Command Palette
Search for a command to run...
APPO:智能体过程策略优化
APPO:智能体过程策略优化
Xucong Wang Ziyu Ma Yong Wang Yuxiang Ji Shidong Yang Guanhua Chen Pengkun Wang Xiangxiang Chu
摘要
代理强化学习(Reinforcement Learning, RL)的最新进展显著提升了大型语言模型agents的多轮工具使用能力。然而,大多数现有方法在粗粒度的启发式单元(如工具调用边界或固定工作流)上分配信用,使得难以识别哪些中间决策会影响下游结果。在本工作中,我们从两个角度研究代理强化学习:\textit{何处进行分支以及分支后如何分配信用}。我们的初步分析表明,关键决策点广泛分布于整个生成序列中,而非集中于工具调用处,而仅凭token熵并不可靠地反映其对最终结果的影响。受这些观察结果的启发,我们提出了\textbf{代理过程策略优化(APPO)},该方法将分支和信用分配从粗粒度的交互单元转移到序列中的细粒度决策点。APPO使用结合token不确定性与后续生成内容由策略引起的似然增益的分支得分来选择分支位置,从而实现更具针对性的探索,同时过滤掉虚假的高熵位置。该方法进一步引入了过程级优势缩放,以在分支轨迹中更好地分配信用。在13个基准上的实验表明,APPO稳定地将强大的代理强化学习基线提升了近4分,同时保持了高效的工具调用并维持了行为可解释性。
一句话总结
本文提出 Agentic Procedural Policy Optimization (APPO),一种面向大语言模型 agent 的强化学习框架。该框架通过将信用分配从粗粒度的交互边界转移至细粒度的决策点,并采用融合 token 不确定性策略诱导的似然增益的 Branching Score 以引导定向探索,同时结合过程级优势缩放机制在分支 rollout 间分配信用,从而提升多轮工具使用能力。
核心贡献
- 本文提出 Agentic Procedural Policy Optimization (APPO),将分支生成与信用分配从粗粒度的启发式单元转移至生成序列中分布的细粒度决策点。
- 该算法采用 Branching Score,融合 token 不确定性策略诱导的似然增益以识别高价值分支位置并过滤虚假的高熵位置,同时引入过程级优势缩放机制在分支 rollout 间分配信用。
