Command Palette
Search for a command to run...
世界模型遇见语言模型:论具体与抽象推理的互补性
世界模型遇见语言模型:论具体与抽象推理的互补性
Yucheng Zhou Wei Tao Yiwen Guo Jianbing Shen
摘要
世界模型与多模态大语言模型(MLLMs)为基于静态视觉观测预测未来结果提供了互补的能力。世界模型能够生成可能未来的具体视觉推演序列,而多模态大语言模型则能够对问题、目标与规则进行抽象推理。然而,生成的推演具有随机性,可能在视觉上合理但在任务执行上不正确,因此有必要判断视觉模拟在何种情况下有效、推演结果是否可信,以及其应如何影响最终答案。我们将该问题形式化为受控的具体推理,在此框架下,模型学习在抽象推理的同时调用、验证并整合视觉未来模拟。为研究该设定,我们构建了两个经人工验证的基准测试:VRQABench用于可控空间前瞻,OpenWorldQA用于开放域物理预测,并提出了特权未来同策略自蒸馏方法(Privileged-Future On-Policy Self-Distillation, PF-OPSD)。在训练阶段,PF-OPSD仅将真实未来视频与答案作为教师端特权上下文,用于评估同策略下的具体推理轨迹;而在测试阶段,可部署的学生模型绝不会观测到真实未来信息。实验结果表明,PF-OPSD在VRQABench和OpenWorldQA上的性能分别较基线方法提升了10.6%和10.9%,同时显著增强了对噪声或冲突推演的鲁棒性。我们的代码与数据集已开源,地址为:https://github.com/yczhou001/PF-OPSD。
一句话总结
作者提出了特权未来在线策略自蒸馏(Privileged-Future On-Policy Self-Distillation, PF-OPSD)框架,该框架训练多模态大语言模型验证并整合随机世界模型推演与抽象推理,在VRQABench和OpenWorldQA基准上分别比基线方法提升了10.6%和10.9%,同时通过在训练阶段使用特权真实未来视频以及在推理阶段施加严格限制,增强了模型对噪声模拟的鲁棒性。
核心贡献
- 本文将未来预测建模为受控的具体推理,并引入两个经人工验证的基准数据集VRQABench和OpenWorldQA,用于评估从静态视觉锚点出发的可控空间前瞻与开放域物理预测能力。
- 该研究提出了特权未来在线策略自蒸馏(PF-OPSD)训练框架,该框架仅将真实未来视频与答案作为教师端特权上下文,用于评估具体推理轨迹,同时确保部署的学生模型在推理阶段绝不访问真实未来信息。
- 实证评估表明,PF-OPSD在VRQABench上超越基线方法10.6%,在OpenWorldQA上超越10.9%,同时显著提升了对噪声或冲突视觉推演的鲁棒性。
引言
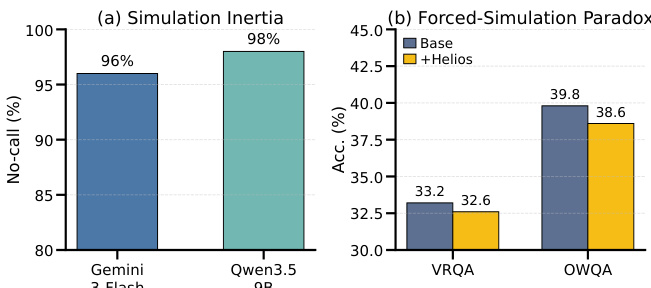
