Command Palette
Search for a command to run...
音频交互模型
音频交互模型
摘要
音频是一种本质上具有交互性的模态,然而当今的大音频语言模型(LALMs)均为离线运行,而流式音频模型各自仅处理单一任务,例如流式语音识别(ASR)或语音聊天。是时候将它们统一为一个在线LALM了:该模型通过持续运行的感知-决策-响应循环,实时聆听声音、环境及指令,并即时做出反应。我们将此范式形式化为音频交互模型(Audio Interaction Model),并通过Audio-Interaction实现该模型。Audio-Interaction是一个统一的流式模型,在保留离线任务执行能力的同时,增加了在线通用音频指令遵循能力,涵盖从对话到完整语音聊天的场景,并能根据流数据的语义决定响应时机。为实现这一目标,我们提出了SoundFlow框架,该框架通过流式原生数据构建、理解感知训练以及用于稳定实时交互的异步低延迟推理,端到端地实现了感知-决策-响应循环,贯穿数据、训练与部署全流程。我们进一步构建了StreamAudio-2M,这是一个包含260万条样本的流式语料库,涵盖7项基础能力和28个子任务;同时构建了Proactive-Sound-Bench,用于评估主动式音频干预能力。在8个基准测试中,Audio-Interaction在主流音频任务上保持了具有竞争力的性能,同时解锁了离线LALMs无法实现的能力,包括实时ASR、流式音频指令遵循以及主动辅助。
一句话总结
作者提出了 AUDIO INTERACTION MODEL(实例化为 AUDIO-INTERACTION),该模型通过 SOUNDFLOW 框架将离线和单任务流式音频系统统一为实时的“感知-决策-响应”循环。该模型在 STREAMAUDIO-2M 语料库上进行训练,并使用 PROACTIVE-SOUND-BENCH 进行评估,旨在实现低延迟的主动音频干预与统一的语音交互。
核心贡献
- AUDIO-INTERACTION 规范了音频交互模型范式,在执行传统离线任务的同时,同步进行实时在线指令遵循与语音对话,并根据输入音频流的语义动态决定响应时机。
- SOUNDFLOW 实现了持续运行的“感知-决策-响应”循环,通过流式原生数据构建、感知驱动训练以及异步低延迟推理,保障了稳定的实时部署。
- STREAMAUDIO-2M 提供了包含 260 万条样本的流式语料库,涵盖七项核心能力与 28 个子任务,并辅以 PROACTIVE-SOUND-BENCH 用于评估主动音频干预能力。在八个基准上的实验表明,该模型在标准任务上表现具有竞争力,同时支持长流交互与主动辅助。
引言
