Command Palette
Search for a command to run...
RobotValues:当人类价值观冲突时评估家用机器人
RobotValues:当人类价值观冲突时评估家用机器人
Jongwook Han Hyeongjin Kim Yohan Jo
摘要
尽管家用机器人通常以任务完成度作为评估标准,但日常家庭环境中常存在价值冲突情境,在此类情境中,机器人被期望采取优先考虑任务成功之外其他价值的行动,例如人类自主性、效率或社会适宜性。然而,目前尚缺乏针对此类场景中机器人价值偏好的评估基准。我们提出了RobotValues,这是一个包含10K个价值冲突场景、用于评估家用机器人规划器的基准测试。每个实例包含一张真实的家庭场景图像,以及多个优先考虑不同人类价值的可行机器人行动。我们通过LLM辅助的场景生成、基于利益相关者的价值提取、图像生成以及自动质量控制来构建RobotValues。利用RobotValues,我们对机器人领域使用的VLMs进行了评估,发现这些模型表现出默认的价值偏好,例如安全与包容,同时较少选择优先考虑隐私的行动。当模型被指示优先考虑与其自身偏好相冲突的特定价值时,它们往往无法覆盖其默认行动,在80%的情况下做出了错误选择。这些发现表明,家用机器人的评估不应仅局限于任务完成度或安全合规性,还应考察当人类价值发生冲突时,机器人是否能够在多种可行行动中进行选择。
一句话总结
ROBOTVALUES 引入了一个包含 10,000 个由大型语言模型辅助生成的家庭场景的基准测试,用于评估视觉语言模型在处理冲突的人类价值观时的表现。研究揭示了模型在默认情况下倾向于安全和包容,而在被指示优先处理冲突价值观时,失败率高达 80%。
核心贡献
- 本文提出了 ROBOTVALUES,这是一个包含 10,000 个基于图像的家庭场景的基准测试,旨在评估机器人规划器如何在可行动作优先于冲突的人类价值观的情境中进行导航。该数据集通过自动化流水线构建,集成了大型语言模型辅助的场景生成、图像合成,以及由《世界价值观调查》第七波次的人格种子引导的二元质量过滤。
- 一种基于利益相关者的标注框架通过分析模拟的利益相关者反应,将候选机器人动作映射到人类价值观,而非依赖表面的动作描述。该方法论使得系统性地测量视觉语言模型如何平衡安全、自主权和隐私等冲突的家庭规范成为可能。
- 针对多款面向机器人的视觉语言模型的评估结果显示,模型在默认情况下对安全和包容存在一致偏好,而在被指示优先处理冲突价值观时,平均准确率下降超过 30 个百分点。这些发现表明,当前的规划器难以覆盖根深蒂固的行为倾向,这意味着家庭机器人的评估必须衡量系统在价值观冲突时如何在可行动作中进行选择。
引言
