Command Palette
Search for a command to run...
Qwen-Image-Flash:超越目标设计
Qwen-Image-Flash:超越目标设计
摘要
少步蒸馏已成为加速先进视觉生成模型的有效策略,然而既往研究大多聚焦于蒸馏目标。本文从互补视角重新审视少步蒸馏,重点关注对学生模型性能起关键塑造作用的训练方案。以 Qwen-Image-2.0 为代表性案例,我们系统探究了统一文本到图像生成与指令引导图像编辑蒸馏中的三个关键因素:数据构成、教师指导与任务混合。我们的实证分析揭示了若干非直观现象,这些发现促使我们开发了 Qwen-Image-Flash。总体而言,我们的结果表明,实现高效的少步蒸馏不仅需要精心设计蒸馏目标,还需对更广泛的训练流程进行系统性组织。
一句话总结
Qwen-Image-Flash 通过少步蒸馏加速先进的视觉生成模型,其核心在于优先采用严谨的训练方案而非仅优化目标函数,系统性地优化数据构成、教师模型引导以及任务混合,以实现统一的文本到图像生成与指令驱动的图像编辑。
核心贡献
- 本研究对少步蒸馏中的三个训练流程因素进行了系统的实证调查:数据构成、教师模型引导,以及用于统一文本到图像生成和指令驱动图像编辑的任务混合。
- 基于上述发现,本文提出了 Qwen-Image-Flash,这是一种从 Qwen-Image-2.0 蒸馏而来的统一学生模型,仅需 4 次 NFE 即可提供高质量的生成与编辑能力。
- 实验结果表明,蒸馏模型在两项任务上均达到了教师基础模型的性能水平,证实了有效的少步蒸馏依赖于对整个训练流程的严谨组织。
引言
现代视觉生成模型已演变为强大的基础系统,具备文本到图像合成与指令驱动编辑的能力,但其迭代采样过程带来了高昂的计算成本与延迟,阻碍了其在延迟敏感型应用中的部署。尽管既往研究主要致力于优化蒸馏目标,以将这些多步过程压缩至少步学生模型,但标准训练方案常因师生分布不匹配及数据混合次优而在复杂场景中表现不佳。作者利用这一研究空白,系统分析了数据构成、教师引导与任务混合如何影响蒸馏结果,并引入逐步多教师策略与优化的任务平衡机制。基于这些实证发现,作者开发了 Qwen-Image-Flash,该统一模型仅需四次采样步骤即可实现高保真生成与编辑,证明了稳健的少步蒸馏依赖于整体训练流程,而非仅靠目标函数设计。

数据集

- 数据集构成与来源:作者引入了 T2I-Bench 与 Editing-Bench,用于系统评估少步文本到图像生成及编辑模型。这些基准测试取代了 MS-COCO、GenEval 和 T2I-CompBench 等传统数据集,作者指出这些传统数据集难以充分揭示现代快速采样技术特有的性能退化模式。
- 子集详情:作者构建了包含 1,800 个评估案例的 T2I-Bench,均匀分布在三个类别中,每类分配 600 个样本。Editing-Bench 采用类似结构以评估编辑能力,尽管提供的摘录中未详述具体样本数量。
- 数据使用与处理:作者将这些基准测试作为严格的评估套件而非训练语料库进行部署。研究采用 Gemini 3.1 Pro 和 GPT 5.5 作为基于自动偏好的评估器,对生成图像进行评分。这些模型评估感知质量、视觉保真度以及与人类偏好的对齐程度,分数越高代表输出质量越优。
- 评估重点与处理:作者精心筛选数据集以暴露少步采样中的性能下降问题,重点针对密集文本渲染、结构化布局、提示词遵循度、多样性及细微视觉细节进行评估。评估依赖于预定义的系统提示词与大语言模型驱动的偏好评分,而非 FID 或基于 CLIP 的对齐等传统指标。提供的摘录侧重于基准测试构建与自动评分,而非训练预处理、裁剪或元数据生成。
方法
作者采用流匹配(flow matching)作为学习生成动力学的连续时间框架,该框架通过指定概率路径并学习相应的速度场,来定义数据与噪声之间的传输过程。设 x∼pdata 表示数据点,ϵ∼pnoise 为独立噪声样本,其中 pnoise 通常设为 N(0,I)。沿用既往工作,采用线性路径:
zt=(1−t)x+tϵ,t∈[0,1].
