Command Palette
Search for a command to run...
自蒸馏策略梯度
自蒸馏策略梯度
Yifeng Liu Shiyouan Zhang Yifan Zhang Quanquan Gu
摘要
基于策略的自我蒸馏(On-policy self-distillation)是指语言模型利用特权上下文(privileged context)对其自身生成内容进行监督,这为稀疏奖励强化学习提供了一种极具潜力的密集监督来源。实际上,该方法可以实例化为一种辅助性的全词表(full-vocabulary)学生-教师反向 Kullback-Leibler 散度损失。因此,我们提出了 SDPG,一种自蒸馏策略梯度框架。该框架结合了组相对验证器优势(group-relative verifier advantages)与归一化标准差、精确的全词表在线自我蒸馏,以及参考策略的 KL 正则化。实证结果表明,相较于 RLVR 和自我蒸馏基线方法,SDPG 在稳定性与性能方面均有所提升。
一句话总结
本文提出了 SDPG,一种自蒸馏策略梯度框架,结合了组相对验证器优势、归一化标准差、通过辅助学生到教师反向 Kullback-Leibler 散度损失实现的精确全词汇在线策略自蒸馏,以及参考策略 KL 正则化,旨在提高稀疏奖励强化学习中相对于 RLVR 和自蒸馏基线的稳定性和性能。
核心贡献
- 本文介绍了 SDPG,一种利用在线策略自蒸馏为稀疏奖励强化学习提供密集监督的自蒸馏策略梯度框架。
- 该方法结合了组相对验证器优势与归一化标准差、精确全词汇在线策略自蒸馏以及参考策略 KL 正则化。
- 实证评估表明,该框架在稳定性和性能方面优于 RLVR 和现有的自蒸馏基线。
引言
具有可验证奖励的强化学习使大型语言模型能够在不依赖人类偏好标注的情况下掌握复杂的推理任务。然而,像 GRPO 这样的标准算法在早期阶段面临稀疏序列级奖励和训练不稳定的问题。虽然在线策略蒸馏提供了密集的 token 级信号,但传统方法通过外部教师施加内存负担,或通过纯自蒸馏强化错误轨迹的风险。作者提出了自蒸馏策略梯度,将精确的全词汇特权蒸馏集成到 KL 正则化的策略优化中。该方法结合了来自验证器的稀疏二元结果奖励和来自上下文条件教师的密集蒸馏信号。他们进一步实施了正优势门控等稳定器来控制噪声,并表明该方法优于 GRPO 和自蒸馏基线。
方法
