Command Palette
Search for a command to run...
你的未嵌入矩阵实际上是文本嵌入的特征透镜
你的未嵌入矩阵实际上是文本嵌入的特征透镜
Songhao Wu Zhongxin Chen Yuxuan Liu Heng Cui Cong Li Rui Yan
摘要
大型语言模型在广泛的下游任务中展现出卓越的零样本能力。然而,它们难以直接作为现成的嵌入模型使用,导致在大规模文本嵌入基准测试中表现欠佳。本文旨在揭示导致这一缺陷的潜在原因。我们的研究动机源于一个意外发现:当投影至词汇空间时,文本嵌入倾向于与高频但信息量匮乏的tokens对齐。我们认为,高频tokens的过度表达抑制了模型捕捉细微语义的能力。为解决该问题,我们提出了EmbedFilter,这是一种简单的线性变换,旨在直接优化源自大型语言模型的文本嵌入。具体而言,我们发现大型语言模型中的未嵌入矩阵编码了一个潜在空间,该空间正积极地将这些高频tokens映射至嵌入空间。通过过滤该子空间,EmbedFilter有效抑制了高频tokens的影响,从而增强了语义表示。作为一项显著的附加收益,该方法实现了固有的降维,在完全保留优化后嵌入质量的同时,降低了索引存储开销并加速了检索过程。我们在多个大型语言模型骨干网络上的实验表明,搭载EmbedFilter的大型语言模型即使在嵌入维度显著降低的情况下,仍能取得更优的零样本下游性能。我们希望本研究能为基于大型语言模型的表示机制提供更深层次的见解,并启发更严谨的设计以改进文本嵌入训练。我们的代码已开源,地址为 https://github.com/CentreChen/EmbFilter。
一句话总结
EmbedFilter 通过线性变换优化大语言模型的文本嵌入,该变换利用 unembedding 矩阵作为特征透镜,过滤掉高频 token 子空间,抑制无信息量 token 并增强语义表示,同时实现内在的降维,在保持嵌入质量的前提下降低索引存储开销并加速检索。
核心贡献
- 本研究识别出大语言模型 unembedding 矩阵中编码高频 token 并导致语义各向异性的潜在子空间。EmbedFilter 被提出为一种无需训练的线性变换,通过投影剔除该子空间,直接优化原始模型嵌入。
