Command Palette
Search for a command to run...
TRIAGE:基于大语言模型针对不规则采样医疗时间序列进行可解释风险预测的辩证推理
TRIAGE:基于大语言模型针对不规则采样医疗时间序列进行可解释风险预测的辩证推理
Hyeongwon Jang Gyouk Chu Changhun Kim Joonhyung Park Hangyul Yoon Eunho Yang
摘要
基于电子健康记录构建的临床早期预警系统,其临床观察被记录为不规则采样医学时间序列(ISMTS),必须同时提供用于患者分诊的校准风险评分以及临床医生可验证的可解释依据。大语言模型(LLMs)已被探索用于此任务,但它们将分级的临床风险坍缩为过度自信的二元预测。这种风险极化削弱了校准效果与跨患者可比性。为解决这一问题,我们提出TRIAGE框架,该框架通过提取结果特定的依据,训练大语言模型对相互竞争的临床结果生成辩证推理。该辩证表述有效缓解了风险极化,使单个大语言模型能够基于明确的临床推理输出连续的风险评分。在三个ISMTS基准上的评估表明,与竞争性基线相比,TRIAGE的平均AUPRC提升了3.3%,校准误差降低了81%。LLM-as-a-judge评估进一步表明,我们的依据在临床推理质量上较基线的事后解释提升了20%。源代码已开源,地址为 https://github.com/HyeongWon-Jang/TRIAGE 。
一句话总结
作者提出 TRIAGE,这是一个训练大语言模型生成关于竞争性临床结果的辩证推理的框架。该框架为不规则采样的医疗时间序列提供连续、校准良好的风险评分和可解释的推理依据,在三个基准测试中平均提升 AUPRC 3.3%,降低 81% 的校准误差,并在临床推理质量上超越基线事后解释方法 20%。
核心贡献
- TRIAGE 是一个训练大语言模型为不规则采样的医疗时间序列生成关于竞争性临床结果的辩证推理的框架。通过提取针对特定结果的推理依据而非强制单一预测,该方法防止了概率坍缩,并输出连续且可跨患者比较的风险评分。
- 该方法采用包含辩证推理监督与自我优化的两阶段训练流水线,以使隐式概率分布与患者临床证据对齐。此设计使模型能够在单次前向传播中权衡同时存在的恶化与稳定临床信号。
- 在三个不规则采样时间序列基准上的评估显示,该框架相比具有竞争力的基线模型,AUPRC 平均提升 3.3%,校准误差降低 81%。基于大语言模型作为裁判的评估进一步表明,生成的推理依据在临床推理质量上超越事后解释方法 20%。
引言