提出的自蒸馏策略梯度(SDPG)框架将在线策略强化学习与精确全词汇自蒸馏相结合,以提高推理任务中的稳定性和性能。整体架构如下图所示,说明了共享策略模型如何与特权上下文交互以生成监督信号。
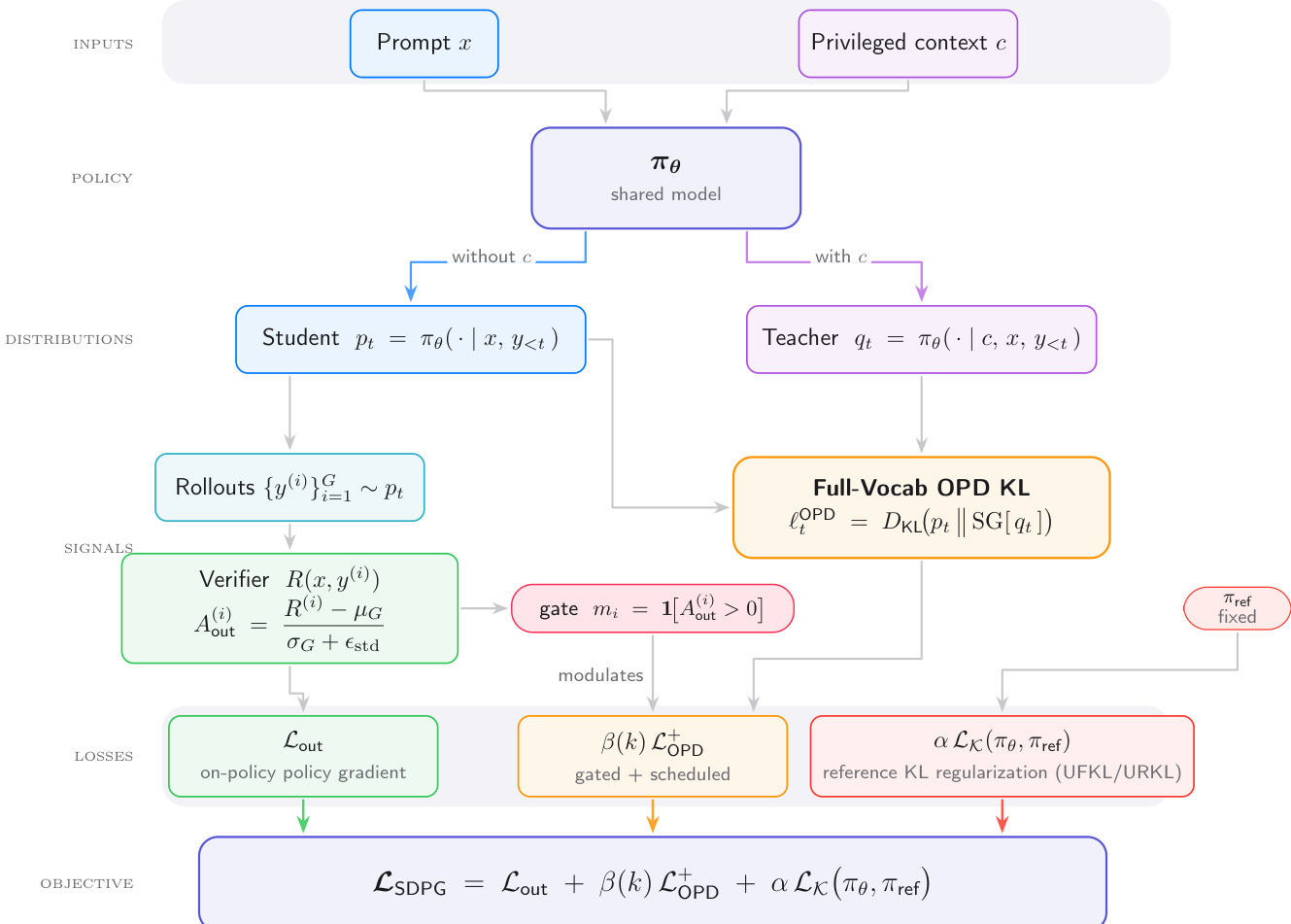
该框架在两个输入上运行:标准提示 x 和特权上下文 c,其中可能包含真实推理轨迹或参考答案。共享模型 πθ 同时充当学生和教师。当仅以 x 为条件时,它定义了学生分布 pt=πθ(⋅∣x,y<t)。当额外以 c 为条件时,它定义了特权教师分布 qt=πθ(⋅∣c,x,y<t)。训练目标结合了三个不同的损失组件:
LSDPG=Lout+β(k)LOPD++αLK(πθ,πref)
第一个组件 Lout 是源自组相对策略优化(GRPO)的在线策略基于奖励的损失。对于一组 G 个采样响应 {y(i)}i=1G,模型计算由验证器奖励 R(x,y(i)) 的均值和标准差归一化的组相对优势 Aout(i)。该术语使用无 PPO 截断的 REINFORCE 风格代理损失来优化策略,依靠验证器来指导探索。
第二个组件 LOPD+ 代表门控全词汇在线策略蒸馏损失。SDPG 不是通过采样 tokens 来近似教师信号,而是最小化学生和教师分布在完整词汇表 V 上的精确反向 Kullback-Leibler 散度:
ℓi,tOPD=DKL(pi,t∥SG[qi,t])=∑a∈Vpi,t(a)logSG[qi,t(a)]pi,t(a)
为了防止特权信号在错误轨迹上与验证器冲突,该损失由二元掩码 mi=1[Aout(i)>0] 进行门控。因此,仅当验证器认可展开为正确时,才会发生蒸馏。
第三个组件 LK 将更新后的策略锚定到固定的参考策略 πref 以防止崩溃。作者采用未归一化 KL(UKL)散度进行此正则化,该散度处理潜在的概率质量不匹配并提供更对称的梯度。支持两种变体:未归一化前向 KL(UFKL)和未归一化反向 KL(URKL)。
为了管理蒸馏信号的影响,系数 β(k) 遵循下图所示的特定计划。
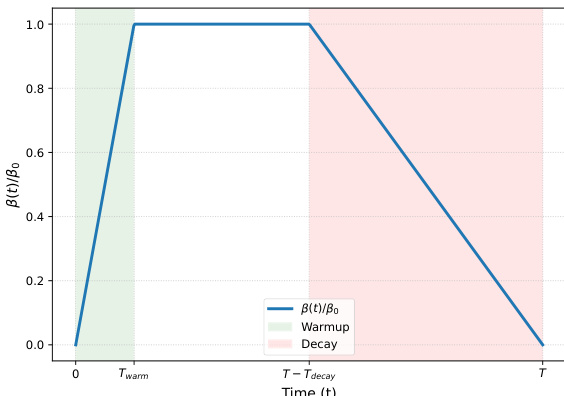
该计划包括一个预热阶段,以便在蒸馏开始之前让策略稳定,随后在训练结束时进入衰减阶段,以鼓励探索并避免用可能嘈杂的特权信号过度约束模型。
特权上下文 c 的注入通过特定的提示工程处理,如下面的教师提示示例所示。