音频本质上是一种连续、实时的模态,但当前的大规模音频语言模型采用离线批处理方式,需等待完整录音结束后才会生成回复。这种架构上的不匹配限制了其在常驻型应用中的部署,此类应用要求系统同时监控环境、遵循动态指令并与用户进行自然交互。先前的流式方法试图弥补这一差距,但仍局限于狭窄的、特定任务的处理流程,无法联合处理声学上下文、环境音与用户提示,也无法动态决定干预时机。作者通过引入音频交互模型(Audio Interaction Model)来解决这些局限。该模型采用统一的流式架构,通过连续的感知、决策与响应循环,以固定块的形式处理音频。通过部署 SOUNDFLOW 框架以实现流式原生数据构建、感知驱动训练与异步低延迟推理,单个模型即可在保持基准性能的同时,并行执行传统音频任务、实时指令遵循与主动辅助。
数据集
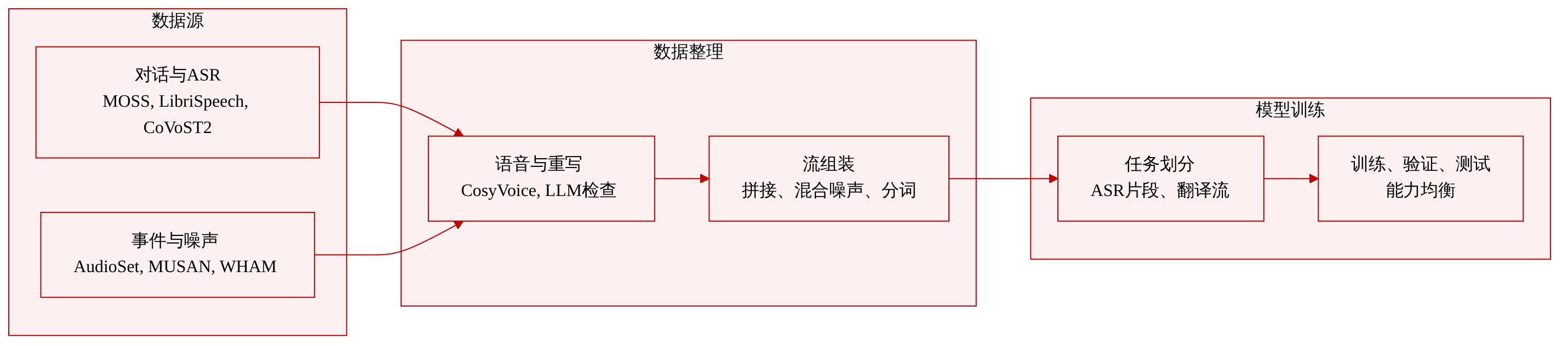
-
数据集构成与来源
- 作者提出了 StreamAudio-2M,这是一个专为连续音频交互设计的大规模流式原生语料库。它涵盖七项核心能力类别与二十八个子任务,总计约 260 万条样本及 30.2 万小时音频。每个样本代表一个包含 3 至 15 轮交互的异构对话,其中交织着各类事件,并包含稀疏且依赖上下文的响应提示。
-
子集详情与规模
- 对话与语言: MOSS 提供了最大规模的数据块,将 39.2 万条文本实例转换为约 4900 小时的多角色语音。
- 语音识别与翻译: LibriSpeech、CommonVoice 和 GigaSpeech 提供识别数据,CoVoST2 和 AISHELL 提供双向英中翻译对。
- 声学事件: 作者将真实的 AudioSet 录音与 AudioX 和 ElevenLabs 生成的合成片段相结合,以覆盖罕见的安全关键声音,共生成约 17.1 万条事件片段。
- 背景噪声: MUSAN、WHAM! 和 DNS-Challenge 贡献了约 620 小时的环境音频,仅用于声学条件训练。
-
数据处理与构建
- 文本源通过多角色 CosyVoice 模型转换为语音,随后利用大语言模型进行重写与语音识别验证,以确保符合自然的口语表达。
- 严格的口语风格重写器通过移除 Markdown 标记、扩展数字与缩写、替换符号来规范化文本,同时保留原始语义与语气。
- 验证后的序列被拼接为多轮流式格式,并混合双轨背景噪声,信噪比经过严格控制。
- 最终语料库被分词为标准输入与标签对,用于模型训练。
-
使用、裁剪与元数据策略
- 作者按能力类别划分数据集,并设定特定任务比例,以在训练期间平衡流式交互、主动响应与连续理解。
- 针对语音识别监督,LibriSpeech 被重新分割为 400 毫秒的块,以便在聆听阶段而非语句边界处提供识别目标。
- 翻译数据同时以原生离线格式和拼接的连续流形式使用,用于训练同传能力。
