Command Palette
Search for a command to run...
记忆是重构的,而非检索的:面向 LLM Agents 的图记忆
记忆是重构的,而非检索的:面向 LLM Agents 的图记忆
Shuo Ji Yibo Li Bryan Hooi
摘要
尽管近期取得了进展,LLM agents 在基于长交互历史进行推理方面仍面临挑战。尽管当前的 memory-augmented agents 依赖于静态的检索-推理范式,但这种僵化的流水线设计使其无法根据推理过程中发现的中间证据动态调整记忆访问。为弥补这一差距,我们提出了 MRAgent,该框架将关联记忆图与主动重构机制相结合。我们将记忆表示为 Cue-Tag-Content 图,其中关联标签作为语义桥梁,将细粒度线索与记忆内容相连接。基于该结构,我们的主动重构机制将 LLM 推理直接整合至记忆访问过程中,使 agent 能够依据累积的证据迭代地探索并剪枝检索路径。这确保了记忆检索能够动态适配推理上下文,同时避免因无约束扩展而引发的组合爆炸。在 LoCoMo 基准与 LongMemEval 基准上的实验表明,该方法相较于强基线取得了显著提升(最高达 23%),同时大幅降低了 token 与运行时间成本,充分验证了主动与关联重构在长程记忆推理中的有效性。
一句话总结
MRAgent 以 Cue-Tag-Content 记忆图谱和主动重构机制取代静态检索流水线。该机制将推理直接整合至记忆访问中,基于累积证据迭代剪枝检索路径,在 LoCOMO 和 LONG-MEMEVAL 基准测试中带来最高 23% 的性能提升,同时降低 token 与运行时间成本。
核心贡献
- MRAgent 框架引入主动记忆重构范式,将 LLM 推理直接整合至检索流程,支持基于累积中间证据动态调整搜索策略。
- Cue-Tag-Content 记忆图谱结构显式编码细粒度线索与记忆内容之间的语义关联,使 agent 能够识别高潜力检索路径并剪枝无关分支。
- 理论分析证明主动检索策略在表达能力上严格优于被动替代方案。在 LoCOMO 和 LONG-MEMEVAL 基准上的评估显示,性能提升最高达 23%,同时大幅降低 token 与运行时间成本。
引言