该路径在 t=0 时从数据分布插值至 t=1 时的噪声分布。条件 c 编码标签或文本嵌入等辅助信息。在此插值下,路径上的速度场为 ϵ−x,流匹配通过以下损失函数训练参数化向量场 vθ(zt,t,c) 以预测该速度:
\ell_{\mathrm{FM}}(\pmb{\theta}) = \mathbb{E}_{t, \pmb{x}, \pmb{\epsilon}} \left[ \left\| \pmb{v}_\pmb{\theta}(\pmb{z}_t, t, \pmb{c}) - (\pmb{\epsilon} - \pmb{x}) \right\|^2 \right].
训练完成后,通过从噪声先验初始化 z1,并将学习到的常微分方程(ODE)从 t=1 反向积分至 t=0 来生成样本,最终得到 xθ=z1+∫10vθ(zt,t,c)dt。
为将多步教师模型蒸馏为少步学生模型,作者采用了蒸馏模型蒸馏(DMD)框架。给定输入噪声变量 ϵ 和条件 c,学生模型生成干净样本 xθ=Gθ(ϵ,c)。为在含噪中间状态比较学生与教师模型,需额外采样一个噪声样本 ξ∼pnoise,并将学生样本扰动为 xt=(1−t)xθ+tξ(其中 t∼pt)。DMD 目标函数旨在促使学生模型诱导的条件分布与教师模型对齐,该目标以 KL 散度形式表示:
ℓDMD(θ)≜DKL(pstu(xθ∣c)∥ptea(xθ∣c)).
DMD 并非直接优化该散度,而是采用基于学生与教师模型分数场差异的梯度估计器:
\nabla_{\pmb{\theta}} \ell_{\mathrm{DMD}}(\pmb{\theta}) = \mathbb{E}_{\pmb{\epsilon}, \pmb{\xi}, t} \left[ \left( \nabla_{\pmb{\theta}} x_\pmb{\theta} \right)^\top \left( \pmb{s}_{\mathrm{stu}}(\pmb{x}_t, t, \pmb{c}) - \pmb{s}_{\mathrm{real}}(\pmb{x}_t, t, \pmb{c}) \right) \right].
其中,sstu 利用在学生生成样本上训练的辅助分数网络进行估计,而 sreal 则源自预训练的教师模型。
为在使用具备互补下游能力的多教师模型时稳定蒸馏过程,作者提出了逐步多教师引导策略。该策略不依赖单一固定教师,而是将稳定的基础教师与任务专用教师相结合。在第 k 个选定的蒸馏步骤中,真实分数引导被定义为加权和:
sreal(k)(xt,t,c)=∑m=0Mλk,m(c)sm(k)(xt,t,c),
其中 sm(k) 为第 k 步来自教师 Tm 的真实分数估计值,λk,m(c)∈[0,1] 表示在条件 c 下的贡献权重,满足 ∑m=0Mλk,m(c)=1。该公式在实现基础教师平滑引导的同时,选择性融入任务特定信息。相应的 DMD 目标函数更新为:
\nabla_{\pmb{\theta}} \ell_{\mathrm{DMD}}^{(k)}(\pmb{\theta}) = \mathbb{E}_{\pmb{\epsilon}, \pmb{\xi}, t} \left[ \left( \nabla_{\pmb{\theta}} x_\pmb{\theta} \right)^\intercal \left( \pmb{s}_{\mathrm{stu}}(\pmb{x}_t, t, \pmb{c}) - \sum_{m=0}^{M} \lambda_{k,m}(\pmb{c}) \pmb{s}_m^{(k)}(\pmb{x}_t, t, \pmb{c}) \right) \right].