临床预警系统利用电子健康记录中不规则采样的医疗时间序列来预测不良事件,这需要既提供用于患者分诊的良好校准风险评分,又提供临床医生可验证的可解释推理依据。现有方案无法同时提供这些能力,因为专用深度学习模型仍然缺乏透明度,且事后解释方法仅能提供非语言形式的归因分数,而非高层级的临床推理。基于大语言模型的方法也面临类似的权衡,通常为了连续风险评分而牺牲自然语言解释,或遭受风险极化问题,即提取的推理依据会预先锁定单一结果,导致概率分布坍缩为过度自信的二元预测。作者提出 TRIAGE,这是一个训练大语言模型通过生成特定结果的推理依据来输出关于竞争性临床结果的辩证推理的框架。该方法缓解了风险极化问题,并通过辩证推理监督与自我优化的两阶段流水线,使单一模型能够基于明确的临床推理,输出连续且可跨患者比较的风险评分。
数据集

实验
在针对脓毒症和死亡率预测的三个不规则医疗时间序列基准上的评估验证了 TRIAGE 的预测准确性、校准效果以及针对缺失临床变量的鲁棒性。消融研究表明,辩证推理与批次级强化学习显著优于传统的单一结果监督与样本级奖励,有效缓解了风险饱和问题并提升了评分可靠性。定性评估进一步证实,该模型生成的推理依据具备临床依据且感知时间动态,避免了标准大语言模型和事后可解释性方法中普遍存在的一边倒偏差与幻觉问题。总体而言,研究结果确立了 TRIAGE 作为一个鲁棒且数据高效的框架,成功实现了高保真临床推理与可靠风险预测的结合。
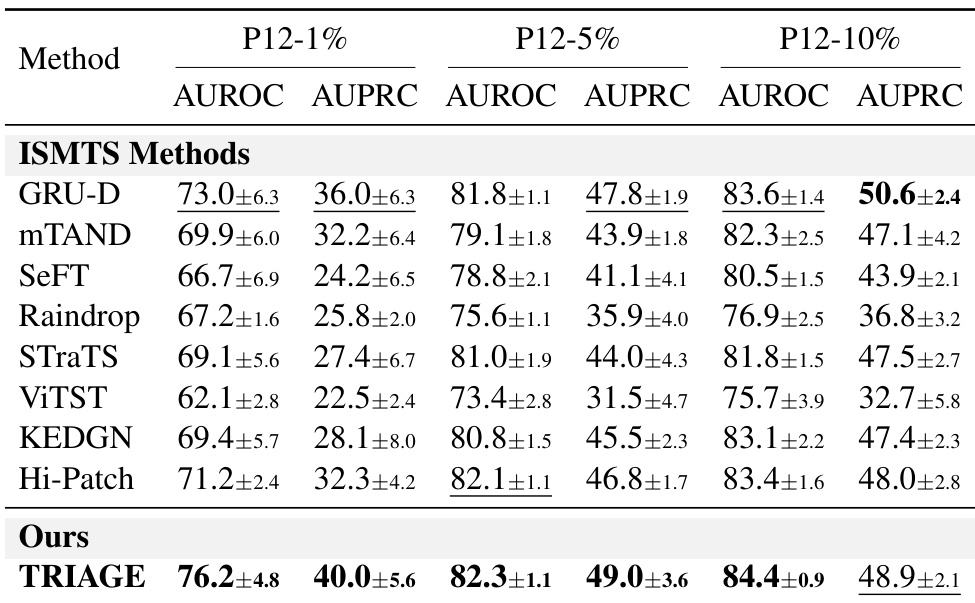
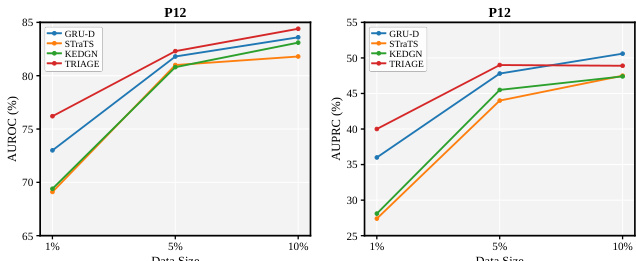
作者在 P12 数据集上,针对不同的训练数据比例,将 TRIAGE 与现有的 ISMTS 基线模型进行了对比评估。结果表明,在标注数据稀缺的情况下,TRIAGE 显著优于现有方法,展现出极高的数据效率。随着数据可用性的增加,TRIAGE 仍保持竞争力,在大多数评估指标上达到顶尖水平。在数据量较少的场景下,TRIAGE 显著超越基线模型,再次证明其高数据效率。该方法在所有评估的数据比例下均稳定获得最高的 AUROC 分数。随着训练数据可用性的增加,TRIAGE 与顶尖基线模型的性能保持相当。
作者通过在推理阶段随机屏蔽输入变量,评估了 TRIAGE 模型相对于现有基线模型的鲁棒性。实验表明,随着缺失数据比例的增加,TRIAGE 比竞争方法更有效地保留了预测能力。经过强化学习调优的变体在严重数据稀缺的情况下,展现出维持高判别指标的优势。当缺失变量比例从 10% 上升至 50% 时,TRIAGE 表现出比基线模型更高的稳定性。在较高的缺失率下,经过强化学习调优的 TRIAGE 变体在 AUPRC 指标上稳居第一。尽管在较低的缺失率下基线模型占优,但 TRIAGE 在所有测试场景中均持续保持在第一梯队。