交互式助手等长周期 LLM 应用需要保留大量交互历史,但固定的上下文窗口从根本上限制了长任务中的持续推理。因此,外部记忆系统对维持连续性至关重要,然而现有方法依赖静态的“检索后推理”流水线,将记忆视为被动数据库。这些系统依赖固定的 top-k 选择或预定义图遍历,导致 agent 无法在推理过程中随新证据出现而动态调整搜索策略。该框架利用 Cue-Tag-Content 记忆图谱将记忆访问转化为主动的多步重构过程。通过嵌入连接上下文线索与详细内容的关联标签,使 LLM 能够基于中间推理迭代探索并剪枝检索路径。该方法使记忆访问与不断演化的推理上下文动态对齐,在显著提升长周期性能的同时降低计算开销。
数据集

- 数据集构成与来源: 研究构建了一套混合评估套件,将两项成熟的对话记忆基准与合成检索分布相结合。LoCoMo 源自人工与 LLM 生成流水线,LongMemEval 提供带时间戳的聊天会话,而“干草堆中的二叉树针”任务通过算法生成以隔离检索机制。
- 子集详情: LoCoMo 包含 50 个扩展对话,跨度最多达 35 个会话,平均每场对话 300 轮,包含约 200 个问答对。LongMemEval 提供来自 LongMemEval S 设置的约 500 个评估实例,每个实例配对约 115K token 的聊天历史。合成二叉树分布构建深度为 d = T - 1 的完整二叉树,包含 n = 2^{d+1} - 1 个节点,目标叶节点索引均匀采样,答案标签 y 从 P_Y 中抽取。
- 数据用途: 上述数据集仅用于评估而非训练。LoCoMo 与 LongMemEval 用于评估模型在持续交互中处理多跳推理、时间追踪与偏好保留的能力。二叉树分布通过要求模型遵循确定性路径以揭示答案,衡量主动导航与被动猜测之间的性能差距。
- 处理与元数据构建: 团队从 LoCoMo 中移除对抗性问题以匹配基线约束,并将重点置于记忆重构而非不可回答查询检测。对于合成树,节点载荷经过设计以显式存储每个前缀节点的下一步路径位,同时为目标叶节点载荷保留最终答案,确保所有非目标信息与 y 保持独立。此外,采用严格的关键词提取提示词隔离每句 2 至 30 个显式术语,过滤推断概念,并对实体、主题与时间标记强制执行直接文本匹配。
方法
研究提出一种重构型记忆 agent,将记忆访问定义为顺序且带状态的决策过程,而非静态查找。这一范式转变超越了依赖固定相似度评分或预定义图扩展的传统被动检索。检索策略的高层对比请参阅框架示意图。