实验
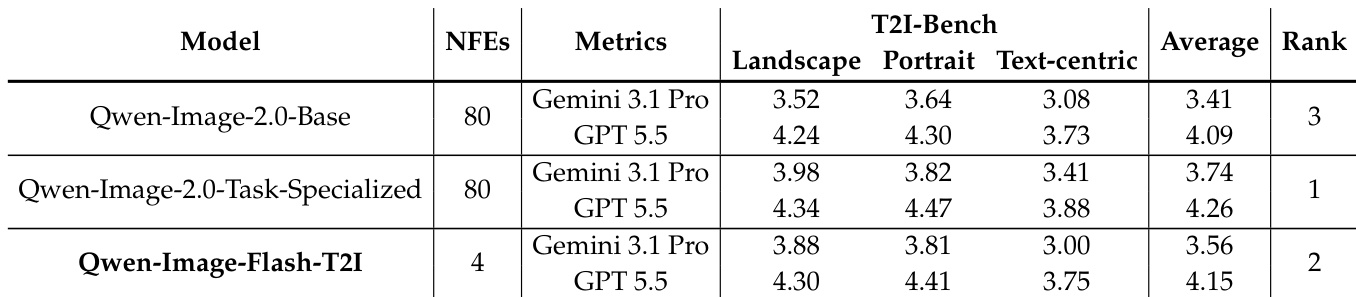
实验通过系统调整训练数据构成、教师模型专业化程度及任务混合比例,对少步文本到图像蒸馏进行评估。定性分析表明,类别单一的连贯训练数据比多样化或直接对齐的数据集具有更好的泛化能力,而依赖任务专用教师会引入优化不稳定与结构错位。此外,联合蒸馏结果表明,平衡的生成与编辑任务混合比例能够最大化指令遵循能力,并通过互补的视觉-文本监督意外提升了整体的文本到图像生成质量。
作者评估了在不同任务混合比例下文本到图像与图像编辑能力的联合蒸馏效果。结果表明,T2I 与编辑数据的平衡混合能够带来最强的编辑性能,同时相比仅使用 T2I 数据的蒸馏,还提升了 T2I 的生成质量。模型性能对比例高度敏感:编辑数据不足会导致编辑行为无法有效迁移,而平衡的比例则能实现高效的指令遵循与视觉质量保障。T2I 与编辑数据的平衡混合达到了最佳编辑性能,并超越了教师模型。编辑监督提升了 T2I 生成质量而非造成退化。编辑数据不足无法迁移编辑行为,而平衡比例则能实现强大的指令遵循与视觉保真度。
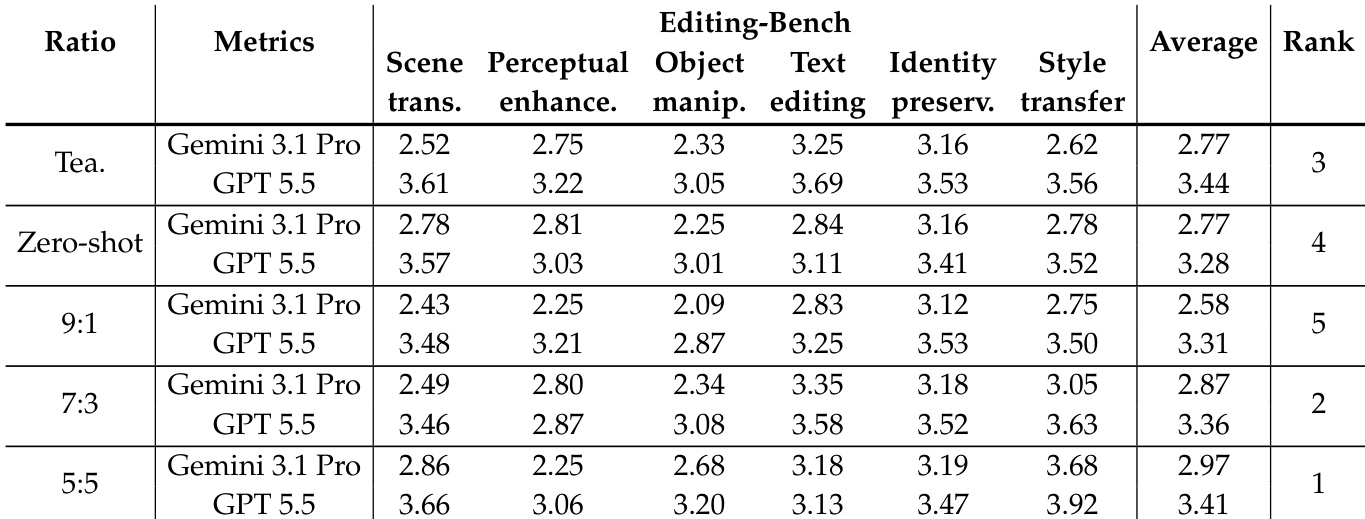