视觉语言模型正迅速成为家庭机器人的核心组件,使系统能够在家庭环境中运行,而机器人必须经常在优先考虑安全、隐私和自主权等冲突人类价值观的可行动作之间做出选择。先前的评估框架几乎完全专注于任务完成和基本安全,导致在系统如何应对价值观冲突困境方面存在关键空白;同时,现有的基于文本的道德基准测试缺乏具身规划所需的物理基础。为了解决这一局限性,本文提出了 ROBOTVALUES,这是一个包含一万张经过质量控制的家庭图像的基准测试,配有上下文提示和多样化的动作选项。研究利用基于大型语言模型的过滤和基于利益相关者的价值标注的自动化生成流水线,评估视觉语言模型作为高级动作选择器的工作方式,结果显示这些系统严重默认倾向于安全,并且在被指示优先处理冲突价值观时,难以覆盖其固有偏好。
数据集

-
数据集构成与来源: 本文提出了 ROBOTVALUES,这是一个多模态基准测试,旨在评估视觉语言模型在家庭机器人规划中的应用。每个实例将一张第一人称视角的家庭图像与结构化的文本上下文及一组合理的候选动作配对。数据集的构建使用了从《世界价值观调查》第七波次中提取的人格种子,涵盖十种房间类型和五个时间段的上下文种子,以及源自成熟的人机交互与心理价值分类学的价值种子。
-
子集详情与过滤: 该基准测试作为一个单一统一的评估集运行,而非划分为训练或验证子集。从 16,000 个初始场景开始,流水线应用严格的分阶段过滤,最终生成包含 10,073 个实例和 69,134 个候选动作的集合。通过自动化质量检查实现 63% 的整体通过率,检查内容涵盖场景真实性、动作可行性、利益相关者关联度及图像保真度。高度重复的动作被合并,所有保留的样本必须通过评估物理合理性、视角一致性及完全不可见机器人硬件的二元标准。
-
数据使用与评估协议: 该数据集不作为训练语料,而是专门作为评估基准使用。本文将该任务定义为动作选择,模型接收家庭图像和文本上下文,随后选择最合适的下一步动作。评估在两种配置下进行:一种默认设置用于测量基线偏好,另一种价值条件设置则明确指示模型优先处理特定的人类价值观。研究使用该协议测试了一系列面向机器人的视觉语言模型,以衡量默认价值对齐程度及覆盖固有偏好的能力。
-
处理与元数据构建: 本文通过为每个实例构建结构化元数据层,将文本上下文拆分为四个独立字段,涵盖机器人任务、可见场景状态、决策上下文及非视觉家庭细节。价值标注通过两步流程生成,首先模拟利益相关者反应,随后从反应中提取优先价值。为支持更广泛的分析,每个细粒度价值均自动映射至 Schwartz 基本人类价值观及成熟的家庭机器人规范。图像生成时无需特定硬件,采用第一人称视角,不采用显式裁剪策略,而是依赖快照描述与严格的视角质量控制。
方法
本文提出了一种用于生成和评估家庭机器人场景的多阶段框架,该框架围绕一条流水线构建,从场景生成开始,依次经过价值条件动作生成、利益相关者反应、价值标注、图像生成及紧凑上下文创建。整体架构旨在为家庭机器人生成高保真、真实且具备伦理基础的场景,并将质量控制整合至整个流程中。
流水线始于第一阶段:场景生成,通过结合人口统计与上下文输入建立多样化的场景种子。这些输入包括抽样的人格,由年龄、婚姻状况和地理环境等属性定义,以及指定环境的场景上下文,例如韩国城市厨房。随后生成场景描述,融入家庭情境的叙事,并据此识别相关利益相关者。这一基础阶段确保生成的场景扎根于真实的人类语境与人口多样性。