- 问答任务的参考答案被严格限制在至少三轮之前出现,不得从近期上下文中推断得出,且表述为自然、基于实体的用户查询,不包含引导性提示。
方法
作者利用统一的流式架构,弥合了传统离线音频语言模型与实时交互场景之间的差距。该框架命名为 AUDIO-INTERACTION,基于连续的音频块流运行,能够自主决策保持沉默或生成回复。在每一个时间步 t,模型接收当前音频块 at,并基于历史状态 a<t,d<t,r<t 预测流式干预决策 dt 与回复 rt。这一感知-决策-响应循环构成了系统的核心,使模型能够执行语音翻译、同传、对话与主动辅助等多种实时任务。如图所示,该架构集成了音频编码器、适配器与语言模型,其中适配器负责将分块声学表示映射至语言模型的隐空间。模型是否响应的决策由特殊 token <response> 控制,该 token 触发自回归回复生成;而 <silent> 则表示继续聆听。该设计使模型能够在实时语音交互中联合学习响应时机与生成内容。
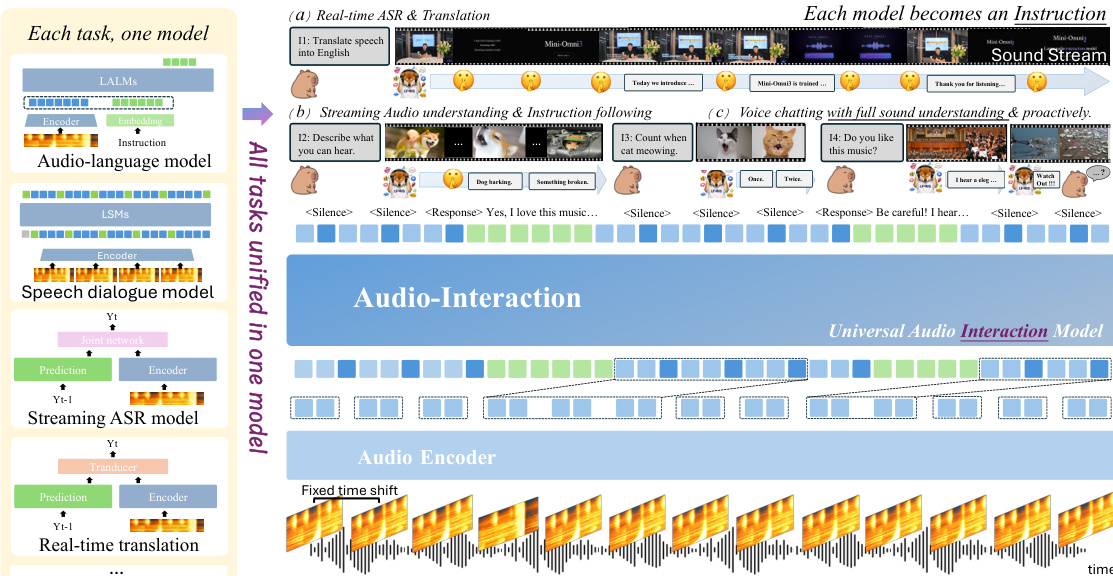
训练流程通过多阶段流水线设计,以支持该流式范式。模型基于紧凑高效的语言模型 Qwen2.5-Omni-3B 进行初始化,并采用双损失目标进行优化,将标准语言建模与专用的流式控制 token 预测相结合。总体损失定义为 L=N1∑j=1N(−logPθ(tj∣Hj)+λ(−logPθ(sj∣Hj))),其中第一项监督文本 token 的生成,第二项由 λ 加权,旨在预测流式控制 token sj。该双目标确保模型同时学习回复内容与生成时机。训练流水线包含四个阶段:格式训练用于教授模型序列格式及 <Spe_token> 的使用;适配器训练用于将声学特征映射至语言模型空间;针对音频理解与对话等核心能力的大规模流式监督训练;以及针对连续辅助与主动响应等复杂行为遵循指令的微调。这种分阶段方法使模型能够逐步构建实时交互所需的核心技能。
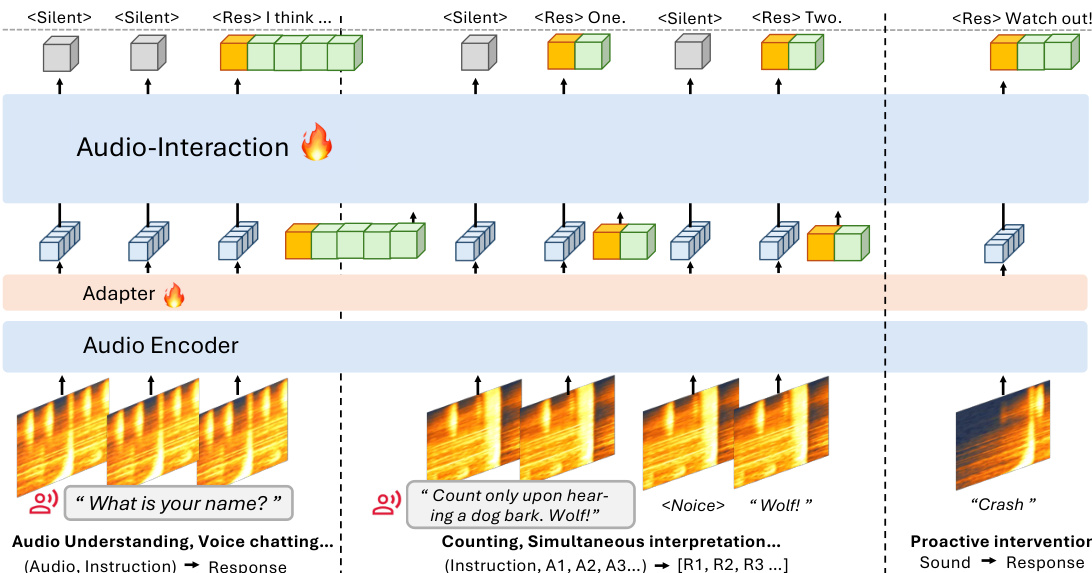
为确保模型在真实场景中的鲁棒性,训练数据经过精心构建,以应对两个关键失效模式:上下文保留不足与误触发。框架采用分层事件策展流水线,以生成长篇连贯的流式音频数据。该流程始于场景规划,大语言模型根据随机匹配的音频标注生成高层叙事,确保事件间的语义一致性。随后,每个主题被细化为具体的音频事件,片段通过检索或生成获取,并验证其合理性与连贯性。数据进一步通过时频联合预处理(TFJP)模块进行处理,该模块通过迭代移除静音、估计并扣除背景噪声、细化信息内容边界来平滑音频片段。此预处理确保音频对齐良好,适用于下游流式任务。最终生成的数据集 StreamAudio-2M 旨在覆盖 28 个子任务中的七项核心能力,为模型训练提供全面基础。

