环优化流程对稳健性能至关重要,因为单模型或未过滤替代方案均会导致结果持续下降。尽管该框架在处理基础生成器未知的域外概念时存在局限,但它仍是面向复杂多模态任务的高度可泛化且与模型无关的解决方案。