- 大量评估表明,该方法在十三个基准测试中比现有方法高出约三个百分点,同时保持了相当的工具调用效率与可解释性。
数据集
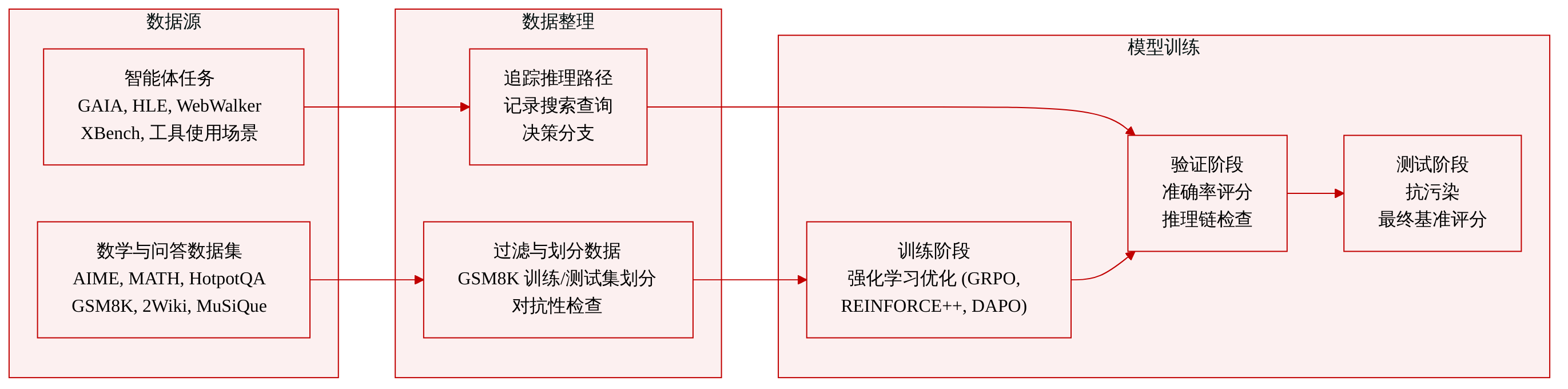
数据集构成与来源
- 作者精心构建了一个涵盖数学推理、多跳知识检索及 agent 网页导航的多领域基准集合。数据来源包括标准化数学竞赛、基于维基百科的问答语料、专家组装的前沿测试集以及真实世界的工具使用场景。
各子集关键详情
- 数学推理:AIME24 与 AIME25 各包含 30 道竞赛级题目,要求输出 0 至 999 之间的整数,涵盖数论、组合数学、几何与代数。MATH500 是更大规模 MATH 语料库的 500 道题目代表子集,而完整 MATH 数据集提供 12,500 道题目,附带逐步解答,难度跨度较大。GSM8K 包含 8,500 道小学级算术应用题。
- 多跳知识:HotpotQA 包含约 11.3 万对维基百科文档,并标注句子级支撑事实。2WikiMultihopQA 基于 Wikidata 三元组构建问题,以确保真正的跨文档推理。MuSiQue 包含约 2.5 万道问题,通过有向无环图链接单跳项目构建,以消除捷径。Bamboogle 是一个经过筛选的 125 道双跳问题集合,专门设计用于击败标准搜索引擎。
- Agent 与前沿评估:GAIA 包含 466 项需要工具使用与规划的真实世界任务。HLE 涵盖 2,500 道专家筛选的 STEM 与人文学科问题,其中约 10% 需要图像理解。WebWalkerQA 包含 680 道要求多页面点击导航的问题。Xbench 提供来自软件工程与法律工作等领域的动态、职业对齐任务,并依据专家参考进行评分。
数据使用与处理
- 作者主要将这些数据集用于严格的能力评估,而非模型训练。GSM8K 明确划分为 7,500 道训练题与 1,000 道测试题,其余所有基准测试均在分布内或分布外使用,以探测特定推理路径。AIME25 因发布时间在训练截止日期之后,被用作防数据污染的验证点。性能指标侧重于较小数据集多次运行的平均准确率,以及多跳任务的细粒度推理链评估。
裁剪、元数据与策略详情
- 数据集构建强调结构完整性与对抗性过滤。多跳基准测试依赖显式的证据链标注与基于 DAG 的组合方式,以防止捷径学习。Bamboogle 将搜索引擎失败作为过滤规则,以强制组合推理。作者还追踪 rollout 轨迹与决策分支,记录搜索查询、中间结果与代码执行块,以分析模型推理稳定性及工具增强规划工作流。