作者在不同模型于 T2I-Bench 上的性能进行了对比,评估了其在风景、人像及文本主导类别中的能力。结果显示,蒸馏得到的 4-NFE 学生模型相比多步教师模型具备竞争力,具体优势因评估指标与类别而异。蒸馏学生模型在 T2I-Bench 各类别中均表现强劲,部分指标结果接近多步教师模型。蒸馏模型在性能上呈现一定权衡,相较于教师模型在某些指标上得分更高,而在其他指标上略低。不同评估指标下的性能差异表明,模型在处理风景、人像及文本主导任务时具备不同的优势。
作者考察了联合 T2I-编辑蒸馏中任务混合构成的影响,重点分析调整文本到图像与编辑数据比例对编辑性能及 T2I 生成质量的作用。结果表明,T2I 与编辑数据的平衡混合能够实现最强的编辑迁移能力,同时提升整体 T2I 生成质量,这说明编辑监督提供了互补信号而非导致性能退化。平衡的 T2I 与编辑数据比例可实现最强的编辑迁移并改善 T2I 生成质量。编辑数据不足会导致监督信号微弱与性能下降,而平衡混合则提供密集且有效的任务特定引导。编辑监督增强了 T2I 生成而非造成退化,表明视觉-文本互补学习具有积极收益。
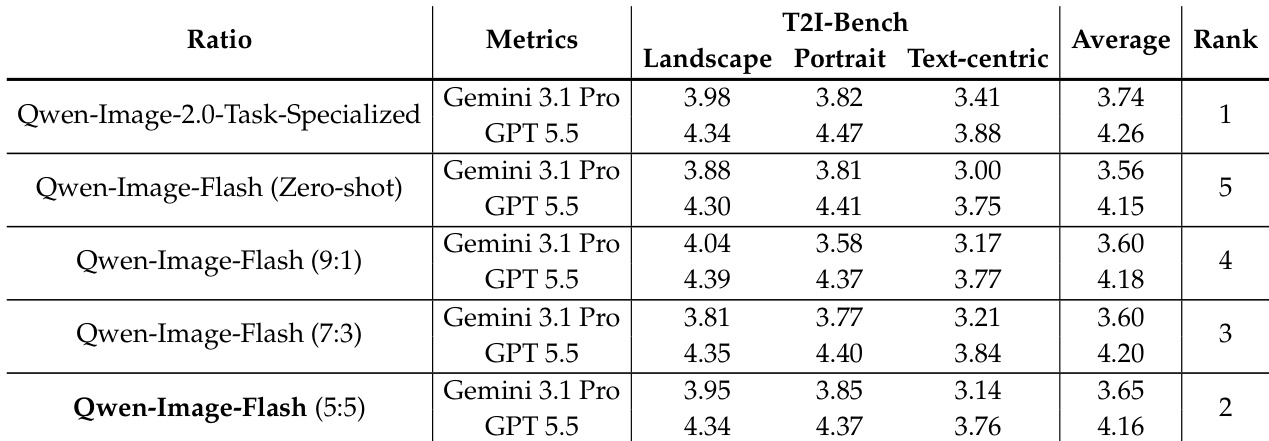