作者通过将多模态大语言模型与视频世界模型相结合,解决面向未来的视觉推理问题,以从静态观测中预测结果。这种结合具有重要意义,因为静态输入缺乏时间动态性,要求模型利用抽象语言推理掌握规则,同时使用具体的视觉推演来模拟物理后果。先前工作面临显著局限,因为世界模型的推演具有随机性,往往在视觉上合理但在任务上错误,从而导致诸如模拟惯性(模型忽略有益的模拟)或强制模拟悖论(模型盲目信任误导性推演)等失效模式。为了解决这一问题,作者提出了受控具体推理方法,并设计了特权未来在线策略自蒸馏框架。该框架在训练阶段使用真实未来作为特权教师上下文,将可靠的模拟调用与验证决策蒸馏至可部署的学生模型中。此外,作者引入了VRQABench和OpenWorldQA基准,用于评估可控空间前瞻与开放域物理预测能力,展示了相比基线方法在准确率与鲁棒性方面的提升。
数据集
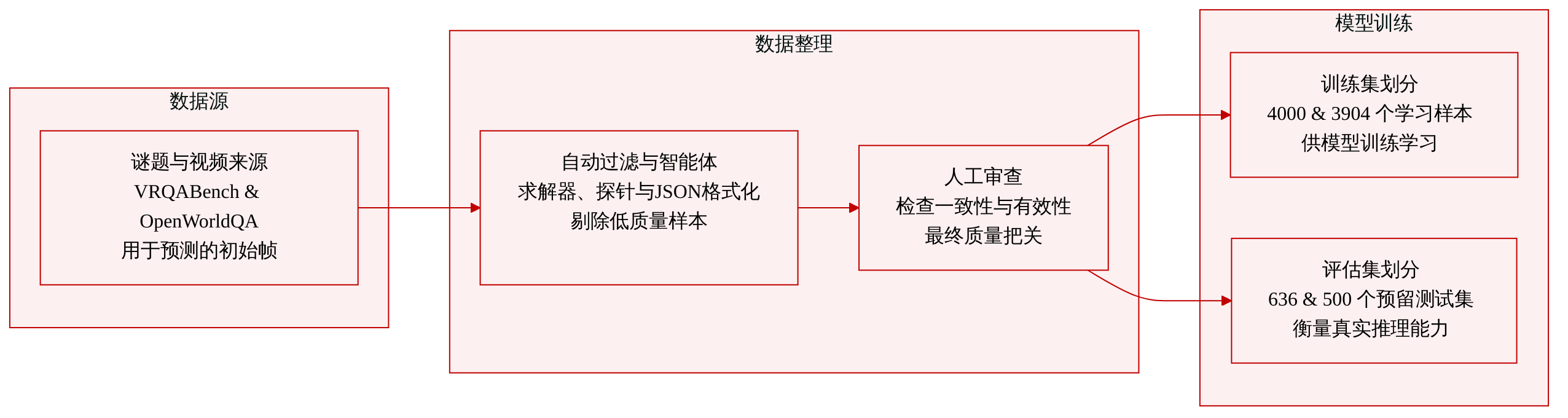
- 数据集构成与来源
- 作者引入了两个四选项基准数据集,旨在评估从静态观测进行未来预测的能力。VRQABench 源自 VR-Bench,专注于谜题环境中的规则驱动空间前瞻。OpenWorldQA 由真实短视频构建,用于测试开放域物理预测能力。
- 子集详情(规模、来源与过滤)
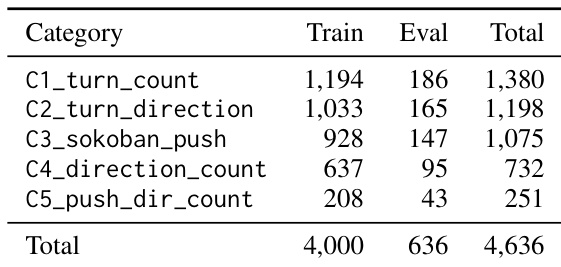
- VRQABench 包含 4,636 道经人工验证的题目,划分为 4,000 道训练题与 636 道评估题。涵盖五个空间类别,并使用确定性求解器替代基于视觉语言模型的求解追踪,以确保标签具有程序化依据。所有题目均经过自动质量过滤与人工验证,以确认视觉一致性、选项合理性与答案有效性。
- OpenWorldQA 包含 4,404 道经人工验证的题目,划分为 3,904 道训练题与 500 道平衡测试题。涵盖十二个物理推理类别与六种题型。该数据集通过一个五阶段 Agent 流程构建,涵盖场景分析、题目设计、干扰项生成与小模型探测,并在最终环节进行人工审查以剔除模糊或视觉不一致的样本。
- 数据使用与处理
- 训练集提供主要学习材料,评估集用于衡量模型在保留推理任务上的表现。未来视频帧被严格排除在模型输入之外。在世界模型辅助实验中,系统可选择性调用外部推演生成器,但模型必须独立决定何时请求、信任或拒绝模拟的未来。作者利用这些基准诊断 Agent 的局限性(如模拟惯性与强制模拟悖论),强调动态推演管理而非简单集成。
- 元数据构建与格式化
- 每个通过的样本被序列化为结构化 JSON 文件,包含类别、题目文本、四个选项、正确答案、来源标识、任务类型以及输入图像与解答视频的文件路径。构建流程附加了全面的元数据,包括程序化求解统计、人工审查决策与评分以及版本追踪。ASCII 装饰符号已进行标准化处理以确保兼容性,所有构建提示词均纳入版本控制,以保证数据集生成的可复现性。
方法
