Command Palette
Search for a command to run...
Continual Learning Bench: 评估前沿 AI 系统在真实世界有状态环境中的表现
Continual Learning Bench: 评估前沿 AI 系统在真实世界有状态环境中的表现
Parth Asawa Christopher M. Glaze Gabriel Orlanski Ramya Ramakrishnan Benji Xu Asim Biswal Vincent Sunn Chen Frederic Sala Matei Zaharia Joseph E. Gonzalez
摘要
持续学习(Continual learning)是指人工智能系统通过顺序经验不断优化的能力,这一方向已引发广泛关注,但目前尚缺乏高质量的评价基准。为此,我们推出了持续学习基准(CL-BENCH),这是首个经过专家验证、具有高难度的基准测试,旨在评估基于大语言模型(LLM)的系统是否真正能够从经验中获得提升。CL-BENCH 涵盖六个多样化的领域:软件工程、信号处理、疾病爆发预测、数据库查询、策略性游戏博弈以及需求预测。每个领域均经过专家验证,且任务设计具有可学习的潜在结构(如代码库布局、疾病传播动力学、对手策略等)。这些结构对于具备状态维持能力的系统而言,可以在在线学习过程中被逐步发现;而对于无状态系统,则难以捕捉。我们在多种 Agent 架构上对前沿模型进行了评估,架构范围从简单的上下文学习(In-Context Learning, ICL)到专用的记忆系统。为此,我们引入了一项“增益指标”(gain metric),以剥离模型固有先验能力的影响,从而单独衡量持续学习的效果。研究发现,当前系统在持续学习方面仍有显著改进空间:Agent 经常对即时观察结果过拟合,或无法在不同实例间复用知识;而引入专用记忆系统并未解决这一问题。事实上,采用朴素 ICL 的系统性能优于那些专门用于记忆管理的系统。
一句话总结
本文介绍了 Continual Learning Bench,这是一个经过专家验证的基准,涵盖六个不同领域并具有可学习的潜在结构,用于衡量基于大语言模型的系统是否在现实世界的有状态环境中随着经验真正提升,揭示出 agent 经常过拟合即时观察,且 naive 上下文学习优于专用记忆系统。