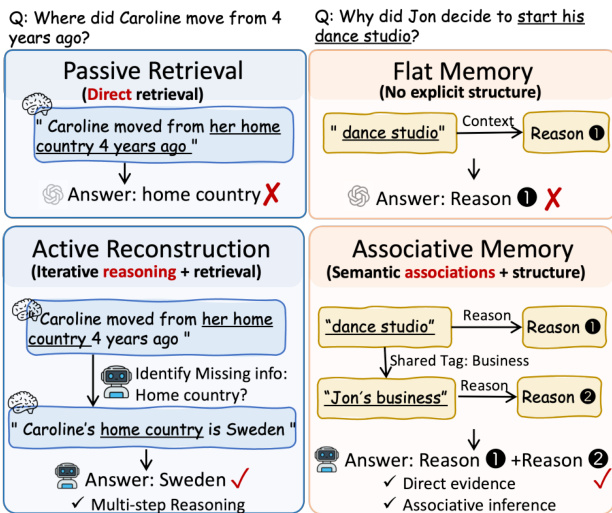
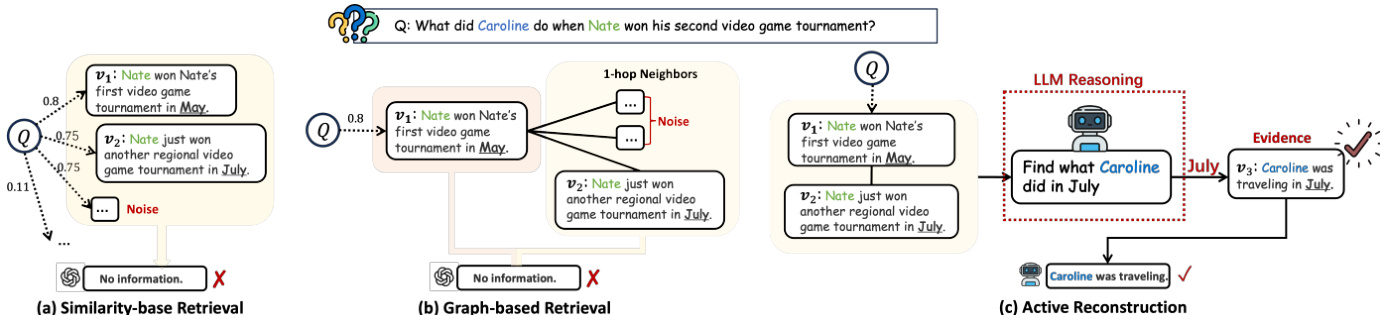
现有记忆系统通常采用基于相似度的检索或基于图的邻居扩展。基于相似度的方法计算查询与记忆单元之间的相关性得分,并选择 top-k 匹配项。基于图的方法通过检索种子节点及其预定义邻居来扩展此过程。然而,这两种范式均存在噪声累积问题,且无法适应中间发现。如图所示,被动检索常检索到无关事件,或无法揭示静态结构中无直接关联的信息。
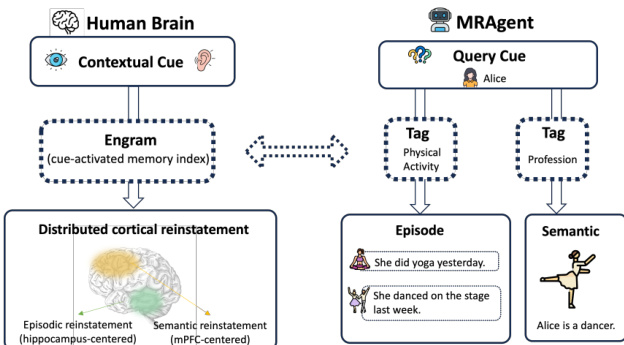
为克服这些局限,研究受认知神经科学启发。人类回忆通过线索激活的记忆索引顺序展开,并偏向后续检索。该生物机制催生了 Cue-Tag-Content 架构的设计。下图展示了人类记忆重构与所提模型之间的功能对应关系。
记忆系统组织为包含细粒度线索、关联标签与记忆内容的异构图。标签作为中间结构,总结线索与内容间的关系模式,使关联推理与内容级检索解耦。记忆图谱进一步划分为多粒度层级,包括用于具体事件的情景层、用于稳定知识的语义层,以及用于主题级模式的抽象层。记忆构建与重构流水线的详细拆解请参阅架构概览。
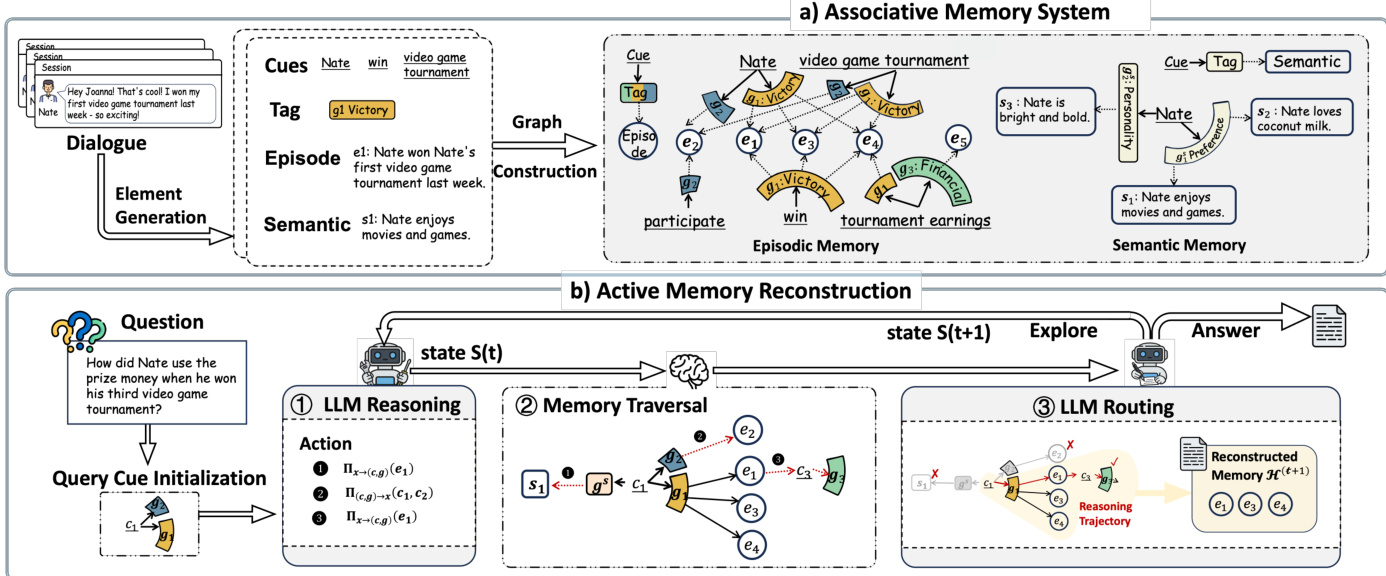
记忆访问被形式化为迭代重构过程,维护显式状态,包含候选节点活跃集与累积证据上下文。在每一步,大语言模型基于当前状态进行推理以选择遍历动作,包括沿线索-标签-内容关系的前向扩展,以及从检索内容激活新线索的反向遍历。模型随后执行这些动作生成候选集,接着进入 LLM 引导的路由步骤,剪枝无关分支并更新重构状态。该闭环机制使 agent 能够基于中间证据动态调整推理轨迹。
该过程的逐步执行详见配套算法。给定查询,系统通过将细粒度线索与记忆图谱匹配来初始化活跃集。agent 随后进入循环,选择遍历动作,应用受控记忆遍历以扩展候选集,并执行路由以更新活跃集与累积上下文。下图展示了此迭代重构的具体示例,说明 agent 如何在多轮推理中逐步收集证据以回答复杂的多跳查询。