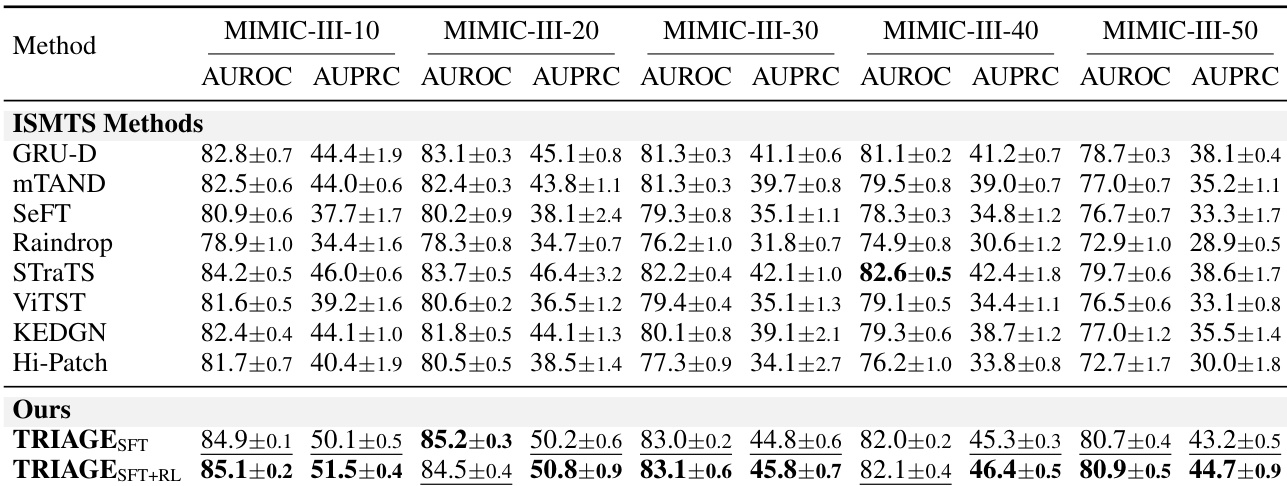
作者在 MIMIC-III 数据集上,针对不同变量屏蔽比例,将 TRIAGE 模型与多个 ISMTS 基线模型进行了对比评估。结果表明,无论是监督微调版本还是强化学习增强版本的 TRIAGE,在所有测试的缺失数据场景下,其判别性能均持续优于现有方法。即使屏蔽变量比例增加,该模型仍能保持稳健的预测准确性,凸显其对不完整临床信息的强韧性。提出的 TRIAGE 模型(尤其是经过强化学习后)在所有变量屏蔽比例下,于 AUROC 和 AUPRC 指标上均稳定超越所有 ISMTS 基线模型。TRIAGE 展现出对缺失数据的卓越鲁棒性,即使移除多达一半的输入变量,仍能维持高预测性能。强化学习阶段相比单独使用监督微调带来了显著的性能提升,在几乎所有评估点上均取得最佳结果。
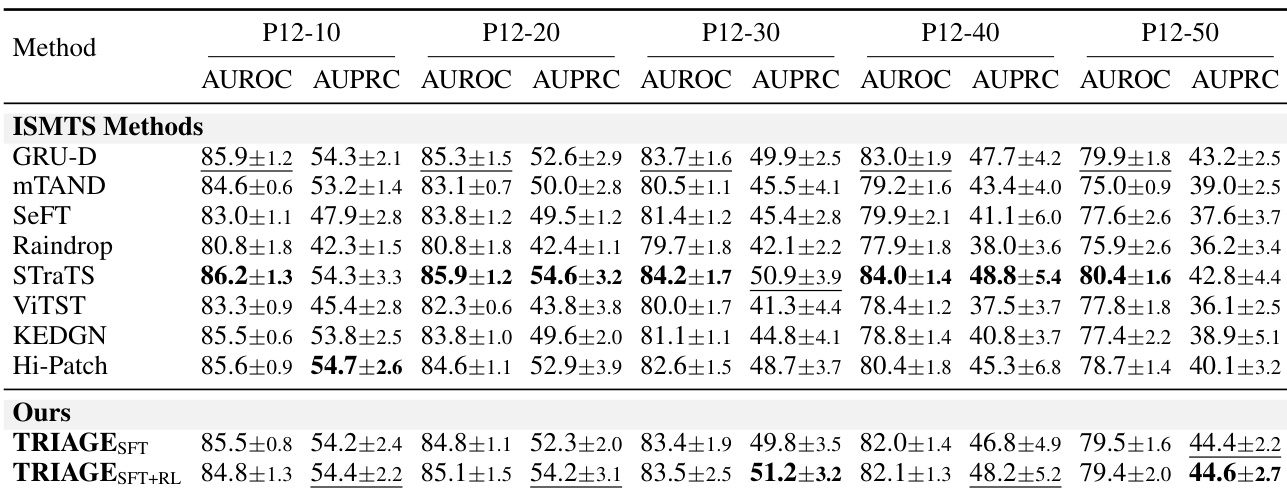
作者在 P12 数据集上评估了模型在不同训练数据规模下的性能。结果表明,所有方法均从数据可用性的增加中获益,随着训练集扩大,性能提升明显。所提方法在所有数据比例下均持续获得最高的判别分数,在低资源场景下展现出最显著的优势。该方法在所有数据规模下均取得最高的 AUROC 和 AUPRC 分数,且在最低训练比例下优势最为明显。随着训练数据规模的增加,所有模型的性能均有所提升。即使数据可用性增长,该方法仍对基线模型保持明显领先,尽管在较高数据比例下领先幅度略有收窄。
作者通过对比零样本推理与监督微调基线,分析了不同推理结构的有效性。结果表明,与所有其他测试方法相比,提出的 TRIAGE_SFT 方法在判别指标上实现了最高性能。相较于零样本推理及其他监督基线,TRIAGE_SFT 在判别指标上表现更优。与仅包含答案的监督微调相比,单一方向推理依据的监督导致预测准确性降低。零样本推理在评估的推理策略中表现最弱。
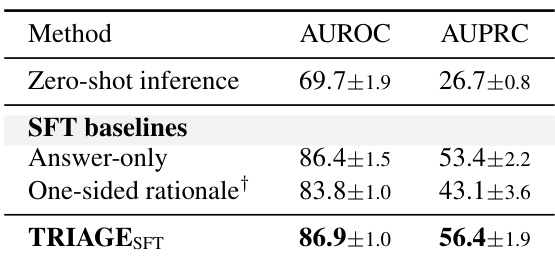
作者在 P12 和 MIMIC-III 数据集上,通过测试不同训练数据比例、递增的输入变量屏蔽比例以及不同的推理策略,将 TRIAGE 与现有基线模型进行了对比评估。这些实验验证了模型在低资源场景下的高数据效率、在严重缺失数据条件下的预测稳定性,以及强化学习相较于零样本或标准监督方法的有效性。总体而言,TRIAGE 对训练数据稀缺和临床信息不完整展现出卓越的韧性,并在所有测试场景中持续保持顶尖性能。