作者采用了一套受控具体推理框架,将生成式世界模型集成到未来预测任务的多步决策过程中。整体架构旨在使模型能够动态决定何时启动基于模拟的推理,验证生成推演的可信度,并将其与抽象推理相结合以得出最终答案。该流程以包含观测与问题的输入开始,模型首先判断仅凭抽象推理是否足够。若不足,模型将生成模拟提示词并查询世界模型以产生候选未来推演。随后对该推演进行一致性与相关性验证,模型据此决定依赖程度,并可能最多重试模拟指定次数。最终答案通过结合已验证的推演与抽象推理得出,若未使用模拟则完全依赖抽象推理。
该策略生成一条具体推理轨迹,记录推理过程中的一系列决策。未使用模拟时,轨迹包含模拟决策、推演依赖决策与最终答案。调用模拟时,轨迹包含有界次数的模拟尝试序列,每次尝试均包含提示词、生成的推演与验证决策。尝试次数由基于验证结果的停止条件或最大上限决定。动作空间提供五项控制决策:模拟决策、模拟查询、推演验证、推演依赖与答案预测。该轨迹使失效点显式化,使模型能够避免过度使用有效模拟、接受误导性推演或过度依赖弱推演。

训练过程被称为特权未来在线策略自蒸馏(PF-OPSD),将格式学习与效用校准分离。在第一阶段,学生策略通过 Gemini-3.1-Pro + Agent 工作流提供的协议监督进行初始化,该工作流为每个训练样本生成结构化轨迹。此阶段固定输出协议,推理阶段不使用。在第二阶段,策略通过教师端评估器进行校准,该评估器仅在训练期间观察真实未来与答案。学生在学生视角上下文中生成基础轨迹,并在每个决策节点构建候选集。离散节点使用有效动作集,文本节点使用当前策略的采样。每个候选动作在节点处强制执行,剩余轨迹通过贪心策略补全。特权评估器对生成的轨迹进行打分,学生策略利用优势加权蒸馏目标进行更新。这种在线策略设计旨在探索哪些替代方案能提升学生自身行为,而非模仿固定的特权轨迹。
测试阶段,模型遵循已学习的模拟控制策略,仅使用学生视角状态与严格的单样本重试上限。首个动作控制模拟开关,若需模拟,每次尝试将采样提示词、查询世界模型并预测验证决策。被拒绝或不确定的推演仅在未达到单样本上限前触发新的提示词。停止后,模型构建依赖状态并预测最终答案。该设计使推理成为涵盖模拟选择、推演验证、重试、推演依赖与作答的闭环策略。世界模型仍作为可能出错的具体推理来源:被拒绝的推演并非机械丢弃,当无已接受推演可用时,可在依赖状态中对其进行降权处理。
实验
该方法在预测未来基准上进行评估,使用通过外部世界模型结构化自蒸馏训练的学生模型,并与零样本、监督学习与提示词基线进行对比。主要结果与消融研究验证了学习的模拟控制与针对中间推理步骤的效用校准监督至关重要,因其始终优于静态提示或强制模拟。定性诊断进一步证实,模型会为复杂查询选择性调用世界模型,可靠地过滤误导性或低质量推演,并有效平衡具体证据与抽象推理,从而在不同数据规模与推演条件下保持鲁棒性能。
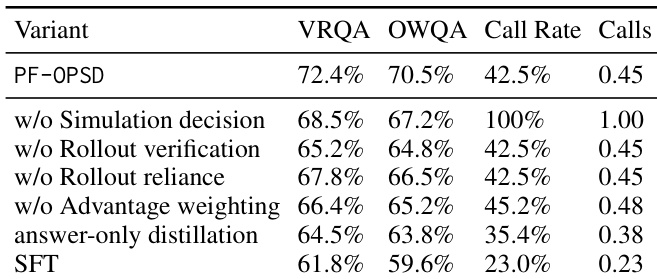
作者在两个未来预测基准上评估 PF-OPSD,发现其在两项基准上均取得最高准确率,优于各类基线。结果表明,移除推演验证、依赖机制或优势加权等关键组件会导致性能下降,说明性能提升源于对中间推理动作的校准监督,而非单纯使用生成的推演。模型还展现出选择性模拟使用的特性,调用世界模型的频率低于全量模拟基线,同时保持高准确率。与所有评估变体相比,PF-OPSD 在两项基准上均取得最高准确率。移除推演验证、依赖机制或优势加权会显著降低性能,表明这些组件对模型成功至关重要。模型选择性使用模拟,调用率低于全量模拟基线,表明其对何时使用世界模型推演具备有效控制。