该过程的数学公式将步骤 t 的重构状态定义为活跃集与重构上下文的二元组。活跃集作为下一步遍历的候选项,而上下文则约束后续方向。agent 基于状态依赖函数选择子集遍历动作,应用相应运算符生成新候选项,并通过评估语义关联的路由函数更新状态。此迭代过程持续至满足停止条件或达到最大步数限制,此时累积上下文用于生成最终答案。
实验
对于每个问题 i,设 Ei∗ 表示标注的真实证据项集合,E^i 表示 agent 检索到的证据项集合。证据召回率计算如下:
Recall=N1i=1∑N∣Ei∗∣∣E^i∩Ei∗∣,其中 N 为评估问题总数。该指标反映检索过程在恢复相关支持证据方面的有效性,与最终答案生成无关。
- D.4. Implementation
研究使用 GPT-4o-mini 作为 LLM judge,温度参数设为 0.0。每种方法独立评估三次,研究报告各次运行中 judge 得分的均值与标准差。为确保各方法计算预算可比,研究将 agent 的推理轮次限制为每查询最多 8 轮,并允许每轮最多调用 10 次工具。若预算耗尽前满足停止条件,agent 可提前终止。
- D.5. Detailed Results on LONGMEMEVAL
下表展示不同评估设置下 LONGMEMEVAL 的详细结果,评估指标为 F1 与 LLM-Judge。
- D.6. Budget Sensitivity Analysis of Multi-step Reconstruction
下图分析 LoCoMo 多跳问题中推理轮次与每轮并行检索之间的权衡。研究调整每轮检索预算(K),即单轮推理中允许的最大并行工具调用数,以及最大推理轮次(T),同时保持其他设置固定。
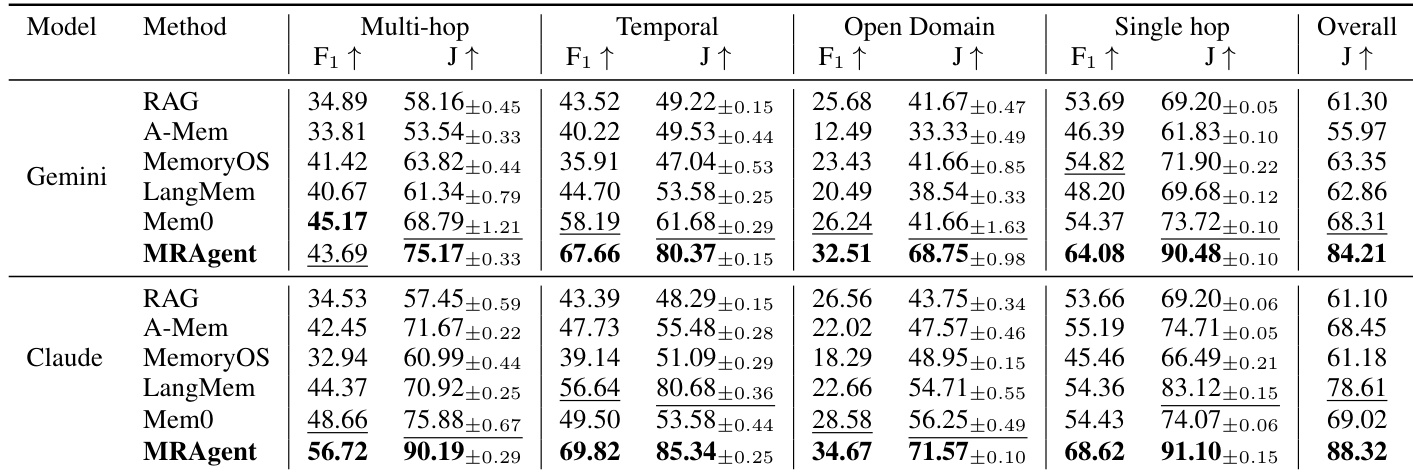
下表。LONGMEMEVAL 评估性能,指标为 F1 与 LLM-Judge ↑。Gemini-backbone 方法中的最佳与次佳结果分别以 粗体 和下划线标记。MRAgent* 使用 Claude 进行检索,记忆由 Gemini 构建。

下图。在 Claude backbone 上使用 LLM-Judge (J) 评估的 LOCOMO 多跳查询性能,作为推理轮次(T)与每轮检索预算(K)的函数。