- 在多种大语言模型骨干网络上的广泛评估表明,EmbedFilter 在零样本文本嵌入任务的 MTEB 基准上实现了高达 14.1% 的性能提升。这种轻量级后处理技术在不需额外训练的情况下提升了表示质量。
- 该变换作为一种保距操作,隐式降低了嵌入的有效维度。这种内在压缩在完全保留优化后嵌入质量的同时,降低了索引存储开销并加速了检索速度。
引言
大语言模型已彻底改变零样本学习,但在语义搜索和大规模检索等关键应用中,作为现成的文本嵌入模型使用时表现始终不佳。以往的改进方案依赖提示词工程与启发式调整,这些方法对配置高度敏感、计算成本高昂,且最终未能触及限制语义捕获能力的根本瓶颈。作者借助机制可解释性揭示,大语言模型的 unembedding 矩阵编码了一个潜在子空间,该子空间强制嵌入向高频但语义空洞的 token 对齐,从而产生各向异性的表示。为解决这一问题,作者提出 EmbedFilter,这是一种无需训练的线性变换,能够隔离并剔除该问题子空间。该方法显著提升了零样本嵌入质量,在不扭曲距离的前提下自然压缩向量空间,并在降低存储开销的同时加速检索。
数据集
- 数据集构成与来源:作者使用了一个专注于零样本文本嵌入与大语言模型研究的语料库,尽管提供的文本未明确外部存储库或原始数据来源。
- 各子集关键细节:未提供关于子集大小、来源划分或应用于材料的过滤标准的信息。
- 论文的数据使用方式:作者未说明训练集划分、混合比例或数据在机制可解释性任务中的分配方式。
- 其他处理细节:输入内容未描述用于准备数据集的裁剪策略、元数据构建或预处理流程。
方法
作者利用大语言模型(LLM)的 unembedding 矩阵开发了一种通过过滤边缘谱子空间来增强文本嵌入的方法,研究发现该子空间编码了主导性的、语义信息匮乏的 token。从 LLM 中提取文本嵌入的标准流程是将输入句子 X=[x1,x2,…,xL] 传入模型骨干网络,并应用池化策略 P 生成稠密向量 h∈Rd。该嵌入源自 LLM 最后一层的输出,而将隐藏状态映射回词汇空间的 unembedding 矩阵是模型解码机制的核心。作者指出,该矩阵在嵌入质量方面尚未得到充分利用,可被用于优化嵌入表示。