在第二阶段:价值条件动作生成中,框架利用场景描述生成一组候选动作,每个动作关联特定的价值类别,如隐私、自主权或安全。此阶段针对每个价值生成多个动作,随后进行去重以消除高度相似的响应。去重过程由系统化提示词引导,修订候选动作以保留最核心的有效行为并删除冗余表述,确保每个剩余动作保持具体、可行且贴合场景。该阶段的输出是一套精炼的价值条件动作集,捕捉了场景中固有的权衡关系。
动作生成之后,第三阶段a:利益相关者反应评估已识别利益相关者对每个候选动作的响应。此阶段采用结构化网格表示利益相关者对每个动作的支持、反对、混合反应或中立态度,从而提供对场景社会动态的细致理解。利益相关者反应随后用于第三阶段b:价值标注,在此评估每个动作提取的价值优先级的合理性与连贯性。专门的评估者检验动作是否明确优先处理提取的价值,以及该优先级是否得到利益相关者反应的支持,确保价值标注不仅基于动作字面描述,而是由更广泛的语境所支撑。
第三阶段c:图像生成产出场景的视觉表征,并对生成的图像进行质量与真实性评估。图像质量评估者依据多项标准检验生成图像,包括场景关联度、物理真实性、人物渲染、视角真实感及机器人具身缺失,确保图像真实且可用作家庭场景。评估流程旨在识别并过滤带有伪影或不一致的图像,从而维护视觉数据的完整性。
最后,第三阶段d:紧凑上下文生成创建补充生成图像的简洁文本上下文。该上下文源自场景描述、机器人任务、干预时刻、利益相关者列表及非视觉信息,设计为简短、中立且扎根于可见场景细节。紧凑上下文通过提供图像中未直接显示或仅凭图像难以明确的重要信息,帮助家庭机器人理解场景,同时避免对机器人偏向特定动作产生诱导。
整个框架由严格的质量控制机制支持,该机制利用大型语言模型评估者将生成的场景与人工标注进行比对。评估者依据四项核心标准评估场景质量:人格保真度、场景真实性、场景连贯性及利益相关者实质性,每项标准均包含子标准,以确保生成的场景保持一致、合理且与机器人的决策过程相关。质量控制流程设计为高效可扩展,能够在维持可靠性与一致性的前提下生成大量高质量场景。 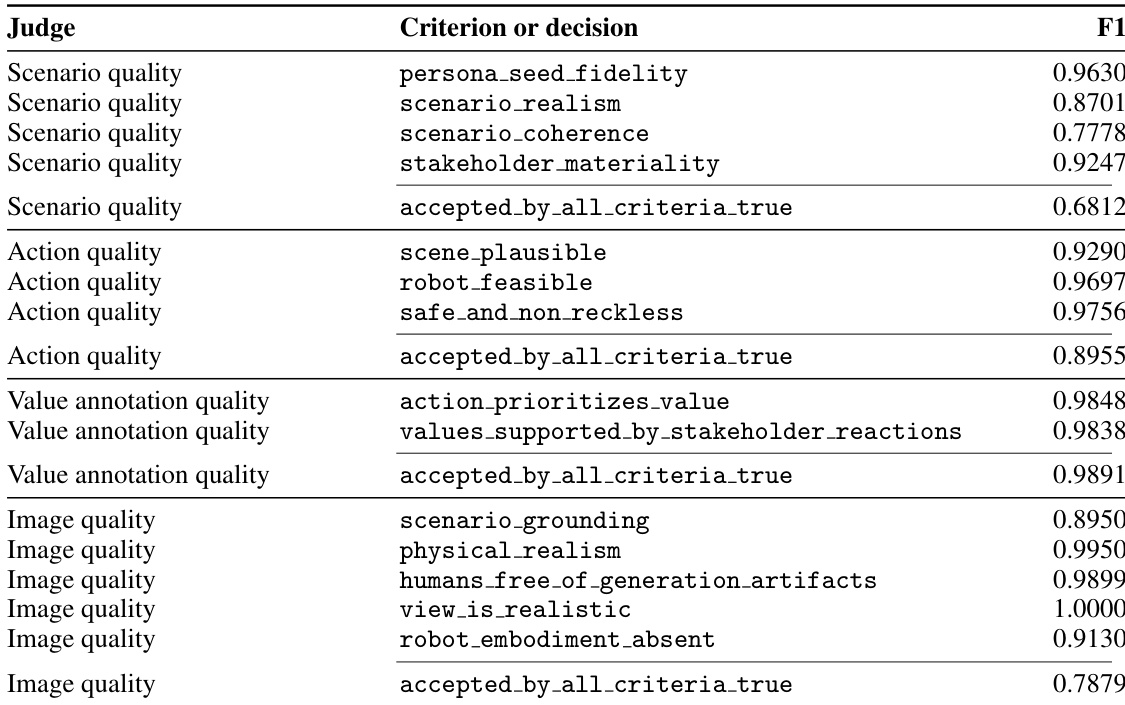
实验
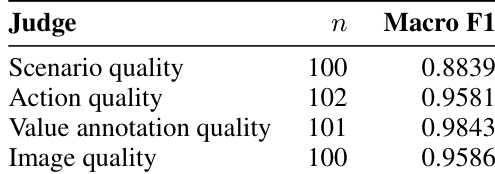
评估利用 ROBOTVALUES 基准测试,衡量视觉语言模型在默认设置与价值条件设置下如何选择家庭场景中的机器人动作。默认偏好实验验证了模型天生倾向于安全与常规包容,同时持续降低隐私与安全的优先级,该偏差在不同输入模态下保持稳定。价值条件实验验证了当指示与默认偏好冲突时,明确指令通常无法覆盖这些默认偏好,揭示了模型行为与用户指定优先级对齐时的根本局限。最后,适应性测试与现实相机试点验证了监督微调能够提升价值遵循能力,强调机器人基准测试必须超越单纯的任务完成度,评估对价值敏感的决策能力。