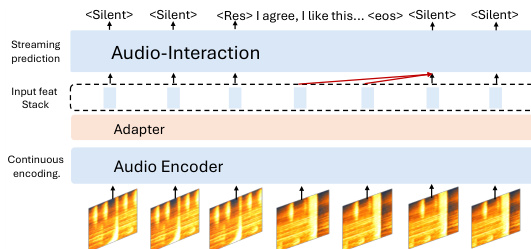
模型的部署通过带先进先出(FIFO)调度的异步推理方案进行管理,以缓解等待冲突并确保低延迟性能。如图所示,音频编码器持续处理传入的块,并将其声学表示追加至按时间排序的队列中。解码器独立运行,并根据最后生成的 token 进行条件触发。当模型输出 或 token 时,队列将被清空,确保解码器的上下文与最新音频输入对齐。该方法消除了推理停滞,并降低了响应后恢复聆听的首帧延迟。系统在 PROACTIVESOUND-BENCH 中使用大量经 agent 验证的静音音频,进一步增强了维持稳定且响应迅速交互的能力,帮助模型学习在非必要干预时保持沉默。强大的训练框架与高效的推理调度相结合,使模型能够有效执行复杂的实时音频交互。
实验
评估框架在全面的音频理解、语音对话与语音处理基准上进行模型测试,并辅以针对流式主动响应与真实声学环境的专项测试。这些实验共同验证了原生流式训练在保留离线理解能力的同时,实现了低延迟且感知上下文的干预,且对声学噪声与长音频拼接保持鲁棒。消融实验进一步证实,异步推理调度与平衡的双损失优化等架构决策,对于维持稳定的决策边界及实现准确率与延迟的最优权衡至关重要。最终,模型在未过滤的真实部署场景中展现出强大的泛化能力,证明其流式行为源于真实的声学理解,而非合成训练伪影。
作者在与语音对话和语音基准任务相关的多项测试中,将 AUDIO-INTERACTION 与一系列专用、全模态及流式音频语言模型进行了对比。结果表明,AUDIO-INTERACTION 在关键指标上取得了具有竞争力的性能,尤其在 Web Questions 和 SD-QA 类别中表现突出,且其模型规模小于许多基线模型。尽管模型规模较小,AUDIO-INTERACTION 在 Web Questions 和 SD-QA 基准上仍保持了竞争力的表现。在专用模型中,Freeze-Omni 和 Moshi 在语音对话任务上表现强劲,其中 Freeze-Omni 在多个类别中领先。AUDIO-INTERACTION 模型在语音对话与语音基准上均展现出均衡的性能,表明其在多任务音频交互场景中的有效性。
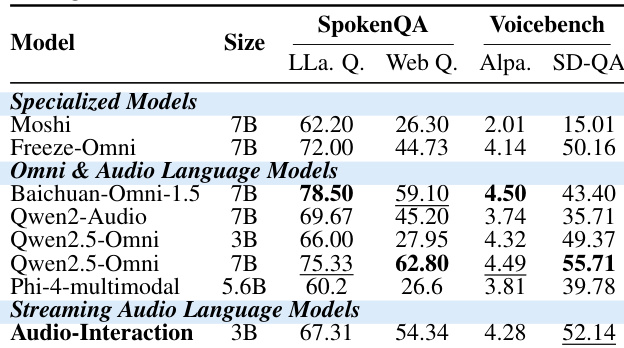
作者分析了不同模型组件在各层与注意力头中针对各项任务(包括语音识别、语音到文本翻译、音频理解与对话)的重要性。热力图显示,特定头与层对某些任务贡献更为显著,且每种任务类型呈现出不同的模式。结果表明,任务特定的注意力机制分布在模型架构的不同部分。不同任务在模型层与注意力头的重要性分布上表现出显著差异。某些头与层对于语音识别、语音到文本翻译、音频理解及对话等特定任务更为关键。任务间的重要性分布差异显著,表明存在专门的注意力机制。