重构深度无法通过增加并行探索来替代。随着推理轮次 T 增加,所有 K 值下的准确率均稳步且单调提升,更深层次的重构带来显著更高的性能。相比之下,增加每轮检索预算 K 仅带来有限增益且迅速饱和。结果表明,尽管并行探索增加了单轮推理内的检索广度,但无法替代多轮重构所支持的证据顺序组合。
- D.7. Evidence Coverage by Retrieval Operators
为分析不同检索算子对记忆重构的贡献,研究按问题类别聚合统计了各工具在 LoCoMo 上的证据覆盖率。下表报告了各独立算子的覆盖率,反映其在重构期间的功能角色。
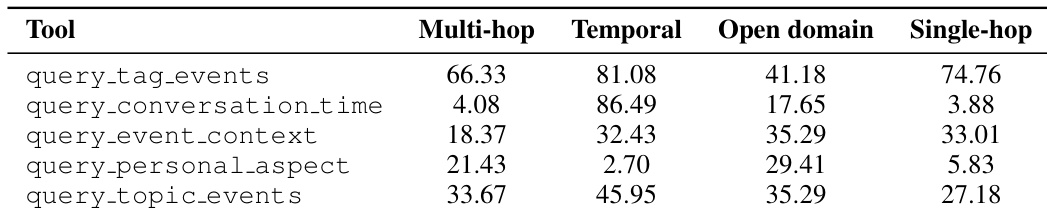
不同检索算子专用于不同的查询结构。时间类问题主要通过 query_conversation_time 解决,该算子承担了大部分基于时间的证据。多跳问题高度依赖 query_tag_events 与 query_topic_events,表明对标签和主题进行关联扩展对于恢复跨多情景分布的证据至关重要。相比之下,开放域问题在多个算子间表现出更均衡的覆盖,反映整合情景、语义与上下文信息的需求。总体而言,结果表明 MRAgent 执行结构化且依赖算子的记忆重构。agent 不依赖均匀或相似度驱动的检索,而是根据查询结构选择性激活不同算子,形成差异化的证据获取模式。
下表展示了不同检索算子在各类问题中的证据覆盖率。结果表明检索策略具有专业性,时间类查询高度依赖时间工具。相比之下,开放域问题更均衡地利用多个算子以整合多样信息。时间类查询主要由时间检索算子处理,在该类别中覆盖率最高。多跳问题严重依赖标签与主题事件查询等关联工具以恢复分布证据。与其他查询类型观察到的专业模式相比,开放域问题在检索算子使用上呈现更均匀的分布。
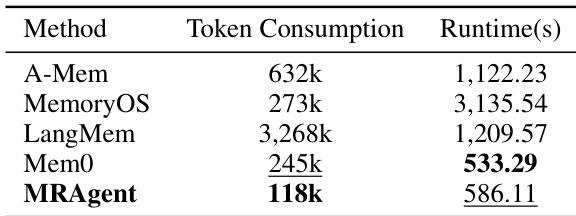
下表对比了 MRAgent 与多项记忆增强基线在 LONGMEMEVAL 基准上的计算成本,具体为 token 消耗与运行时间。MRAgent 展现出更优的信息效率,所需 token 数量最低,且与大多数现有方法相比保持具竞争力的执行速度。在所有对比方法中,MRAgent 的 token 消耗最低,显著降低了记忆访问所需的提示词规模。该方法运行时间显著短于 MemoryOS 与 LangMem,表明其具备复杂推理能力时仍能快速执行。此效率归功于轻量级记忆构建阶段与剪枝无关路径的选择性检索,区别于反复总结历史的基线方法。