核心贡献
- Continual Learning Bench (CL-BENCH) 被引入为第一个困难、经过专家验证的基准,旨在衡量基于大语言模型的系统是否真正随着经验在六个不同领域提升。基准内的任务包含可发现的潜在结构,要求有状态系统在线学习,而不是依赖静态预训练知识。
- 引入了一种增益指标,通过衡量具有在线经验的系统与无状态基线之间的性能差异,将真正的学习从先前能力中隔离出来。该指标定义了何时测量的改进反映了环境特定结构的在线学习,而不是静态模型能力。
- 对多种 agent 架构的前沿模型的评估表明,当前系统仍有提升持续学习性能的空间。结果表明,agent 经常过拟合即时观察,且 naive 上下文学习优于专注于记忆管理的系统。
引言
构建能够随序列经验提升的大语言模型系统对于软件工程 agent 和决策支持 agent 等现实世界应用至关重要。现有评估协议依赖召回率或语言建模损失等代理指标,无法验证系统是否真正在线学习环境特定的潜在结构。本文介绍了 Continual Learning Bench (CL-BENCH),用于衡量 AI 系统是否跨越六个不同领域随序列经验提升。其框架利用具有可发现潜在结构和概念漂移的任务,以最小化对预训练知识的依赖,同时定义增益指标以将有状态学习与静态能力隔离开来。
数据集
数据集组成与来源
- 该基准涵盖六个不同领域,包括软件工程、数据库分析、流行病学预测、射频频谱监控、销售预测和策略游戏。
- 数据源自 SWE-bench 和 Amazon Products Metadata 数据集等现实世界仓库,随后经过策划,确保任务包含无法从预训练中恢复的可学习潜在结构。
每个子集的关键细节
- 代码库适配: 包含来自 jazzband/tablib 和 jd/tenacity 仓库的 19 个问题。实例针对超过 600 个字符的问题陈述和 8 到 300 行之间的补丁进行了过滤。
- 数据库探索: 在包含 5 万个 Amazon 产品的 SQLite 数据库上提供 40 个自然语言问题。模式经过混淆,并在序列中途进行迁移。
- 队列研究: 由五个研究块中的 20 个实例组成,每个实例提供一个独特的 SQLite 数据库,具有不同的人口统计变量和编码约定。