为识别负责编码高频、非语义 token 的子空间,作者采用了 Logit Lens 和 Logit Spectroscopy 等机制可解释性工具。Logit Lens 将中间表示投影至词汇空间,以分析激活值如何影响 token 预测。在此基础上,Logit Spectroscopy 利用 unembedding 矩阵 WU=UΣV⊤(其中 WU∈R∣V∣×d)的奇异值分解(SVD),分离各个谱分量的贡献。对于每个维度 i,过滤器 Ψi=I−V[i]V[i]⊤ 会移除表示在 V 的第 i 个右奇异向量上的投影,从而实现对隐藏状态的谱分析。
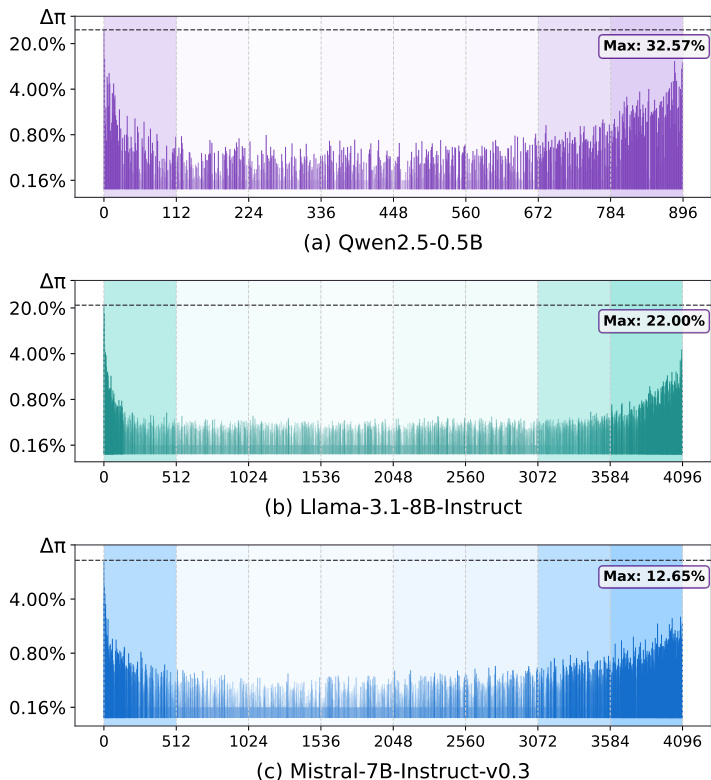
作者结合训练语料中的词频与 unembedding 矩阵,逆向推导“平均” token 表示。利用 WU⊤ 的 Moore–Penrose 伪逆,他们计算平均嵌入 h^=log(p^)WU+,其中 p^ 为 token 的经验频率分布。将该平均 token 应用于 Logit Spectroscopy,作者通过累积 logit 差值 Δπ(i) 量化了每个谱子空间对高频 token 的影响,该差值衡量了 logit 预测对过滤掉第 i 个子空间的敏感度。结果表明,对应于最大和最小奇异值的边缘谱对高频 token 具有主导作用,说明该区域编码了通用且非语义的信息。
基于上述洞察,作者提出 EmbedFilter,一种用于从原始 LLM 文本嵌入中过滤边缘谱子空间的线性变换。主体谱变换 Φτ 定义为 Φτ=V[lτ:rτ]V[lτ:rτ]⊤,其中 lτ 和 rτ 为中程奇异成分的索引,排除了与极端奇异值相关的成分。该变换在处理后阶段应用,将嵌入 ei 优化为 ei=eiΦτ⊤,在有效抑制边缘谱影响的同时保留捕获核心语义的主体谱。 
如图所示,优化后的嵌入在频繁且无信息量 token 上的过度表征现象得到缓解,语义丰富度显著提升,Logit Lens 分析证实了这一点。作者进一步观察到,EmbedFilter 能够在不损失性能的前提下实现降维。由于变换矩阵 V[lτ:rτ] 是正交的,它保留了成对距离,使得嵌入能够被投影至低维空间,且相似度测量在理论上不会退化。这种降维降低了内存开销并加速了检索,兼顾了效率与效果的双重提升。