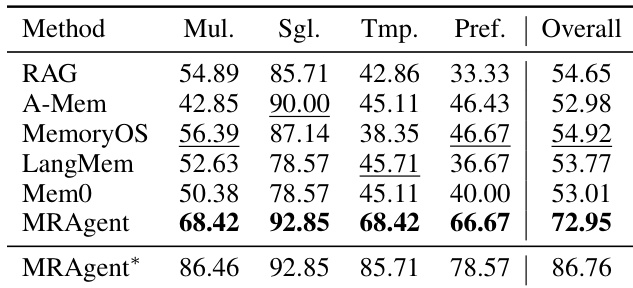
研究在 LONGMEMEVAL 基准上评估 MRAgent,并与 RAG、A-Mem、MemoryOS、LangMem 与 Mem0 等基线对比。结果表明 MRAgent 在多会话、单会话、时间推理与偏好查询等所有问题类型上持续超越竞争对手。此外,MRAgent* 变体在所有指标上均取得最高性能得分。MRAgent 在所有评估类别的主要基线中取得最佳结果。MRAgent* 变体在多会话、时间推理与偏好任务中斩获最高分。MRAgent 与 MRAgent* 在单会话用户查询方面均展现出优于其他方法的能力。
研究分析不同查询类型所需的平均推理轮次,以评估多轮记忆重构的效率。结果表明查询复杂度与所需推理深度相关,与其他更简单类别相比,多跳问题需要最多的迭代步骤才能收敛。多跳查询在测试类别中需要最高的平均推理轮次。单跳查询显示最低的平均推理轮次,表明检索路径更简单。开放域查询平均所需轮次多于时间类查询。
研究在 LoCoMo 基准上使用 Gemini 与 Claude backbones 对比评估 MRAgent 与代表性记忆增强基线。结果表明 MRAgent 在多跳、时间、开放域与单跳查询等各类问题中持续取得优越性能,整体得分显著优于现有方法。MRAgent 在不同问题类别与 LLM backbones 中持续取得最高性能得分,相比基线方法表现突出。该方法在整体评估指标上展现显著相对提升,尤其在需要多跳推理的复杂查询中表现优异。性能增益归因于 Cue-Tag-Content 记忆结构与多轮推理,支持更有效的证据检索与语义引导。
在 LONGMEMEVAL 与 LoCoMo 基准上对比多项记忆增强基线与 LLM backbones 的评估实验,验证了 MRAgent 的检索效率、推理动态与整体性能。对证据覆盖与推理深度的分析表明,查询复杂度直接决定检索专业化程度与迭代步骤,时间类、多跳与开放域问题需要不同的算子分布与收敛路径。计算评估表明,系统通过轻量级记忆构建与选择性检索实现更优的信息效率与更快执行。最终,MRAgent 在所有评估类别中持续超越现有方法,其先进能力主要归功于高效的 Cue-Tag-Content 记忆结构与稳健的多轮推理。