- 可利用扑克: 包括在五个阶段针对确定性对手策略的 120 手德州扑克,以测试策略推断。
- 销售预测: 包含 12 个实例,跨越 2027 至 2038 年的预测年份,分布在三个商店位置,具有轮换可见数据。
- 射频频谱监控: 呈现 90 次扫描,其中 agent 使用 IoU 评分报告占用频谱。
模型使用与评估
- 研究使用从开始到结束顺序处理的完整实例计划来评估系统。
- 性能通过标准化增益衡量,以将在线学习与底层模型能力隔离开来。
- 系统与无状态基线进行比较,以确定记忆或状态管理是否随时间提高了效率或准确性。
处理与验证
- 每个任务经过两位作者和两到三位领域专家的审查,以验证真实性和学习潜力。
- 数据转换包括模式混淆、单位修改和注入干扰列,以防止浅层探索。
- 实例被划分为边界和内部变体集,以分析概念切换时的适应性。
方法
研究建立了严格的基准构建协议,以确保任务有效衡量学习能力。请参阅工作流图了解三阶段过程。该管道始于任务设计,聚焦于领域和实例序列。随后进行专家验证,小组验证诸如提升空间、共享结构和学习机制等标准。最后,决策阶段基于真实性、可重用性和改进的三轴评级将任务分类为拒绝、优化或接受。
为了量化学习,研究引入了区分有状态和无状态系统的比较框架。请参阅持续学习系统图。无状态基线独立处理每个实例 xt,定义为 πt=π(xt)。相比之下,有状态系统以完整历史 Ht−1 为条件,使其能够积累知识。核心指标 Gain 隔离了该累积状态的价值。它计算为有状态系统 rtsf 和无状态基线 rtsl 为每个实例获得的奖励之差,在任务计划上聚合为 g=∑t=1N(rtsf−rtsl)。
该框架的实际动态在 agent 交互循环中可视化。请参阅显示 agent 生命周期的框架图。在冷启动阶段 (Q1) 期间,agent 必须从零开始探索环境,利用查询发现模式细节。随着 agent 积累过去经验 (Q10),它利用已知结构更有效地回答问题,需要更少的查询。然而,系统还必须处理概念漂移,例如数据库迁移 (Q25)。在此阶段,之前学习的信息变得过时,例如由于列重命名,盲目重用过去经验会导致失败。agent 必须检测此漂移并丢弃过时知识以重新探索,证明自适应记忆管理的必要性。