此提示结构包括问题、正确答案和解决步骤的占位符,以及使用严格数学方法推导答案的具体说明,而不明确指出信息来源。这确保教师模型生成高质量的推理轨迹,学生可以在蒸馏阶段学习模仿。
实验
本研究使用 Qwen3 模型在数学推理基准测试中实证评估了提出的 SDPG 框架与 GRPO 和 RLSD 等基线的表现。实验结果表明,SDPG 变体实现了更高的准确性和更快的收敛速度,同时避免了纯自蒸馏方法中观察到的熵崩溃和训练不稳定性。消融研究进一步验证了将全词汇特权蒸馏与策略 KL 正则化相结合对于在不同模型规模下保持连贯的推理模式和稳定性至关重要。
作者使用预训练 LLM 在数学推理任务上实证评估了他们提出的 SDPG 算法与基线的表现。结果显示,在所有基准测试中,两种 SDPG 变体始终比 GRPO 和 RLSD 等基线方法实现更高的性能。SDPG-UFKL 通常获得最高分数,而 SDPG-URKL 在 AIME25 基准测试上表现出最佳性能。两种 SDPG 变体在所有基准测试中始终优于 GRPO 和 RLSD 等基线方法。SDPG-UFKL 在大多数指标上获得最高分数,特别是在 AIME24 和 AMC23 上。SDPG-URKL 专门在 AIME25 基准测试上获得顶级性能。
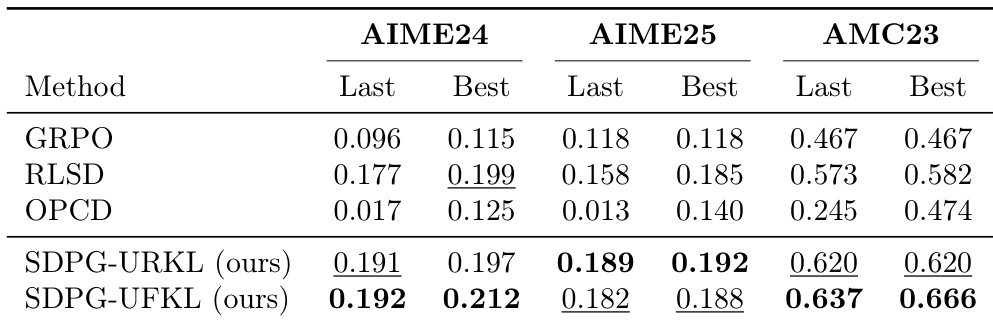
作者在包括 AIME24、AIME25 和 AMC23 在内的数学推理基准测试上评估了他们提出的 SDPG 框架与 GRPO 和 RLSD 等基线的表现。结果表明,两种 SDPG 变体在所有测试数据集上始终优于基线方法。具体来说,SDPG-UFKL 变体在大多数报告的指标中实现了最高性能。两种 SDPG 变体在所有数学推理基准测试中始终优于基线方法。SDPG-UFKL 变体在大多数评估类别中获得了最高性能分数。在 AMC23 基准测试上观察到显著的性能提升,所提出的方法大幅领先于基线。
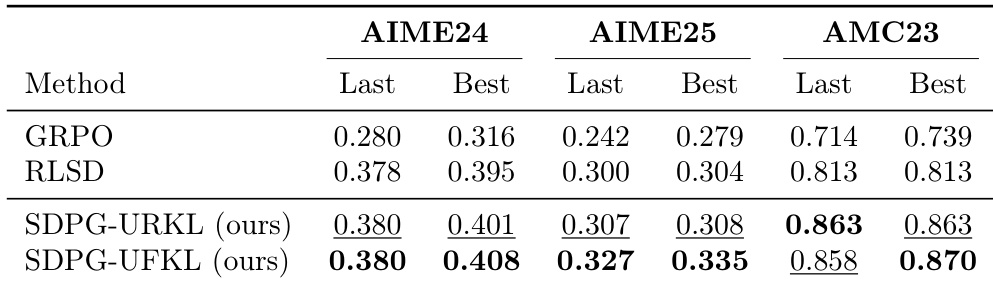
作者使用预训练 LLM 在包括 AIME24、AIME25 和 AMC23 在内的数学推理基准测试上评估了提出的 SDPG 框架与 GRPO 和 RLSD 等基线的表现。两种 SDPG 变体在所有测试数据集上始终优于基线方法,特别是在 AMC23 上观察到显著改进。具体来说,SDPG-UFKL 变体在大多数评估类别中获得了最高性能分数,而 SDPG-URKL 在 AIME25 基准测试上领先。