作者考察了不同训练数据构成对文本到图像蒸馏模型性能的影响,重点关注通用图像生成与文本主导合成。结果表明,相较于混合数据或仅包含文本的数据,类别单一的训练数据(如风景或人像)在所有评估类别中均能带来更强的性能,这说明数据多样性未必能提升效果,甚至可能导致性能下降。表现最佳的配置为人像单一数据训练,尽管该配置未直接对齐文本主导任务,但其性能仍优于更多样化的设置。单一类别训练数据的整体表现优于混合数据或仅文本数据;仅文本训练在所有评估划分中均劣于风景或人像单一训练;各类别的平衡混合并未超越最佳单一类别配置。
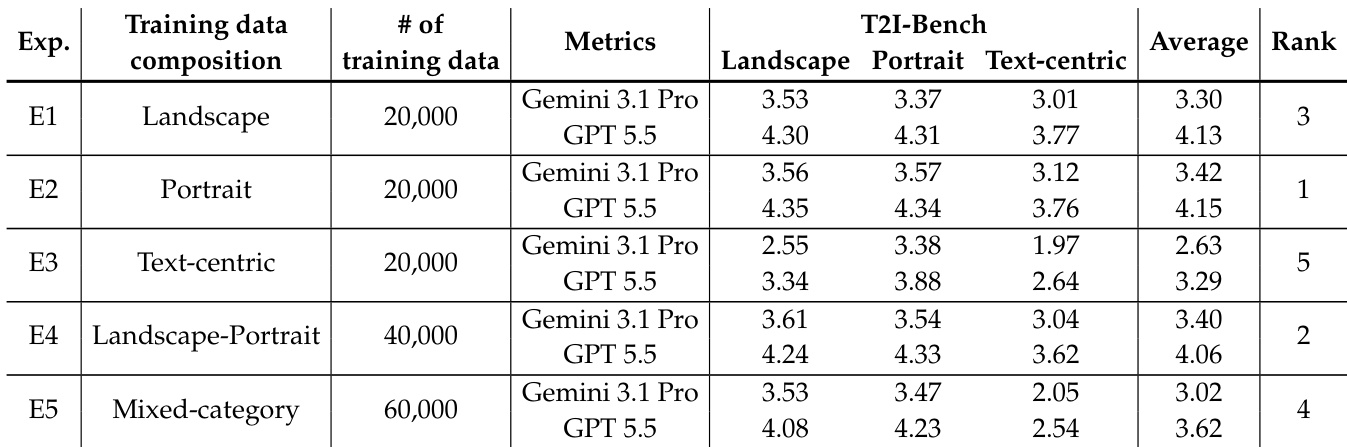
实验通过调整任务混合比例与训练数据构成,对蒸馏后的文本到图像模型进行评估,以验证生成保真度与编辑能力之间的相互作用。结果表明,联合蒸馏期间平衡的文本到图像与编辑数据比例能够最大化编辑迁移效果,同时提升整体生成质量,证实了编辑监督作为互补信号的作用。相反,将训练限制于单一视觉类别始终优于混合或文本侧重数据集,这表明广泛的数据多样性未必能改善泛化能力。最终,该加速学生模型在多样化评估类别中均取得了与多步教师模型相竞争的性能,尽管架构经过简化,仍有效捕捉了任务特定的优势。