方法
作者提出 APPO,一种 agent 强化学习算法,将分支生成与信用分配从粗粒度的工具或工作流级单元转移至生成序列内的细粒度决策点。在标准的 agent 强化学习设置中,agent 与外部环境及工具集交互以完成任务。rollout 由交错的思考与工具调用步骤组成,随后生成答案。训练目标旨在最大化期望奖励,同时通过 KL 散度惩罚偏离参考策略的行为。
为了解决仅依赖 token 熵的传统分支策略的局限性,作者引入了一种细粒度的过程分支机制。传统基于熵的方法通常选择具有较高词汇不确定性的 token,这可能并不对应实际改变下游推理的决策点。为克服此问题,APPO 将 token 熵与面向未来的似然增益相结合,构建 Branching Score。请参阅概览图以直观对比分支位置与综合指标。
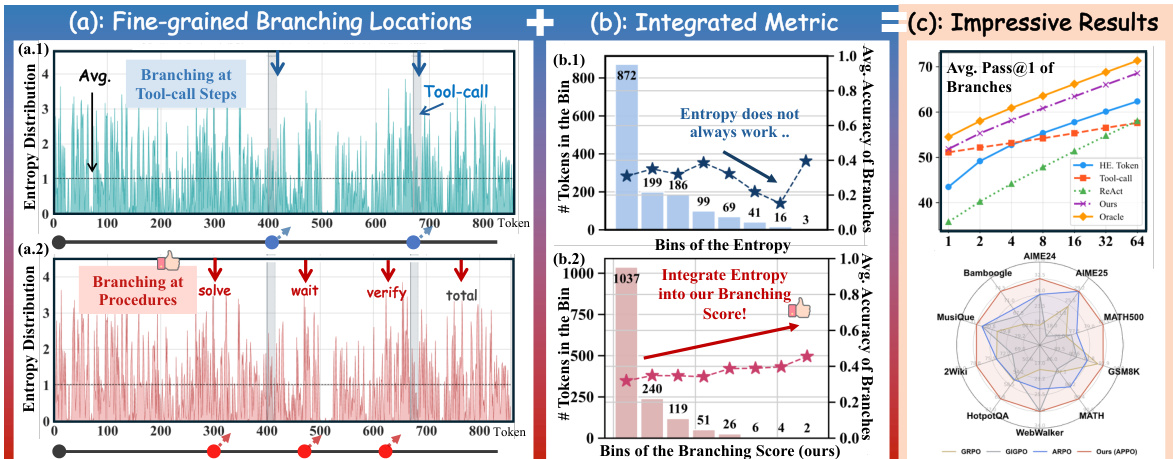
APPO 的核心训练流程如下图所示。
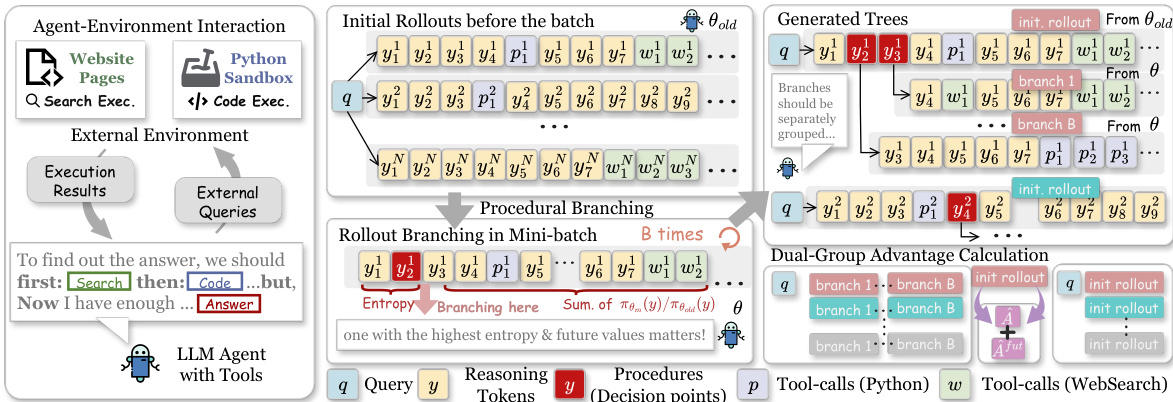
流程始于初始化。给定输入查询与全局 rollout 预算,模型使用当前策略生成一组完整 rollout。这些 rollout 作为独立树的根节点。在 mini-batch 训练阶段,APPO 通过计算 rollout 中每个 token 的 Branching Score 来识别细粒度决策点。Branching Score 定义为归一化 token 熵与未来值项的乘积。token 熵捕捉局部不确定性,而未来值项衡量后续 token 的累积衰减重要性采样比。该未来值作为后验准确率的代理指标,指示 token 是否导向当前策略偏好的状态。通过结合这两个因素,该方法选择既不确定又具关键影响的 token。
识别出顶级分支 token 后,模型使用当前策略从这些位置重采样后续内容以生成新分支。随后这些分支被分组并整合至 rollout 树中。与传统树强化学习方法从固定行为策略中采样分支不同,APPO 使用活跃的 mini-batch 策略生成分支,以更好地反映当前学习动态。
针对优势估计,作者采用双组策略以避免混合不同策略生成的 rollout 所带来的偏差。初始 rollout 与新生成的分支分别计算组内相对优势。该方法将生成的 token 视为潜在决策点的可观测实例,从而实现局部信用分配。此外,为强调推理过程中作为转折点的關鍵过程,APPO 引入面向未来的优势项。该优势项基于从决策点开始的累积重要性采样比对基础优势进行缩放,有效为具有更强下游影响力的决策分配更大信用。最终优势为基础优势与面向未来组件的加权和。