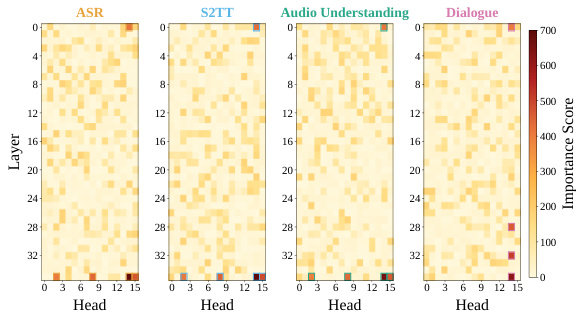
作者在一个主动声音基准上评估了多种音频语言模型的性能,对比了全模态与音频语言模型同流式音频语言模型的表现。结果表明,所提出的 Audio-Interaction 模型在单事件与多事件层级均实现了更高的平均准确率,尤其在 Daily 和 Traffic 类别中表现优异,超越了流式音频语言模型类别中的其他模型。在流式音频语言模型类别的所有模型中,Audio-Interaction 取得了最高的平均准确率。与其他模型相比,Audio-Interaction 在 Daily 和 Traffic 类别中展现出显著的提升。该模型在单事件与多事件层级均保持高性能,表明其具备强大的主动响应能力。
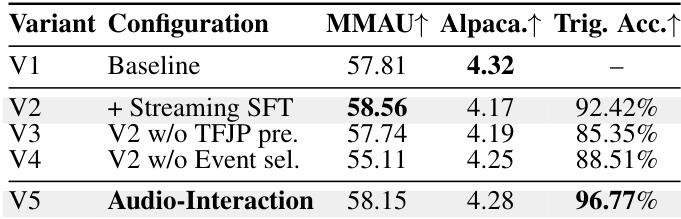
作者进行了消融实验,以评估不同训练组件对模型性能的影响。结果表明,相较于基线,引入流式监督微调提升了音频理解与主动响应准确率。移除特定的预处理或事件选择方法会导致准确率下降,而完整的 Audio-Interaction 配置实现了最高的主动触发准确率。相较于基线,添加流式监督微调同时提升了音频理解与主动响应准确率。移除 TFJP 预处理或事件选择会降低主动触发准确率,印证了它们的重要性。完整的 Audio-Interaction 配置在所有变体中取得了最高的主动触发准确率。
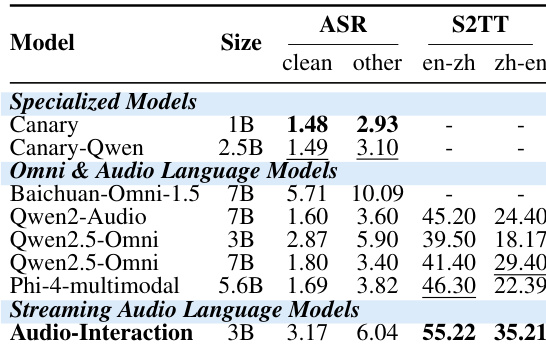
作者将流式音频语言模型 AUDIO-INTERACTION 与专用、全模态及音频语言模型在语音与语音到文本翻译任务上进行了对比评估。结果表明,AUDIO-INTERACTION 在核心语音任务上取得了具有竞争力的性能,尤其在语音到文本翻译方面,且其模型规模小于其他多模态模型。AUDIO-INTERACTION 在语音到文本翻译任务上表现强劲,在英译中与中译英方向均超越了其他模型。与其他多模态模型相比,该模型在保持较小参数规模的同时,依然取得了具有竞争力的结果。与 Canary 和 Canary-Qwen 等专用模型相比,AUDIO-INTERACTION 在语音识别任务上性能有所提升,尤其在 other 类别中。
评估框架在语音对话、主动声音、语音识别与翻译任务上,将 AUDIO-INTERACTION 与专用、全模态及流式音频语言模型进行了基准对比,同时分析了内部注意力分布与训练组件的贡献。定性结果表明,尽管参数量紧凑,该模型在多样化的音频交互场景中均能提供均衡的性能。内部分析显示,不同的层与注意力头专注于不同任务,凸显了高效的任务特定注意力机制。此外,消融实验证实,流式监督微调结合针对性的预处理与事件选择策略,对于最大化主动响应与音频理解能力至关重要。