实验
在三种主流大语言模型骨干网络上进行的 MTEB 基准评估表明,实验验证了 EmbedFilter 通过轻量级降维与定向子空间过滤提升嵌入质量的能力。该方法在语义相似度、分类、聚类及检索任务中均持续提升性能,同时在不同过滤比例下保持鲁棒性,并显著降低计算开销。消融研究证实,这些性能提升源于对中间奇异子空间的策略性过滤,而非简单的维度截断,使框架无需任务特定校准即可逼近理论性能上限。此外,该方法在无需监督数据的情况下优于传统校准基线,确立了其作为高效且可泛化的增强方案,适用于将大语言模型部署为嵌入生成器。
作者在 MTEB 基准的多种任务与骨干模型上评估了 EmbedFilter,证明其相较于基线方法具有稳定的性能提升。结果显示,EmbedFilter 在大幅降低嵌入维度时仍能保持强有效性,且计算开销极小。该方法优于多种消融配置与校准基线,凸显了其鲁棒性与高效性。即使在显著降维的情况下,EmbedFilter 在所有评估任务与模型上均实现一致的性能提升。该方法在计算开销极低的情况下维持了强大的下游性能,超越了复杂的提示词工程框架。EmbedFilter 优于消融配置与校准基线,证明其无需任务特定调优即可发挥有效性。
作者在 MTEB 基准的多种任务与骨干模型上评估了 EmbedFilter,证明其相较于基线方法具有稳定的性能提升。结果显示,EmbedFilter 在显著降维时仍能保持强有效性,且无需任务特定校准数据即可超越提示词工程方法与校准基线。EmbedFilter 在不同模型与任务中实现一致的性能增益,即使在高降维比例下仍能维持提升效果。该方法优于提示词工程与白化等校准基线,不依赖监督数据或复杂的校准过程。EmbedFilter 的有效性并非源于简单的降维,因为替代过滤策略的表现均不及该方法。
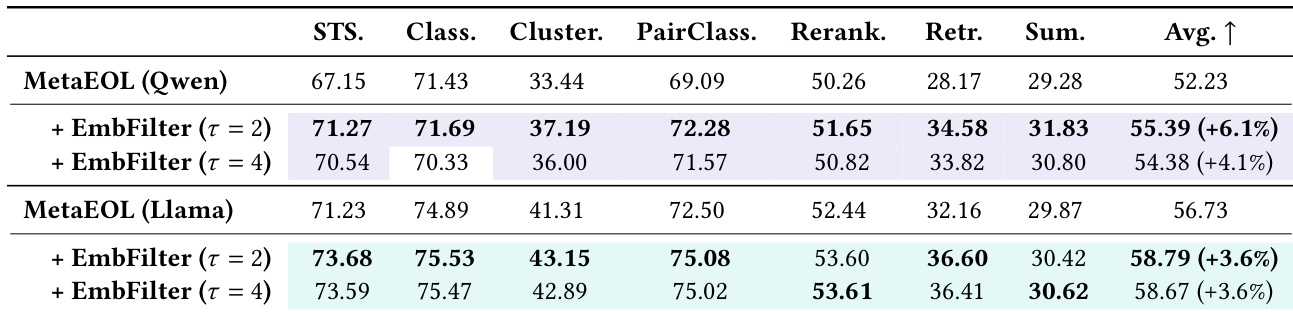