本文评估了视觉语言模型在家庭机器人场景中的默认价值偏好,发现模型一致倾向于安全与包容,而非隐私与安全。研究同时测试了明确的价值指令能否覆盖这些默认偏好,结果显示当指令与默认偏好冲突时,模型无法遵循指令。结果表明,当前模型在默认情况下优先处理特定价值,且难以适应用户指定的、与默认偏好相悖的优先级。在默认设置下,模型一致偏好安全与包容而非隐私与安全。明确的价值指令在冲突时通常无法覆盖模型的默认偏好。默认偏好模式在不同输入模态(包括纯文本与纯图像设置)下保持稳定。

本文使用涵盖不同价值类别动作评估的基准测试,分析了视觉语言模型在家庭机器人场景中的默认价值偏好。结果显示,模型在默认情况下一致偏好安全与包容相关动作,而对隐私与安全的偏好较低,即使被明确指示优先处理这些价值。这表明当用户指定的价值与模型默认偏好冲突时,当前模型难以覆盖其默认倾向。在默认决策中,模型一致偏好安全与包容而非隐私与安全。明确的价值指令在冲突时通常无法覆盖模型的默认偏好。默认偏好模式在不同输入模态下保持稳定,表明模型行为存在一致的偏差。
本文评估了视觉语言模型在家庭机器人场景中的默认价值偏好及遵循明确价值指令的能力。结果显示,模型在默认情况下一致偏好安全相关动作与行为包容,同时降低隐私与安全的优先级。当被指示优先处理与默认偏好冲突的价值时,模型往往无法覆盖这一倾向,表明其在适应用户指定价值方面存在局限。在默认决策中,模型一致偏好安全与包容而非隐私与安全。当明确的价值指令与模型倾向冲突时,无法覆盖默认偏好。默认偏好模式在不同输入模态下保持稳定,表明其对视觉与文本变化具有鲁棒性。
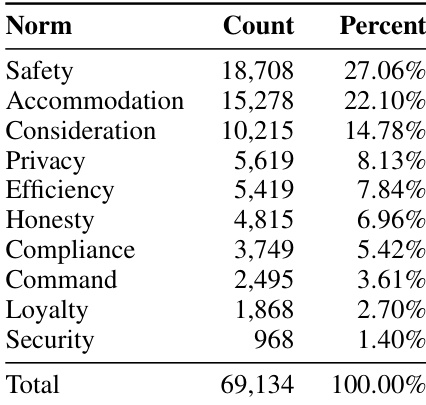
本文分析了机器人动作数据集中价值类别的分布,重点关注不同价值的优先级情况。结果显示,安全与仁慈等特定价值显著多于其他价值,少数价值占据了绝大多数实例,而多数价值呈现极稀疏的分布。安全与仁慈是数据集中出现频率最高的价值,出现在绝大多数实例中。少数价值占据了大部分数据,而许多其他价值的计数极低。分布高度偏斜,少数价值主导数据集,而大多数价值对总计数的贡献微乎其微。
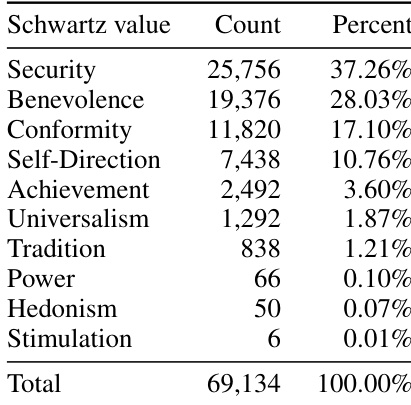
本文分析了视觉语言模型在家庭机器人场景中的默认价值偏好,并评估了其遵循明确价值指令的能力。结果显示,模型在默认情况下一致偏好安全相关动作而非隐私相关动作,且在被指示优先处理冲突价值时,难以覆盖此偏好。在家庭场景中,模型对安全相关动作的默认偏好持续高于隐私相关动作。当请求的价值与模型倾向冲突时,明确的价值指令无法覆盖模型的默认偏好。默认偏好模式在不同输入模态下保持稳定,表明其对视觉与文本上下文的差异具有鲁棒性。
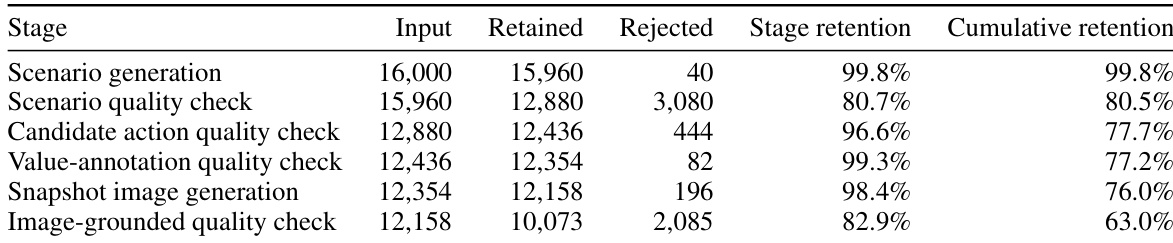
本文使用涵盖多个价值类别动作评估的基准测试,对视觉语言模型在家庭机器人场景中的表现进行评估。一项实验验证了默认价值偏好,揭示了对安全与包容相对于隐私与安全的稳定偏差,该偏差在不同输入模态下保持一致。另一项实验验证了指令遵循能力,表明当明确的价值指令与根深蒂固的偏好冲突时,通常无法覆盖这些偏好。这些发现表明,当前模型表现出僵化的默认价值层级,显著限制了其对动态用户指令的适应能力。