策略优化步骤遵循截断代理目标。模型通过最大化期望优势加权的对数概率比来更新参数,并施加截断约束以确保更新稳定。同时应用 KL 散度惩罚以约束策略相对于参考模型的更新幅度。训练期间生成的分支不直接参与优化,而是提供辅助过程信号,以提升初始 rollout 优势估计的准确性。该设计实现了过程级决策的定向信用分配,显著提升了 agent 任务的探索效率与推理性能。
实验
评估在数学推理、知识密集型推理及深度搜索基准测试中,将所提出的 APPO 方法与多种强化学习及 agent 基线方法进行对比。主要结果验证了基于决策点的分支策略始终优于固定步长方法,其通过将探索导向具有结构意义的推理步骤,而非高熵噪声。缩放分析与定性分析进一步证实,该定向策略产生更稳定的训练动态,生成语义截然不同的推理轨迹,并显著提升不同 rollout 配置下候选方案的多样性与可靠性。
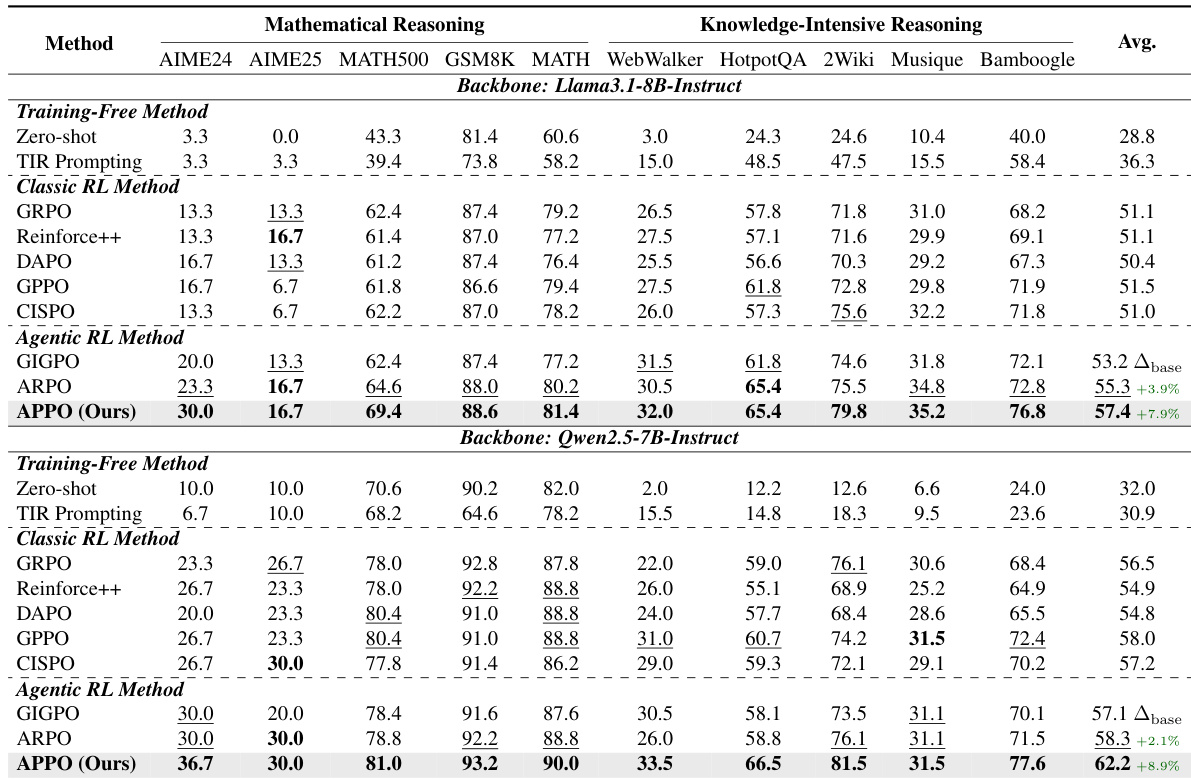
作者使用 Llama3.1-8B 与 Qwen2.5-7B 骨干模型,在数学与知识密集型推理任务上评估 APPO 方法,并与无训练、经典 RL 及 agent RL 基线进行对比。结果表明,APPO 始终取得优越性能,在两类任务中均超越所有基线方法。该方法较基础模型展现出显著的平均提升,并为 agent 推理确立新的最先进水平。在数学推理任务(包括 AIME 与 MATH 等竞争基准)上,APPO 全面超越所有基线。在知识密集型推理数据集上,该方法取得最高平均分,展现出强大的多跳信息综合能力。APPO 在两个模型骨干的几乎所有独立数据集上均稳居第一,表现出稳健的泛化能力。
作者使用 Pass@K 指标在四个深度搜索基准测试中将 APPO 方法与 ARPO 基线进行对比。结果显示,APPO 在所有数据集与采样设置中均稳定取得高于 ARPO 的性能。此外,随着采样轨迹数量增加,APPO 与 ARPO 之间的性能差距往往扩大,表明 APPO 有效提升了有效推理路径的多样性。在 Pass@1、Pass@3 与 Pass@5 指标下,APPO 在全部四个数据集(GAIA、HLE、WebWalkerQA、xbench-DS)上均稳定优于 ARPO。APPO 相对于 ARPO 的性能优势通常随采样轨迹数量(K)增长而扩大。这一趋势表明,APPO 优化了候选方案的整体分布,而非仅提升 Top-1 轨迹。