作者在 MTEB 基准的多种任务与骨干模型上评估了 EmbedFilter,证明其相较于基线方法具有稳定的性能提升。结果显示,EmbedFilter 在显著降维时仍能保持强有效性,在引入极小计算开销的同时实现更高的综合性能。该方法优于替代过滤策略与校准基线,凸显了其鲁棒性与高效性。即使在显著降维的情况下,EmbedFilter 在所有评估任务与模型上均实现一致的性能提升。与基线方法相比,该方法在计算开销极低的情况下维持了优越的综合性能。EmbedFilter 无需任务特定校准数据,即可优于替代过滤策略与嵌入校准基线。
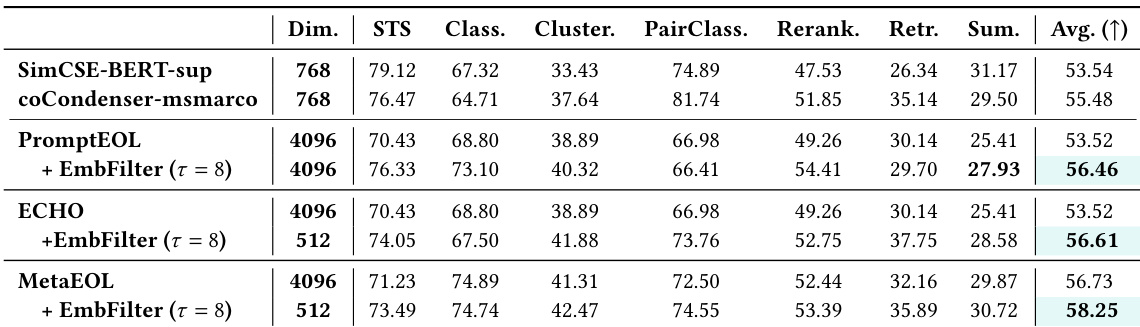
作者在 MTEB 基准的多种任务与骨干模型上评估了 EmbedFilter,证明其相较于基线方法具有稳定的性能提升。结果显示,EmbedFilter 在降低嵌入维度的同时提升了各项任务的性能,且在高过滤比例下仍能维持增益。该方法无需额外监督数据,在结果上优于提示词工程基线与白化等校准技术。EmbedFilter 在 MTEB 各项任务中持续提升性能,取得高于基线方法的综合得分。该方法在降低嵌入维度时仍保持强劲性能,在高过滤比例下展现出有效性。EmbedFilter 优于白化等基于校准的方法,且不依赖监督校准数据。

作者在 MTEB 基准的多种大语言模型与配置上评估了 EmbedFilter,证明其在不同任务与降维比例下相较于基线方法具有稳定的性能提升。结果显示,EmbedFilter 在显著降维时仍能保持强劲性能,且其有效性在不同模型架构与提示策略下均表现稳健。该方法以极小的计算开销实现性能增益,适用于资源受限场景下的高效部署。即使在大幅降低嵌入维度的情况下,EmbedFilter 在所有评估模型与任务中均持续提升性能。该方法以极小的计算开销取得优异结果,优于需要迭代调用大语言模型的更复杂框架。EmbedFilter 的有效性并非源于简单的降维,因为随机或截断子空间方法的表现均不及所提出的过滤策略。
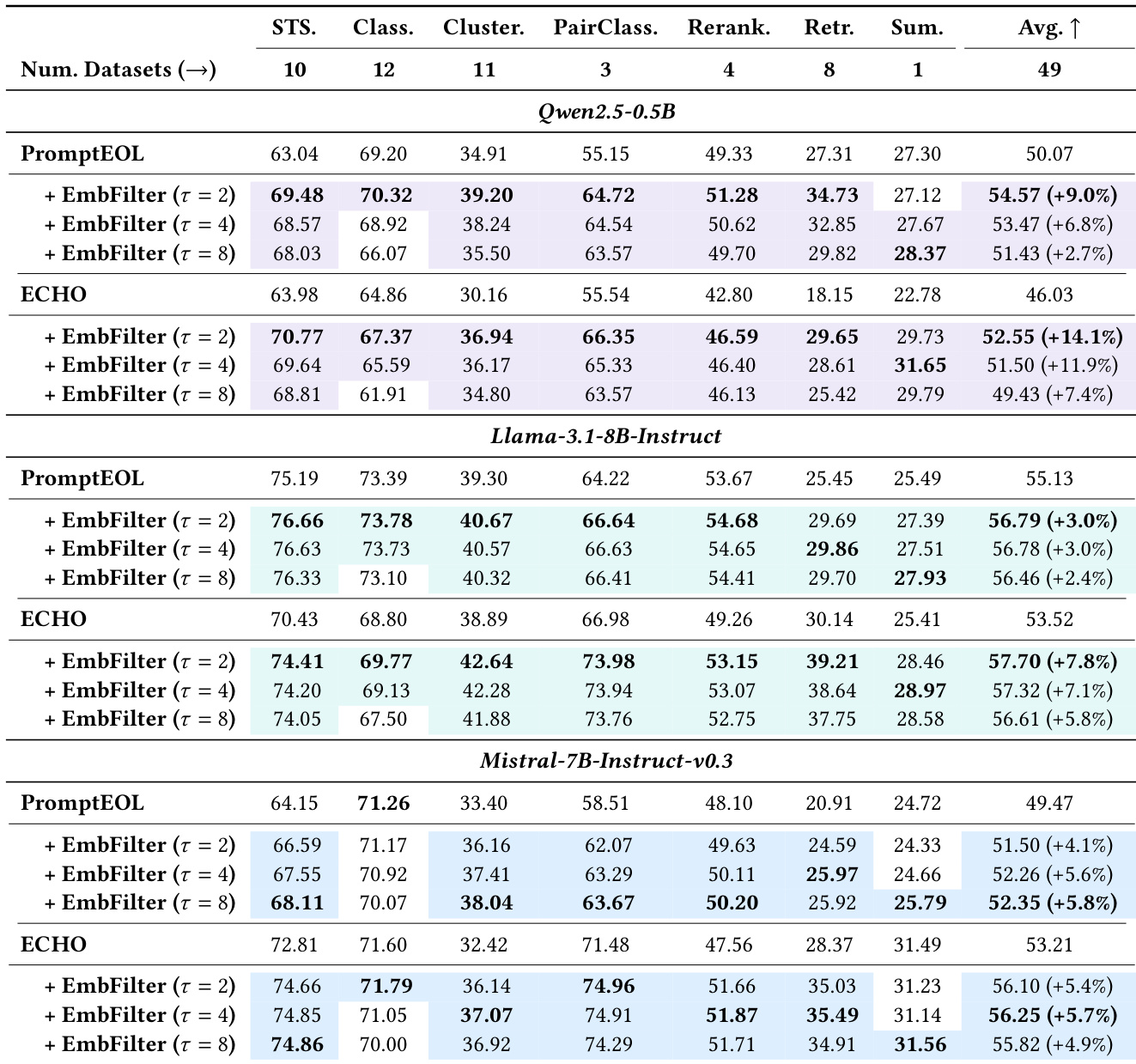
在包含多种骨干模型与任务的 MTEB 基准上进行的评估表明,实验验证了 EmbedFilter 在显著降低嵌入维度的同时持续提升下游性能的能力。该方法在不同架构与高过滤比例下展现出稳健的有效性,在极小计算开销下维持了强劲结果。此外,该方法无需任务特定数据或监督数据,即可超越校准基线与复杂的提示词工程框架,证实其性能提升源于定向过滤而非简单降维。