最后,研究分解了标准化增益以分析稳定性 - 可塑性权衡。这涉及将增益分离为稳定性组件,衡量跨变体保留有用结构的能力,以及可塑性组件,衡量变体内对新信息的适应性。这种分解允许对系统平衡保留旧知识与学习新模式的能力进行细粒度评估。
实验
本研究介绍了 CL-BENCH,这是一个跨越六个现实世界领域的基准,旨在评估前沿语言模型如何在各种 agent 架构中随序列经验提升。比较全上下文上下文学习与专用记忆系统的实验表明,简单的上下文保留通常在性能和成本效率方面优于专用持续学习机制。尽管学习动态因任务而有显著差异,但结果表明,可靠的在线适应仍然是一个开放性问题,因为专用记忆系统通常无法证明其计算成本的合理性。
研究在 CL-BENCH 基准上评估了各种持续学习 agent 架构的前沿语言模型。结果表明,全上下文上下文学习 (ICL) 充当强基线,在learning gain 和成本效率方面经常优于专用记忆系统如 ACE。虽然 ACE 系统实现了最高的累积奖励,但与此表现最佳的 ICL 配置相比,其财务成本显著更高。全上下文 ICL 配置在累积增益方面一致排名靠前,经常优于专用记忆机制。ACE 系统实现了最高的累积奖励,但在评估系统中招致了最高的财务成本。包括使用 Codex 和 Gemini 模型在内的几种配置表现出负的累积增益,表明未能优于无状态基线。
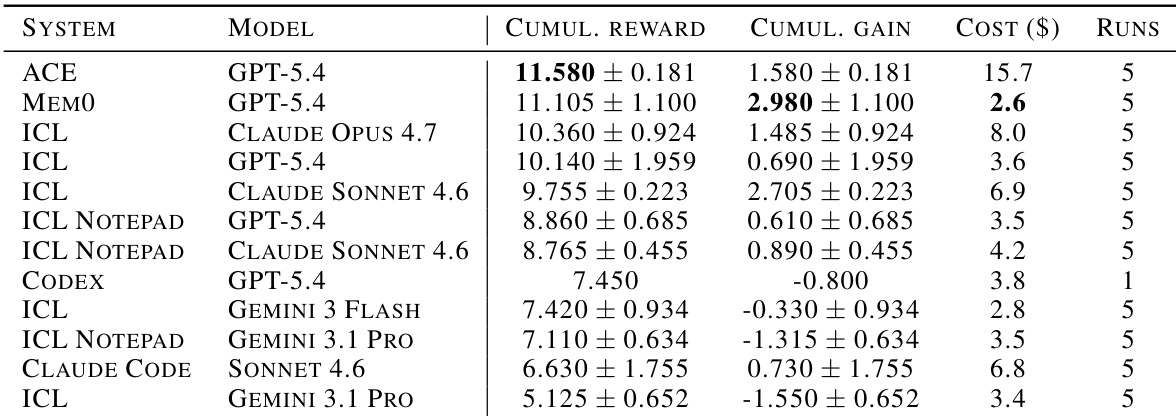
研究使用不同的 agent 架构评估前沿语言模型,以评估其持续学习能力。发现表明,naive 上下文学习充当稳健基线,在奖励和成本效率方面经常优于专用记忆机制。虽然 ICL Notepad 等专用系统实现了显著的学习增益,但它们在绝对性能指标方面经常落后于全上下文 ICL。全上下文 ICL 配置在所有测试的系统 - 模型对中一致获得最高的累积奖励。专用记忆系统招致实质更高的运营成本,而未实现成比例更高的性能增益。ICL Notepad 实现了最高的累积增益,表明尽管总体奖励分数较低,但对序列经验具有很强的适应性。
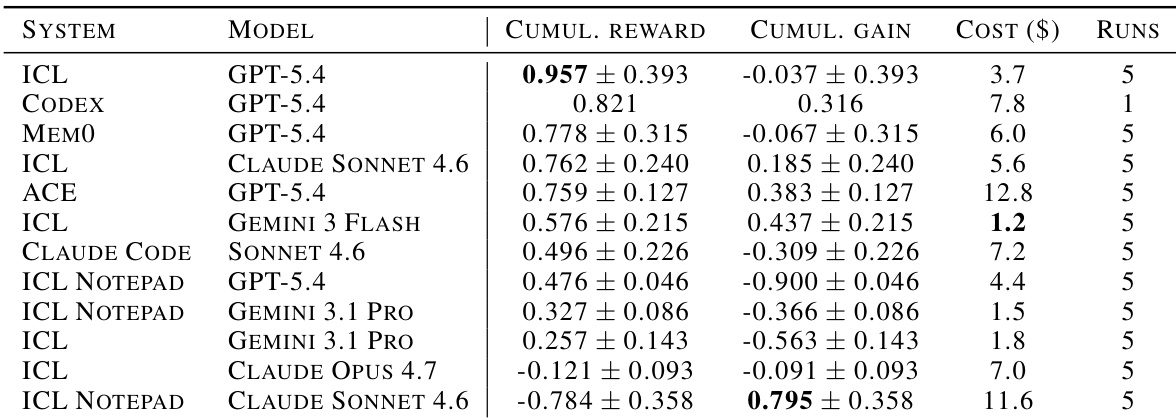