实验评估了 APPO 方法对分支配置的敏感性,重点关注初始树数量、分支 token 数量与循环次数。结果表明,仅含单棵初始树的配置在知识密集型推理任务上表现相对较差,且该性能基本不受分支宽度或深度变化的影响。相反,将初始树数量增加至三棵会带来显著的性能提升,凸显了初始 rollout 多样性的重要性。单初始树配置表现出次优性能,且对分支参数变化不敏感。与单树设置相比,将初始树数量增至三棵导致整体性能显著改善。研究结果表明,在低多样性框架内微调分支预算,不如确保初始 rollout 的多样性对成功更为关键。

实验使用 Llama 与 Qwen 模型骨干,将 APPO 方法与消融变体及基线进行对比。APPO 在所有数据集上始终取得最高平均性能,优于移除特定组件或使用基于熵指标的变化版本。结果表明,包含未来优势与双组估计的完整方法对达到最优性能至关重要。与消融变体及基线相比,APPO 在所有数据集上稳定获得最高平均分。移除未来优势组件会导致性能明显下降,在 Qwen 骨干上尤为显著。禁用双组优势估计会导致性能低于完整 APPO 方法。
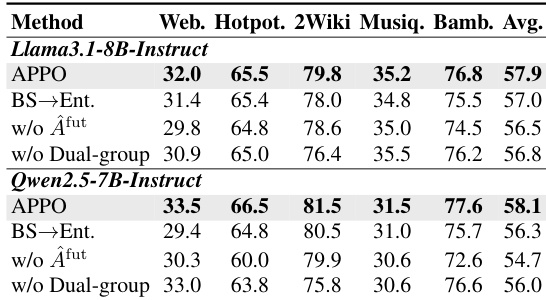
实验分析了固定 rollout 预算在初始树数量与用于分支的选定 token 数量之间的分配方式。结果表明,平衡配置显著优于极端设置,极端设置将预算严重倾斜于初始多样性或深度扩展。与极端预算分配相比,初始树与选定 token 的平衡配置始终产生更优性能。增加初始树数量可提升轨迹多样性,但会减少用于扩展高影响力决策点的预算。过度聚焦于扩展特定决策点会将预算集中在较少路径上,从而限制全局覆盖范围。
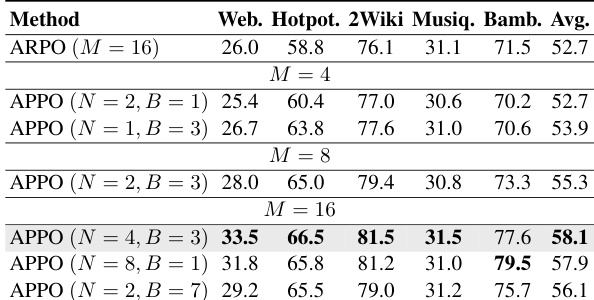
作者使用标准 LLM 骨干,在数学与知识密集型推理任务上评估 APPO 与多种基线及消融变体的对比。对比与消融研究验证了完整方法始终优于现有方法,其通过有效提升推理轨迹的多样性与质量来实现这一目标,且未来优势估计与双组估计均被证明对最优性能至关重要。敏感性与预算分配实验进一步表明,优先考虑多样初始 rollout 而非深度扩展可产生最稳健的结果,而在初始树生成与 token 级分支之间平衡计算资源对于最大化整体推理能力至关重要。