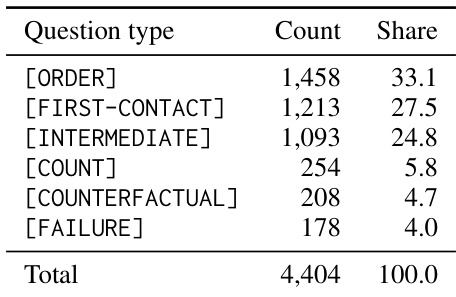
作者分析了基准数据集中题型的分布情况,指出顺序相关题目占据主导地位,其次为首次接触与中间类型,计数、反事实与失败案例占比较小。该分布为评估模型在不同推理需求下的表现提供了依据。顺序相关题目构成数据集主体,其次为首次接触与中间类型。计数、反事实与失败题型占比较小。数据集共包含 4,404 道题目,涵盖六种不同题型。
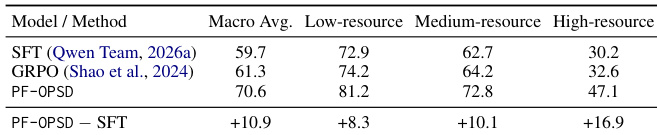
作者在两个未来预测基准上评估 PF-OPSD,证明其通过有效学习模拟选择与验证,取得了高于基线方法的准确率。模型选择性调用世界模型,在避免冗余调用的同时保持强劲性能,并在不同世界模型与资源层级下展现鲁棒性。PF-OPSD 通过学会做出选择性且可靠的模拟决策,超越基线准确率。模型减少不必要的模拟调用并保持高性能,表明模拟控制有效。PF-OPSD 在不同世界模型与资源层级下维持性能优势,展现出良好的鲁棒性与泛化能力。
作者提出了面向未来预测基准的评估框架,将 PF-OPSD 与监督微调及工作流 Agent 提示等多种基线进行对比。结果显示,PF-OPSD 在两项基准上均取得高于所有基线的准确率,并在不同数据集类别与资源层级下实现稳定提升。模型展现出选择性模拟使用的特性,有效避免冗余推演,同时在困难案例上保持高性能。PF-OPSD 在两项基准上均超越所有基线准确率,在不同数据集类别中实现一致提升。模型选择性调用世界模型,避免不必要模拟的同时在困难样本上维持高性能。PF-OPSD 在各资源组中表现强劲,包括训练样本少于 100 个的低资源类别。
作者在受控条件下分析推演验证行为,表明随着推演质量下降,模型接受率急剧降低,而最终准确率保持相对稳定。模型展现出精细的判别能力,能够信任高质量推演,拒绝误导性或不一致推演,并在推演与静态线索互补时将其结合。该行为表明策略学会了根据具体证据的质量与相关性校准依赖程度。随着推演质量下降,模型接受率显著降低,从已验证未来的高接受率降至严重损坏推演的极低接受率。不同推演条件下最终准确率保持稳定,说明策略在推演不可靠时可回退至抽象推理。模型有效拒绝误导性推演,同时在其能纠正抽象推理错误时加以利用。

在涵盖多样题型与资源约束的两个未来预测基准上,PF-OPSD 通过学会选择性验证与整合世界模型模拟,始终超越基线方法。消融实验验证了推演验证与优势加权等组件的关键作用,确认准确率提升源于对中间推理的校准监督,而非未经验证的推演生成。补充分析表明,模型战略性限制模拟调用,并根据推演质量动态调整依赖程度,有效剔除不一致输出,在模拟质量下降时回退至抽象推理。最终,该框架通过掌握模拟未来的选择性可靠使用,实现了强大的泛化能力与优越的预测性能。