研究在 CL-BENCH 基准上评估各种前沿语言模型和 agent 架构,以评估持续学习能力。结果表明,全上下文上下文学习 (ICL) 充当强基线,其中 Claude Sonnet 4.6 模型在所有测试配置中实现了领先的聚合奖励和增益。相比之下,专用记忆系统如 ACE 和 ICL Notepad 通常相对于其更高的计算成本表现不佳,或未能匹敌简单上下文保留的有效性。使用 Claude Sonnet 4.6 的全上下文 ICL 在基准任务中实现了顶级累积奖励和增益。专用记忆系统如 ACE 招致显著更高的成本,而未将费用转化为成比例更高的性能增益。ICL 变体主导成本效率前沿,在奖励和经济效率方面优于复杂 agent 记忆机制。
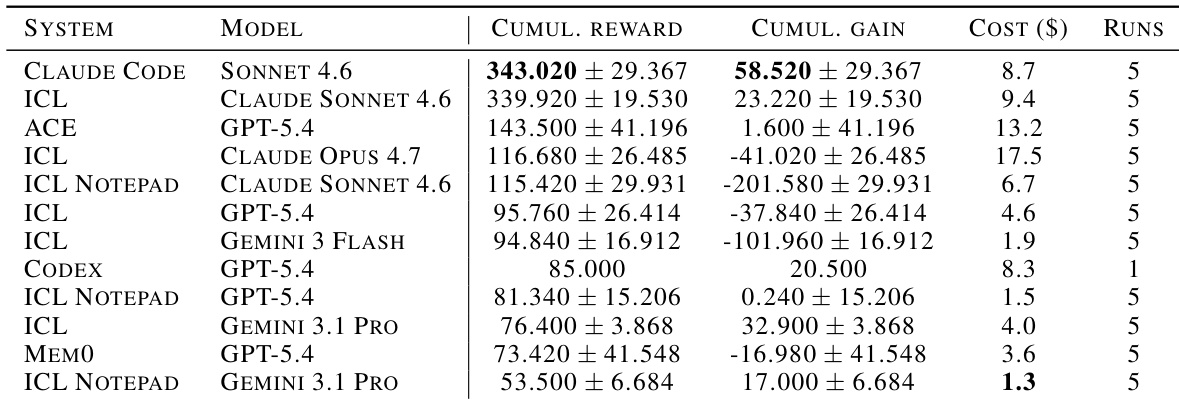
研究评估配备各种持续学习架构的前沿语言模型,发现全上下文上下文学习 (ICL) 充当强基线。结果表明,基于 ICL 的系统经常占据累积增益的顶部位置,而专用记忆系统经常为较低的相对性能招致更高的成本。基于 ICL 的系统在累积增益方面一致排名靠前,证明全上下文保留的有效性。成本效率分析表明,ICL 变体优于专用记忆系统如 ACE,后者为较低增益招致高成本。简单的上下文保留机制被证明比结构化记忆范式如 ICL Notepad 更有效,后者尽管具有相似的模型骨干但显示较低的奖励。
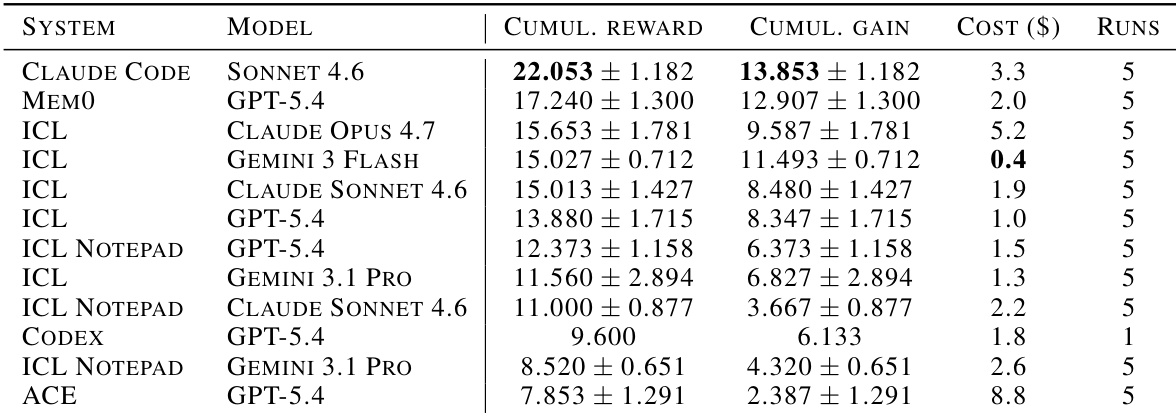
研究在持续学习基准上评估配备各种 agent 架构的前沿语言模型,以评估其随序列经验提升的能力。结果表明,上下文学习 (ICL) 及其变体与专用记忆系统如 ACE 或 Mem0 相比,一致实现最高的累积奖励和增益。此外,ICL 配置显示出优越的成本效率,其中 Gemini Flash 变体在保持强性能的同时提供最低成本。ICL 和 ICL Notepad 配置在评估中占据累积奖励和增益的顶部位置。专用记忆系统如 ACE 和 Codex 相对于其运营成本显示出较低的性能。使用 Gemini Flash 的 ICL 配置在所有测试系统中提供最佳成本效率。
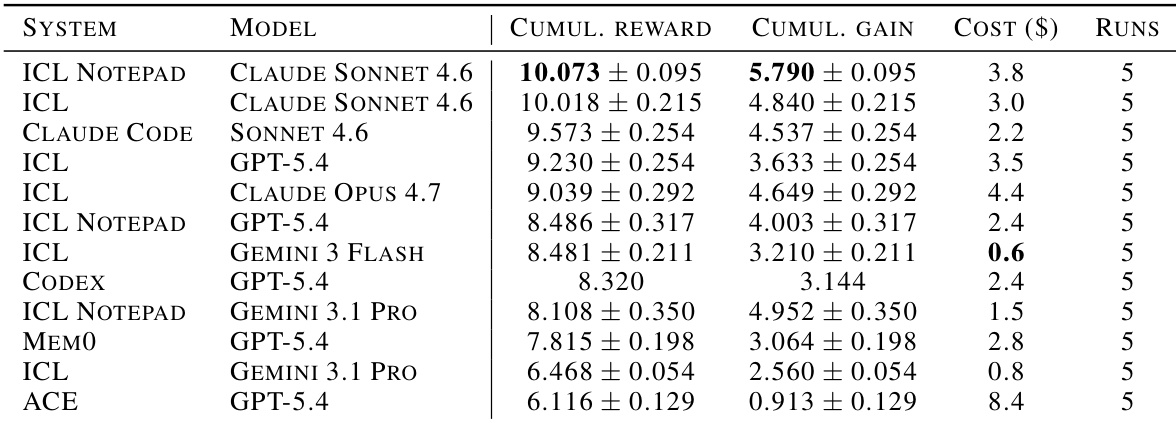
研究在 CL-BENCH 基准上评估各种持续学习 agent 架构的前沿语言模型,以验证其序列改进能力。结果表明,全上下文上下文学习充当强基线,在学习增益和成本效率方面经常优于专用记忆系统。尽管专用系统实现了高奖励,但招致显著更高的财务成本,而未交付成比例更高的性能增益。